
基于嵌入式平台的实时视频行人检测
2021-07-03 03:52郑章陶青川赵兴博
现代计算机 2021年12期
郑章,陶青川,赵兴博
(四川大学电子信息学院,成都610065)
0 引言
行人检测在智能监控,视频分析具有很重要的作用。早期视频行人检测靠人工进行查看分析,但是随着监控范围及摄像头数量的不断增加,人力效率低下的缺点无法弥补,凸显了智能视频行人检测的必要性。行人检测发展历程主要分为两个阶段,第一阶段主要是传统图像处理算法,需要人为地设计算法对图像进行处理,主要有Haar 小波特征[1]、HOG+SVM[2]等,这类算法普适性较低。第二阶段是深度学习相关算法,深度学习利用机器的强大算力对大量样本图片进行迭代计算,使用多层网络来对目标进行特征提取,再利用提取的特征信息,对图像中的目标进行定位与分类[3]。之后随着Fast R-CNN[4]、SSD[5]、YOLO[6]等系列优秀算法的提出,深度学习算法的性能得到进一步提升,在图像处理领域的准确率以及速率表现优异,大幅度超过传统的图像处理算法。
但是以上深度学习算法的良好表现与其在较好设备上运行有关,因为上述算法的复杂度普遍较高,要想达到实时地计算需要平台强大的计算能力,由于嵌入式设备的算力相对较差,内存相对较小,在嵌入式设备上运行速度很慢,无法达到实时性[7]。其中YOLO 系列算法中的YOLOv3 在已有网络的基础上,使用DarkNet或者ResNet 来作为特征提取的主干网络[8],并且使用多级检测网络,具有效果较强检测准确率较高的特点。不过在嵌入式这种性能较差的开发板上运行的话,YOLOv3 的速度还是偏慢,达不到实时性的要求。针对上述问题,对YOLOv3 算法加以改进以提高行人检测的速度,使得可以在嵌入式平台上实时运行。
1 YOLOv3算法介绍
YOLOv3 网络结构整体上分为特征提取部分Dark⁃Net-53 和检测部分两单元[9],特征提取网络包含残差网络,因为残差网络可以消除网络加深带来的梯度消失等问题,所以提取网络可以设计的较深,网络中若干卷积层和跳跃层构成一个残差单元,多个残差单元组成一个残差块,网络由5 个残差块组成,卷积结构包括卷积层、批标准化层和激活函数[10]。图1 为DarkNet-53的示意图
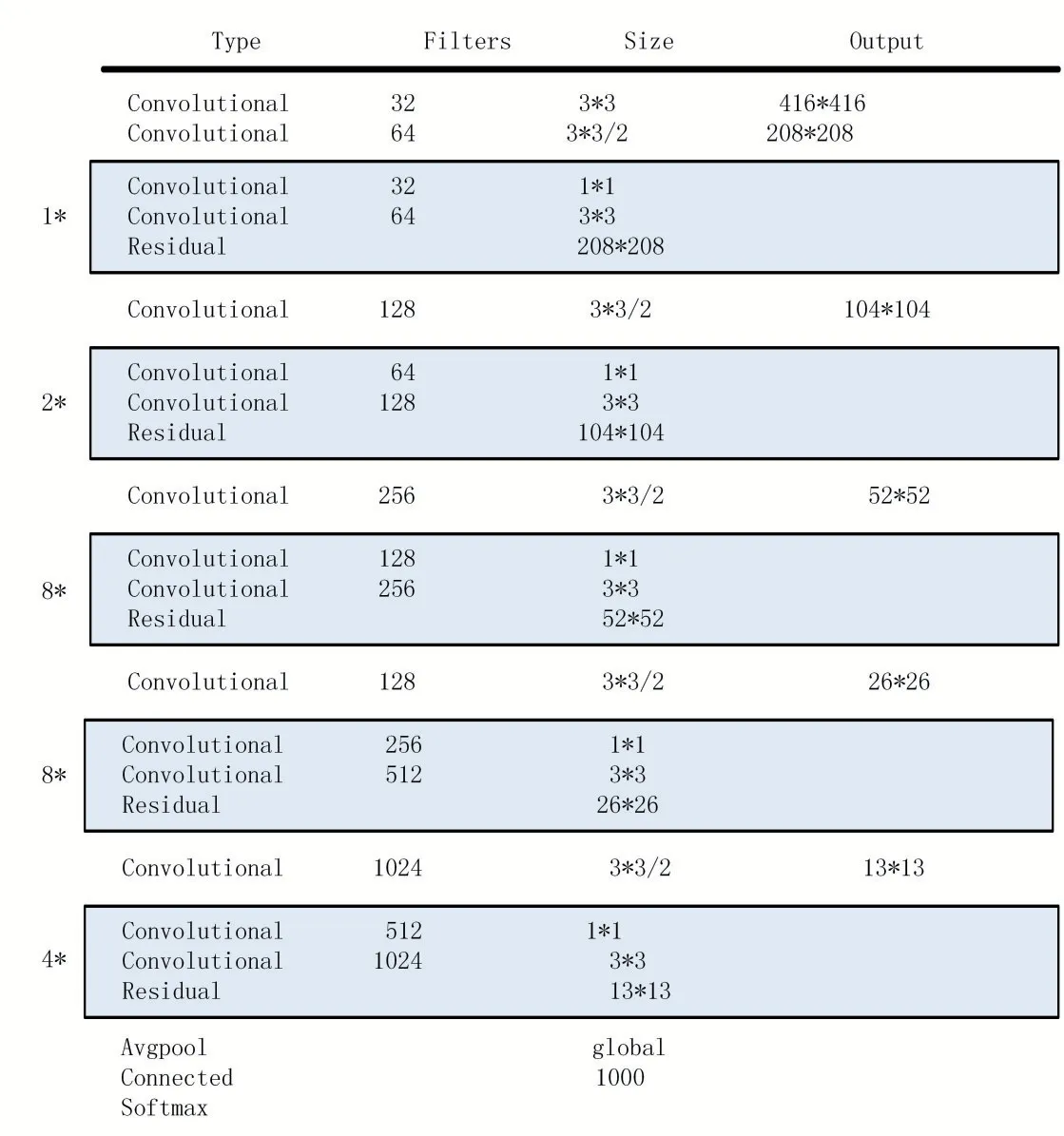
图1 DarkNet-53示意
另外DarkNet-53 网络相比于传统的神经网络,采用的是全卷积结构[11],理论上因此可以支持任意大小的图像输入,不过由于内部采用了5 个步长为2 的下采样来降低网络计算中的信息损失,因此只支持任意25=32 的倍数的输入图像尺[12]。特征提取网络会将尺寸为52×52、26×26 和13×13 这3 层特征图提取出来输出到检测网络进行接下来的处理。
检测网络采用多尺度检测机制。首先对输出的13×13 的图上进行第1 次检测,一个像素点对应输入图片416/13=32 个像素点,因此对大目标的检测效果较好;之后将其上采样与26×26 特征图融合,此时一个像素点对应输入图片16 个像素点,适用于检测中等尺寸的目标;同理对26×26 的特征图上采样并与52×52 的输出特征图融合完成第三次检测,此时一个像素点对应输入图片8 个像素,适用于检测小尺寸的目标。可以发现检测网络采用多级金字塔的思想,增强了对不同尺寸的目标特别是小目标的检测能力。
YOLOv2 后的YOLO 网络都使用锚点框(anchor boxes)来检测目标[13]。每个边界框会被预测4 个坐标(tx,ty,tw,th),分别代表其相对坐标以及宽度和高度。定义网格的坐标(cx,cy),锚点框宽和高分别为(pw,ph),便可计算出边界框的位置为:

其中(bx,by)为预测边框的中心坐标,(bw,bh)为其宽度和高度。YOLOv3 的损失函数如下,采用逻辑回归损失函数来预测每个边界框的得分。

损失函数由三部分组成,分别为置信度损失Econfi,坐标损失Ecoodi,以及类别损失Eclassi。如果当前预测的边界框比之前预测和真实对象重合度更高,那它的得分就是满分1。
2 改进的YOLOv3
YOLOv3 是一个通用的多类别检测网络[14]。与单分类检测网络不同,对不同类型不同特征的物体需要考虑到差异性,例如巨大的飞机和很小的猫,因此对特殊类型的检测能力并不是特别突出。同时因为YO⁃LOv3 网络的复杂度较高,例如其特征提取网络Dark⁃Net-53 一共有53 层之多,最大宽度达到了2048,参数量很大,网络的推理计算量比较耗时,无法达到在嵌入式平台上实时运行的要求。因此本文针对行人检测做出以下改进:
(1)对输入尺寸进行改进,由于目前监控相机图像尺寸多为1920×1080,因此裁剪到YOLOv3 的输入尺寸416×416 会损失很多特征信息,因此调整到960×512作为输入图像的大小。
(2)对网络尺度和深度进行精简,YOLOv3 特征提取网络为了检测80 分类问题,设计的网络尺度和宽度较深,但是单分类的行人检测无需这么强大通用的特征提取能力,因此对特征提取网络进行改进。
(3)改进损失函数,YOLOv3 是多分类的网络,但是行人检测只有一类,因此可以去掉分类置信损失,减少计算量。
2.1 网络输入改进
YOLOv3 输入图片尺寸一般为416×416,但是目前监控相机的常见像素大多是1920×1080,如果将其裁剪到416×416 会过分压缩图片质量损失很多信息并且长宽比会与原图像不协调,对检测的精度影响较大,因此本文采用960×512 的输入图像尺寸,之所以用960×512 尺寸的原因有以下两点:
(1)特征提取网络部分进行了5 次步长为2 的下采样,因此输入尺寸需要为25=32 的倍数,960/32=17,512/32=9,宽高符合输入要求。
(2)1920/960 ≈1080/512,较好地保持了原图的比例大小,对于原有图像的特征损失的较小。
2.2 对网络尺度和深度进行优化
DarkNet-53 的特征提取能力十分强大,因此可以支持YOLOv3 的多分类检测[12],并且其多级尺度检测是为了检测不同大小目标特别是特征不明显的小目标,但是对于视频行人检测来说,目标特征一般比较明显,不需要提取很小的特征,因此其需要的特征提取能力不需要这么强大,同时由于嵌入式设备性能相对较差,YOLOv3 的网络结构相比于算力比较复杂,实际运行过程速度较慢,无法达到实时性的要求,对网络分析可以发现,绝大部分时间都花在特征提取部分,因此我们对其进行改进,在不损失精度的条件下提升网络计算的速度。同时由于输入尺寸相对较大,因此我们增加一层7×7 的卷积,步长为2,能够在提取特征并且对图像进行压缩,同时减少网络的参数量,便于接下来的计算。
具体精简哪些层的网络需要进行分析,首先通过消融实验,即模拟删除该层的网络对输出精度的影响,对每层进行试验后,就可以确定每层的消除对于输出损失的影响,之后选取对输出影响最小的20 层将其删除,剩余的网络作为新的特征提取网络,并且同时对网络的宽度也进行压缩。
2.3 修改损失函数
由于本文算法的目的是只检测行人,而YOLOv3是一个多分类的网络,在输出层需要对检测的目标进行类别概率的预测,因此可以对其改进,只需要预测行人边界框和置信度,不需要对类别概率进行计算,从而减少了计算类别的工作量,因此与之对应的损失函数可以由两部分组成,其计算公式为:

式中,Ecoodi为位置损失,Econfi为置信度损失,对比原始YOLOv3 的损失函数,改进算法少了类别损失,YOLOv3 的单个输出框的参数量为N×N×3×(4+1+C) ,改进算法单个预测框的参数量仅有N×N×3×(4+1)。参数变少了因此降低了计算量。
2.4 改进后的网络结构
综上,对YOLOv3 的网络结构进行分析,并针对行人检测的特点对其进行了调整和优化,使之能更好地适用行人检测,改进的网络结构如图2 所示。
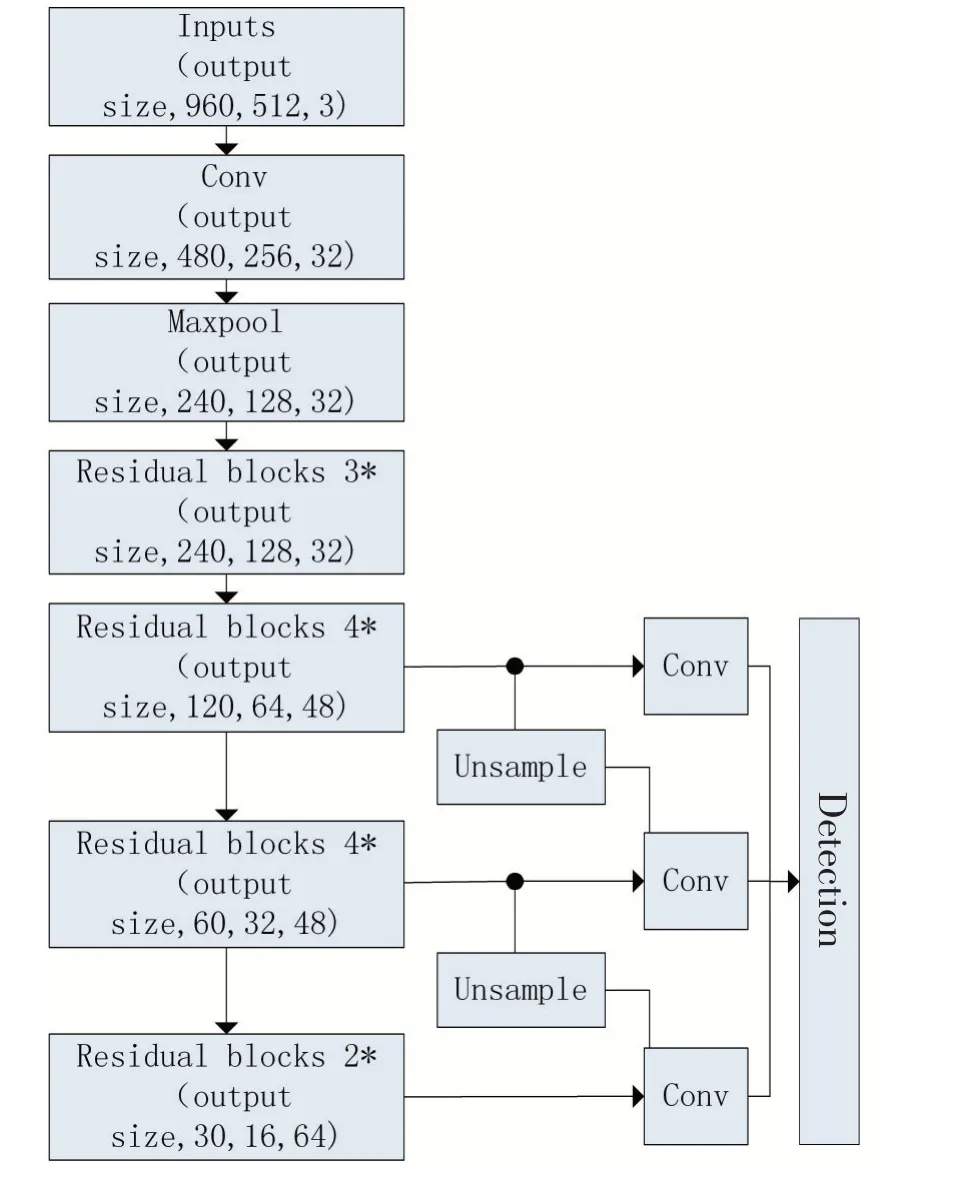
图2 改进网络结构示意
3 实验过程与分析
3.1 实验环境及训练过程
本文的实验环境包括训练所用的训练平台和测试所用的嵌入式平台。
训练平台配置如下:处理器型号Intel Core i5-9700,8 Gb 内存,Ubuntu16.04 操作系统,显卡为NVIDIA GeForce GTX1080Ti,显存11 Gb,训练框架使用开源深度学习框架DarkNet。
嵌入式平台配置如下:开发板芯片采用海思Hi3559A,处理器为双核ARM Cortex A53,2 Gb 内存,操作系统为海思HiLinux,使用3559A 自带神经网络推理机NNIE(Neural Network Inference Engine)推理。
本文选择COCO 数据集作为训练集,不过COCO是个种类齐全的多分类的数据集,因此将行人分类的图片单独提取出来,选取其中的10000 张图片为作为训练样本。训练步骤及参数设置如下:迭代批量32,动量0.9,衰减系数0.0005,迭代次数100000 次。
3.2 结果分析
下图为改进网络训练过程的loss 以及mAP 统计图,可以看到迭代到40000 步的时候loss 趋于稳定,到60000 步的时候mAP 趋于稳定。

图3 训练损失及精度
为了验证改进算法的精度和实时性,我们选取YOLOv3 以及同样以快速为特点的YOLOv3-tiny 来作为对比,表1 为在嵌入式平台下的对统一数据集下的测试结果,均使用量化后的权重。由表可以看出,本文算法的原始权重大小仅为YOLOv3 的1/64,YOLOv3-tiny 的1/9,量化权重为YOLOv3 的1/45,YOLOv3-tiny的1/6,模型权重占用的内存极小,更适合在嵌入式平台使用;速度上相比于YOLOv3 快了454.1%,达到了101.4fps,和YOLOv3-tiny 差不多,达到了实时性的要求;并且在精度上本文算法mAP 达到了84.4%,YO⁃LOv3-tiny 仅有57.7%,精度上相对YOLOv3-tiny 提升了许多,相比于YOLOv3 也没有明显的下降,因此本文的算法模型在精度和速度总体上具有更好的表现。
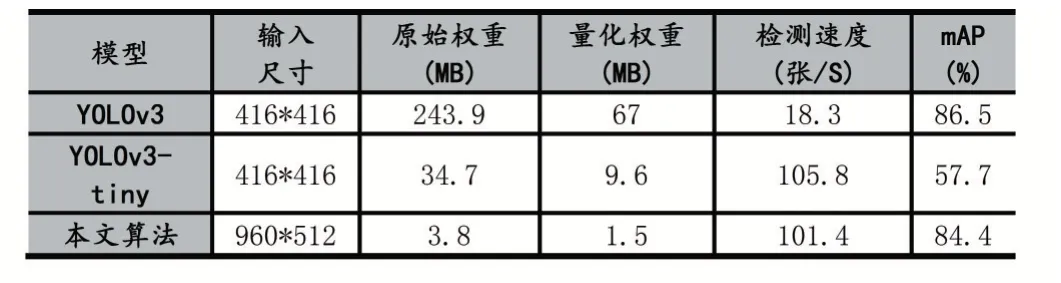
表1 算法性能对比
为了更直观地显示改进算法的效果,我们给出三种算法在实际情况下测试的实例图片,如图4-图6。

图4 YOLOv3-tiny

图6 YOLOv3
可以直观看出,YOLOv3-tiny 存在漏检和误检的情况,但是本文改进算法和YOLOv3 没有漏检和误检。
4 结语
针对嵌入式设备性能较差计算力弱,无法同时达到高速度高精度的行人检测需求,本文提出一种基于YOLOv3 的改进算法,通过对YOLOv3 特征提取网络进行精简,保留其提取大目标的能力,减少了网络计算的时间,增加其提取特征的能力,并且对损失函数进行改进,将类别损失函数舍弃,降低了计算量,最后实验结果表明,改进算法的参数量仅为YOLOv3 的1/47,在嵌入式平台上速度上相比于原始YOLOv3 提升了454%,达到了101fps,并且在精度上接近YOLOv3,因此改进算法符合实际生产环境的需求。不过该算法在极其恶劣的条件下的检测还是存在漏检和误检的情况,因此还需要扩充数据集,并且对网络进一步优化。

图5 改进算法
猜你喜欢
导航定位学报(2022年5期)2022-10-13
汽车实用技术(2022年13期)2022-07-19
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
电机与控制学报(2018年9期)2018-05-14
小天使·一年级语数英综合(2017年6期)2017-06-07
计算机应用(2016年10期)2017-05-12
图书馆界(2013年5期)2013-03-11
现代电子技术(2009年6期)2009-05-31
电子设计应用(2004年7期)2004-09-02
