
基于内容与协同过滤的GitHub学习资料库推荐
2021-07-03 05:56:06李晓娴余娇榕徐海平
河南工程学院学报(自然科学版) 2021年2期
李晓娴,游 佳,余娇榕,林 倩,徐海平
(闽江学院 数学与数据科学学院,福建 福州 350108)
GitHub是全球最大的代码托管服务平台,平台上有不少优质有趣的开源应用及项目。在开源环境下,用户通过GitHub既可以参与别人的开源项目,也可以让别人参与自己的开源项目,但在众多项目中,想找到自己感兴趣的是一件费时费力的事情。在大数据时代,信息技术的迅速发展提升了信息的丰富度,使用户获取信息越来越便捷,但数据增长过快非常容易引发信息过载[1],严重降低了用户和信息提供者之间的供需效率。用户在海量的数据中很难找到真正需要的信息,而信息提供者则因不清楚用户的需求和兴趣而无法提供更优质的内容。
推荐系统作为一种有效代替主动搜索技术的信息过滤系统,可以与搜索引擎在应对信息过载问题上形成技术互补[2]。与搜索引擎相比,推荐系统不需要用户描述自己所需要的信息,而是通过充分挖掘用户潜在的兴趣偏好,进而主动向用户提供与其兴趣相契合的个性化信息或服务。推荐系统还可以通过不断积累的用户行为信息捕捉到用户的兴趣变化,然后根据用户的兴趣变化相应调整推荐结果,从而为用户提供更精准、更智能的个性化服务。
本研究在GitHub平台上设计出了基于协同过滤的学习推荐系统[3],可让目标用户在GitHub平台上多方位地找到实用的工具和资源。该推荐系统利用GitHub的API来获取目标用户已经标星的学习资料库,然后得到这些资料库的全部创始作者,再挖掘出这些创始作者加星的资料库,与用户加星的资料库形成相似度对比,来寻找有相似兴趣的新用户,并把相似的资料库推荐给寻找到的新用户,从而形成推荐用户感兴趣的学习资料库。这样,可方便用户发现与自己兴趣相似的学习资料库。基于内容的推荐算法是对目标用户加星学习资料库的简介描述进行分词分析,创建一个特征集来实现基于内容的推荐,但它只从目标用户的学习资料库描述简介分词中取关键词进行分析,只能推荐用户看过的同类内容,不能对其他的相似内容进行推荐。本研究选择在其他用户的学习资料库简介分词中取关键词来创建一个特征集,以实现学习资料库的推荐。基于用户的协同推荐和内容推荐的混合推荐算法可辐射到全部用户的学习资料库,让目标用户有了更多的选择。
1 数据来源
本研究数据是在目标用户的GitHub平台上用Python软件的requests库获取的。首先,把目标用户中加星用户的学习资料库网址爬下来,可以观察出这些网址里面包含用户名,再把用户名解析出来,组成一个列表。然后,从这些用户中找到相应的加星学习资料库网址和简介描述,形成DataFrame表。其中,自己加星的学习资料库有62条,解析里面的用户名并去重,发现没有重复的用户名,则目标用户加星的作者有62个。其他用户的学习资料库和学习资料库简介描述共8 597条,去重后还有7 009条。
2 学习资料库推荐方法
现有推荐方法的推荐内容质量不高,准确度也达不到用户的要求。为了使推荐内容和准确度能够满足用户的要求,本研究提出混合推荐系统。该推荐系统是将基于用户的协同过滤算法和基于内容的推荐算法进行结合,目的是推荐最符合用户要求的学习资料库。
学习资料库的推荐流程是借助用户登入GitHub,在目标用户里面对自己喜欢的学习资料标星,通过这些标星的学习资料找到对应的作者,再获取这些作者的标星资料库。对资料库简介描述进行jieba分词分析,用Counter分析出全部资料库的分词数量,进行降序排列,取前面8个最热门的关键词形成特征,然后形成混合推荐发给目标用户。
推荐算法在机器学习还没有兴起时就已经在应用了。传统的推荐算法一共有3种[4],本研究使用的是其中两种,即基于用户的协同过滤算法(user-based collaborative filtering)[5]和基于内容的推荐算法(content-based recommendations)[6]。
2.1 基于用户的协同过滤算法
基于用户的协同过滤算法的原理是依据目标用户的兴趣去寻找兴趣相似的用户群体,然后计算目标用户与其他用户群体之间的相似度,选取与目标用户最相似的几个用户群体,最后将这些用户群体喜欢的且与之不同的项目推荐给目标用户。这个算法基于如下假设:两个用户共同偏好的项目越多,这两个用户的兴趣偏好就越相似;一般用户都会喜欢与其兴趣相似的用户喜欢的项目。
本研究把目标用户加星的学习资料库里的作者作为兴趣相似的用户群体,然后用Pearson相关系数法计算用户与其他用户的相似度,把相似度高的用户群体的学习资料库推荐给目标用户。
(1)寻找相似用户
利用目标用户标星的学习资料库找到作者标星的学习资料,形成学习资料库,这些作者从而成为兴趣相似的其他用户群体。首先从用户群体中剔除同一作者,把目标用户所标星的学习资料与其他用户群体标星的学习资料构成矩阵;然后用Pearson相关系数来衡量这两个数据集之间的相似性;最后把这些相似度以降序方式排序,选取前3个最相似的用户群体进行学习资料库推荐。
(2)Pearson相关系数法
Pearson相关系数法[7]是余弦相似度在维度值缺失情况下的一种改进。把缺失的维度都填上数字0,然后让其他维度减去这个向量各维度的平均值,这样的操作叫中心化。中心化之后所有维度的平均值是0,满足进行余弦计算的要求,再进行余弦计算得到结果。这样先中心化再进行余弦计算得到的相关系数叫Pearson相关系数。
Pearson相关系数公式[8]一般是由总体相关系数r定义两个随机变量X、Y之间的协方差和两者标准差乘积的比值,即
(1)
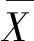
表1给出了目标用户与排名前5位用户之间的相似度。第一个完美相似的用户是自己,往下排相似度逐渐降低。取相似度前3名的用户ID为0、57和29,把这3个用户中两两相同的学习资料库形成推荐,推荐给目标用户。
从表1中可发现相似度较低,对比目标用户与最后5位用户之间的相似度(表2),目标用户与其他用户之间相似度的正相关系数相对较大,说明实验是有效的。
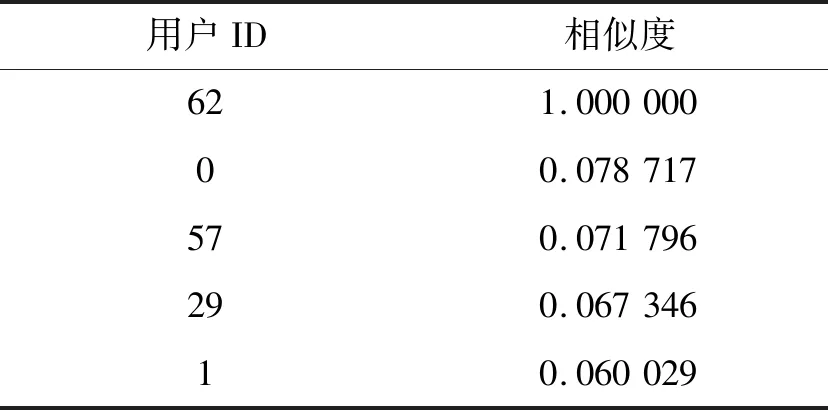
表1 目标用户与前5位用户之间的相似度Tab.1 The similarity between the target user and the top five users
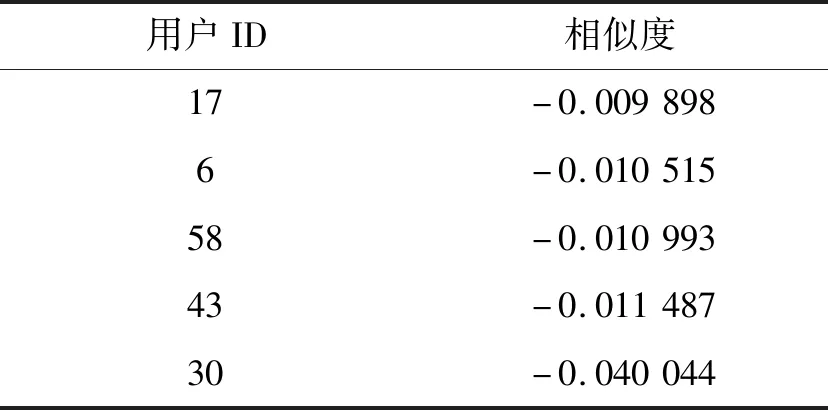
表2 目标用户与后5位用户之间的相似度Tab.2 The similarity between the target user and the last five users
2.2 基于内容的推荐算法
基于内容的推荐算法,其主要思想是先给商品划分一些属性,然后在用户看某个商品的时候,给他推荐一些同类属性的商品。
首先利用GitHub爬取其他加星用户的学习资料简介描述;然后使用jieba中文分词工具对加星学习资料库的简介描述进行分词分析[9],对分析出来的学习资料库信息进行过滤,创建一个特征集,实现基于内容的推荐;最终为目标用户推送适合用户阅读的学习资料库[10-11]。
(1)jieba中文分词工具
目前使用较广泛的分词工具是jieba中文分词工具。分词的原理是基于前缀词典高效的词图扫描,生成句子中汉字所可能构成的有向无环图(DAG),采用动态规划查找最大概率路径,找出词频的最大切分组合,对于未登入词采用基于汉字成词能力的隐马尔可夫模型(Hidden markov model,HMM),使用Viterbi算法[12]。
本研究的资料库内容简介描述见图1。在分词的过程中,观察图1发现,中文的文本信息中有标点符号、停用词、语气词和助动词等,英文文本中有介词、人称代词和提问词等,这些无意义的词会妨碍关键字的提取,所以需要删除。从网站上下载这些停用词放在一个文本中,然后对全部内容进行停用词去除。图2显示的是去除停用词后的简介描述。

图1 未去除停用词的学习资料库简介描述Fig.1 A brief description of the learner database with prohibited words

图2 去除停用词后的学习资料库简介描述Fig.2 A brief description of the learner database without prohibited words
(2)Counter统计单词数
Counter是 colletions的一个类,Counter类的目的是跟踪值出现的次数,可以理解为一个简单的计数器,用来统计字符出现的次数。它是一个无序的容器类型,以字典的键值形式存储,其中元素作为key、计数作为value。计数值可以是任意的Interger(包括0和负数)。
图3是目标用户学习资料库简介描述分词的排序。由于目标用户加星的学习资料库较少,才62个,所以只能取前5个关键词与全部学习资料库进行匹配推荐给目标用户。图4是其他用户学习资料库简介描述分词的排序,取前8个关键词与全部学习资料库进行匹配推荐给目标用户。从图3和图4中可以看出,排在第一的都是“python”,说明目标用户与加星的其他用户的兴趣是相似的。

图3 目标用户学习资料库简介描述分词排序Fig.3 Target users learning database profiles that describe word sorting

图4 其他用户学习资料库简介描述分词排序Fig.4 Other users learning database profiles to describe participle sorting
(3)正则表达式
正则表达式是一个特殊的字符序列,它方便检查一个字符是否与某种模式匹配,可以测试字符串内的模式、替换文本和基于模式匹配从字符串中提取指定字符串。
本研究用re模块的re.match函数对简介描述进行内容匹配。re.match函数只匹配字符串的开始,如果字符串的开始不符合正则表达式,则匹配失败,函数返回None。所以一开始关键词的标签都设置为数字0,如果匹配成功则返回数字1。
3 混合推荐
从前面的介绍可知,如果单独使用一种算法进行推荐,那么推荐的学习资料库不够全面。本研究把基于用户的协同过滤算法和基于内容的推荐算法结合形成混合推荐,以解决学习资料库推荐不够全面的问题[13]。
混合推荐首先对全部用户的学习资料库描述简介分词取关键词,对关键词进行排序。本研究取排序前8位的关键词进行对应的学习资料库匹配,然后利用基于用户的协同过滤算法进行学习资料库的推荐。这样的混合推荐可辐射到全部用户和学习资料库,让目标用户有了更多选择。
4 实验结果
本研究利用基于用户的协同过滤算法和基于内容的推荐算法进行混合推荐,推荐出与目标用户兴趣最相似的学习资料库,推荐出的最优学习资料库方便目标用户进行查阅,不受其他学习资料的干扰,可直接在推荐列表中找到,节省了目标用户的时间,也让目标用户得到了最具个性化的推荐。
基于用户的协同过滤推荐见表3。其中,第一列为学习资料库,数字“1.0”表示其他用户加星的学习资料库,数字“0.0”表示没有加星的学习资料库,每个学习资料库至少有2个用户加星。表3中只有2个推荐,所以仅基于相似用户的推荐会发现推荐的学习资料库范围不够大,只能局限于相似用户加星的资料库。

表3 基于用户的协同过滤推荐Tab.3 User-based collaborative filtering recommendations
基于内容的推荐算法一共有24个推荐,这里选取前10个推荐,见表4。表4的第一列为学习资料库,数字“1.0”表示学习资料库有相应的关键词,数字“0.0”表示学习资料库没有相应的关键词,每个学习资料库至少有两个关键词。关键词“机器学习”“python”和“算法”是相似的,一起推荐的学习资料库内容比较准确。可以发现,基于内容的算法进行推荐比基于用户的协同推荐效果好,推荐的学习资料库比较多。
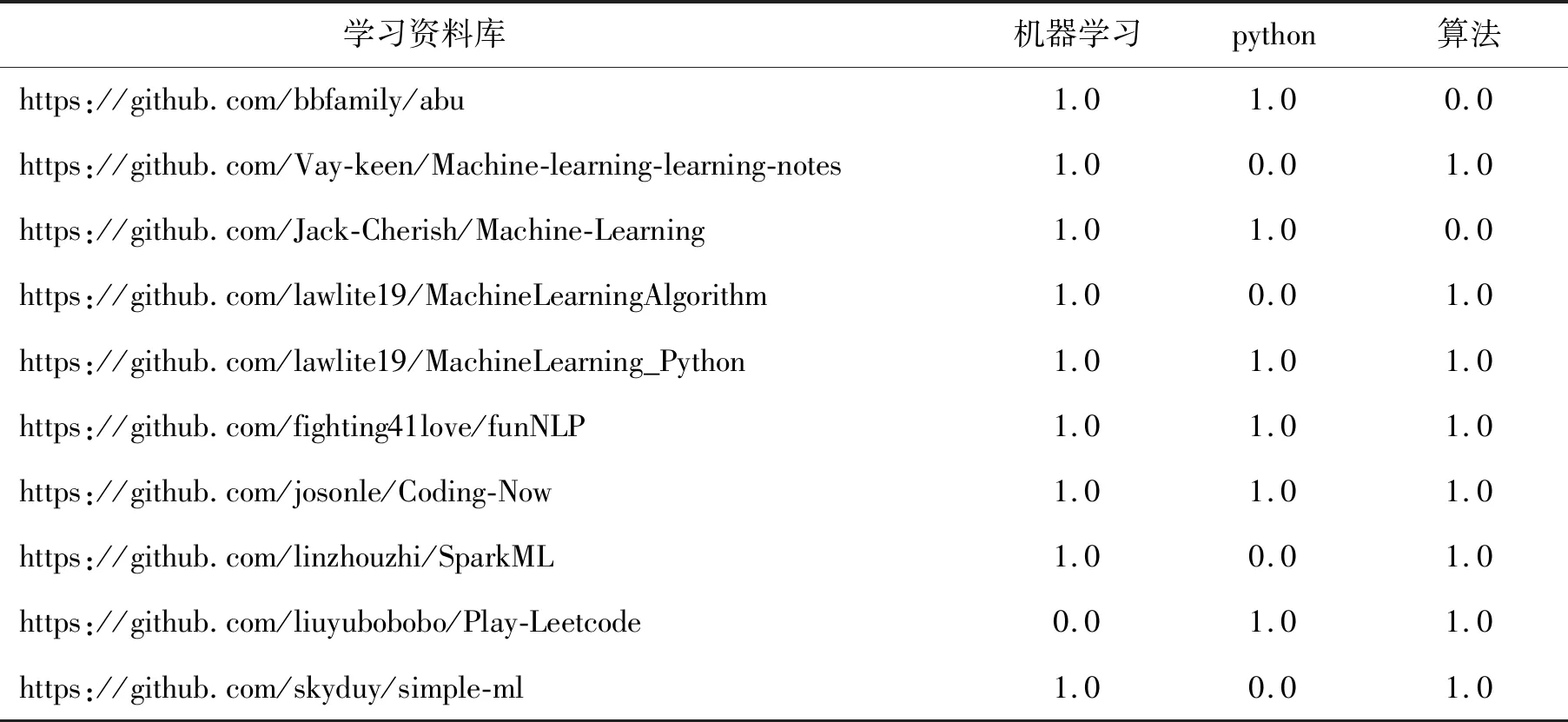
表4 基于内容的推荐算法Tab.4 Content-based recommendations
在前面的基础上,可以从两方面考虑目标用户需要的兴趣相似的学习资料,而不是仅从一个方面推荐,从而实现个性化推荐,具体见表5。混合推荐的结果一共有121个,表5选取了前10个学习资料库进行推荐,第一列为学习资料库,数字“1.0”表示学习资料库有相应的关键词,数字“0.0”表示学习资料库没有相应的关键词,每个学习资料库至少有两个关键词。从关键词“framework”“web”和“js”可以判断出该内容是与网页制作有关的学习资料库,从而实现了高质量的学习资料库推荐。
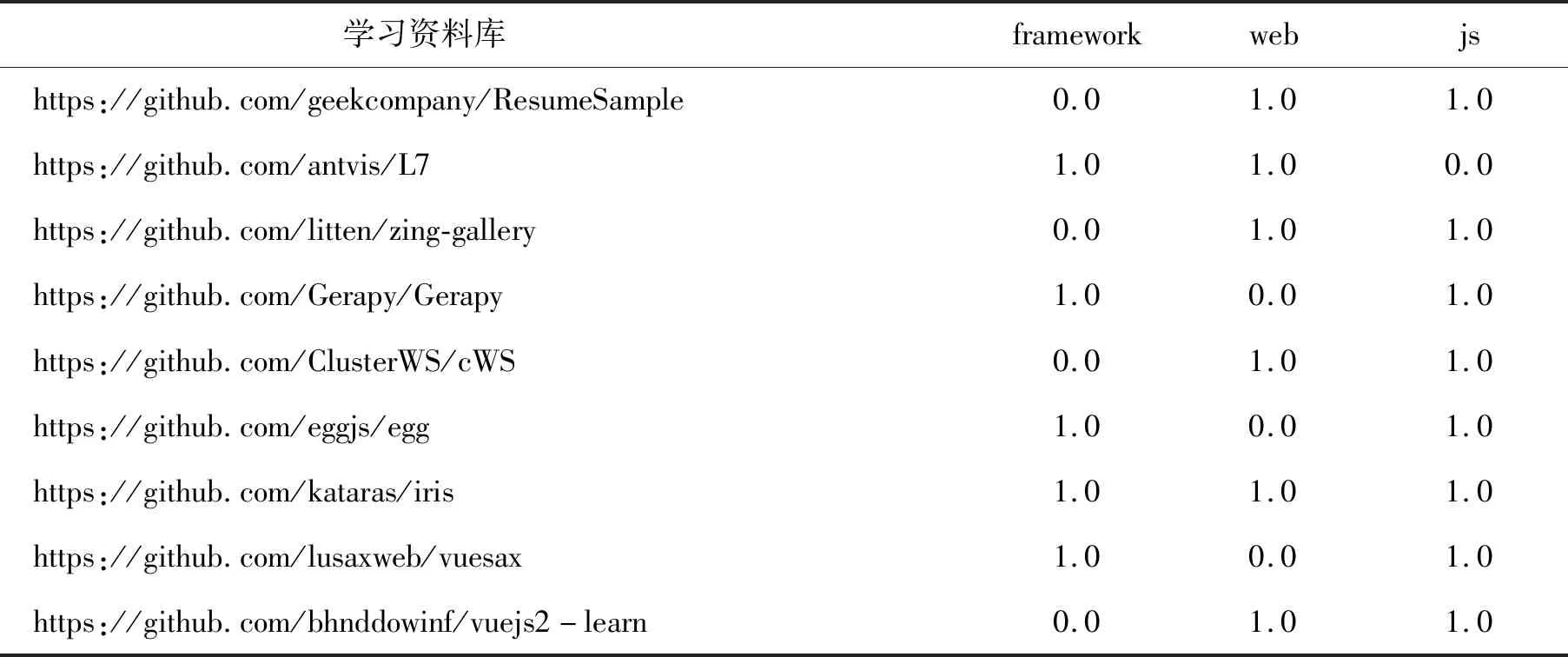
表5 基于内容与协同过滤的混合推荐Tab.5 Content-based and collaborative filtering recommendations
5 结语
为了实现推荐的学习资料库与目标用户兴趣最相似这一目标,基于用户协同过滤提出了基于内容推荐与协同过滤算法的GitHub学习资料库推荐,并对算法进行了验证。结果表明,该推荐考虑到了目标用户的需求,节省了目标用户的时间,使目标用户得到了最具个性化的推荐。
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
汉字汉语研究(2020年2期)2020-08-13 07:52:38
天津科技(2020年5期)2020-01-08 12:27:35
智富时代(2019年6期)2019-07-24 10:33:16
汽车观察(2019年2期)2019-03-15 06:00:50
中文信息(2016年12期)2017-05-27 07:40:17
高中生·天天向上(2016年9期)2016-11-22 09:10:34
中国卫生(2016年5期)2016-11-12 13:25:26
生物进化(2014年2期)2014-04-16 04:36:26
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
