
井下复杂环境人员重识别研究
2021-07-02 08:56魏力云霄程小舟孙彦景
工矿自动化 2021年6期
魏力,云霄,程小舟,2,孙彦景,3
(1.中国矿业大学 信息与控制工程学院, 江苏 徐州 221116;2.中钢集团马鞍山矿山研究院股份有限公司 选矿及自动化研究所,安徽 马鞍山 243000;3.徐州市智能安全与应急协同工程研究中心, 江苏 徐州 221116)
0 引言
目前对煤矿智能监控的研究大多针对煤炭开采和运输设备监测或相关作业人员行为识别[1-2],缺乏对人员个体的智能识别,人员监管效率低。人员重识别是一种利用计算机视觉算法在图像或视频序列中查找特定人员的智能识别技术,根据给定人员的穿着、姿态、发型等信息检索跨设备下该人员的其他图像,可与人员检测、跟踪技术相结合,应用于智能安保、智能视频监控、智能检索等领域。将人员重识别技术用于煤矿智能视频监控系统,对提高煤矿人员监管效率、减少安全事故的发生具有重要意义。
人员重识别主要包括特征提取和特征度量2个部分。传统的人员重识别方法是先设计描述人员图像的手工特征,再建立模型来计算手工特征之间的相似性[3-4]以进行匹配。然而这种基于手工特征的人员重识别方法对人员特征的描述能力有限,难以适用于复杂场景下的大数据集任务。随着深度学习技术的发展[5-6],基于卷积神经网络(Convolutional Neural Network,CNN)的人员重识别方法不仅能够自动学习出复杂的特征描述,还能实现端到端的人员重识别任务,从而简化人员重识别模型。文献[7]提出一种人员干扰抑制网络,利用一个全卷积网络提取人物图像的特征,然后在待查询人员特征的引导下增强候选图库中目标人员的特征,同时抑制干扰人员的特征。文献[8]将知识蒸馏应用到人员重识别网络中,通过引入一个推理能力强但复杂度高的教师网络来引导一个参数量较少的学生网络训练,使其在获得高精度结果的同时拥有较低的复杂度。文献[9]提出一种多尺度自适应超分辨率人员重识别网络,利用超分辨率生成对抗网络对分辨率较低的人员进行再生,以解决因人员图像分辨率差异造成的错误匹配问题。上述人员重识别方法在公共数据集中取得了较好性能,在一定程度上解决了视频监控系统中同一人员外观强烈变化时的匹配问题。但受煤矿井下环境复杂性和视频监控设备性能局限性的影响,摄像头捕获的人员图像存在分辨率低、遮挡、背景干扰等问题,导致人员差异性较小,应用上述方法时识别精度不理想。
本文提出了一种基于通道注意力和距离度量的网络(Distance-metric Channel Attention Network,DCAN)结构,并将其应用于井下复杂环境人员重识别。该网络针对井下人员与背景不易区分的难点,引入通道注意力模块(Channel Attention Module,CAM)[10],在提高人员前景特征信息的同时抑制背景信息,并扩大网络输出特征图的尺寸,以获得更多的细粒度信息,丰富人员的判别特征,从而增强网络对特征的学习能力;在实现井下人员身份(Identity Document,ID)分类的基础上,利用图像特征间的绝对距离信息,通过距离度量模块(Distance Metric Module,DMM)对难识别图像进行采样和加权处理,增加难样本在反向传播时的权重,使其更加关注具有判别力的人员特征,提高井下人员重识别的准确度。
1 DCAN框架设计
DCAN框架如图1所示,包括用于提取图像特征的骨干网络和用于特征度量的分支结构。对于输入为256×128的人员图像,首先通过骨干网络提取人员的深度空间特征,得到2 048×16×8的特征图;然后采用全局平均池化(Global Average Pooling,GAP)层对空间特征信息进行汇总,得到2 048×1×1的特征向量;最后利用该特征向量进行下一步的度量。
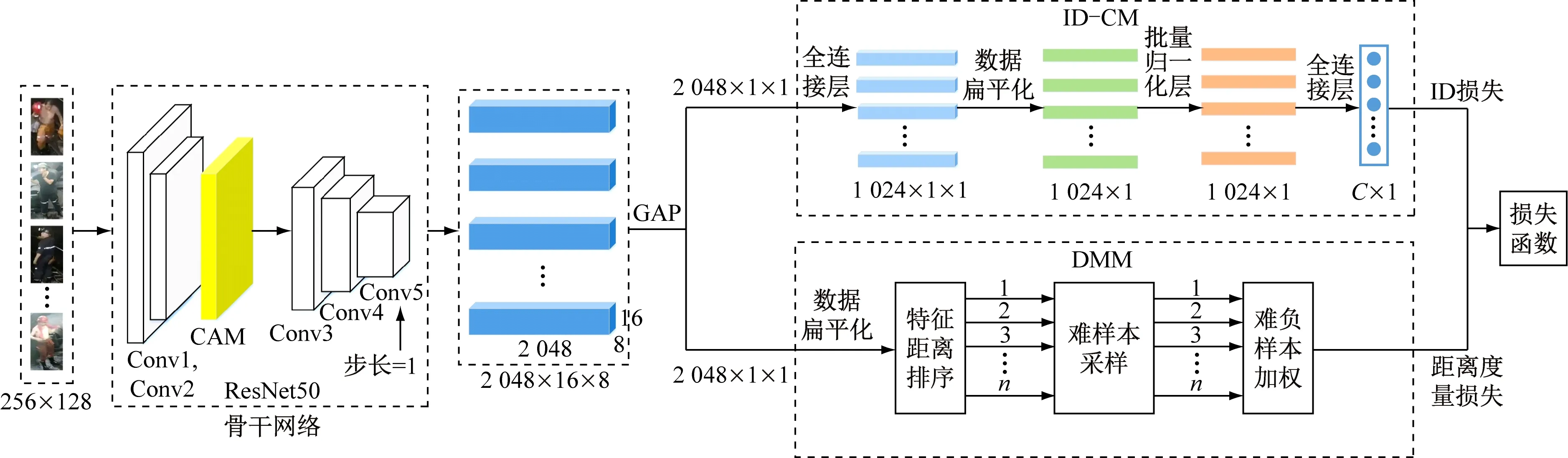
图1 DCAN框架Fig.1 DCAN structure
在特征提取阶段,为了丰富预测阶段的人员特征信息,使网络更加关注与人相关的特征,在骨干网络ResNet50的Conv2层之后没有直接进行下采样,而是通过CAM对其输出的深度特征进行重新分组和聚合。同时,为了获取人员的细粒度特征,将Conv5层最后1次下采样的步长设置为1,使输出的空间特征图尺寸扩大1倍,提高特征图的空间分辨率。
在特征度量阶段,由于学习目标不同,将其设计为2个分支结构,即ID分类模块(ID Classification Module,ID-CM)和DMM。首先,为了学习出不同ID人员在特征空间的差异性,将人员重识别视为多分类问题,用人员的ID作为标签来监督网络训练过程,通过ID-CM来区分每类人员的特征;然后,为了学习出相同ID人员间的相似性,充分利用特征间的绝对距离信息,通过DMM使同一人员不同图像间的相似度大于不同人员的不同图像;最后,联合ID损失和距离度量损失共同优化特征层,从而学习出一个判别能力足够强的模型。
2 骨干网络
在人员重识别任务中,设计骨干网络来学习人员的特征表达是关键。骨干网络的特征表达能力越强,所提取的特征越可靠,由此构建的重识别网络性能越好。基于CNN的骨干网络可通过增加网络层数来提升性能,但当层数增加到一定程度后,由于梯度消失或爆炸等原因,训练误差和测试误差会逐渐增大。ResNet50[11]通过在网络中融入跳层连接和残差拟合策略,不仅可以训练出更深的CNN模型,而且提高了模型的准确率。因此,本文选取ResNet50作为骨干网络实现人员的特征表达。
在ResNet50特征提取过程中,每个卷积通道所提取的特征与语义相互关联。以图2所示的通道特征为例,通道c1,c3,c9能够提取出具有语义相似性的人员前景特征信息,通道c2,c4,c6,c11能够提取出与人员不相关的背景信息。为了区分井下人员与背景,使网络更加关注与人相关的特征信息且抑制不相关的背景信息,在ResNet50基础上引入CAM[10],将语义相似的通道特征进行重组再聚合,即先根据各通道间的特征相关性进行分组,然后对语义相似的通道特征进行融合,组成新的特征,以增强单一通道的特征信息量,提高网络的特征提取能力。
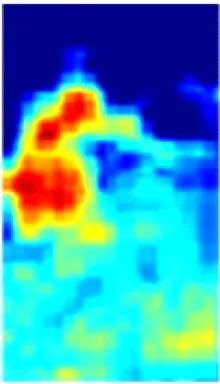
c1

c2
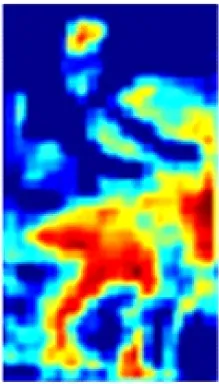
c3
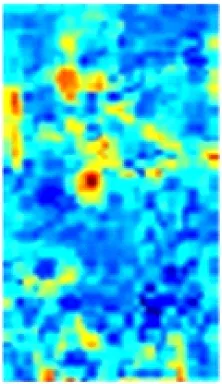
c4
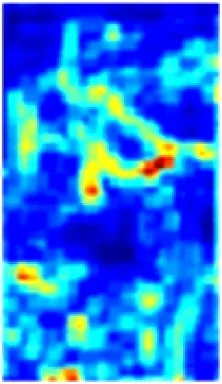
c5
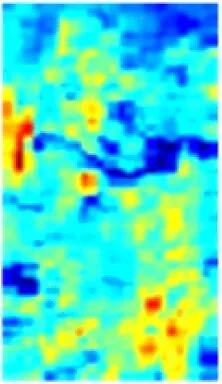
c6
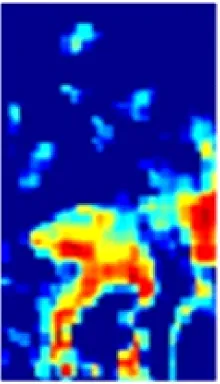
c7

c8
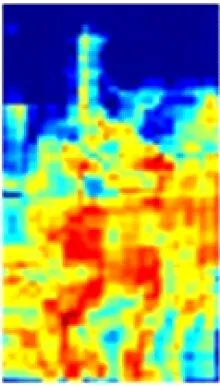
c9

c10
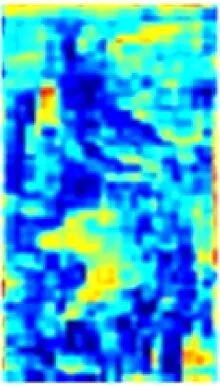
c11
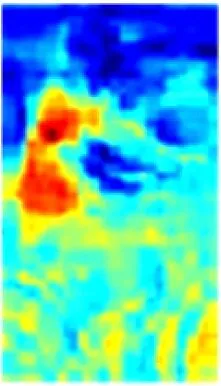
c12
CAM结构如图3所示。对于Conv2层输出的特征图A∈RC×H×W(C为特征通道数,H为特征图高度,W为特征图宽度),首先进行降维操作以降低计算复杂度,得到大小为C×M(M=H×W)的通道特征矩阵;然后通过该通道特征矩阵计算各通道间的相关性,得到特征相关性矩阵X∈RC×C;最后根据各通道特征间的相关性进行重组再融合,得到具有丰富人员信息的特征图E∈RC×H×W。相关计算公式如下。
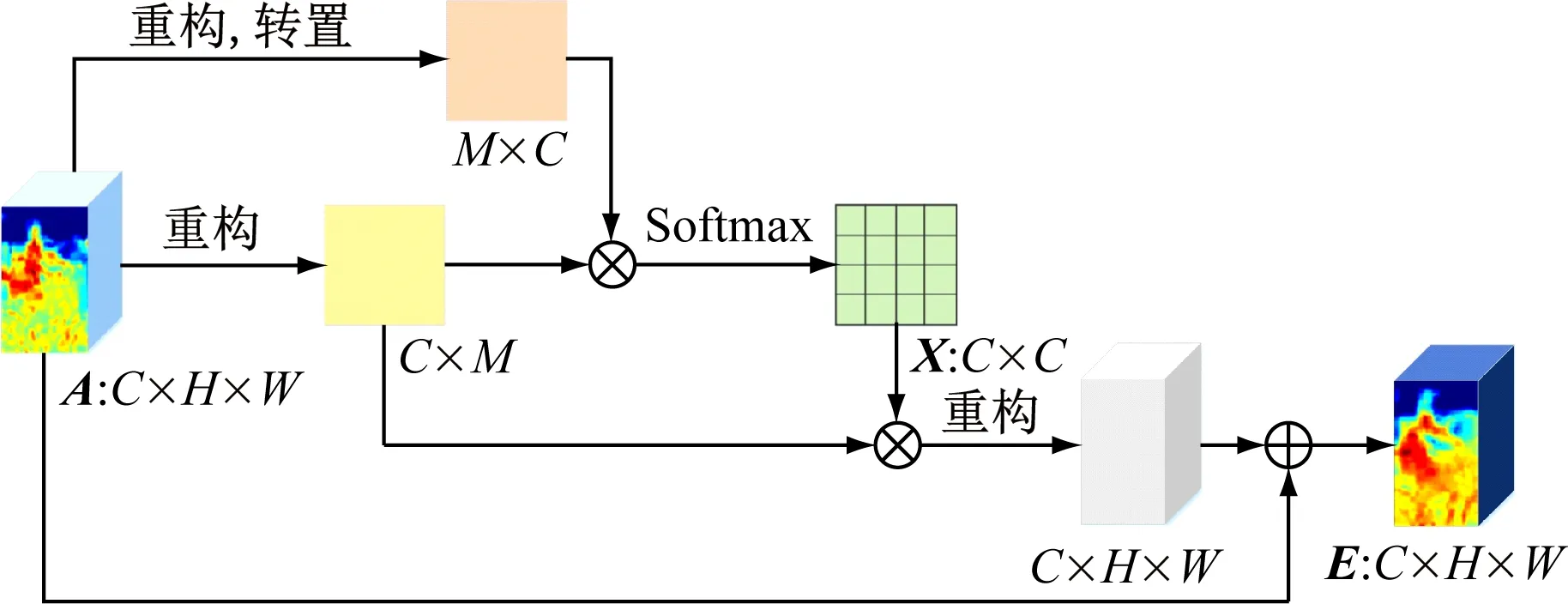
图3 CAM结构Fig.3 CAM structure
(1)
(2)
式中:xij为通道i对于通道j的影响,xij∈X;ai,aj分别为通道i,j的特征向量。
本文中C取256,H取64,W取32。
在特征空间中,特征粒度越小,细节特征越明显,而具有较高分辨率的特征图往往会带来更加丰富的细粒度特征。对于输入大小为256×128的图像(图4(a)),当骨干网络中Conv5层下采样步长为2时,输出大小为8×4的特征图(图4(b));当步长为1时,输出大小为16×8的特征图(图4(c)),较图4(b)包含更多的像素,提供更多的细粒度特征。因此,将Conv5层下采样步长设置为1。
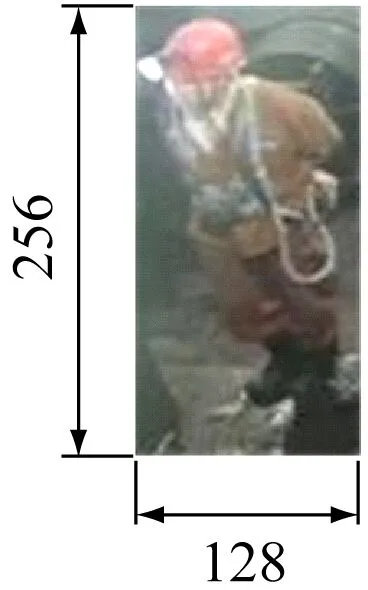
(a) 输入图像
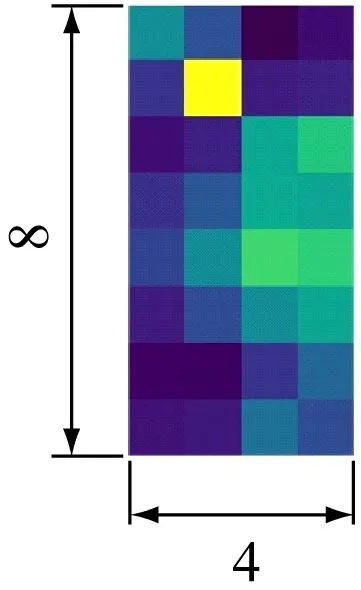
(b) 步长为2
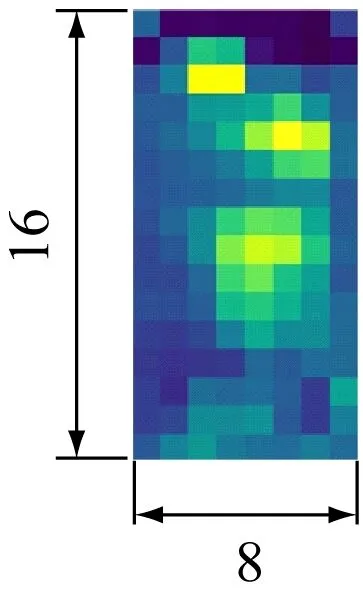
(c) 步长为1
3 ID-CM
ID-CM架构如图1所示。首先,对于GAP输出的2 048×1×1特征,采用全连接(Full Connection,FC)层将2 048维特征降到1 024维,在减少计算量的同时,综合有效信息并摈弃无用信息,从而减少冗余信息造成的误差,提高识别精度;然后,通过数据扁平化操作将多维数据一维化来降低计算复杂度,提高识别速度;其次,加入批量归一化(Batch Normalization,BN)层将一维特征的数据分布拉回服从标准分布的归一化特征,增大反向传播时的梯度,加快网络收敛速度和训练时间;最后,再次加入FC层,通过整合前端具有类别区分性的归一化特征信息完成分类任务。
在进行特征分类时,先利用softmax激活函数对每个人员进行ID概率预测,再用交叉熵损失函数来约束网络参数优化,利用监督信息使网络学习到具有类别差异性的人员特征。假设每个批次需要处理n张人员图像,对其进行特征提取,得到每个人员的判别ID描述向量F,则交叉熵损失函数可表示为
(3)
式中:p为人员ID预测概率,p=softmax(F);y为每个输入图像的实际ID,y∈{1,2,…,K},K为ID数量,即训练集中人员类别数;pk为人员图像属于第k类ID的预测概率;qk为人员图像属于第k类ID的真实概率,若预测ID与真实ID相同,则qk=1,否则qk=0。
由式(3)可看出,若仅采用交叉熵损失函数作为人员ID分类损失来衡量预测ID与真实ID之间的差异,网络只会考虑预测ID正确的损失值,而将其他ID的损失值完全丢弃,使网络在训练过程中过分相信人员的ID标签,过于关注增大预测正确标签的概率,而减小预测错误标签的概率,最终导致网络出现过拟合现象且泛化能力较差。为了解决该问题,防止网络训练时的标签监督信息极端化,采用标签平滑正则化[12]对交叉熵损失函数中的qk进行处理,使预测的所有信息都能得到一定程度的保留,增强网络的泛化能力。经标签平滑正则化处理后的qk为
(4)
式中ε为平滑因子。
通过ε来控制ID预测概率的权重,以抑制过拟合问题。本文将ε设置为0.1。最终将标签平滑正则化后的交叉熵损失函数作为人员的ID损失LID,引导网络提取具有类别区分性的人员特征。
(5)
4 DMM
特征度量的目标是使相同ID人员间的特征距离最小化的同时,不同ID人员间的特征距离最大化,即类内距离最小、类间距离最大。虽然ID-CM已通过ID损失学习出不同ID人员在特征空间的分界面,但ID损失更倾向于增大类间距离以分离不同ID的人员,而不会缩小类内距离使相同ID的人员更加聚集。基于排序动机的深度度量方法[13]利用训练集中全部样本间的特征距离建立相似度结构,根据样本间的距离分布在不同层次上对数据进行划分,不仅可保持类内的相似结构,还能加快网络收敛速度。受深度度量方法的启发,为增强相同ID人员间的聚类性能,采用DMM来学习同一ID人员间的相似性。与一般使用度量学习进行相似性计算的方法不同[14-15],DMM充分利用每个样本间的绝对距离信息,根据距离阈值对所有难样本(难正样本和难负样本)进行采样,并使难负样本在反向传播过程中拥有较高的权重,不仅能在减小人员类内距离的同时增大类间距离,还能在网络最终收敛时使各类样本均达到聚类效果,从而使网络具有更好的特征表达能力。
DMM主要包括特征距离排序、难样本采样及难负样本加权3个子模块,如图1所示。特征距离排序主要用于计算每个批次图像的特征距离并从小到大进行排序;难样本采样负责根据排序结果和距离阈值挑选难正样本和难负样本;难负样本加权用于根据特征距离对采样后的负样本进行重新加权处理。
4.1 特征距离排序
针对每个批次中的n个训练样本,将每个样本依次作为查询样本,其余样本作为候选样本。如果候选样本与查询样本属于同一个人员,即具有相同ID,则为正样本,否则为负样本。令查询样本为Ia,候选样本为Ib,根据欧氏距离计算Ia,Ib之间的特征距离:
(6)
式中fIa,fIb分别为Ia,Ib通过网络前向传播得到的特征向量。
按递增顺序对样本间的特征距离进行排列,得到初始排序列表,相似度越高则排序越靠前。训练批次中每个查询样本均可得到1个初始排序列表,因此1个训练批次可得到n个初始排序列表。
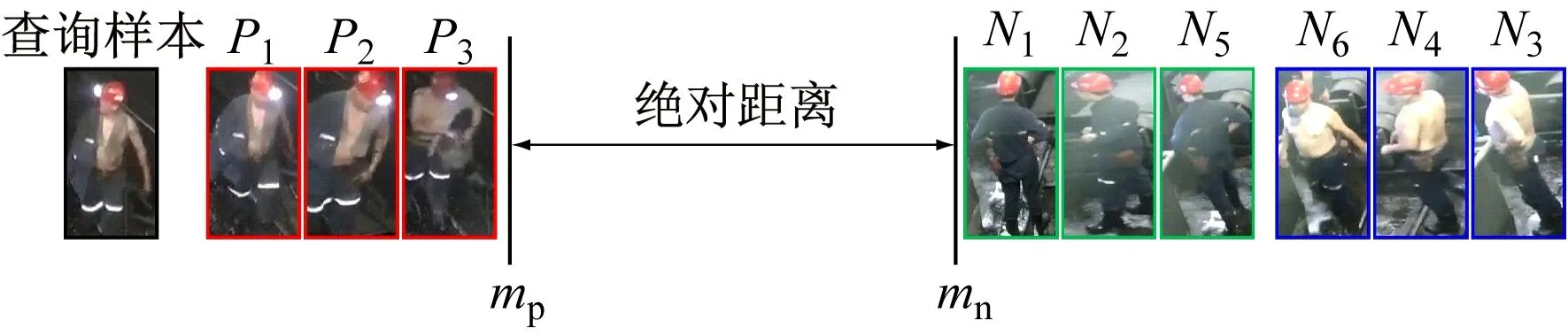
DMM训练批次排序列表如图5所示,其中人员图像代表每个批次选取的样本,除查询样本外,其余均为候选样本。在候选样本中,不同颜色代表不同类别的样本,且P1—P3为正样本(与查询样本类别相同),N1—N6为负样本(与查询样本类别不同)。

(a) 初始排序列表
(b) 目标排序列表
由于井下人员图像容易受到光照、遮挡、视角及相机分辨率的影响,仅依靠ID-CM对人员特征进行度量无法实现准确识别,导致在初始排序列表中存在负样本(如N1,N2,N3)排序靠前而正样本(如P2,P3)排序靠后的现象。因此,对每个查询样本,DMM先通过2个距离阈值——正样本阈值mp和负样本阈值mn来约束样本间的距离度量过程,其目标是将每个查询样本的正样本拉到mp以内且将负样本推到mn以外。
LM(Ia,Ib)=Yab[d(Ia,Ib)-mp]++
(1-Yab)[mn-d(Ia,Ib)]+
(7)
(8)
式中:LM(Ia,Ib)为样本间距离度量损失;[·]+=max(·,0);ya,yb分别为Ia,Ib的ID标签。
4.2 难样本采样
在度量过程中,每个批次的样本都是从训练集中随机挑选的,而网络常挑选出一些比较容易识别的样本,导致人员重识别网络的泛化能力受限。由于特征距离较大的正样本和特征距离较小的负样本(统称为难样本)在训练过程中易产生较大损失,能更好地体现样本间的差异性,所以在网络训练时在线挑选出难样本并对其训练[16],以提高网络对正负样本的判别能力。
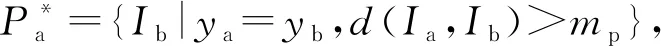
在度量学习过程中使用难样本采样,可压缩训练样本,减少运算量,提升网络学习速度。
4.3 难负样本加权
在训练样本集中,每类查询人员的负样本数量远大于正样本。通过特征距离排序和难样本采样虽然可减小类内距离并增大类间距离,但由于负样本基数较大,导致网络更擅长在特征空间推开正负样本,使正样本之间的距离很近,却忽视了负样本间的类别差异性,导致不同类别的负样本在度量空间中的距离分布仍存在交叉问题。为了解决该问题,根据初始距离度量信息对难负样本进行加权处理,增加难负样本在反向传播时的权重,从而获得网络更多的注意力,提升网络识别能力和鲁棒性。对于每个查询样本Ia,加权策略为
(9)
式中ωab为难负样本权重。
经加权处理后,网络收敛时负样本之间会呈现聚类效应,最大限度地维持了同一人员样本间的结构相似性。将经过难样本采样和负样本加权处理的样本间距离度量损失[13]作为最终距离度量损失:
(10)
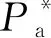
在训练过程中,通过最小化LDM来引导网络实现不同ID人员图像分离与相同ID人员图像聚集。
最终联合ID损失LID和距离度量损失LDM来优化特征层,以引导网络探索更具判别力的特征。目标损失函数为
(11)
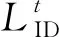
5 实验与结果分析
5.1 数据集
采用Miner-CUMT数据集验证DCAN的有效性。Miner-CUMT是由中国矿业大学工业物联网与应急协同创新实验室构建的一个适用于井下场景的数据集,包含由10个摄像头捕获的63 852张人员图像,被分为训练集、测试集和查询集,其中训练集包含1 000个人员的28 394张图像,测试集包含1 000个人员及干扰物的31 110张图像,查询集包含1 000个人员的4 348张图像,所有人员图像均由检测器自动检测并切割,更加接近真实场景。
5.2 实验环境
实验操作系统为64位Ubuntu 16.04,搭载4块NVIDIA 1080Ti GPU,采用CUDA9.0+cudnn7.1.1加速包,在Pytorch1.1.0深度学习框架中实现DCAN。在训练过程中,以Miner-CUMT训练集中的图像作为输入,将图像大小调整为256×128,并通过随机裁剪、随机水平翻转和随机擦除[17]来增强训练图像;网络迭代次数设置为120;批量大小设置为64,并使用Adam优化网络参数;初始学习率设置为3.5×10-5,且在前10次迭代过程中,学习率随迭代次数T呈线性变化,即3.5×10-5T/10,此后每迭代30次衰减至原来的0.1倍。在测试过程中,以Miner-CUMT测试集和查询集中的图像作为输入,先利用训练好的井下人员重识别网络提取特征,再根据欧氏距离计算人员间的相似性,从而进行ID匹配,以评估DCAN性能。
5.3 实验评估与分析
实验采用目前人员重识别任务中常用的2种评价指标——平均精度均值(mean Average Precision,mAP)和首位命中率(Rank-1)。mAP综合考虑了查准率与查全率,能反映所查询人员在图库中的所有正确图像排在结果队列前面的程度,能够全面衡量人员重识别方法性能;Rank-1表示检索结果中置信度最高的人员图像即第1名图像识别正确的概率。
为了验证CAM性能,选取原始ResNet50网络(包括Conv1—Conv5层)及ID-CM作为基准网络(Baseline),在不同的Conv5层下采样步长情况下进行实验,结果见表1。可看出Conv5层下采样步长为2时,Baseline添加CAM后,Rank-1为90.3%,mAP为74.1%,分别较无CAM的网络提高了2.1%和0.6%;Conv5层下采样步长为1时,具有CAM的Baseline的Rank-1达94.6%,mAP达76.5%,分别较无CAM的网络提高了0.7%和1.6%。实验结果不仅证实了在井下人员重识别网络中添加CAM的有效性,还说明改变Conv5层下采样步长有助于网络对人员特征进行学习。
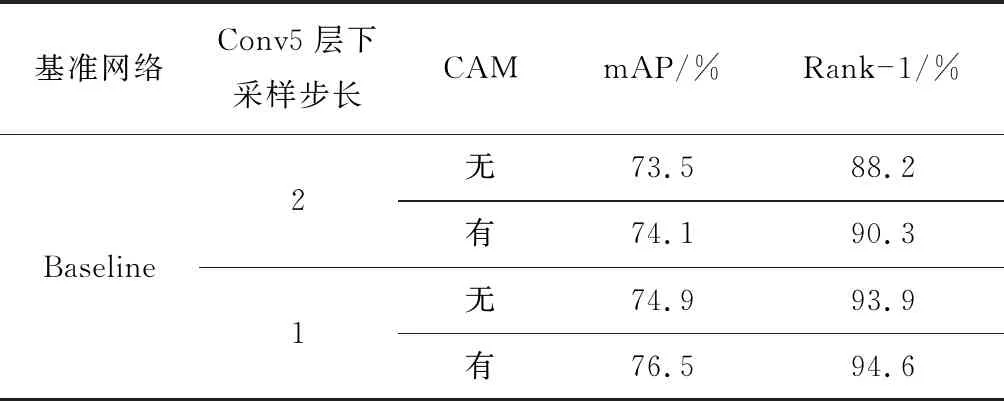
表1 CAM性能实验结果Table 1 CAM performance experiment results
在前端特征提取的基础上,为了评估DMM中距离阈值mp和mn对网络性能的影响,分别固定mp和mn,在DCAN上进行实验,结果如图6所示。可看出在mn一定的情况下,mp=0.8时Rank-1和mAP均达到最优值;在mp一定的情况下,mn=2.0时Rank-1和mAP均达到最优值;mp>0.8,mn>2.0时,随着距离阈值增大,Rank-1和mAP均明显下降。可见距离阈值对提高网络判别能力具有重要意义。本文将mp和mn分别设置为0.8和2.0。
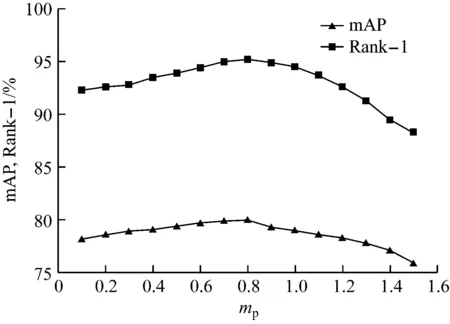
(a) mn一定,mp对网络性能的影响
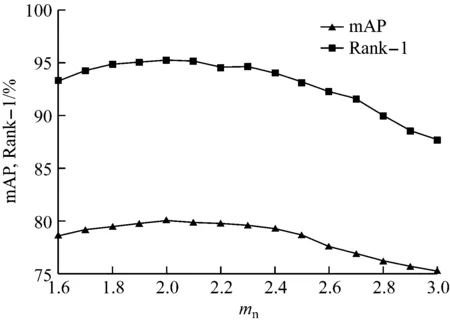
(b) mp一定,mn对网络性能的影响
为了验证DMM的有效性,在由骨干网络及ID-CM构成的网络(B-ID)上进行实验,结果见表2。可看出B-ID引入DMM(即DCAN)后,Rank-1达95.2%,mAP达80.0%,分别较无DMM时提高了0.6%,3.5%,说明添加DMM的网络能学习到更精确的人员特征,从而提高井下人员重识别的准确度。

表2 DMM性能实验结果Table 2 DMM performance experiment results
为了能更直观地观察DCAN对井下人员的判别能力,采用Grad-CAM++[18]方法对网络提取的人员特征进行可视化。从Miner-CUMT测试集中选取3张图像输入到训练好的网络中进行一次前向传播,Conv5层人员特征的可视化结果如图7所示,其中CAN为在Baseline基础上加入CAM并将Conv5层下采样步长设置为1的网络。从图7可看出,Baseline只能提取出人员的整体轮廓特征,且背景干扰较为严重;CAN能够增强人员特征的显著性,抑制背景干扰;DCAN不仅关注人员的轮廓特征,还能挖掘出更多关键且显著的信息,同时能抑制部分背景干扰,使得人员特征更具判别性,提高了对井下人员的重识别能力。

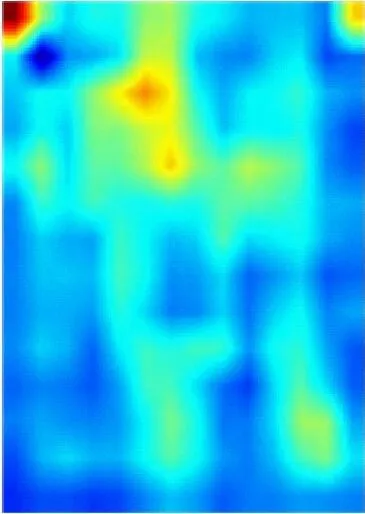



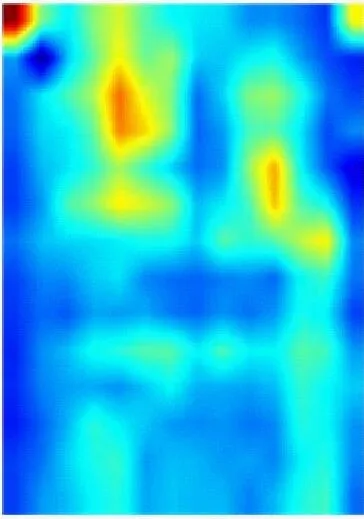
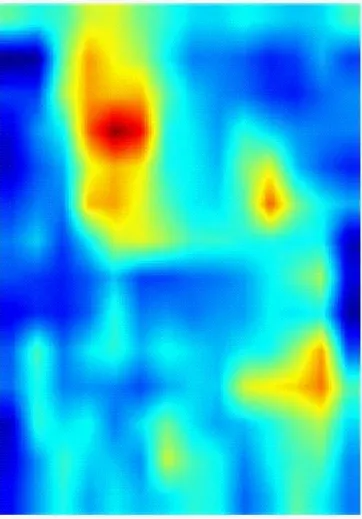
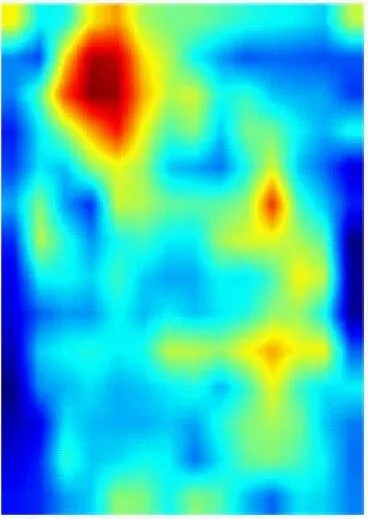

(a) 输入图像
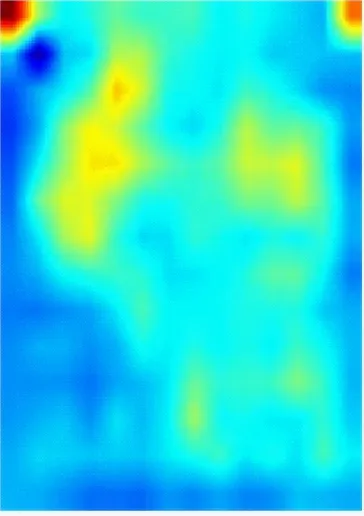
(b) Baseline
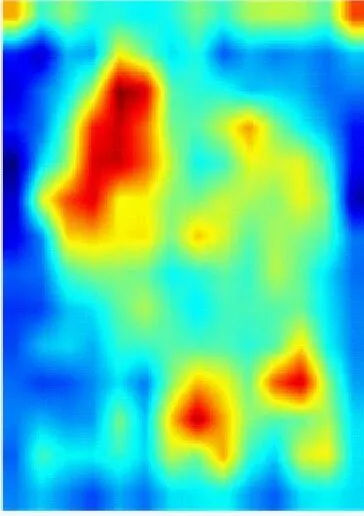
(c) CAN
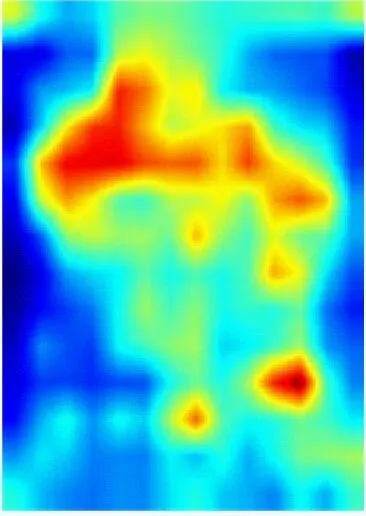
(d) DCAN
6 结论
(1) 针对井下环境复杂、人与背景不易区分等因素导致的人员难以正确识别问题,提出一种可用于井下复杂环境人员重识别的DCAN。
(2) DCAN在骨干网络中引入CAM,使网络能够学习到井下图像的人员前景特征,同时抑制与人不相关的背景信息,并将骨干网络最后一层的输出特征图大小扩大1倍,以获得更多的细粒度特征信息;对于井下难以进行正确ID匹配的人员,采用DMM进行难样本采样和加权处理,利用人员图像间的绝对距离信息,使网络学习出关键特征;联合使用ID损失和距离度量损失来优化特征层,使网络可提取出更具判别力的人员特征,从而提高重识别准确度。
(3) 在适用于井下的Miner-CUMT数据集中对DCAN进行实验验证,结果证明该网络具有较强的人员重识别能力,可为煤矿智能视频监控系统提供可靠的技术支持,有利于实现安全生产与管理。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
数学小灵通·3-4年级(2021年5期)2021-07-16
科普童话·学霸日记(2020年1期)2020-05-08
数学年刊A辑(中文版)(2019年3期)2019-10-08
小天使·一年级语数英综合(2019年2期)2019-01-10
今日农业(2019年15期)2019-01-03
中国学术期刊文摘(2016年1期)2016-02-13
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
