
结合目标检测和语义分割的违规广告牌检测
2021-07-03 03:52刘罗成刘正熙熊运余
现代计算机 2021年12期
刘罗成,刘正熙,熊运余
(四川大学计算机学院,成都610065)
0 引言
随着国内现代化、城市化的进程加快,城市中的店铺等商业活动越来越多,使得城市中的广告牌数量与日俱增,随之而来的是违规摆放广告牌的现象也越来越严重。为了清理这些违规广告牌,目前的主要方法是大量雇佣城管来监视和管理,当然视频监控也是管理违规广告牌的有效手段之一,但是不免需要人工不断监视视频和处理相关问题,这些方法都存在费时费力的缺点。为了更好地节省管理违规广告牌的人力成本,亟需一种高效辅助人工进行监控管理的方法。
对于广告牌的检测,一般可以使用传统的机器学习目标检测算法或者是基于深度学习的目标检测算法。传统的机器学习目标检测算法基于特征提取,一般流程如下:在待检测图片上通过采用滑动窗口的方法设定大小不同的候选框,利用HAAR[1]、HOG[2]、DPM[3]等特征提取方法对每个窗口中的局部信息进行特征提取,在特征提取后,对候选区域提取出的特征送入SVM[4]等的分类器中进行分类判定。在分类判定过程中,如果单类别检测只需要区分当前的候选框中包含的对象是背景还是目标,而对于多分类不免会产生重叠的候选框,这时需要通过NMS 来对候选框进行合并抑制,去掉多余的候选框,计算出各个类别的候选框,最终完成目标检测。
从传统目标检测算法流程可以看到一些缺点:首先手工设计特征,这些特征一般获取的是低层次和中层次的特征,表达能力较差,对于多样性的变化没有很好的鲁棒性,而且基于滑动窗口的区域选择策略没有针对性,检测结果也不尽人意。
随着近年来的深度学习的迅速发展,基于卷积神经网络的目标检测算法也得到很大的突破,与传统机器学习目标检测算法相比,最主要的是在检测精度上得到很大的提升,这得益于其强大的深层次的特征提取能力。考虑到基于卷积神经网络的目标检测算法的优点,本文也选用了这类目标检测算法。
基于深度学习的目标检测算法大体可分为One Stage 和Two Stage 两种类别。其中One Stage 的目标检测速度较快,但精度比Two Stage 较低,如YOLOv3[5]等;而Two Stage 的目标检测精度较高,但检测速度较慢,如Faster R-CNN[6]等。在选用何种基于深度学习的目标检测算法,本文主要从速度方面考虑,因为继本文的下一步研究是想达到实时性,所以本文最终选择YO⁃LOv3 作为目标检测部分的算法。
如今,无论在哪个城市中,广告牌好像是必不可缺少的一部分,但是在人行道中间和车行道上摆放的广告牌严重阻碍了交通环境而且抹黑了市容,如图1 所示。如果在特定区域,例如某条街道上,使用固定摄像头拍到的广告牌都是违规摆放,这种情况下只需使用目标检测算法就可以检测到违规摆放的广告牌,但是现实中,监控的摄像头都是转动的,拍到的区域都不是特定的,所以拍到的广告牌有些不是违规摆放的,这种情况下,需要判定检测到的广告牌是否处于阻碍交通的位置是一项具有挑战性的任务。
为了划分城市道路区域,本文使用语义分割算法。语义分割是在像素级别上的分类,属于同一类的像素都要被归为一类,因此语义分割是从像素级别来理解图像的。在深度学习应用到计算机视觉领域之前,研究人员一般使用纹理基元森林(Texton Forest)或是随机森林(Random Forest)方法来构建用于语义分割的分类器。2014 年,Long 等人提出的FCN(Fully Con⁃volutional Networks)[7]是首次将CNN 网络用于语义分割,这种网络将目标识别的AlexNet[8]网络的最后的全连接层改为卷积层,使用反卷积层进行上采样并且提出了跳跃连接来改善上采样,在性能上,比传统采用区域特征提取的图像分割方法有显著提升。随后几年,一系列优秀的语义分割模型层出不穷,如SegNet[9]、PSPNet[10]、DeepLabv3+[11]等。本文使用的语义分割模型是精度比较高的DeepLabv3+。
本文将违规摆放广告牌简化成图1 所示的两种情况,为了能够准确检测到这两类违规广告牌,本文使用两个子网络,一个是YOLOv3,用于检测出图片中的广告牌;另一个DeepLabv3+,用于分割城市道路区域,最后结合这两个算法的结果判断出广告牌是否处于人行道中间或者车行道,进而来判断是否属于违规摆放。在进一步提高检测速度的尝试中,笔者比较了两种Backbone 的YOLOv3,发现更加简单的MobileNetv1[12]与默认使用DarkNet53 相比,模型更轻量,检测速度更快,检测精度相差无几,所以最后选用MobileNetv1 作为YOLOv3 的Backbone。两个网络的最终测试结果中,YOLOv3 的mAP 为70.27%,DeepLabv3+的mIOU为0.7854,能达到高效辅助工作人员的目的。

图1
1 YOLOv3目标检测网络
1.1 YOLOv3网络概述
在目标检测网络快速发展的历史上,YOLO 系列的目标检测网络无疑是具有代表性一类的网络,跟SSD[13]等One Stag 网络的主要思路一样,摒弃了Two Stage 中的region proposal 阶段,将待检测的图片分割成N×N 个格子,然后每个格子负责检测物体类别,输出固定数目的Bounding Box 信息和属于各种类别的概率信息,并且利用CNN 提取特征后直接进行分类和回归,整个过程只需要一步。YOLOv3 的算法是在YOLOv1 和YOLOv2 的基础上形成,相比较前两者的研究,YOLOv3 更注重多标签的分类和提高对小目标检测精度。
为了将分类任务由单标签分类改进到多标签分类,YOLOv3 将分类器由Softmax 改为Logistic。Soft⁃max 分类器假定各种类之间是互斥关系,如果一个对象属于一个类,那么它一定不属于另一个类,这在有些数据集中表现正常,包括本文的个人数据集,但是在有些数据集中,如果一个对象同时属于几个类别,Softmax分类器似乎违背了它的假设。Logistic 分类器是使用阈值来预测对象的多个类别标签,如果该对象在某个类别标签的分数高于设定的阈值时,就将此类标签分配给该对象。比较两种分类器的不同的分类原理,YOLOv3 最终选择Logistic 分类器。
为了对小目标的检测结果更准确,YOLOv2 和YO⁃LOv3 都做了一些操作,YOLOv2 中使用Passthrough Layer 和Bounding Box Prior 来加强对小目标检测的精确度;YOLOv3 中除了YOLOv2 中使用的方法外(其中Passthrough Layer 和YOLOv3 使用的残差网络结构原理相似,故如此说),最重要的是将YOLOv2 的网络主干DarkNet19 换成DarkNet53,在DarkNet53 网络主干上,YOLOv3 采用多制度融合和全卷积的方式来进行预测,这些设计让YOLOv3 的检测精度相较YOLOv2 而言更高,速度也没有降低。
1.2 DarkNet53和MobileNetv1网络结构对比
YOLOv3 默认使用的网络主干DarkNet53 性能固然优秀,但是在本文中,针对只处理广告牌这一种类别问题,是否可以换用更简单的网络主干使得检测速度更快,精度损失不大来更好地符合现实中追求实时性的要求,于是选用MobileNetv1 作为YOLOv3 网络主干是一个不错的尝试。
DarkNet53 的网络设计具有层次深的特点。Dark⁃Net53 中的53 这个数字是表示此网络主干中的卷积层个数,此网络由52 个卷积层+1 个全连接层构成,其中最后的全连接层是通过1×1 的卷积实现的,也算一层卷积层,所以共有53 个卷积层。从输入开始,先经过两层卷积层,然后由5 组重复的残差单元Residual 构成,残差单元基本构件如图2 所示。每组残差单元有两个卷积层和一个快捷链路构成,这5 组残差单元分别重复1 次、2 次、8 次、4 次。由于每个残差单元的第一个卷积层是做步长为2,大小为1×1 的卷积操作,所以整个残差网络一共降维5 次,共降维25=32 倍。每个残差单元会有三次多尺度融合操作,一系列的组合,使得DarkNet53 相比之前的One Stage 目标检测网络具有更高的精度。
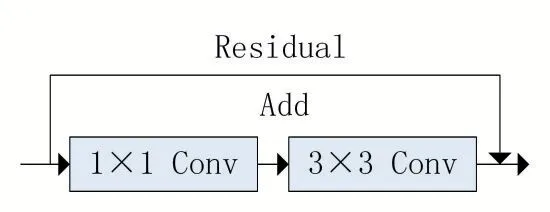
图2 DarkNet53残差单元基本构件
MobileNetv1 原本就是为了加快网络运算速度而设计的一种轻量化网络模型。与DarkNet53 的多层卷积层不同,MobileNetv1 总共只有28 层卷积层,第一层是标准卷积层,后面紧接着13 个深度可分离卷积层,再后面是由1×1 卷积得到的全连接层,其中一个深度可分离卷积层包含一个3×3 的Depthwise Conv,一个1×1 的Conv,它们中间会加入BN 和ReLU 激活函数,如图3 所示。
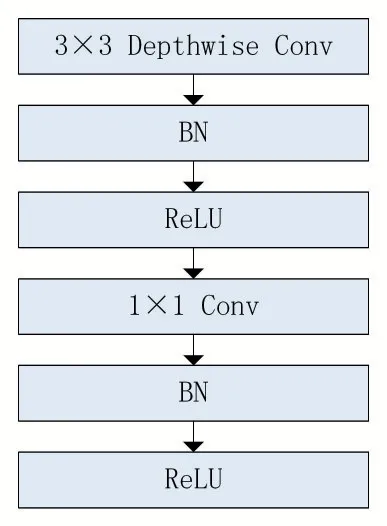
图3 深度可分离卷积基本构件
比较上述两个网络主干,MobileNetv1 相对有更浅层的网络结构,深度卷积的参数数量只有普通卷积的1/M,其中M 表示通道数,综合以上两点,采用Mobile⁃Netv1 相比DarkNet53 在理论上是可以有更快的推理和计算速度。
2 DeepLabv3+语义分割网络概述
语义分割是计算机视觉的一项基本任务,相比目标检测,语义分割是一项更精细的工作,是像素级的分类。DeepLab 系列网络是语义分割网络中的佼佼者,DeepLabv3+是在DeepLabv3 的基础上发展改进而来。
在DeepLabv3 中,DCNN 通过多次下采样,获得低维度的、高级语义信息的特征图,但是特征图过小会丢失边界信息,导致预测精度降低。为了改进DeepLabv3这一缺点,DeepLabv3+加入解码器来逐层恢复图像的空间信息,如图4 所示,输入图片通过DCNN,经过4倍下采样,得到低层次的特征,这低层次特征在编码器部分经过ASPP 模块,最终下采样16 倍,获得高层次的特征;在解码器部分,低层次的特征经过1×1 卷积调整维度,在编码器中获得的高层次特征经过双线性插值,获得4 倍上采样,然后将这两个相同层次相同维度的特征Concat,再采用3×3 卷积进一步融合特征,最后经过双线性插值4 倍上采样后得到与输入的原始图片相同大小的分割预测图。由于解码器部分融合了低层次和高层次的特征,所以DeepLabv3+获得更丰富的语义信息和更高的精确度。
同时,DeepLabv3+为了减少计算量,采用改进的Xception[14]网络作为网络骨干,在图4 的DCNN 中将原Xception 网络中的最大池化层使用stride=2 的深度可分离卷积替换,同时增加了更多的层。DeepLabv3+最后还尝试在ASPP 中也加入深度可分离卷积,发现在几乎不损失预测精度的前提下,进一步减少计算量。
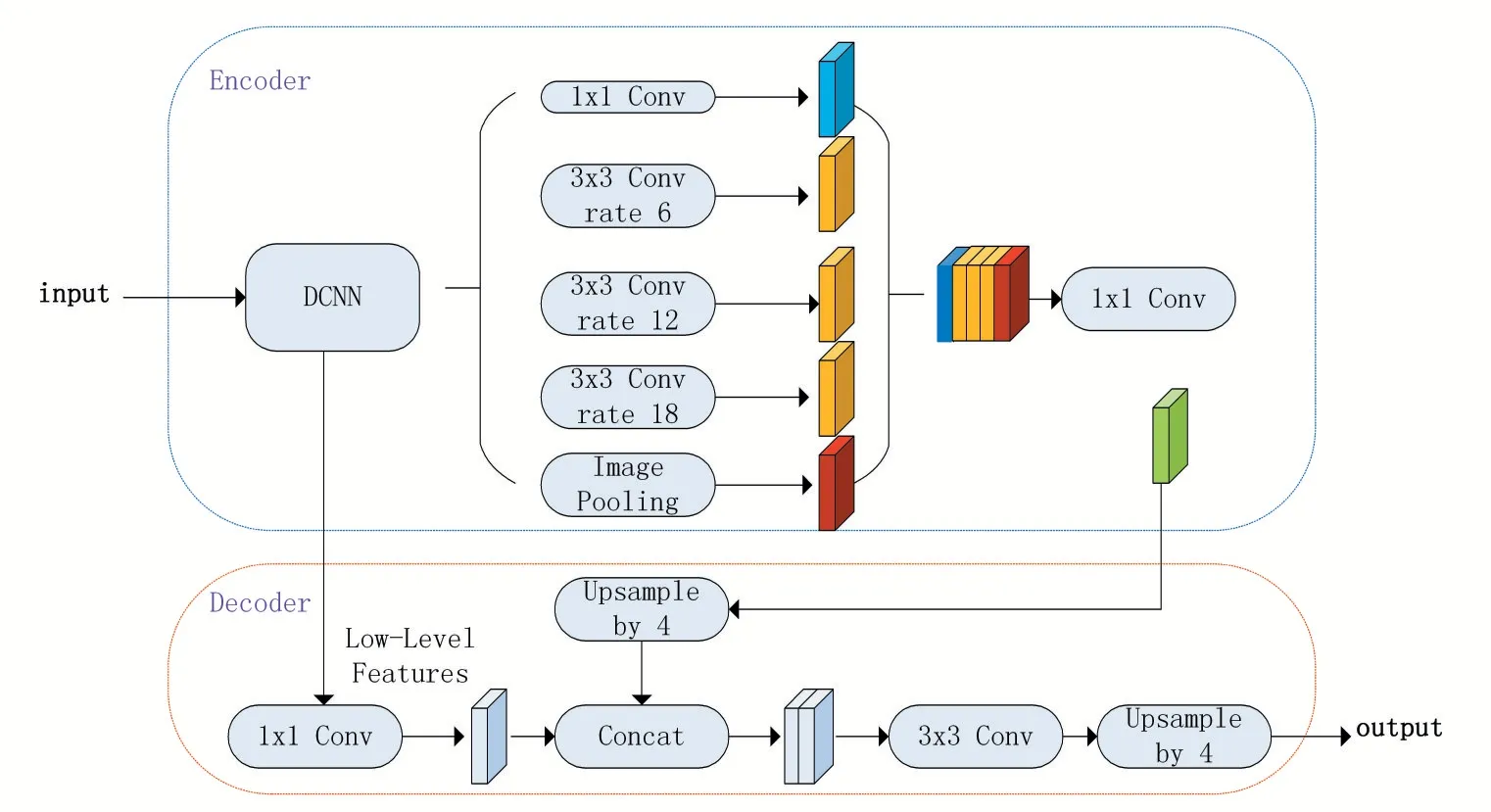
图4 DeepLabv3+网络结构
3 道路广告牌的违规判定
正如前文所述,本文提出的违规广告牌简化成两种情况,一种是处在人行道中间,另一种在车行道上。如图5 所示,先使用语义分割算法分割出人行道区域,同时使用目标检测算法得到广告牌的位置,也就是在图片上标出检测框,获得图片中检测框的坐标,在分割图中的相同位置,统计人行道的像素是否是除广告牌以外的像素点的1.5 倍以上,如果是,则为人行道上的违规广告牌;但由于要保证车行道上的安全,所以只要在分割图上检测出车行道的像素点,就直接判定为车行道上的违规广告牌。
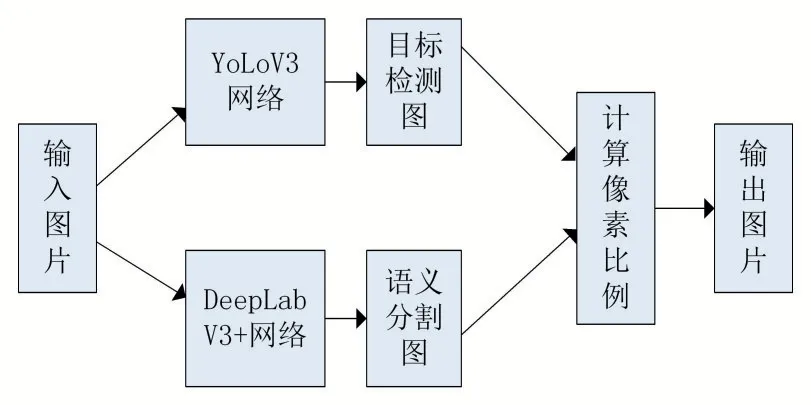
图5 道路违规广告牌网络结构图
如图6 所示,左上是原输入图片,右上是目标检测算法得到的检测图,左下是经过语义分割算法得到的分割图,右下图片是经过两个网络判定所得出的属于人行道违规广告牌。整体判定流程如图7 所示。

图6 人行道违规广告牌
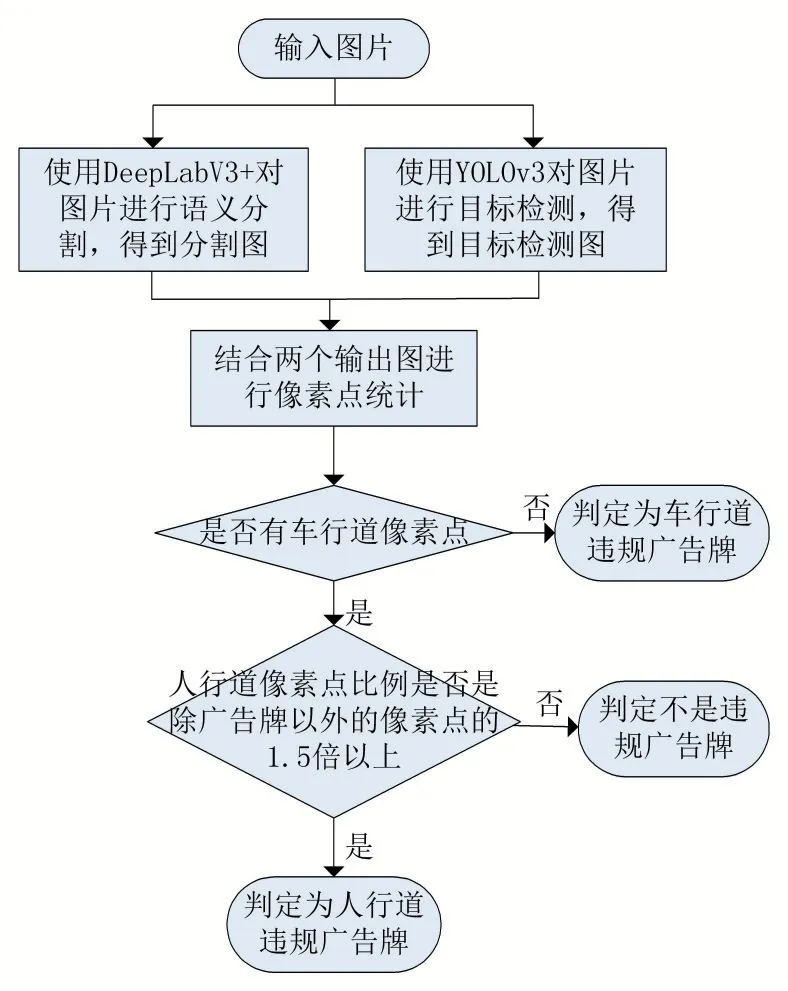
图7 违规广告牌判定流程
4 实验结果与分析
本文目标检测部分所选用数据集中的图片全部来自国内城市中监控摄像头采集的照片,共4928 张,通过人工标签,其中标定的广告牌(ad)类别数量有7799个,语义分割部分所选用的图片是从这4928 张图片中随机选取500 张进行标定,标定的类别有三类:广告牌(ad)、车行道(road)、人行道(sidewalk)。
本文的实验环境配置如下:GPU 为NVIDIA GTX1080Ti、CPU 为Intel Core i7 8700k,操作系统为Ubuntu 16.04.6。YOLOv3 算法所选用的语言是tesor⁃flow-gpu+keras、DeepLabV3+算法所选用的语言是tes⁃orflow-gpu。
4.1 YOLOv3目标检测实验
训练时将数据集分为两部分:训练集(train)和验证集(val),其中训练集占85%,验证集占15%。为了训练的公平性,默认的DarkNet53 骨干网络和换用的MobilNetv1 骨干网络都不使用预训练模型,从头开始训练。
网络训练参数方面,考虑显存大小,使用Dark⁃Net53 时将batch_size 设为8,不使用迁移学习训练,共训练500 个epoch,使用Adam 优化器,初始学习率设为10-4;使用MoblileNetV1 时将batch_size 设为16,其余和DarkNet53 相同。网络测试参数方面,设置score为0.3,IOU 为0.5。
两个不同的骨干网络训练时间和测试的结果如表1 所示。

表1 DarkNet53 和MobileNetv1 实验结果对比
从表1 可以看到,训练同样数量的数据集,Dark⁃Net53 所需时间是MobileNetv1 的2 倍多,测试的结果,mAP 两者并没有相差多少,但是测试的FPS,虽然两者都达不到官方论文中给出的那么高的数值,但是在本文实验环境下中,MobileNetv1 差不多达到DarkNet53的两倍。综合以上结果,本文最终选了速度更快,精度不损失多少的MobileNetv1 做目标检测的骨干网络。
4.2 DeepLabV3+语义分割实验
语义分割训练时将500 张数据集也分为两部分:训练集和验证集,其中训练集占80%,验证集占20%。训练参数配置为:训练迭代30000 次,裁剪尺寸train_crop_size 设置为513×513,初始学习率设置为10-4,batch_size 设置为4,由于本文所选用数据集中的类别之间空间大小极不平衡,因此将三类loss 权重设置为ad:road:sidewalk=15:1:1。在验证集上测试所达到的平均交并比(mIOU)为78.54%。
结合目标检测和语义分割网络的结果,最终的效果如图8 所示,左上图共有三个广告牌,在右上图全部被检测到,左下图的语义分割边界比较明显,右下图的最终结果检测到两个违规的广告牌,还有一个广告牌因为靠近图中的店面,并不妨碍交通,所以判定不是违规广告牌。

图8 实验最终结果展示
5 结语
本文提出了一种结合目标检测和语义分割算法来检测城市中的违规广告牌,在目标检测中,通过比较两种不同的网络骨干,最终在不损失很大精度的前提下,选用模型简单,计算速度更快的MobileNetv1 作为目标检测算法的骨干网络;在语义分割中,使用DeepLabv3+划分城市道路区域。实验结果表明本文提出的算法能在转动摄像头下拍摄的图片中,检测出违规广告牌。
本文旨在检测的性能具有实时性,但所选用的语义分割模型并不具备很快的检测速度,针对这点,在之后的研究中,将选用实时性的语义分割网络模型和调整训练的数据集,在不损失精度的前提下,使检测效果具有更快的速度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年2期)2021-02-23
作文周刊·小学一年级版(2019年20期)2019-06-27
软件导刊(2017年4期)2017-06-20
知识窗(2017年4期)2017-04-12
