
基于人脸检测自动服务机器人的设计
2021-07-02 12:22吴晶莹
电子测试 2021年11期
吴晶莹
(中北大学理学院,山西太原,030051)
0 引言
在人口密度大、就餐时间规律的大型场所,用餐环境的特性是在固定的用餐时间都会有人流的激增,造成短时间内的拥堵,服务员忙碌不能及时提供服务。本设计可以自动巡逻式检测人脸,当发现目标人脸对其眨眼,机器得到指令给用户提供所需。本项目是基于人脸检测系统上的智能化用餐服务配发设备,搭载上智能车平台,按需移动实现移动式配发。
1 总体设计
本设计的重点也是核心是人脸检测系统,首先需要搭建完成人脸检测系统。对于人脸检测的系统主要有两种设想,一是通过搭建神经网络来对人脸及动作进行检测,二是通过Haar Cascade分类器来进行人脸检测,动作识别则需要其他算法来求解或者寻找其他办法来进行确认。此外便是搭建移动式平台,本设计因需要具有略大负载能力的智能车,此处便选择了恩智浦智能车竞赛里越野组所用的 L型车模。总体实现的流程图如图1所示。

图1 总体实现流程图
2 人脸检测系统原理
2.1 人脸检测
人脸检测是指对电子设备采集到的图像进行搜索,找到所有可能是人脸的位置,并返回人脸位置和大小的过程。在这个过程中,系统的输入是一张可能含有人脸的图片或者视频输入,输出是人脸位置的矩形框。获得包含人脸的矩形框后,第二步要做的就是人脸对齐(Face Alignment)。原始图片中人脸的姿态、位置可能较大的区别,为了之后统一处理,要把人脸“摆正”。为此,需要检测人脸中的关键点(Landmark),如眼睛、鼻子、嘴巴的位置、脸的轮廓点等。通过Python自带的FacialLandmark Detection功能,它可以检测出面部的68个关键点,如下图2所示。
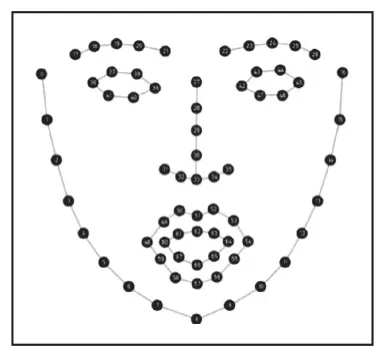
图2 人脸68个关键点
根据这些关键点可以使用仿射变换将人脸统一校准,以尽量消除姿势不同带来的误差。识别人脸可以使用机器学习算法和工具Dlib,也可以使用OpenCV,通过实际操作情况可得OpenCV识别的速度比Dlib要快得多,但是OpenCV的识别正确率较低,所以,经过综合考虑,采用Dlib对人脸进行识别。利用OpenCV对检测到的人脸画出方框进行反馈。上述过程的实现效果如下图3所示。

图3 实现效果图
由于颜色信息对于人脸检测没有影响,且为了减小条带失真和减少计算量要将图片灰度化。对每个像素以及其周围的像素进行分析,依据明暗度画一个箭头,重复操作,这些像素将会被箭头即梯度(gra-dients)所取代。最终将原始图像转换成一个非常简单的HOG表达形式,便于捕获面部的基本结构。如图4所示。

图4 图像HOG转换
2.2 眨眼识别
针对人脸面部动作——眨眼识别。本设计采用的是Soukupová和Cech发表的论文《使用面部标志实时眼睛眨眼检测》推导出反映这种关系的方程,称为眼睛纵横比(EAR)。

这个方法与传统的计算眨眼图像处理方法是不同的,使用眼睛的长宽比是更为简洁的解决方案,它涉及到基于眼睛的面部标志之间的距离比例是一个非常简单的计算。其中p1,p2,p3,p4,p5,p6是2D面部地标位置如图5(a)所示,图5(b)是闭眼地标所在位置。

图5
通过观察绘出的眼纵横比随时间的视频剪辑的曲线图,如下图6所示。可知眼睛纵横比是恒定的,然后迅速下降到接近零,然后再增加,表明进行一次眨眼。

图6 人眼眨眼检测数据
在上一步检测的基础上我们已经得到了68个面部特征,从这些特征点可以很容易的计算出眼睛纵横比,这时主要的程序循环部分已经出来了,也就是说,通过while循环从摄像头部分读取每一帧,在检测部分中将其转化为灰度图并检测人脸。通过遍历脸部,在每个脸部应用面部标志检测得到68个关键位置,然后提取左眼和右眼的坐标来计算长宽比,以检查眼睛长宽比是否低于我们的眨眼阈值,如果是,则表示正在进行眨眼;否则,我们将处理眼睛宽高比不低于眨眼阈值的情况,并检查是否有足够数量的连续帧包含低于预定义阈值的眨眼速率。因为是要用于餐具放下时的确认工作,此时的“眨眼”应为有确认意义的“闭眼”,一帧时间为1 /12s,而眨眼一次时间为0.2到0.4s,所以只需要判断大于5帧或者保险起见大于6、7帧的“眨眼”就可作为确认信号了。
2.3 分类器的选择
实现人脸检测的流程主要包括人脸Haar—like特征提取、AdaBoost级联分类器生成以及人脸检测结果三个环节。adaboost算法首先使用haar-like特征表示出人脸,但是此时得到的人脸特征值并不精确,然后通过增加阈值的方式设计出弱分类器,对特征值进行筛选,此时得到的人脸特征值还是比较粗糙,因此将弱分类器并联起来组成强分类器,经过强分类器筛选之后的特征值非常接近真实的人脸特征值,为了增加检测速度,以级联的形式将已获得的强分类器串联成最终的分类器,Rainer Lienhart和Jochen Maydt两位将这个进行了扩展,最终形成了OpenCV现在的Haar分类器。经过长时间的改进,我们利用Haar特征分类器来检测人脸并利用眼睛的位置判断动作。
3 系统硬件的搭建与选择
基础系统构成包括基于ARM11的嵌入式系统开发板树莓派(Raspberry Pi)3B+、CSI视频接口摄像头元件、显示屏。因为该平台开始处理图像时视频帧数会极低,极大地影响到正常动作识别,成功率也因此大大降低。为此我们选用了新的开发平台——Nvidia JETSON Nano,如下图7所示。

图7 Nvidia JETSON Nano
Jetson Nano提供472 GFLOP,用于快速运行现代AI算法。它可以并行运行多个神经网络,同时处理多个高分辨率传感器,非常适合入门级网络硬盘录像机(NVR)、家用机器人以及具备全面分析功能的智能网关等应用。利用Linux+Python的编程环境和Python语言的可跨平台特性,代码的移植没有太多障碍,辅以OpenCV这一开源计算机视觉库,来进行基本的图像处理。
底部的智能车选用的是竞赛用的恩智浦智能车L型车模,因为其负载能力大,在越野组的竞赛中表现优异,故将其作为移动式平台。我们用基于ARM Cortex-M4内核、带有高级外设的节能型MCU的LPC54606搭建了一个遥控L车来进行测试。使用逐飞的LPC普通组主板+LPC核心板+MOS单驱搭建的测试平台对车模进行控制。通过采集接收机的PWM占空比信号,解析出遥控器的动作。并使用LPC控制电机以及舵机动作。工作时:通过蓝牙模块接受上位机的跑位信号,在固定的路线慢速巡航配发,当接收到紧急信号的时候迅速跑到感应器位置进行工作。该机器人设计工作流程如下图8所示。
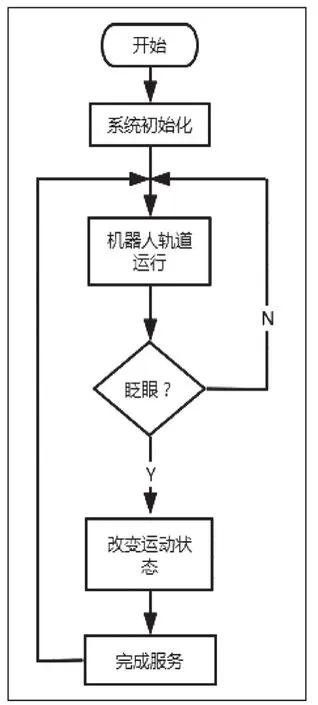
图8 机器人工作流程图
4 结论
该智能服务设计旨在方便用户,在用餐高峰期有效识别用户以机器视觉的形式进行用餐。该装置可扩展性很高,在此基础上可以增加餐具回收或者餐具消毒功能。目前这款装置的缺陷在于,若用餐者佩戴眼睛装饰品比如眼镜的时候,面部特征标记的68个点位置偏差较大,在光线过于明亮的环境中,眼镜的反光会使眼部特征无法检测与辨认。但总体而言,在条件合适的工作场景下,该配发装置具有较高的工作效率,可以缓解日常餐厅就餐使得人流拥堵现象。
猜你喜欢
品牌研究(2022年8期)2022-03-23
品牌研究(2022年1期)2022-03-18
数学物理学报(2021年5期)2021-11-19
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
动漫星空(2018年9期)2018-10-26
数学物理学报(2018年3期)2018-07-17
小太阳画报(2018年4期)2018-05-14
创新作文(小学版)(2017年22期)2017-04-04
