
基于形态自适应网络的无人机目标跟踪方法
2021-07-05 13:46刘贞报马博迪高红岗院金彪江飞鸿张军红赵闻
航空学报 2021年4期
刘贞报,马博迪,*,高红岗,院金彪,江飞鸿,2,张军红,2,赵闻
1. 西北工业大学 民航学院,西安 710000 2.航空工业第一飞机设计研究院 飞控系统设计研究所,西安 710089
无人机航拍获取目标场景影像信息的方式具有可低空作业、覆盖面积广、机动性强、效率高、不受地势环境阻碍等优点,广泛应用于军事和民用领域[1-3]。无人机目标跟踪技术是无人机视觉研究领域的关键技术,研究稳定、高效的航空影像目标跟踪算法对于无人机的应用有着重要意义[4-6]。
视觉目标跟踪系统有很多种,根据算法追踪目标建模方式的不同可以将其分为生成类模型、判别类模型和深度学习模型3种类型。生成类模型是指在当前帧对目标区域进行建模,在随后的视频序列中寻找与模型最相似的区域[7],从而实现目标追踪的目的,生成类模型的追踪效果很大程度上取决于特征的选择和搜索算法。其中特征需要满足转移不变形和尺度不变形,例如颜色特征、纹理特征等。而在获取合适的目标特征之后,则需要通过合适的搜索算法对特征进行描述、匹配以及预测,从而最终完成整个追踪过程。判别类模型显著地区分了前景和背景的信息,通过判别函数将目标从背景中分割出来,故而在实际应用过程中模型的表现更为鲁棒;常用的判别类模型有KCF[8](Kernelized Correlation Filters)、DSST[9](Discriminatiive Scale Space Tracker)、SRDCF[10](Spatially Regularized Discriminative Correlation Filters)等。可基于深度学习的目标跟踪算法通过深度神经网络等模型,获取表征能力很强的深度特征,根据深度特征的特点实现目标的检测和追踪。近年来,随着深度学习技术的迅猛发展,国内外学者及研究人员们提出了一系列性能优良的深度学习目标检测模型,SiamFC[11](Siamese Fully Convolutional deep networks)基于孪生神经网络构建了一个相似性度量函数,通过互相关计算得到响应得分图,响应图中得分最高的位置对应于原图中目标所在位置。Siam RPN[12](Siamese Region Proposal Networks)由孪生神经网络和RPN[13](Region Proposal Networks)网络两部分组成,前者用来提取特征,后者用来产生候选区域,通过回归方式对目标进行跟踪定位,整个网络实现了端到端的训练。
相比于通用目标跟踪,无人机影像目标跟踪方法更具有挑战性。首先无人机影像目标跟踪的数据集较少,样本多样性不足;其次无人机航空拍摄过程中,地面同一类目标容易具有多个不同的旋转方向;此外,航拍影像中的目标易发生目标遮挡和光照干扰,同时存在相机抖动等影响,这些特点增加了无人机影像目标跟踪的难度。
针对上述问题,本文提出一种基于形态自适应网络的无人机影像目标跟踪方法,首先在训练过程中通过数据驱动的方式[14]产生多个目标感兴趣区域,对数据集进行扩增,提高样本多样性;然后加入旋转约束项使卷积深度置信网络能够自适应无人机影像目标形态变化,提取具有强表征能力的深度特征;接着使用深度特征变换算法得到目标预定位框,提出基于Q学习算法的搜索机制对目标进行自适应精准定位,进一步精确目标位置,采用深度森林分类器获取目标类别信息,提升跟踪效果。为验证所提方法的精度及目标跟踪结果,在UAV123数据集、VisDrone数据集和自研无人机航拍数据集上进行实验测试,并与其他10种常用目标跟踪方法进行对比。
1 相关工作
1.1 样本数据预处理
针对无人机视频影像数据样本数量较少、多样性不足的情况,在训练过程中,采用一种基于数据驱动的方法[14]对样本数据集进行扩充。对训练样本数据X={x1,x2,…,xk},该方法使用选择性搜索算法对样本图像数据提取目标建议区域,该方法首先对输入图像进行分割产生许多小的子区域,然后根据这些子区域之间的相似性进行区域合并,相似性指标包括颜色相似度、纹理相似度、尺寸相似度和交叠相似度。选择性搜索算法生成多个目标建议区域,通过不同目标建议区域的交并比值(IoU)取值判断所生成目标建议区域是否为正例样本数据,IoU计算方式为
(1)
式中:Bop为目标建议区域图块;Bgt为标注框;area(Bop∩Bgt)为目标建议区域图块和标注框的交集;area(Bop∪Bgt)为目标建议区域图块和标注框的并集。如果目标建议区域IoU大于预设阈值0.6,则定义该目标建议区域为正例样本;若IoU<0.6,则定义该目标区域图块为负例样本。
1.2 卷积受限玻尔兹曼机
卷积受限玻尔兹曼机[15]是包含一层可见层变量和隐藏层变量的无向概率图模型,通过堆叠的方式(一层的输出为下一层的输入)构成更深的深度置信网络模型。可见层和隐藏层层间的各神经元节点之间有连接,可见层和隐藏层层内的任何单元之间无连接。卷积受限玻尔兹曼机旨在以最大概率拟合输入数据的分布学习到可视层和检测层之间的统计关系,通过训练提取输入数据的深度特征获得数据内部之间的高阶相关性。
令v=[vi]表示可视层变量的状态,代表输入数据;h=[hj]表示隐藏层变量的状态值,使用W=[wij]表示可见层与隐藏层之间的卷积核,π=[πi]表示可见层节点单元的偏置,τ=[τj]表示隐藏层节点单元的偏置,模型参数集为参数θ={W,π,τ},当给定可见层和隐藏层的状态{v,h}时,卷积受限玻尔兹曼机的能量函数定义为
(2)
根据能量函数可以描述可见层和隐藏层的概率分布[16],当模型参数确定时,状态{v,h}的联合概率分布为
(3)
(4)
式中:ξ(θ)为配分函数,起概率分布归一化的作用。根据式(3)和式(4)中概率分布模型的定义,得到了能够对实际输入数据分布规律进行表示的卷积受限玻尔兹曼机模型。给定可见层输入样本v,卷积受限玻尔兹曼机可见层变量的概率分布为
(5)
卷积受限玻尔兹曼机训练的目标函数为ψ(θ)=-lgP(v),采用随机梯度下降优化方法最小化目标函数求解模型参数。
1.3 强化学习
强化学习[17]使用智能体和环境进行交互,环境对智能体的行为进行奖惩,智能体根据环境反馈的信息调整自身参数,以达到累积奖励期望值最大化,通过训练智能体可以选择出当前状态下最优的动作。Q学习算法属于强化学习的一种,通常需要定义一个状态动作函数,即Q值函数,表示在状态s下采取动作a能够获得最大的奖励值,然后通过迭代的方式不断更新Q值。如果Q函数足够准确且环境确定,那么只要采取实现最大Q值动作的策略即可。对于离散的状态空间,Q学习算法将Q值存储在一个Q表格中,该表格的行表示不同的状态,列表示所有可能的动作。对于状态连续或者状态数量很多的情况,通常用深度神经网络模拟近似Q值函数,使用当前值与目标值之间的差异,将此差异作为目标函数并使用梯度下降算法解算网络参数集。
2 本文方法
针对无人机航空影像目标跟踪中常出现目标形态变化问题(如目标旋转、目标遮挡等问题),提出了一种基于形态自适应网络的无人机目标跟踪方法。提出的形态自适应网络包含改进深度置信网络、深度特征变换模块、基于Q学习的搜索机制和深度森林分类器,模型整体框架结构如图1所示。
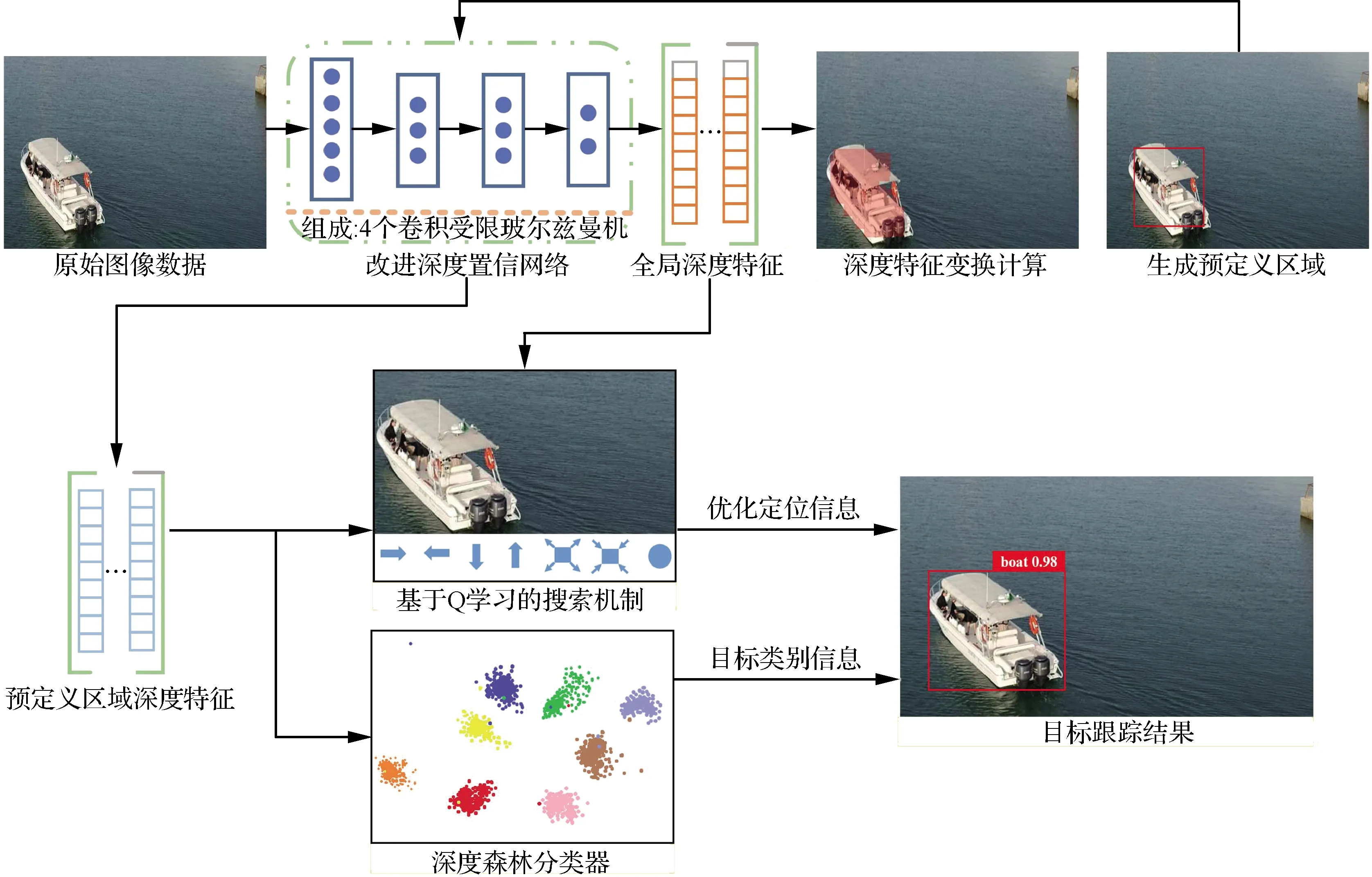
图1 所提方法框架结构Fig.1 Architecture of proposed method
在训练过程中,首先采用选择性搜索算法对训练样本进行扩充,得到目标遮挡样本与目标旋转样本,使用改进深度置信网络提取影像数据的深度特征,该特征具有旋转不变性,对遮挡变化具有鲁棒性;然后采用深度特征变换算法得到目标预定位位置,提出基于Q学习算法的搜索机制优化目标框位置,使用深度森林获取目标分类信息,得到精准的目标跟踪结果。
2.1 改进深度置信网络
深度置信网络由多个卷积受限玻尔兹曼机堆叠构成,属于一种无监督模式的多层神经网络结构,旨在利用对数似然最大化算法不断调整模型各层间的权值,使模型能够拟合可见层和隐藏层数据之间的联合概率分布,从而学习到输入数据中的深度特征,该深度特征具有强表征能力。针对无人机影像视频中目标易受到遮挡、形变、复杂背景干扰等问题,提出了改进深度置信网络模型,通过对原始样本数据集进行数据扩充,加入遮挡样本和旋转样本进行训练,使模型对遮挡和旋转问题具有更好的鲁棒性,具体如下。
为使深度置信网络模型能够自适应目标遮挡和旋转变化,在训练阶段使用1.1节中介绍的选择性搜索算法对原始训练样本X进行扩增,扩增后的正例样本数据由IoU取值在0.6~1.0之间的样本图块组成,可代表目标被不同程度遮挡的情况。在所生成的遮挡样本P之中,IoU取值范围在0.6~0.7和0.7~0.8的样本数据各占30%,IoU取值范围在0.8~0.9和0.9~1.0的样本数据各自占20%。IoU值越接近0.6,表示目标被遮挡部分越多;IoU值越接近1.0,表示目标被遮挡的区域越少。通过加入遮挡情况的训练样本,模型可以适应目标的遮挡变化。
设计了旋转不变约束项,使卷积受限玻尔兹曼机模型具有旋转不变性:
(6)

O2(Rφ2pi)+…+On(Rφnpi)]
(7)
通过加入旋转不变正则项约束,使不同旋转角度的目标数据在经多层受限玻尔兹曼机重构后能够得到相近的表示。改进的卷积深度置信网络模型损失函数由原卷积受限玻尔兹曼机损失函数项、旋转不变约束项和权值衰减项组成:
(8)
式中:λi为约束项的参数;第1项为原损失函数项,使训练数据的输入和输出尽可能相等;第2项为旋转不变项,使目标在旋转变换前后经过模型输出的重构特征尽可能接近;第3项为权重衰减项,有助于减少模型过拟合。
通过旋转不变约束项生成的遮挡训练样本和目标旋转训练样本,改进深度置信网络可以提取到具有强表征能力的深度特征,该特征具有旋转不变性,并适应目标遮挡变化。改进深度置信网络可以看作是由多个卷积受限玻尔兹曼机通过集成学习的方式堆叠构成的,即前一个受限玻尔兹曼机的输出作为紧接着的后一个受限玻尔兹曼机的输入。在训练过程中,首先根据损失函数训练好第1个受限玻尔兹曼机,然后以其输出作为第2个玻尔兹曼机的输入,依次训练完成所有受限玻尔兹曼机,最后一个受限玻尔兹曼机的输出作为深度置信网络输出的深度特征,记做F={f1,f2,…,fd},fd为对应于原图中的一个图块区域。
2.2 深度特征变换算法
训练完成卷积深度置信网络后,对于视频的前L帧[18],可得到视频中每帧图像的深度特征,首先计算深度特征平均值:
(9)

(10)
得到相关性矩阵Cov(f)后,可以计算相关性矩阵的特征向量,用e1,e2,…,ed表示,用emax表示最大特征值对应的特征向量,计算深度特征在该特征向量上的投影:
(11)

2.3 基于Q学习的搜索机制
为进一步精确目标跟踪定位框的位置,采用基于Q学习算法的主动目标定位方法[10],在训练过程中使用动态注意力调整方法,预定位目标框不断调整接近真实标签,训练目标跟踪的对应搜索机制;在跟踪过程中,将预定位框输入训练好的搜索机制,得到待检测目标的精准定位。模型的动作序列如图2所示,对应7种搜索框尺度位置变化,分别是上边缘移动、下边缘移动、左边缘移动、右边缘移动、整体放大、整体缩小和停止。
在所研究搜索机制模型中,定义当前状态由三元组组成s={o,p,h},其中o为原始图像的深度特征,p为预定位区域的深度特征,h为历史动作。具体地,将当前帧输入改进深度置信网络得到当前帧深度特征、1 024维度的特征向量;同样地使用深度置信网络模型提取预定位框的深度特征;h由过去搜索机制前5步历史动作组成,因此h的维度是7×5=35维。
预测框位置由框左上角和右下角的图像坐标表示,即b=[x1,y1,x2,y2]。图2所述变换动作通过变换预测框位置坐标表示完成:

图2 Q学习动作序列Fig.2 A sequence of actions in Q-learning
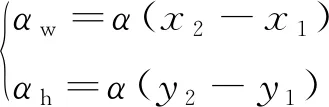
(12)
式中:α为预测框变换阈值,α∈[0,1];αw为预测框宽度变化值;αh为高度变化值。每个变换动作通过给x或y坐标增减αw和αh量值表示。如水平向右变换动作为给x2增加αw;竖直向下变换动作为给y2减去αh。基于搜索速度和跟踪精度的考虑,将α取值为0.05。
通过强化学习算法中的奖励策略学习搜索机制,具体定义奖励函数为r(s,s′),表示搜索机制对状态s经过动作函数α变换后得到新状态s′的奖励分值:
r(s,s′)=sign(IoU′-IoU)
(13)
式中:IoU为在动作变换前预定位框和标注的交并比值;IoU′为在动作变换后预定位框和标注的交并比值。
搜索机制的触发器会触发停止动作,因此对于该动作变换前后IoU的差值为0。设定触发器的奖励函数为
(14)
式中:下标ω代表触发停止动作;μ为触发器奖励值,实验中μ取值为4。给定当前的状态,搜索机制将会给出最优的图像变换行为,参考文献[18-19],采用神经网络模拟搜索机制的状态动作值函数,Q值函数表示为

(15)
式中:s′和a′为s的下一个状态和行为;θ为当前神经网络参数;γ为折扣因子,取值范围为0~1,γ越趋近于0表示算法越倾向于当前状态所获得的奖励,γ越趋近于1表示算法越倾向于从长远角度获得奖励。神经网络通过梯度下降优化损失函数、迭代解算模型参数,损失函数定义为
Li(θi)=(yi-Q(s,a;θi))2
(16)
式中:θi为模型参数;yi为迭代算子,计算公式为
(17)
基于Q学习算法的目标搜索机制如图3所示,图中:-d表示维度(dimension)。在给定待检测图像的状态下,根据奖励值从给定的动作集合中选取期望收益最大的动作,使预定位框不断逼近目标真实位置,得到最优解作为目标跟踪结果输出。
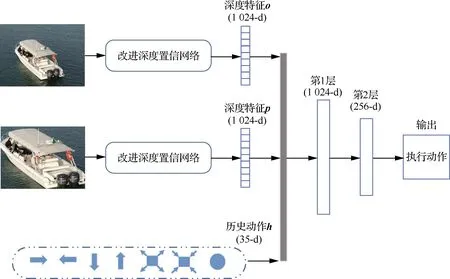
图3 Q学习搜索机制Fig.3 Illustration of Q searching policy
2.4 深度森林分类器
为使所提方法能够识别提供跟踪目标的类别信息,需要在顶层添加一个分类器,采用深度森林[20]模型作为分类器。相比于传统分类器(如softmax等模型),深度森林具有鲁棒性强、精度高、超参数少的特点,能从复杂特征中获取类内相似性和类间差异性,从而提供准确的跟踪目标分类信息。
深度森林结构如图4所示,由多层级联随机森林组成,每层级联森林包括两个完全随机森林(绿色)和两个随机森林(蓝色),每个森林包含500棵随机树,完全随机树使用所有样本作为输入,决策树的每个节点都是随机选择一个特征做分裂,直至每个叶节点包含的实例属于同一个类,或者实例数目不多于10个,该方法增加了样本的多样性;随机森林的训练过程为每棵树输入样本的一个随机子集,分裂节点选择最优基尼系数的一类进行分裂,该方法保证了算法的效果。假设当前有Z个分类类别,样本特征属于第z个类别的概率为gz,则其基尼系数计算方式为

图4 深度森林结构Fig.4 Architecture of deep forest
(18)
将预定位区域的深度特征输入到深度森林的第1层级联森林中,对于Z分类问题该层级联森林输出Z维类特征向量并与深度特征聚合,得到新的特征向量,输入到下一层级联森林中,依次迭代,取最后一层级联森林输出类特征向量最大值所在类别为所跟踪目标的类别信息。
3 实验及分析
3.1 实验概述
为验证所提方法的有效性,在无人机航空影像数据集:UAV123数据集、VisDrone数据集和自研无人机航拍数据集上,对本文模型性能进行了评估。模型运行环境为Inter®CoreTMi9-9900K CPU、2080Ti GPU、内存为64 GB的台式机工作站上运行,操作系统为Ubuntu 18.04。
UAV123数据集[21]是国外学者Mueller在ECCV(European Conference on Computer Vision)会议上发布的无人机航空影像数据集,该数据集由123个无人机摄像头记录的影像组成,数据覆盖了多种场景,如公路、海滩、港口、田野、建筑物等,目标有行人、船只、汽车、飞行器和建筑物,图像尺寸为1 280×720,实验中的主要研究目标为车辆、船、人等。
VisDrone[22]数据集包含239个无人机视频片段,由各种无人机摄像头拍摄,场景类别众多,包括城市街道、公园、车辆、行人等,该数据集具有覆盖范围广、拍摄视角多变的特点。
自研无人机航拍数据集包含100个无人机航拍视频,覆盖场景类别包含乡村道路、城市街道、建筑工地、工程车辆、行人、树木、房屋等,图像尺寸为1 000×800。
通过重叠率、中心位置误差、精准度、成功跟踪率和曲线下方面积(Area Under Curve,AUC)对算法进行综合评估。重叠率为预测目标框和真实目标框的IoU;中心位置误差指预测目标框中心点与真实目标框中心点之间的欧氏距离;给定IoU阈值,IoU大于该阈值的视频帧数占总视频帧数的比率为跟踪成功率;给定中心位置误差阈值,跟踪精准度表示中心位置误差小于该阈值的视频帧数占总视频帧数的比率;跟踪精准度与跟踪成功率图的曲线下方面积用来评价跟踪算法的整体效果。
3.2 实验设置与参数优化
所提方法主要参数是通过大量试验取得的,所设计改进深度置信网络模型由4个受限玻尔兹曼机组成,约束项参数λ1=0.55,λ2=0.35,λ3=0.10,学习率η为0.01。
为探究不同参数对跟踪效果的影响,在自研无人机航拍数据集上,对参数取值问题进行了分析。
改进深度置信网络约束项参数验证范围为λ1={0.10,0.15,…,1.00}、λ2={0.10,0.15,…,1.00}和λ3={0.05,0.10},图5显示了保持其他超参数不变时,通过调整改进深度置信网络约束项参数设置,测试得到的跟踪精准度曲线下方面积,即AUC分数,可以看出改进深度置信网络的约束项参数取值变化对跟踪效果有一定影响,当λ1=0.55、λ2=0.35、λ3=0.10时,模型能够取得最好效果。
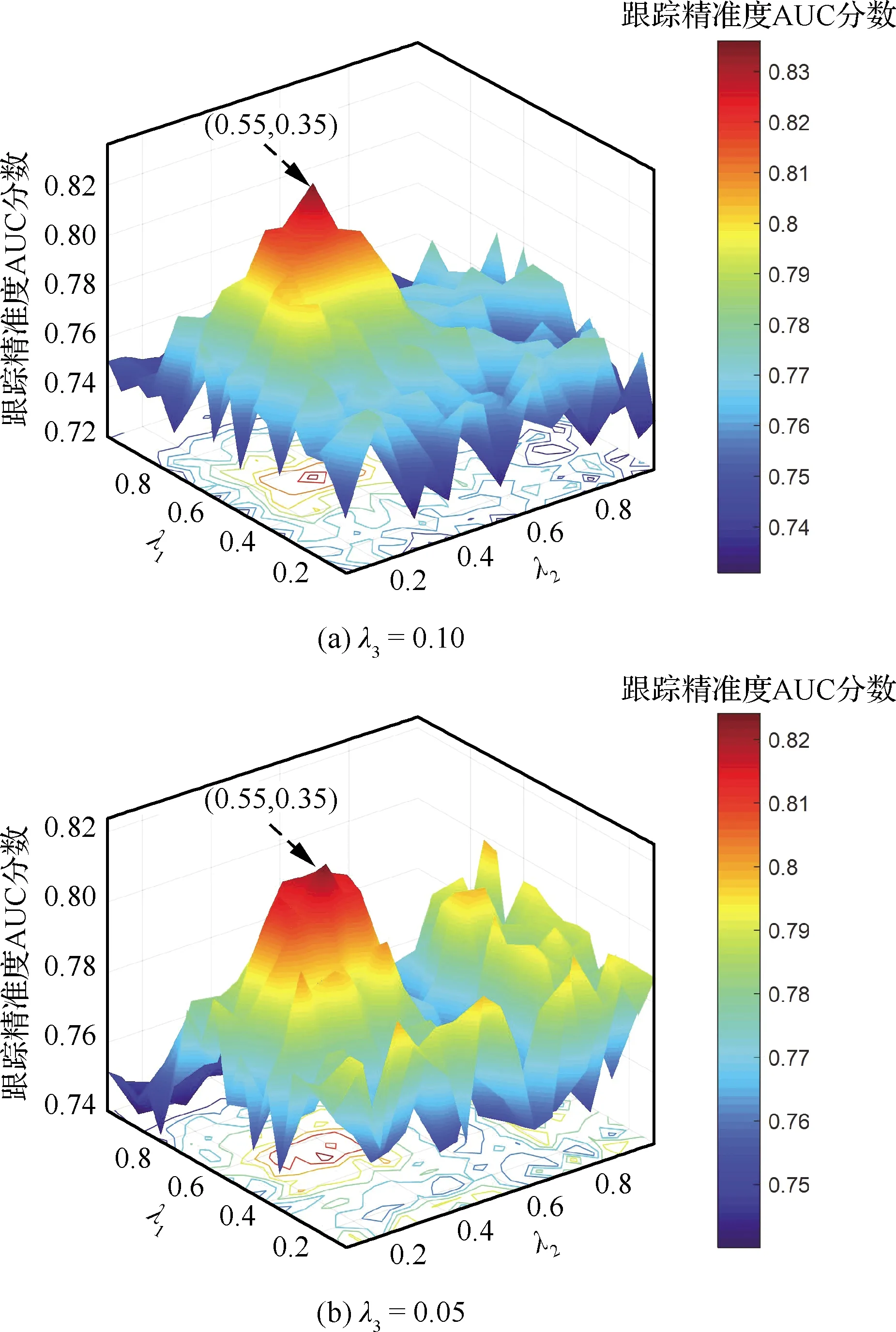
图5 约束项参数对跟踪效果的影响Fig.5 Influence of constraint parameters on tracking effect
进一步的,图6反映了受限玻尔兹曼机数量对跟踪性能的影响。当受限玻尔兹曼机数量较少时候,精准度AUC分数较低,原因是此时深度置信网络提取的特征表征能力较弱;当逐渐增加受限玻尔兹曼机个数时,AUC分数逐渐提高,当受限玻尔兹曼机数量大于4后,提升效果不再明显,说明使用4个受限玻尔兹曼机堆叠构成深度置信网络是本应用场景的最优配置。
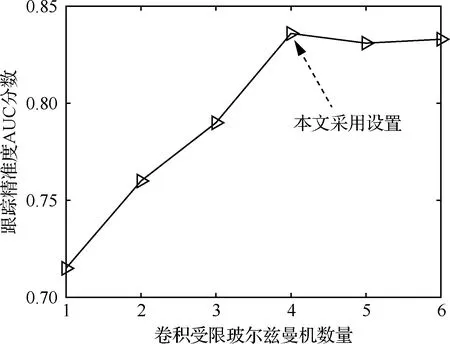
图6 卷积受限玻尔兹曼机数量对跟踪效果的影响Fig.6 Influence of number of convolution restricted Boltzmann machine on tracking effect
表1显示了学习率对目标跟踪效果的影响。当调整学习率过大时,精准度AUC分数会有所下降;当调整学习率较小的时候,可以有限地提高模型跟踪性能,但另一方面会使模型收敛速度太慢,降低效率。综合以上原因,改进深度置信网络模型采用的学习率为0.010。

表1 学习率对跟踪效果的影响Table 1 Influence of learning rate on tracking effect
3.3 消融实验分析
为论证本文方法组成模块对目标跟踪性能的影响,在自研无人机航拍数据集上展开了消融实验分析,表2为各组合模块在跟踪精准度曲线和跟踪成功率曲线的曲线下方面积,跟踪精准度曲线下方面积记为AUC1,跟踪成功率曲线下方面积记为AUC2。本文方法各模块标识如下:① ODBN(Optimized Deep Belief Networks)表示改进深度置信网络模块;② DDT(Deep Descriptor Transforming)代表深度特征变换,生成跟踪目标的预定位框;③ QL(Q-Learning)表示基于Q学习的搜索机制,用来精确跟踪目标位置,QL下标数字代表搜索机制所需前k步历史动作信息;④ DBN(Deep Belief Networks)代表标准深度置信网络模块,提供深度特征,该特征不具备旋转不变特性;⑤ DAE(Deep Auto Encoder)表示深度自动编码器模型,能够提取深度特征,与深度置信网络模型进行对照;⑥ SDA(Selective Descriptor Aggregation)为选择性特征符聚合算法,通过将特征符在深度方向加和,对所跟踪目标进行定位,用于和深度特征变换方法进行对比。最终采用的方案为ODBN + DDT + QL5。
表2的实验结果显示了各模块对跟踪效果的影响:① 相比于未添加旋转约束的深度置信网络,改进后的深度置信网络性能有较大提升,跟踪精准度AUC分数和跟踪成功率AUC分数分别提升8.2%和6.8%,说明改进深度置信网络具有较好的旋转不变性,能够适应无人机影像中跟踪目标旋转方向的变化;② 与深度自动编码器提供压缩后的特征相比,标准深度置信网络模型提供的深度特征更具丰富性,精准度AUC分数提升了5.2%,成功率AUC分数提升了5.8%;③ 在使用选择性特征符聚合算法代替深度特征变换算法的情况下,跟踪效果呈现一定程度的下降,精准度AUC分数和成功率AUC分数分别下降11.5%和10.1%;④ 在不使用Q学习搜索机制进行精确定位的情况下,跟踪效果下降,精准度AUC分数和成功率AUC分数分别下降15.3%和12.7%;⑤ 进 一步测试了Q学习搜索机制中历史动作数量对算法整体效果的影响,当仅采用前1步历史动作信息时,AUC1和AUC2分数分别为71.9%和57.1%;当采用前3步历史动作信息后,跟踪效果有较大提升,AUC1和AUC2分数分别提升为78.2% 和64.0%;采用前7步历史动作信息与5步 历史动作信息相比,跟踪效果已无明显提升,因此采用前5步历史动作信息为Q学习搜索机制的最佳方案。消融实验分析表明,所提方法各模块之间组合紧密,能够有效提升无人机影像目标跟踪的效果。

表2 消融实验的ACUTable 2 ACU of ablation experiment
3.4 实验结果与分析
为验证所提方法有效性,选取UAV123数据集、VisDrone数据集和自研数据集中的视频数据作为测试数据集,对所提方法进行测试,并与当前目标跟踪领域内的一些主流方法(UPDT[23](Unveiling the Power of Deep Tracking)、CFnet[24](Correlation Filter networks)、SiamFC[11]、ECO[25](Efficient Convolution Operators)、EAST[26](Efficient and Accurate Scene Text Detector)、SRDCF[10]、KCF[8]、ADT[27](Adversarial Deep Tracking)、ATOM[28](Accurate Tracking by Overlap Maximization)、KCFYOLO[29](Kernelized Correlation Filters You Only Look Once))进行比较。其中KCF算法、KCFYOLO算法和SRDCF算法为基于相关滤波器的跟踪算法,UPDT算法、ADT算法、ECO算法和EAST算法是基于深度学习的目标跟踪算法,SiamFC算法、CFnet算法和ATOM算法采用了孪生网络结构。图7展示了上述部分算法在不同视频序列里的比较实验结果,深度森林输出的目标类别信息与类别概率记录在图片下方。

图7 目标跟踪效果Fig.7 Demonstration of tracking results
图7(a)为工程车序列,目标在不同视频帧下存在着旋转角度变化和部分尺度变化,可以看出本文方法能够一直精准定位跟踪到目标,具有良好的旋转不变性。在31帧之后,工程车辆旋转角度发生变化,ECO和KCF算法不能提取目标旋转方向的特征,发生偏移和目标跟丢现象。
图7(b)为船只序列,目标在不同视频帧下存在着旋转角度变化、视角变化和尺度变化,通过提取目标旋转方向信息和深度特征,能够自适应场景环境变化,使跟踪框和目标的真实位置基本重合。
图7(c)为小型车辆序列,目标从127~825帧存在遮挡情况、尺度变化和地面环境变化。EAST、SRDCF和KCF算法在环境发生变化以及目标遮挡情况下出现目标丢失;UPDT和SiamFC算法虽然可以定位目标,但是没有对目标遮挡情况进行优化,所得目标框要大于目标真实框,丢失大量正样本信息,发生目标框偏移情况;本文方法在训练过程中,通过数据扩增技术产生大量具有遮挡信息的训练样本,使得本文方法在遮挡环境下能够精确检测到目标,具有良好的鲁棒性。
图7(d)为行人序列,目标发生光照变化、部分遮挡以及周围环境有相似目标,增加了跟踪难度。本文方法通过深度置信网络提取具有强表征能力的目标深度特征,通过搜索机制模型获取目标定位信息,能够有效跟踪目标的移动情况,提供精准跟踪检测结果。
为验证所提方法针对形态变化的鲁棒性,采用平均重叠率和平均中心误差率作为评价指标对不同形态变化的场景进行定量分析,表3和表4分别为本文方法与其他方法在不同视频场景下的平均中心误差和平均重叠率,视频场景包括目标旋转、遮挡、尺度变化、目标快速移动、视角变化、光照变化和背景干扰;图8和图9使用成功跟踪率和精准率指标评价目标跟踪方法在UAV123数据集和VisDrone数据集上的整体表现。从表3和表4中看出,相比于其他10种常用方法,本文方法在目标形态变化场景下取得了较好的平均重叠率和平均中心误差率,从图8和图9可以看出,本文方法取得了最好的目标跟踪效果,主要原因是通过数据扩增提高了样本多样性,使用改进深度置信网络模型提取强表征能力的深度特征,采用基于Q学习的搜索机制进一步精确目标跟踪结果,使模型对无人机影像视频的跟踪检测能力更具有鲁棒性。
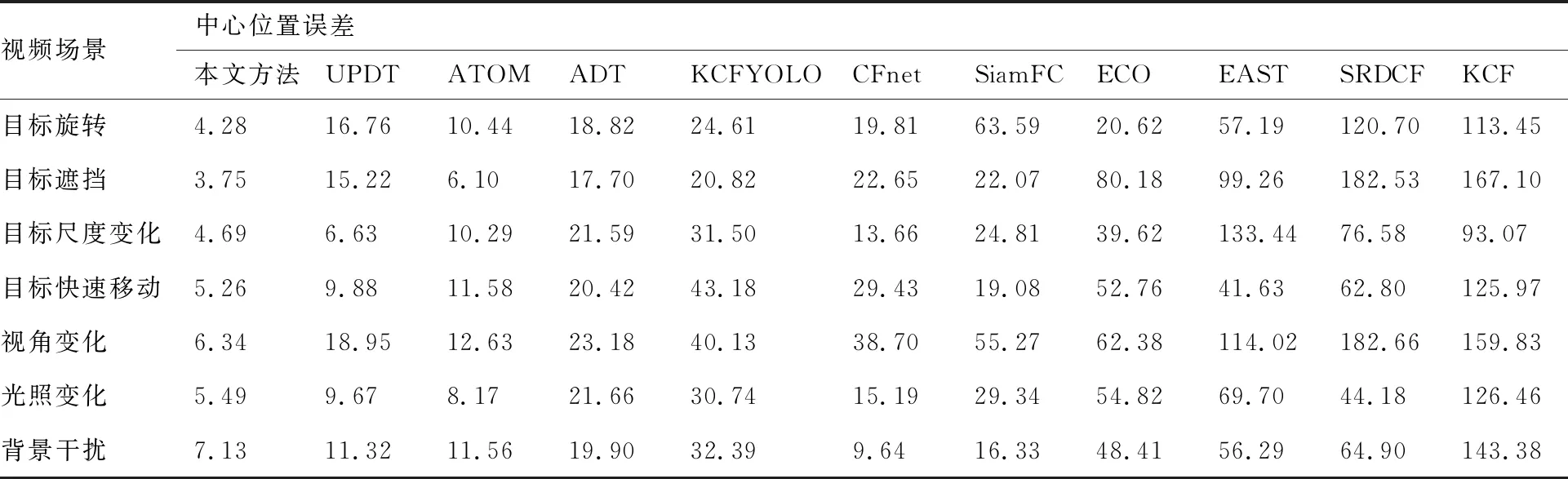
表3 平均中心位置误差Table 3 Mean error of center position

表4 平均重叠率Table 4 Average overlap rate
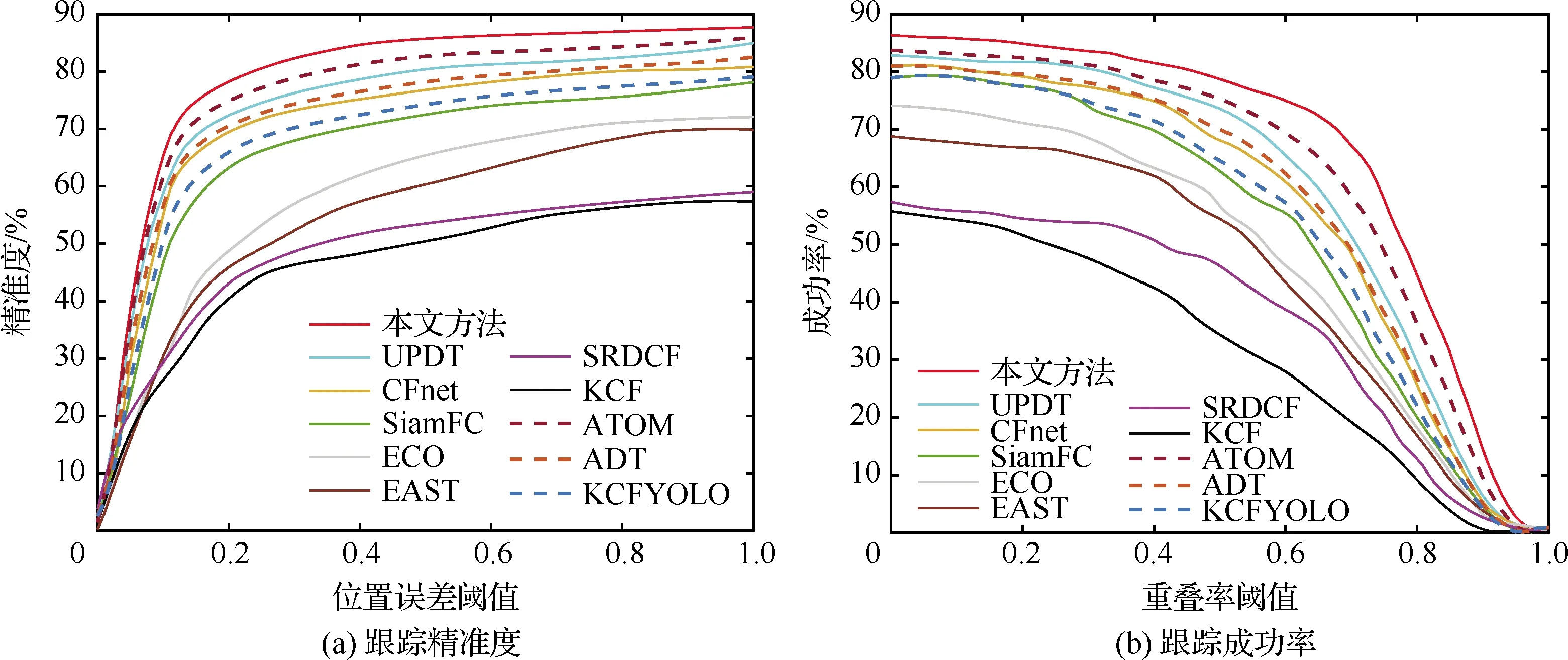
图8 在UAV123上的整体效果Fig.8 Overall performance on UAV123
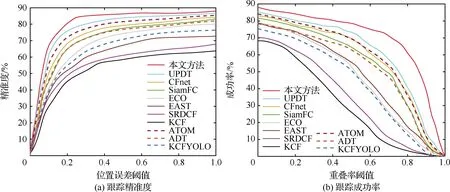
图9 在VisDrone上的整体效果Fig.9 Overall performance on VisDrone
3.5 深度森林分类特性评估
使用深度森林分类器对所跟踪的目标进行分类,为进一步验证深度森林算法提供类别信息的准确度,对深度森林分类特性展开评估分析。
对于常见的无人机影像跟踪目标类别,图10展示了深度森林学习得到的类特征向量与使用随机森林提取的类特征向量的可视化对比。采用KPCA[30](Kernel Principal Component Analysis)技术依次提取深度森林和随机森林学习得到的类特征向量的前2个主分量,然后绘制主成分的散点图,如图10所示,其中KPCA1和KPCA2依次为第1主分量和第2主分量。实验结果表明,相比于随机森林模型,深度森林模型能够有效提取不同类别无人机影像跟踪目标的类特征向量,主要原因是深度森林模型能够从输入数据中学习到目标最具代表性的类别信息特征,从而准确提供目标类别信息。

图10 类特征向量可视化Fig.10 Visualization of class feature vector
3.6 算法复杂度分析
对所提方法的时间复杂度进行记录,如表5所示。本文方法的速度为12.6帧/s,当不使用深度森林模型时,本文方法速度为14.8帧/s,具有较好的实时性,均能满足实际场景应用需求,计算负荷主要集中在深度特征提取方面,后续将在保证算法精确度的同时在进一步提高该算法运行效率方向进行研究。
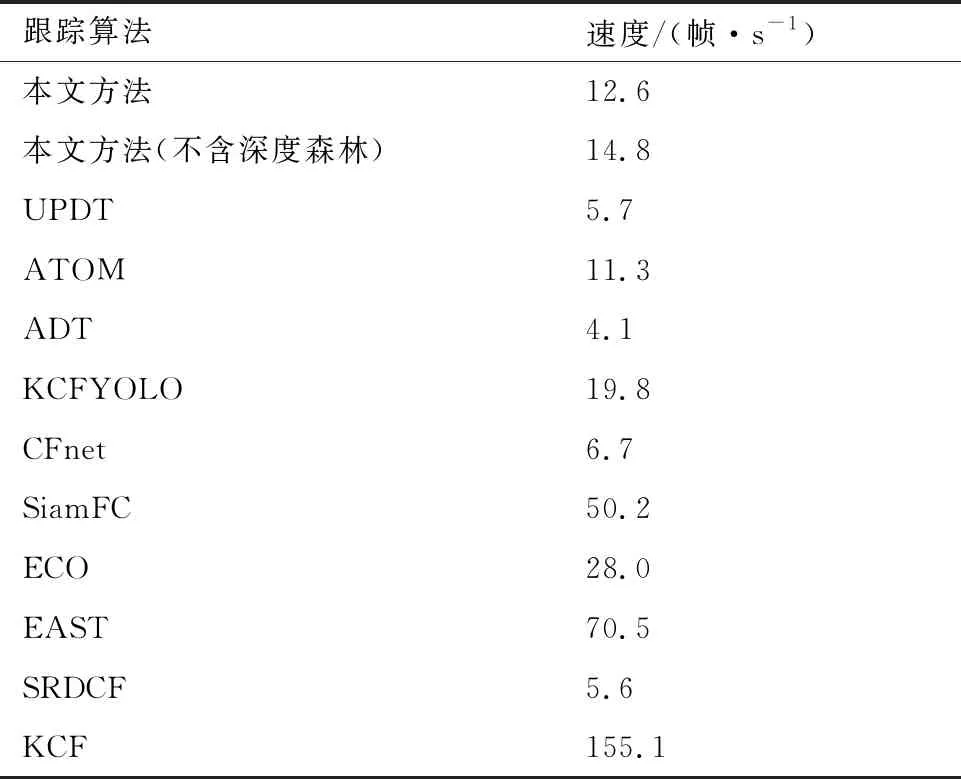
表5 算法时间复杂度Table 5 Time complexity of algorithm
4 结 论
针对无人机影像目标跟踪过程中常出现目标旋转、遮挡等形态变化,以及训练样本多样性不足等问题,提出了一种基于形态自适应网络的无人机航空影像目标跟踪方法。通过数据扩增提高训练样本数据多样性,扩增模型对目标形态变化的覆盖范围;使用改进深度置信网络获取无人机影像中具有强表征能力的深度特征,通过预定位方法和精确定位方法相结合的方式,可以在保证算法实时性的同时,更好地挖掘目标表征信息,实现对目标宽高比变化的自适应调整,有效定位无人机影像数据中的目标所在区域,提高算法对目标形态变化的适应能力和影像背景环境变化的鲁棒性;采用深度森林模型提取类别信息,获得高精度的目标跟踪结果。在UAV123数据集、VisDrone数据集和自研无人机航拍数据集上展开了对比实验,同其他10种常用目标跟踪算法进行比较,本文方法在跟踪成功率、精准度、平均重叠率、平均中心位置误差等评价指标上取得了最好的效果。在多种目标跟踪场景下进行了测试,所提方法能够有效适应无人机影像中目标出现的形态变化情况,在跟踪准确性、稳定性和鲁棒性方面具有优异的整体性能。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小学生学习指导(低年级)(2021年12期)2021-12-31
阅读与作文(英语初中版)(2019年8期)2019-08-27
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年6期)2019-05-28
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
