
基于深度学习算法的水尺刻度提取技术
2021-07-03 03:52祝子维陶青川沈建军雷磊
现代计算机 2021年12期
祝子维,陶青川,沈建军,雷磊
(四川大学电子信息学院,成都610065)
0 引言
近年来,南方夏季经常暴雨成灾,多地洪水泛滥,汛情来势汹汹,河流水位智能监控对于减少人力和实时监控分析有着重要意义。随着信息化时代的发展,社会基础设施的完善,信息化建设逐渐渗透到各个领域,水域监控系统日益完善,智能监控逐渐取代人工监控。水位值测量传统方法主要依靠安装水尺人工读数或者通过传感器[1]自动采集模拟信息并转为数字信息来获取,这些方式测量水位值成本较高而且实时性低。随着图像技术的发展,许多学者将人工智能、机器视觉方法运用到水尺测量,测量过程主要分为两步,首先是水尺定位去掉背景里的大部分背景信息,目前主要使用传统机器视觉或深度学习目标检测的方式进行定位,传统机器视觉方法主要使用图像处理的边缘检测算子[2]进行水尺边缘角点特征提取、从HSV 色域空间提取水尺颜色定位水尺以及人工标定水尺区域等方法,雾天、噪声、周围环境等因素对传统机器视觉检测方法影响极大,需要不断调参适应不同环境,实用性差。基于深度学习目标检测算法如SSD[3]等虽然可以大致框出水尺位置,但还是会有一部分背景信息对后续的水尺刻度提取造成影响。第二步水尺刻度提取目前主要采用传统机器视觉形态学处理、二值化、旋转矫正、字符分割等方法[4],但是这些方法里的阈值参数设置受环境影响较大,不能自主学习,并不能适应复杂多变的实际监测环境。
本文提出一种基于改进SegNet 和YOLOv3 网络的水尺刻度检测算法,通过深度学习语义分割和目标检测提取水尺信息,有较强的抗干扰能力,能适应复杂多变的环境。语义分割是一种分类算法,实现对图像像素的归类并提供类别语义,输入一张图像经过语义分割网络得到一张逐像素标注的图像,语义分割从像素级别解释图像,目前已广泛应用在医疗、无人驾驶等众多领域。Vijay Badrinarayanan 等人提出一种用于图像分割的深度卷积编码-解码架构SegNet[5],SegNet 分割引擎包含一个编码网络和一个解码网络并跟随一个像素级别的分类层,相比其他广泛的语义分割网络(FCN[6]、UNet[7]、DeepLab[8])等,在保证良好分割精确度的同时,内存和时间的利用率上更加高效,能在AI 计算芯片(Atlas 200、Hi3559A 等)运行。改进SegNet 融入双重注意网络DANet[9],引入位置注意力模块和通道注意力模块改进特征表示,一定程度上解决分割边界粗糙,提高分割准确度。Joseph Redmon 提出的YOLOv3[10]在BackBone 网络上将用DarkNet-53 替换DarkNet-19,性能提升巨大,本文在保证水尺特殊字符检测精确度前提下,修改BackBone 模块卷积层,使网络权重大幅减小,提高运行效率。
1 水尺刻度提取整体流程
本文算法结合SegNet 和YOLOv3 改进网络对图像进行处理,提取水尺刻度,具体步骤分为:①从摄像机采集视频流,通过视频解码模块,得到RGB 格式的图像帧。②将RGB 格式图像帧输入SegNet 语义分割模块,分离出水尺、水域、背景3 个特征部分。③由边缘检测算子提取出水岸线。④截取水尺图像resize 后输入到YOLOv3 改进网络,检测出特殊字符个数。⑤配合水岸线位置计算出部分进入水中的不完整字符长度值,最后得到完整水尺刻度值。算法流程如图1 所示。
2 水尺刻度提取算法
2.1 基于改进的SegNet水尺定位算法
(1)SegNet 网络概述
SegNet 是剑桥大学团队开发的开源语义分割网络,网络在像素级别对图像内部不同特征分类,主要分为编码模块(encoder)和解码模块(decoder)两块,编码模块基于VGG16[11]网络模型,通过卷积神经网络解析图像信息,得到图像的特征图谱。解码模块在得到编码模块从原图解析出来的特征图谱后,实现对图像每一个像素的分类标注,最后得到语义分割图。SegNet编码和解码结构是一一对应关系,一个编码模块对应一个解码模块,他们具有相同的空间尺寸和通道数。SegNet 采用池化索引(pooling indices)解决过多的边界细节损失,存储每个池化窗口中最大特征值的位置,用于编码模块和解码模块的特征映射。在保证精度前提下,SegNet 内存消耗比其他语义分割架构明显更小。
(2)改进的SegNet 网络结构
SegNet 网络分割虽然可以保证低内存使用率情况下对图片特征像素级的分类,但仍然是使用局部感受野进行特征的提取,这会导致最终的feature map 的表达可能不同,以致分割效果不理想。DANet 是一种双重注意力网络,可以自适应地将局部特征和全局依赖项联系在一起。水尺也暴露在露天室外环境,时常因为光照、雾天、遮挡等环境因素而影响分割效果,SegNet网络虽然可以有效捕获目标,但是忽略了全局信息。因此,本文在SegNet 中融入DANet 注意力机制,DANet包括位置注意力模块(position attention)和通道注意力模块(channel attention),从SegNet 解码出feature map分别送入两个注意力模块,得到新的加权feature map,再相加后输入到解码模块。
①位置注意力模块
特征图的表示能力体现对图像的理解,位置注意模块将全局语义信息融入局部感受野中,增强特征图表示能力,具体流程如图2 所示。
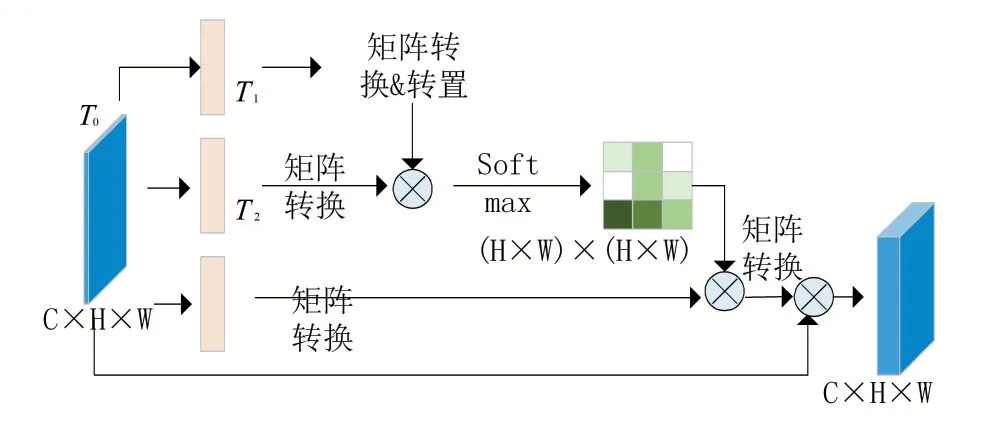
图2 位置注意力模块流程
如图2 所示,对SegNet 解码模块输出的特征图T0∈RC×H×W,其通道特征数为C,经过一个带有BN 层和ReLU 层的卷积网络得到 3 个新的特征图T1,T2,T3∈RC×H×W,将T1,T2矩 阵 变 换 为RC×N,其 中N=H×W,将T1乘以T2的转置,然后通过Softmax 层计算位置注意力映射图S∈RN×N,计算如公式(1)所示。

其中Sij表示第i 个位置对于第j 个位置的影响程度,值越大表明特征越相似。然后将T3∈RC×H×W矩阵变换为RC×N,再乘以S,矩阵变换为RC×H×W,乘上因子α,并与特征图T0逐像素相加得到最终特征E,如公式(2)所示。

其中加权系数α初始设置为0,然后不断学习,E为通过注意力机制模块后得到的特征图,其中每个位置为所有位置的特征和原始特征加权和,因此融入全局的图像信息。
②通道注意力模块
通道注意力模块通过获取不同通道映射之间的联系增强特征图语义的表达能力。具体流程如图3所示。

图3 通道注意力模块流程
与位置注意力模块中把特征图通过卷积神经网络再与原始特征加权和不同,通道注意力直接把原始特征T0∈RC×H×W矩阵转换为RC×N,其中N=H×W,然后与不同通道特征转置后进行一次矩阵乘法,最后通过Softmax 层获得RC×C特征矩阵,如公式(3)所示。

其中Xij表示第i 个通道与第j 个通道的联系,然后对Xij转置后与原始特征进行矩阵乘法运算得到RC×H×W,再乘上因子β并与原始特征逐像素相加得到最终的特征图E∈RC×H×W,如公式(4)所示。

每个通道都是所有通道的特征和原始特征图的加权和,增强通道之间的依赖,增强特征图的判别能力。将DANet 模块加入到SegNet 的解码和编码之间的整体结构图如图4 所示。
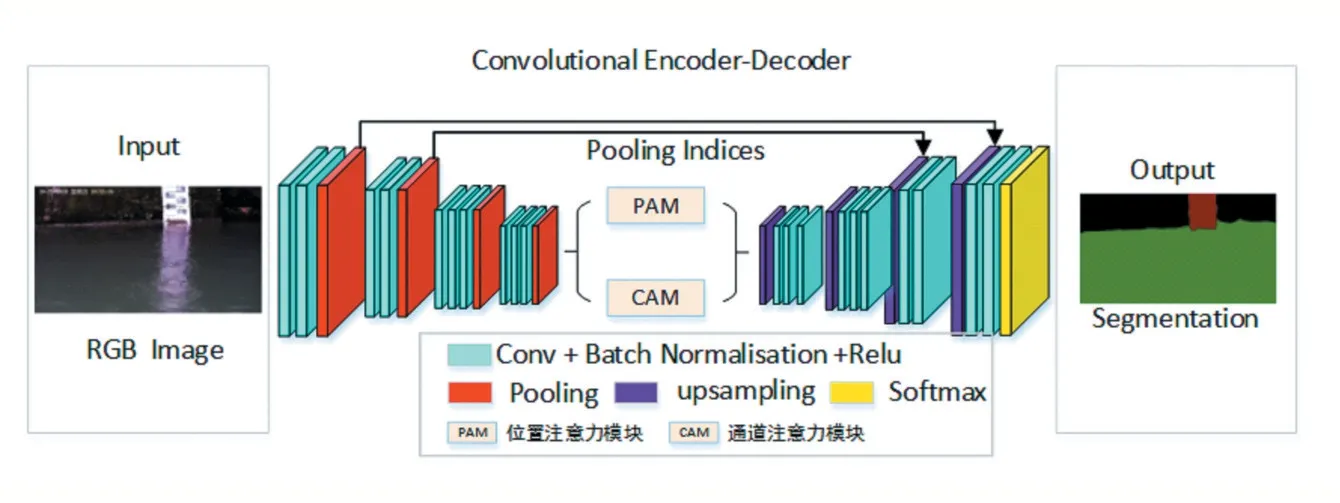
图4 加入注意力机制的SegNet网络
(3)改进SegNet 模型分割图像结果
本文使用2112 张样本图训练网络模型,加载训练好的模型对图像进行分割。分割结果如图5 所示,其中黑色代表背景,红色代表水尺,绿色代表水域。从分割图中提取水尺位置和水岸线信息,水尺区域之后输入到目标检测模块提取水尺刻度,水岸线用来计算不完整字符长度。

图5 分割结果
2.2 基于改进YOLOv3网络的水尺刻度检测算法
目前,在定位水尺之后,水尺刻度提取大都基于传统机器视觉,通过倾斜矫正、水尺裁剪、图像形态学操作分割字符、刻度提取等步骤,很容易受到环境影响。因此,本文改进YOLOv3 网络提取水尺特殊字符“ㅌ”和“ヨ”。
(1)RulerYolo 网络结构
YOLOv3 网络结构采用DarkNet-53 作为特征提取的特征网络,DarkNet-53 引入残差ResNet 模块,解决深层次网络梯度问题,减小梯度爆炸的风险,提高学习能力,重复利用两个卷积层和一个快捷链路组成的残差组件,而原网络结构较深,权值参数太过庞大,本文根据YOLOv3 来改进的网络,在保证精度的情况下,减少内存使用和运行速率,为了方便理解,将改进的YO⁃LOv3 网络称为RulerYolo。在卷积层和残差模块组成的特征提取的BackBone 基础上,对网络深度和特征图数量上进行缩减,通过5 次下采样,每次采样步长为2,先后通过7×7 的卷积核和MaxPooling 2 倍下采样,然后残差块的数量从1,2,8,8,4 改变为3,3,3,4,保证网络特征能力的前提下,缩减网络的层数,使网络权重大大减少,提高运行速度。利用多尺寸特征进行对象检测,水尺图像为矩形形状,自定义输入尺寸为768×384,图像通过BackBone 网络32 倍、16 倍、8 倍下采样得到三种不同尺度的预测结果,分别为24×12、48×24、96×48 三种尺度,改进后输入尺寸为768×384,权值大小为3.8Mb,大小相对于原始YOLOv3 减小了64 倍,GPU 运行平均耗时12ms,改进后的结构框图RulerYolo 如图6所示。

图6 RulerYolo网络结构图
经过修改网络模型结构,样本制作,训练模型,得到RulerYolo 网络模型,将水尺区域图像通过双线性插值resize 到768×384 尺寸,输入到网络模型中得到目标检测结果如图7 所示。

图7 目标检测结果
(2)水尺刻度检测
本文完整水尺检测算法分为两部分,第一部分长度通过RulerYolo 检测特殊字符“ㅌ”和“ヨ”获取,第二部分长度通过SegNet 语义分割获取的水岸线位置和RulerYolo 获取特殊字符最低位置距离来估算不完整字符的长度,水岸线可以通过Canny 边缘检测算子提取,水岸线位置坐标通过Canny 边缘算子获取的边缘轮廓像素取均值得到,具体计算如公式(5)、(6)、(7)所示。
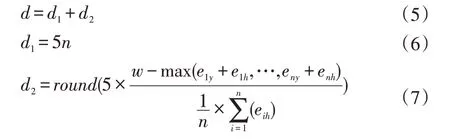
式(5)中d 为水面之上水尺总刻度,d1为RulerY⁃olo 测得完整特殊字符的刻度和,d2为不完整字符的长度。式(6)中5 表示为一个“ㅌ”和“ヨ”字符刻度为5 cm,n为字符个数。式(7)中round为取整,eiy和eih分别为第i个框的左上角纵坐标和高,w为水岸线。计算出总刻度之后,除以水尺总刻度,乘水尺实际长度即可得水岸之上的长度,最后得到水位值。各参数在图中具体表示如图8 所示。

图8 水尺刻度检测标注
3 实验结果与分析
3.1 数据集
本文样本数据集通过互联网爬取、成都河长制水利摄像头获取、四川大学附近人工河拍摄得到,由于网上水尺图片样本较少和人工拍摄的样本比较单一,通过对图片进行裁剪、旋转、加噪、亮度、对比度等操作进行样本扩充。总共2112 张图像,随机抽取1689 张作为训练集,423 张图像作为验证集。首先使用labelme对样本图进行人工标注,分为水域、水尺、水岸3 个区域,把水域标注为红色,水尺标注为绿色,水岸等其他背景标注为黑色,通过脚本文件把JSON 格式文件转换出人工分割图作为真实分割效果,然后由人工分割图制作全黑的mask 图像作为图像模型分割训练。
3.2 实验结果
本文实验环境为PyTorch1.4.0、Cuda9.0、Python3.6、Ubuntu18.04.4LTS;处理器为Intel Core i5-7400,CPU频率为3.0 GHz;内存8 Gb;GPU 显卡为NVIDIA GTX 1080TI,显存11 Gb。
实验测试包括图片和视频,选取图片测试集分辨率大小不一,从不同的水位高度、不同的水尺倾斜角度、不同远近距离、水面清晰度等选取的100 张测试图片,水尺种类为红色和蓝色两种水尺,总长为1m,最小刻度为1cm。视频是通过成都河长制水利系统部署的摄像头获取的,因实际环境,摄像机捕捉的视频有轻微抖动,也更正符合水利监控的实际场景,对红蓝两种水尺场景进行测试,视频通过FFMpeg 进行解码,分别率为1920×1080、帧率为30。水位检测实验结果如表1所示,水位检测部分结果图如图9 所示。
从表1、图9 可以看出,本文算法测试大部分图结果误差在0 cm 到3 cm 之间,准确率达到了95%,对不可控的环境因素有较强的适应性,基本能满足实际水利监控的要求,对水利监控系统有一定的帮助。

表1 实验结果

图9 实验结果图
4 结语
本文基于深度学习网络提出的水尺检测算法,能准确测出水尺刻度,计算当前水位值,并且有较强的环境适应力,对于不同水域环境如:水库、河流等场景都能很好适应,对于不同光照、雾天、摄像机轻微抖动等不可控因素有一定适应性。实现了对水域水位线实时监控,极大减少了人工监控成本,为水利智能化监控提供新的方法。本文提出改进SegNet、YOLOv3 网络还可以推广到其他目标的分割和检测,诸如:人入侵、车辆、水面漂浮物等场景,有较强的应用性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
睿士(2020年6期)2020-08-18
南方周末(2019-12-19)2019-12-19
学苑创造·A版(2019年9期)2019-11-07
南方周末(2019-07-18)2019-07-18
南方周末(2019-05-09)2019-05-09
学苑创造·B版(2017年1期)2017-02-21
学苑创造·B版(2017年1期)2017-02-21
小天使·二年级语数英综合(2016年9期)2016-05-14
长江学术(2015年1期)2015-02-27
