
基于生成对抗网络的OCT 图像去噪方法
2021-07-03 03:52贺玉华杨明明
现代计算机 2021年12期
贺玉华,杨明明
(四川大学计算机学院,成都610065)
0 引言
光学相干断层扫描(Optical Coherence Tomography,OCT)[1]是一种极有潜力的生物医学光学成像技术,由于其具有无接触、扫描速度快和超高分辨率的特点而被广泛应用于眼科。然而,OCT 图像中含有大量的散斑噪声,散斑噪声会掩盖细微并且很重要的图像特征,最终影响临床诊断。因此,去除OCT 图像中的斑点噪声对于提高图像质量和临床诊断来说有很重要的意义。
近年来,为了有效地去除SD-OCT 中的斑点噪声,基于块匹配[2-4]、稀疏字典学习[5]、偏微分方程[6],以及基于其他理论的多种算法相继被提出。Buades 等人[2]提出的非局部均值滤波算法(Non-Local Means,NLM)应用在自然图像上去噪并取得了很好的效果,但对OCT图像去噪来说并不适用,因此,研究者提出了很多改进的非局部均值算法[3],但这些方法往往会使图像变模糊。在非局部均值算法的基础上,Chong 等人[4]提出了块匹配三维过滤(Block-Matching and 3D filtering,BM3D)算法,其原理是对匹配的相似块进行协同过滤来进行去噪,但在抑制噪声的同时可能会引起图像边缘的失真。Esmaeili 等人[5]提出了一种改进的基于KSVD 的字典学习算法,其原理是学习含噪图像数据和不含噪图像数据之间的字典,并通过不断更新字典使得去噪图像逼近不含噪的图像,但该算法对字典太过依赖。Puvanathasan 等人[6]提出了一种基于偏微分方程的各向异性扩散方法,该方法虽然能够在去除噪声的同时保留图像细节甚至增强边缘,但其结果往往过于平滑。这些算法在OCT 去噪上都存在一些缺点:过度模糊或平滑图像,噪声的去除不够彻底或者在去噪结果中引入了伪影。总之,这些算法在去噪和保留原图细节之间很难达到平衡状态。
目前,深度学习已经在多种成像应用中取得了巨大成就,从低级任务到高级任务,例如图像去噪[7-8],去模糊[9]和超分[10]到分割[11],检测和识别。它模仿了人类处理信息的方式,并通过分层网络框架从像素数据中提取高级特征[12]。Wei 等人[13]首次将聚类的卷积神经网络应用于OCT 图像去噪。Song 等人[14]提出了一种基于ResNet 的方法,可以在提高信噪比的同时保留细节特征。Ma 等人[15]提出了一种基于wasserstein 生成对抗网络(wGAN)的方法。
由于条件生成对抗网络(cGAN)[16]在图像生成和风格迁移等图像任务上有着良好表现,我们觉得也可以将图像去噪问题视为图像到图像的转换问题,并提出了一种基于条件生成对抗网络(cGAN)的改进方法来实现这一目标。用有噪声的图像和无噪声的图像对进行训练,并在生成器和鉴别器的相互竞争下,来实现去噪的目的。
1 cGAN模型简介
1.1 cGAN原理
生成对抗网络(Generative Adversarial Network,GAN)的原理是:生成器负责学习从输入到真实数据的映射,生成与之相似的数据;而判别器负责对生成数据进行判断,判断其属于还是不属于真实数据;判别器再将其判断结果反馈给生成器,进而激励生成器生成更加相似的数据,在这个过程中判别器也需要不断提高自己的判别能力。总之,生成对抗网络的原理是生成器和判别器通过相互竞争,最终到达一种平衡状态。但是对于无条件的生成网络来说,生成数据的模式无法被控制,为了解决这一问题,条件生成对抗网络(con⁃ditional Generative Adversarial Network,cGAN)应运而生,其原理是向生成器和判别器中加入约束信息来指导数据生成过程,使得生成器生成的数据是我们所期望的数据而不是为了欺骗判别器而得到的数据。
1.2 损失函数
cGAN 通过输入图像x和随机向量z学到目标图像y,即G:{x,z}→y,然后将生成的图像和目标图像分别输入到判别器进行打分。对于生成器来说,希望生成更加真实的样本可以骗过判别器,而对判别器来说,希望能够尽可能地区分真实样本和生成样本,即判别器对真实样本的打分尽可能高,而生成样本打分尽可能低。对抗损失函数表达式如下:
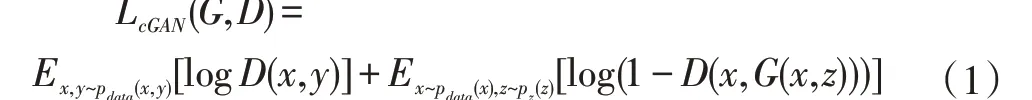
其中,x 是输入的含噪声的图像,y 是与x 对应的不含噪声的图像,z 是随机向量。
为了使生成的图像与目标域图像尽可能相似,我们可以将生成图像和目标图像之间的L1 或L2 距离加入到损失函数中。由于L2 距离会使图像模糊,我们采用L1 距离来衡量真实的不含噪声图像和生成的去噪图像之间的差异。其目标函数如下:

2 网络结构
2.1 生成器结构
本文使用的生成器基于文献[17]提出的网络架构,该网络结构在医学CT 图像去噪中展示了很好的性能,该网络是基于Encoder-Decoder 的网络结构,在此基础上,增加了三个快捷连接,将卷积层的特征图和对应的反卷积层的特征图相加,其结果作为下一个反卷积层的输入,其目的是使该网络可以保留更多的图像特征。生成器的网络结构共包含14 层,卷积层和反卷积层各七层,每一层之后都使用了ReLU 激活层。所有卷积层和反卷积层的卷积核大小均为3×3,步长均为1。除了输入和输出,中间层的特征图个数均为64。该生成模型的输入输出均为单通道OCT 图像,可以接受任意大小的图片输入。
2.2 判别器结构
判别器采用PatchGAN 结构[18],其作用是判断输入图像的真假。其网络结构一共有七层,其中奇数卷积层的步长为1,其余为2,所有卷积核大小都是4×4。根据从第一卷积层到最后一个卷积层的顺序,其特征图个数分别是64、64、128、128、256、256 和1。除了第一个和最后一个卷积层,每个卷积层后都使用了批处理归一化(BN)层和斜率为0.2 的Leaky ReLU 激活层。由于将BN 层用于所有层会导致生成图像结果振荡和模型不稳定,所以第一个卷积层后只使用leaky ReLU激活层。
3 实验与结果分析
3.1 数据集
本文采用的OCT 数据集来自文献[18],其中包括28 对分辨率为450×900(高×宽)的合成图像,该图像对是通过从28 位受试者的28 只正常或异常眼睛中捕获的高分辨率图像进行二次采样而生成的。更具体地说,在每个图像对中,含噪声的图像是由OCT 设备(Biopitgen)直接采集的(B-scan),无噪声的图像是通过配准和平均在同一位置获得的多个B-scan 图像而得到的,也就是说无噪声的图像是由在同一位置采集的多张含噪声图像经过配准和平均所得。
在实验中,我们丢弃了两对非常差的图像,并使用剩余的26 对图像进行实验,其中随机选择了十对图像用于训练模型,其余的用于测试。由于训练模型需要大量的数据,因此我们将这十对图像进行滑动剪裁,每隔8 个像素点裁剪一张分辨率为64×64 的图像,最后数据量大约为一万多张。
3.2 参数选择
在实验中,软件环境操作系统为Windows 10,深度学习软件框架为TensorFlow 1.14,GPU 为NVIDIA GTX 1080,内存为8 Gb。在训练时,我们的生成器和判别器都使用了Adam 算法进行优化,学习率为0.0002。加权参数a的值设为10。
3.3 实验分析
本实验分别采用K-SVD 模型、BM3D 模型、wGAN模型和本文模型在测试集上进行测试。为了客观说明本文模型的性能,对于BM3D 和K-SVD 模型,其参数按照取的最优降噪效果去设定,对于其他模型,其参数与提出该方法的参考文献中的参数保持一致。所有型的降噪结果如图1 所示。由实验结果可见,本文模型对OCT 图像的降噪效果在视觉上整体优于其他模型。为了更清晰地展示各模型的降噪结果,图1 对局部细节进行了放大。可以看出,经BM3D 和K-SVD 模型处理过的图像在视网膜层内部和边界处存在条形伪影,视觉效果较差,其中,K-SVD 模型并未完全去除噪声,BM3D 引入了块状伪影。wGAN 模型有效去除了斑点噪声,增强了图像的对比度,但是存在明显的边缘模糊和细节丢失的现象。采用本文模型去噪后的图像,保留了更多的边缘信息和细节信息,得到的结果与校准无噪声的OCT 图像更加接近,并且具有更加理想的视觉效果。
为了更加客观地进行去噪效果对比,本文采用了三个评价指标,分别是峰值信噪比(Peak Signal-To-Noise Ratio,PSNR)、结构相似性(Structural Similarity Index,SSIM)和边缘保持系数(Edge Preservation Index,EPI)。表1 所示为五种模型在测试集上得到的三种评价指标的对比。可以看出,本文模型的去噪结果在PSNR 和SSIM 这两个指标均值上优于其他四种模型,这与图1 所示的视觉效果对比图基本上是吻合的,说明本文模型降噪效果最优,且是最接近其对应的无噪声的OCT 图像。指标EPI 计算的是去噪图像与含噪图像之间的边缘信息保存能力,K-SVD 模型在该指标上取得了最大值,其原因是它的去噪结果中仍然含有噪声,而本文模型取得了最小值,其原因是它的结果中不含噪声。
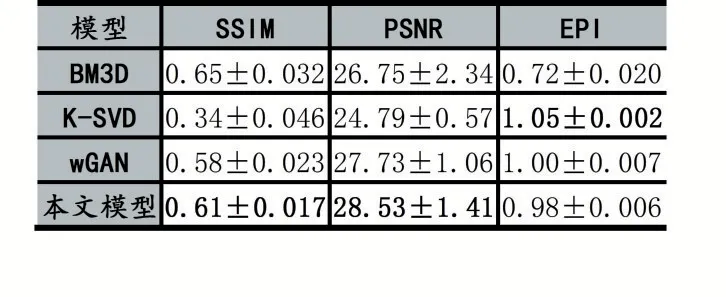
表1 四种模型在测试集上去噪结果的评价指标

图1 四种模型在测试集上的结果
其中前两行为不同模型的测试结果,第三行中的图对蓝色区域进行放大,第四行中的图对红色区域进行放大
4 结语
本文提出了一种基于条件生成网络(cGAN)的图像去噪方法,通过学习有噪图像到无噪图像的映射来实现去噪过程。实验结果表明,本文提出的方法是最接近无噪图像的,对于指标PSNR 和SSIM,均优于其他对比方法。但我们的结果中仍然存在少量的噪声,通过改善模型赖去除这些噪声将会是我们今后的研究方向。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
电脑报(2022年24期)2022-07-01
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
舰船科学技术(2021年12期)2021-03-29
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
饮食科学(2016年7期)2016-07-27
软科学(2014年8期)2015-01-20
