
基于双伪随机序列的物联网安全蜜罐节点研究
2021-07-02 10:51陈大文
通信电源技术 2021年5期
陈大文,刑 伟
(江苏金盾检测技术有限公司,江苏 南京 210042)
0 引 言
物联网一词最早由Kevin Ashton在1999年提出,其没有官方定义,事实上不同作者之间的定义差异很大。CASAGRAS将物联网描述为一种全球网络基础设施,通过利用数据捕获和通信能力将实体和虚拟对象连接起来。这一基础设施包括现有的和不断发展的Internet网络,它将提供具体的客观识别、传感器以及连接能力,作为独立合作服务和应用开发的基础拥有高度自主的数据捕获、事件传输、网络连接以及互操作性等特点[1]。
短时间内,物联网相关技术得到飞跃式发展,物联网也跨越工业、商业、医疗、汽车以及其他应用迅速进入人们的日常生活。鉴于其对个人、机构及系统的影响范围甚广,安全性上升成为所有物联网系统中最关键的组成部分。物联网网络的脆弱性往往是在作评估时开发人员要特别关注的最基本元素,而边缘节点通常是小型低成本的智能设备,人们往往因为其访问资源有限,从而错误地认为边缘节点不易受到攻击,而边缘节点到目前为止还未具备成熟的安全技术。由于物联网边缘节点部署的特点,使其很容易被攻击者接触并破解,修改其中的固件或代码,造成物联网边缘节点被利用,成为攻击者发送DDOS攻击、假冒身份攻击以及中间人攻击等的有效途径。如果要真正重视物联网节点的安全性,那么物联网的节点安全也必须与网上银行账号登录类似,其安全性由多个层次来提供。现有的SSL/TLS等网络加密协议也仅能保护未遭受入侵的边缘节点与服务器之间的通信通道,无法防止非入网型攻击,另外物联网节点运算能力及能源往往被忽视,其较弱的运算能力加上被限制的能源很难执行复杂度高的非对称或对称加密算法。因此,需要有一种对能源需求和计算复杂都较低的边缘节点保护机制。
1 加密算法原理及优化
在物联网节点保护中,加密算法是最常用的方法。在基于数据加密的保护方法中,同态加密技术和安全多方计算使用最多。Rivest等人于1978年提出同态加密技术,它是一种允许对密文进行操作的加密变换技术[2]。Domingo等人在此基础上做了进一步改进,改进之后的算法拥有既保证用户可以对敏感数据进行操作,又不泄露数据的特点。另外,安全多方计算使用SMC临时密码组合保护并隐藏RFID的标志[3]。基于密码机制的安全协议也是物联网节点保护中常见的方法,主要包括基于Hash函数的方法、重加密方法以及匿名ID方法。其中基于hash函数的方法又分为随机化hash锁协议和Hash链协议[4]。在上述的保护方案中,大部分要使用到加密算法,但是由于物联网节点运算能力以及能源都受到一定限制,很难执行复杂度高的非对称或对称加密算法。因此,需要设计一种对能源需求和计算复杂度都较低的边缘节点保护机制。另外,物联网节点具有趋同性,即大部分节点上运行的代码和功能都相同,若一个节点被攻击者发现有利用的漏洞,那么大部分节点都存在有相同的漏洞,攻击者就能攻击大部分的物联网节点。由此本文提出一种基于双伪随机序列的物联网安全蜜罐节点,该节点具有与物联网中其他节点相同的功能,同时承担蜜罐功能。一旦其被攻击者攻击并利用,则物联网管理中心会立刻发现该节点被劫持,从而发挥物联网边缘节点的安全警戒作用。
2 基于双伪随机序列的物联网安全蜜罐节点的相关技术
2.1 伪随机生成函数
随机数是指一组不能被预测的数字或符号序列,这些数字和序列是完全偶然产生的,即随机数是客观世界不确定性的理论抽象[5,6]。随机数数列分为真随机数数列和伪随机数数列两种,真随机数数列和伪随机数列的区别在于真随机数数列是完全不可预测的,得到它的途径为放射性衰变、电子设备的热噪音以及宇宙射线的触发时间等物理过程,仅仅通过软件方式是无法获得的。伪随机数则是指一组特性接近随机数特性的数的序列,是可预测的,严格意义上讲,它并不具有随机性质,通常用数学公式的方法获得[7]。由上述比较及相关研究可知,确实的数的序列是伪随机数的本质,只是其序列周期的长度远长于所研究的问题集分布序列的长度[8]。
如果一个序列是伪随机的,那么它至少应具有如下性质。一是伪随机序列能通过已知的,所有正确的随机性检验,只是看起来随机,并非真正的随机。二是不可预测的,也就是说,即使给出产生序列的算法或者硬件设计和以前产生序列的所有知识,也不可能通过计算来预测下一个随机位是什么值[9-11]。
2.2 蜜罐原理与作用
在面对网络入侵和攻击时,蜜罐技术这种网络防御陷阱技术常常被使用来抵御攻击[12]。蜜罐系统最主要的功能是对系统中所有的操作和行为进行监视和记录,通过对系统进行伪装,使得攻击者在进入到蜜罐系统后并不会知晓其行为己经处于系统的监视中,然后根据所有攻击行为分析攻击方法和攻击企图,来保护真实服务资源。通过蜜罐,人们能够采集针对服务器的攻击和漏洞,这样攻击破坏行为就可以被延缓乃至阻止。蜜罐技术的出现,打破了传统防御的被动僵局,其具备如下特点。
(1)蜜罐第一个也是最大的一个优势就是其简易性。跟其他方法相比,蜜罐中既涉及不到任何特殊的计算,也不需要保存特征数据库。
(2)蜜罐的第二个优势就是资源占用率低。其所要做的事情十分简单,仅仅需要捕获进入的所有数据,然后对那些尝试连接的行为进行记录,并作出响应。
(3)蜜罐第三大优势就是其采集的数据具有很高的价值。安全防御中最棘手的问题就是如何简单快速的从成千上万的数据中筛选出符合自己需求的数据,蜜罐收集的数据多且价值高,很好地解决了安全防护的难题。
蜜罐处理流程如图1所示,涉及的技术主要包括诱骗技术、数据捕捉技术、数据控制技术以及数据分析技术。其中,诱骗技术是蜜罐技术体系中最为关键的核心技术,使入侵者相信存在有价值的、可利用的安全弱点,诱使攻击者对蜜罐进行扫描、攻击。数据捕捉技术是指对进出蜜罐的所有活动进行监视和记录。数据控制技术顾名思义是指控制所有网络活动的技术。而数据分析技术是指从大量的网络数据中提取出攻击行为的特征和模型,这其实是相当困难的,数据分析也是是蜜罐技术中的难点,对捕获的各种攻击数据进行融合与挖掘,分析黑客的工具、策略及动机,提取未知攻击的特征,为研究或管理人员提供实时信息。

图1 蜜罐处理流程
2.3 数据扰动
在本文提出的物联网安全节点中,应用了一种隐私保护研究领域中基于数据修改的技术,即数据扰动。所谓数据随机化是指对待分析的原始数据对象加入一些随机噪声进行数据扰动,随机扰动是数据随机化处理的一种方法,它采用数据随机化过程修复敏感数据,而从实现对隐私数据的保护。数据扰动简单而有效的特点使其在与现有其他隐私保护技术的比较中脱颖而出,用来保护敏感数据。通过扰动思想的数据修改技术是对原始数据进行某些方面的修改以实现数据挖掘中敏感数据的隐私保护。
3 带区域限制的双伪随机序列数据扰动
3.1 数据扰动算法
本文提出的物联网安全蜜罐节点是通过对物联网节点上传数据进行扰动来实现的。为了能充分利用蜜罐功能,同时兼顾低计算复杂度与能耗,本文基于上述伪随机序列,采用双伪随机序列对物联网节点上传的数据进行扰动。数据扰动具体步骤如图2所示。

图2 数据扰动算法流程
其扰动的步骤如下:第一步,预先设定物联网观测数据的大小范围及平均有效数据位数;第二步,物联网节点通过伪随机数生成器,生成N个及N+1个随机数;第三步,使用第一个随机数取整,将所得整数对平均有效数据位数进行求余;第四步,使用余数m对观察数据进行扰动,若为负数,则截取观察数据后m位,并在发送下一个观察数据之前将其添加到下一个观察数据尾部,若为正数,则将第二个随机数变换成纯小数,直接添加到当前观察数据之后;第五步,判断第四步扰动后生成的数据是否在观测数据范围之内,如果否,则返回第二步取N+2和N+3个随机数,再尝试扰动。
3.2 数据扰动的恢复算法
为了对数据扰动进行恢复,本文提出相对于数据扰动的恢复算法,算法流程如图3所示。在物联网管理中心针对各物联网蜜罐节点保持记录值,记录对应蜜罐节点当前随机序列已生成的随机数个数N。当收到了蜜罐节点发送来的数据时,执行与扰动算法相反动作来恢复蜜罐节点的发送数据。
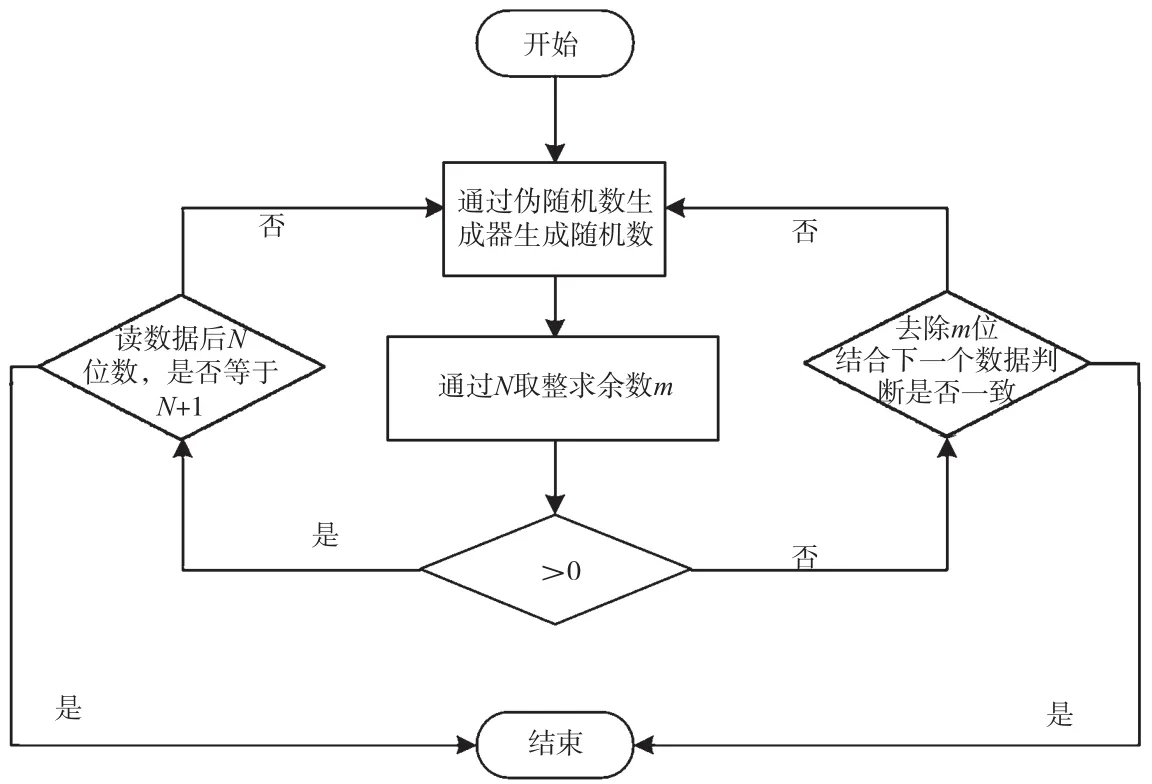
图3 数据扰动恢复算法流程
具体步骤如下:第一步,与上述相同生成N、N+1随机数;第二步,通过N取整,求余数m,若为正则判断该数据后N位数是否等于N+1,若为负则将接收的数据去除m位,并结合下一个接收数据判断是否一致;第三步,如果第二步中判断为否,则回到第一步生成N+2、N+3随机数,再次验证。
4 蜜罐边缘节点的部署与警戒作用
蜜罐节点由于需要生成伪随机序列,因此在部署之前需要先预置两个数据,并记录在物联管理中心,一个是蜜罐节点的ID号,另一个是伪数据数序列的生成种子。其中,节点的ID号用作管理中心区分不同物联网节点的依据,生成种子用作对蜜罐扰动数据的恢复。由于本文所提的蜜罐节点在功能上与普通的物联网节点一致,因此可以按一定的比例与正常的节点混合在一起部署。
一旦平台发现某个蜜罐节点发送的数据扰动恢复失败,则意味着有可能蜜罐节点被攻击了或者蜜罐节点出现了故障,此时物联网管理中心可以对蜜罐节点的扰动数据进一步分析,将当前随机数生成个数N恢复成0,再一次进行校验,看是否能通过校验,如果能通过,则说明蜜罐节点发生了重启,数据扰动的随机序列从0开始生成了,蜜罐内的程序应没有被破坏。
5 结 论
本文所提出来的物联网蜜罐节点采用了双随机序列对观测数据的扰动,执行的功能与普通的物联网节点完全一样,所以攻击者在众多的物联网边缘节点中很难发现。当攻击者对其采用与其他节点一样的同类攻击时,必然会改写该节点发送的观测数据,从而引发物联网管理中心的扰动数据恢复失败,从而实现了蜜罐的警戒作用。此外,本文的蜜罐功能只使用到随机数生成与数据扰动,计算复杂度很低,对于能源方面的需求很小,因此可以充分满足物联网边缘节点的应用需求。
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
现代电子技术(2022年11期)2022-06-14
汽车实用技术(2022年5期)2022-04-02
北京航空航天大学学报(2021年7期)2021-08-13
计算机与网络(2020年21期)2020-04-01
中学时代(2019年9期)2019-11-13
中外文摘(2019年20期)2019-11-13
知识窗(2019年6期)2019-06-26
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
