
基于空间分频的超声图像分割注意力网络
2021-07-02 08:55:14沈雪雯王晓东
计算机应用 2021年6期
沈雪雯,王晓东,姚 宇
(1.中国科学院成都计算机应用研究所,成都 610041;2.中国科学院大学,北京 100049)
(∗通信作者电子邮箱shenxuewen18@mails.ucas.ac.cn)
0 引言
心脏作为人体内最重要的器官之一,通过机械做功推动血液的流动维持身体各器官、组织的正常工作,而它的效率与心脏的形态、心脏四腔体的大小息息相关。因此,准确分割获取心脏不同时期的轮廓是评定心功能或者心脏疾病必要又重要的程序。在临床医学中,心脏的多种成像方式为心脏结构和功能的评估、诊断、疾病检测、治疗计划等提供了有力的支持,如磁共振成像(Magnetic Resonance Imaging,MRI)、计算机断层扫 描(Computed Tomography,CT)成 像、超 声(UltraSound,US)等。而其中,超声成像以其价廉、简便、迅速、无创、无辐射、可连续动态及重复扫描等优点,成为医学中使用率高,受众面广的影像检查技术。因此,从二维超声心动图中提取临床指标进行数据分析,对临床常规检测心脏形态、功能及诊断具有重要意义。例如,提取左室射血分数(Left Ventricular Ejection Fractions,LVEF)需要准确地描绘舒张末期(End-Diastolic,ED)和收缩末期(End-Systole,ES)的左室内膜。在临床上,由于全自动心脏切分方法缺乏准确性和可重复性,半自动或手动的心脏切分仍然是庞大而繁重的日常工作。近年来,深度学习在图像分割领域的迅速崛起,让计算机科学与医疗知识的结合成为可能,医工交叉领域的研究也成为热点。
深度学习结合图像数据来辅助疾病诊断能够更加准确利用技术来解决人体的生理疾病,但由于超声成像噪声大、腔体边界不清晰的特点,同时医学超声样本很少,表现优异的自然图像分割网络应用在医学图像分割任务上往往达不到同等优秀的效 果。Long 等[1]在全卷 积网络(Fully Convolutional Network,FCN)中最早提出编码-解码(Encoder-Decoder)结构,为实现更为精确的分割引入了上下文信息,这成为图像分割的开山之作;2015 年MICCAI(Medical Image Computing and Computer-Assisted Intervention)会议上U-Net[2]修改并扩大了FCN 的网络框架,它的跳跃连接(Skip-connection)和深浅层特征融合的思想,让少量的训练样本就能得到精确的分割结果,也成为现在大多做医学影像分割任务的基线网络;Oktay 等[3]提出的Attention U-Net加入了Attention Gate结构,为医学图像分割打开了新思路;同时还有很多研究通过将U-Net 与ResNet[4]、DenseNet[5]相结合等方法都得到了不错的效果。
当前的医学图像分割多为二类分割,超声心脏分割也大多只分割了左心室或者右心室。全心脏超声序列图像含有丰富的心脏运动信息,但从超声序列图像中提取心脏四腔的同步特性的研究还较少,当临床医生诊断心脏病,例如扩张型心肌病、右心室不正常等病症时,医生需要患者左、右心室和左、右心房的分割结果来进一步计算各种临床指标,以便作出疾病诊断。本文提出了一种基于空间分频的超声图像分割注意力网络(Spatial Frequency Divided Attention Network for ultrasound image segmentation,SFDA-Net),该方法基于++引入图像空间分频与注意力机制多类分割。根据实验室现有的数据资源,从病例库中选取二尖瓣成像数据,获得心脏四腔心标准切面,使用SFDA-Net 分割心脏超声图像中的左、右心房和左、右心室,得到心脏各腔体的轮廓。
1 相关知识
1.1 ++
医学图像有着边界模糊、梯度复杂的特点,需要高分辨率信息用于边界轮廓精准分割;同时人体内部结构相对固定,分割目标在人体图像中的分布具有规律,且语义简单明确,需要充分利用低分辨率信息来进行目标物体的识别。医学图像分割的特殊需求在U-Net的编码-解码(Encoder-Decoder)结构得到了满足。但在实际分割任务中,大物体边缘信息和小物体本身很容易被网络在降采样和升采样中丢失,不同于FCN 和Deeplab[6]等,U-Net没有直接在高级语义特征上进行监督和损失误差(Loss)的反向传播,而是利用跳跃连接进行深浅层特征融合,获得更多的信息,帮助还原降采样所带来的信息损失。
但U-Net对于特征的利用程度仍然是有限的,Zhou等[7]受到ResUNet、DenseUNet 的启发提出UNet++,让不同深度的U-Net 学习不同深度的特征,共享一个特征提取器。UNet++没有直接使用U-Net 的跳跃连接,而是改为使用短连接与长连接的结合,长连接就是跳跃连接,短连接则是把每个分支U-Net在同一层相同尺寸的特征都连接起来,让模型的中间部分参数能够有效参与训练,这个改动把1~4 层的分支U-Net全部连了起来。
UNet++编码(Encoder)操作中使用了4 次下采样,用来降低运算量,增加对输入图像小扰动的鲁棒性,同时扩大了深层结构的感受野;对称地,在解码(Decoder)操作也进行4次上采样,将Encoder 得到的高级语义特征图恢复到原图片的分辨率,分类输出。同时UNet++还使用了深监督(Deep Supervision),具体实现是在4个分支U-Net的输出后分别进行1×1的卷积,计算4个Loss,主要是为了让模型选择做一个平均再得到最终输出,或者从其中的所有分支输出选择一个作为输出。本文没有使用UNet++的深监督方式,而是在最后一个输出层对每个分支U-Net的输出X01、X02、X03、X04以及对输入的初始化层输出X00 进行拼接,最后用一个1×1 的卷积分类输出,利用中间部分收到传递过来的梯度共同计算Loss。本文SFDA-Net结构如图1所示。
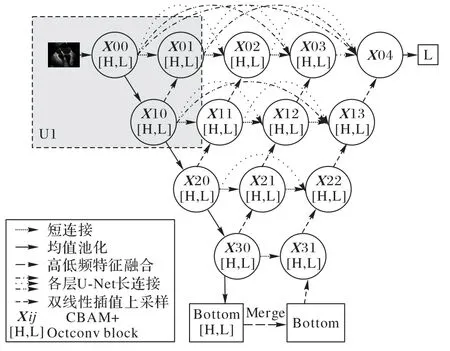
图1 SFDA-Net结构示意图Fig.1 Structure schematic diagram of SFDA-Net
1.2 Octave卷积
在自然图像中,信息以不同的频率在传递,同样,对于卷积层输出的特征图也可以看作是不同频率下信息的混合。Chen 等[8]提出了一种新的Octave 卷积(Octconv),用来存储和处理空间分辨率较低且空间变化较慢的特征图。Octave 卷积的正交性和互补性对于建立更好的拓扑结构和减少深度卷积网络中低频信息带来的空间冗余有良好的效果,在提高精度的同时,节约计算资源的消耗。Octconv 使用一个α系数将特征图分解为高分辨率(高频)分量(XH)和低分辨率(低频)分量(XL)两个部分,低频部分保存图像的抽象信息,信息数据量少;高频部分保存图像的边缘、轮廓等细节信息,信息数据量大。同时还提出了多频特征表示方法将平滑变化的低频映射存储在低分辨率张量中,可以减少空间冗余。
如图2所示,αin为输入的低频通道占总通道的比例,总输入张量的尺寸为cin×w×h,总输出张量的尺寸为cout×w×h,Wp→q为相应卷积核。取卷积尺寸为cin×cout×k×k(stride=1,padding=same),普通卷积对于输出特征图(feature map)中的每个数据,需要进行cin×k×k次乘加计算,可以得出总计算量为Cconv=(cin×k×k)×(cout×w×h)。对比普通卷积,Octave 卷积有一定的比例是低频通道,操作会有一定的复杂性,但在性能和计算量上总体都优于普通卷积。Octconv 直接作用于XH、XL,两组频率之间会通过上采样和下采样进行信息交互,输出高、低频分量(YH、YL),这能够为网络带来更加多元的信息,内部共有四个操作。
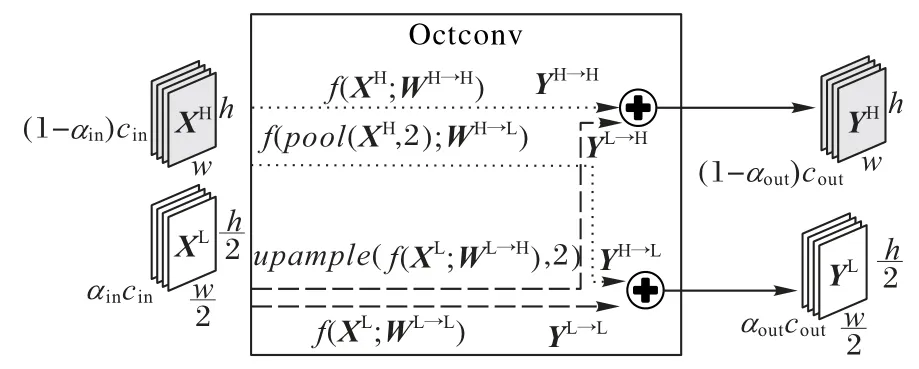
图2 Octave卷积Fig.2 Octave convolution
1.2.1 高频到高频
使用指定卷积核WH→H对高频分量XH直接卷积,得到:

计算量为:
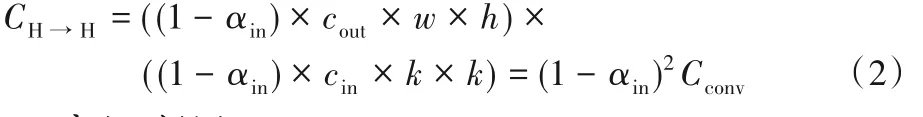
1.2.2 高频到低频
首先进行步长和尺度为2 的平均池化,之后卷积生成与YL通道数相同的特征,得到:
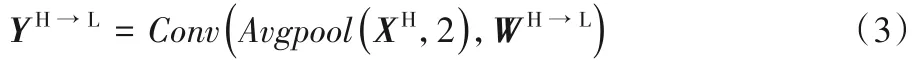
计算量为:
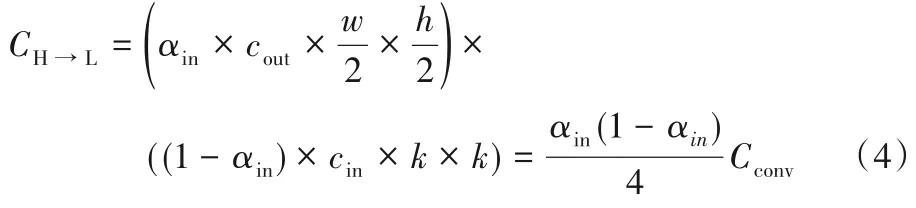
1.2.3 低频到高频
通过上采样生成与XL长宽相同的张量,得到:

计算量为:
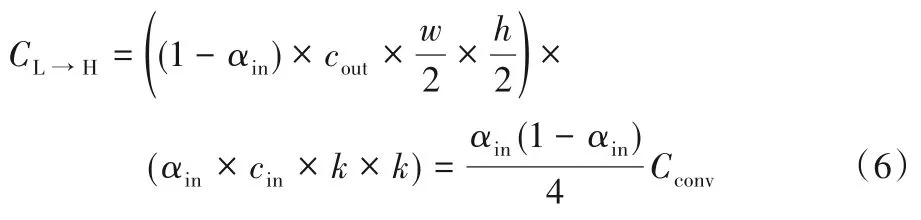
1.2.4 低频到低频
操作同YH→H,使用指定卷积核WL→L对低频分量XL直接卷积,得到:

计算量为:
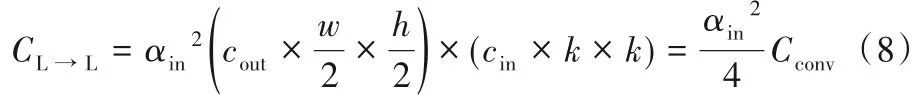
最后通过式(1)、(3)得到高频输出YH=YH→H+YL→H,通过式(2)、(4)得到低频输出YL=YH→L+YL→L,Octave 卷积四个操作的计算量相加得到总计算量Coctconv,有:
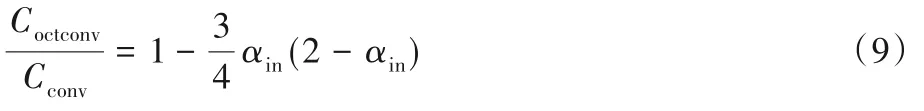
在αin∈[0,1]中单调递减,当取αin=1时,有Octave 卷积的计算量仅为普通卷积的1/4;当取αin=0 时,输入没有低频通道,此时Octave卷积与普通卷积相同。
1.3 CBAM注意力模块
在引入注意力机制之前,长距离信息会被弱化,一些重要的信息在经过层层处理之后会丢失,所以将有限的注意力集中在重要的信息上,快速获得有效信息成为了模型优化的突破点。Vaswani 等[9]提出了不使用循环神经网络(Recurrent Neural Network,RNN)或卷积神经网络(Convolutional Neural Network,CNN)等复杂的模型,仅仅依赖注意力模型可以使训练并行化且拥有全局信息。注意力建模在自然语言处理领域的成功,激发了它在计算机视觉领域的应用。在计算机视觉中注意力机制(Visual Attention)的实现有两种方式:一种是Mask RCNN[10]采用的添加先验来引入注意力,假如目标是分割小狗,首先检测出小狗的边框(bounding box,bbox)后再对bbox内的小狗进行分割,可看作目标检测和语义分割的结合,常用于实例分割,属于硬注意力(Hard Attention)。另一种是让网络利用全局信息有效地增强有益特征通道同时抑制无用特征通道,从而实现特征通道自适应校准,这就是Hu 等[11]提出的SENet(Squeeze-and-Excitation Network),属于软注意力(Soft Attention)。Woo 等[12]基于SENet 进行了进一步拓展,提出了一种结合通道和空间的卷积块注意模块(Convolutional Block Attention Module,CBAM),把通道注意力模块(Channel Attention Module)和空间注意力模块(Spatial Attention Module)串联起来,先找到“哪个特征是重要的”,再关注“哪里的特征是有意义的”,找出图片信息中需要被关注的区域,通过对应的空间变换把关键信息提取出来[13]。CBAM 结构如图3所示。
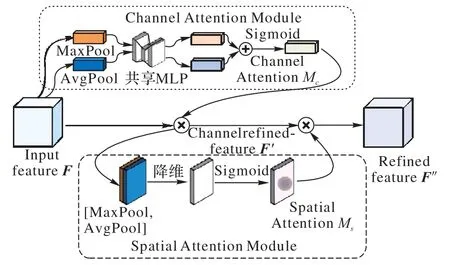
图3 CBAM结构Fig.3 Structure of CBAM
1)通道注意力模块。首先将H×W×C的输入特征F分别经过全局最大池化(MaxPool)和全局平均池化(AvgPool)得到两个1×1×C的通道描述,把它们分别送进一个参数共享的两层的神经网络MLP(Multi-Layer Perceptron)。第一层神经元个数为C/r,激活函数为线性整流函数(Rectified Linear Unit,ReLU),第二层神经元个数为C,将得到的两个特征相加后经过一个Sigmoid激活函数得到权重系数:
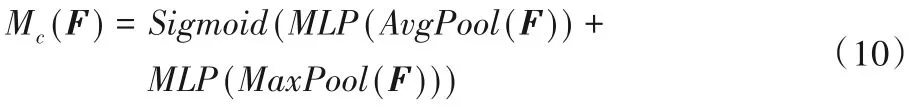
最后把Mc(F)与F相乘即可得到缩放后的新特征F'。
2)空间注意力模块。关注“哪里的特征是有意义的”,对通道注意力的输出F'先分别进行一个通道维度的平均池化和最大池化得到两个H×W×1 的通道描述,并将这两个描述按照通道拼接在一起。然后经过一个7×7的卷积层,激活函数为Sigmoid,得到权重系数:
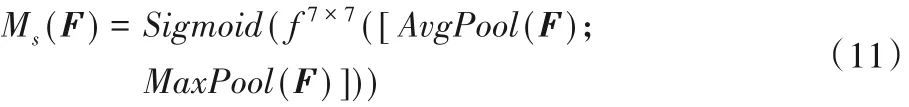
最后Ms(F)和F'相乘即可得到缩放后的新特征F"。
这两个模块形成了互补,并且在模块内使用全局最大池化和全局平局池化并行的方法,降低池化操作带来的损失的同时获得了更加多元的信息,使得CBAM 相较于SENet 只关注通道的注意力机制可以取得更好的效果,并且在小模型上添加CBAM 只需要增加少量的计算量,就能带来稳定的性能提升。
1.4 双线性插值上采样
在Encoder 时,需要对图像进行下采样,降低计算量的同时进行特征提取,但在这个过程中图片的分辨率也在降低。于是在Decoder 的部分,本文使用双线性插值上采样(Bilinear Upsampling)恢复各层最后输出的特征图的大小,到最终输出层得到与原图像大小尺寸一样的输出。双线性插值上采样利用原图像中目标点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,其核心思想是在两个方向分别进行一次线性插值。
如图4所示,已知Q12、Q22、Q11、Q21,但是要插值的点为P点,首先在X轴方向上对R1和R2两个点进行插值,得到:
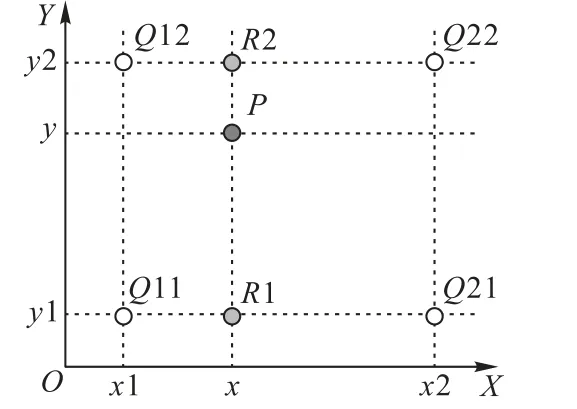
图4 双线性插值上采样Fig.4 Bilinear interpolation upsampling
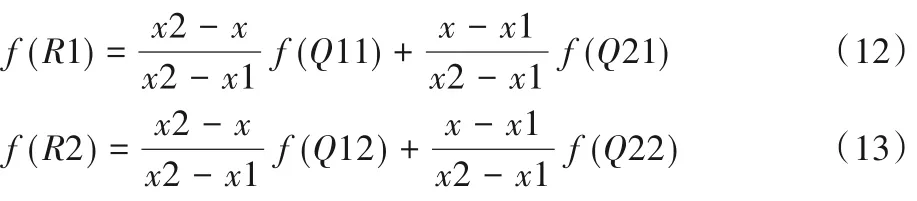
然后在Y轴方向上根据R1和R2对P点进行插值,得到:
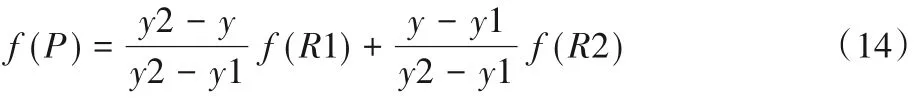
普通的上采样将一个点复制作为周围四个点的像素值,双线性插值上采样需要周围四个点共同线性计算,不易产生像素突变,要更加稳健,同时双线性插值上采样方法不需要进行学习,运行速度快,操作简单。
2 空间分频注意力网络
2.1 模型框架
UNet++的主要优势在于连接了每个分支U-Net 共享一个编码层,让模型中间部分都参与了训练,使Encoder 过程中出现的未知信息损失得到一定程度的修复,从而在增加的参数量不多的基础上,获得了明显的性能提升。但每个分支U-Net共享一条Encoder路径,这使得它们在下采样过程中丢失掉的是同样的信息,UNet++虽然在Decoder 过程中虽然获得了不同深度的U-Net 特征,但这种特征差异性是在每个分支U-Net进行各自的上采样之后得到的,所以UNet++在特征恢复的过程中的信息补充是有限的,同时缺乏针对性。
本文提出了一种基于空间分频的超声图像注意力网络(SFDA-Net),使用UNet++作为基础框架,共设计5 层,如图1所示,其中图1 中的U1 内部实现结构如图5 所示,SFDA-Net分频框架示意图如图6 所示。用Octconv 取代传统二维卷积(2-D Convolution,Conv2D),将整个框架分为高、低频同步并行的两个具有完整UNet++结构的支路,在编码-解码的每一层都使用Octconv让高频支路和低频支路进行一次信息交互。这个改进一方面可以降低模型的参数量,另一方面是为了减少每个编码层在下采样中引入的信息丢失,同时让整个网络获得更加丰富的信息。在解码部分双线性插值上采样进行图像恢复,在每个上采样之后,都与同层(stage)、同尺度的特征进行拼接,拼接后紧跟CBAM,用于提高模型注意力,加强模型在接下来卷积操作中对目标区域的关注,实现更为精准的像素类别分类。同时SFDA-Net 在Encorder 中使用双线性插值上采样,尽可能避免恢复特征出现偏移等问题,使网络更加稳健。
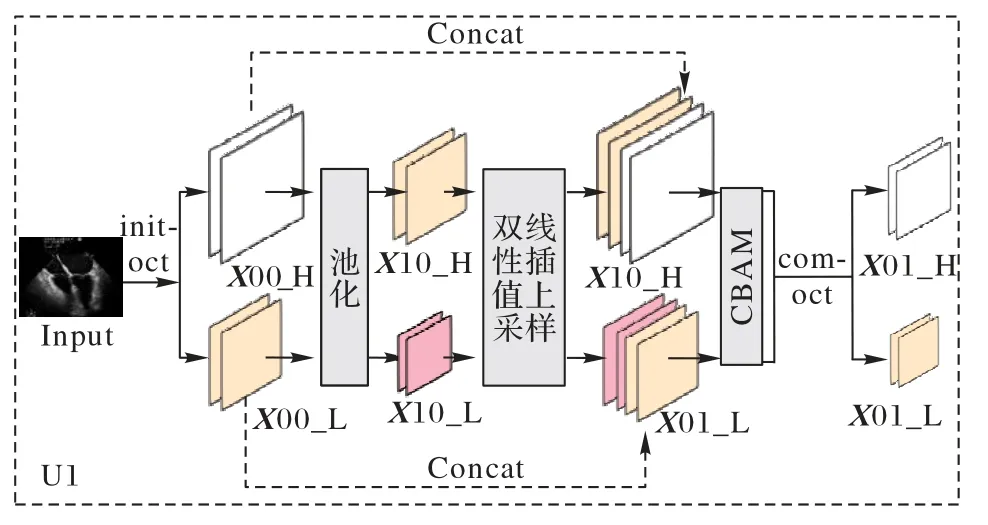
图5 U1内部实现结构Fig.5 Internal implementation structure of U1
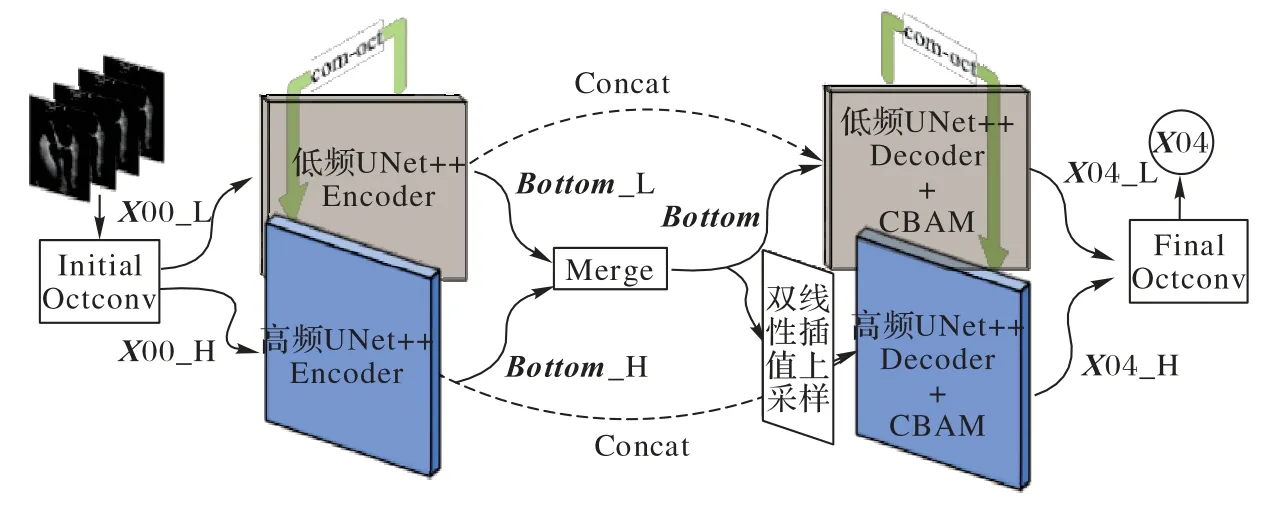
图6 SFDA-Net分频框架示意图Fig.6 Schematic diagram of SFDA-Net framework with frequency division
实验中使用到了三种Octconv:1)initial octconv(init-oct)。在网络的输入层使用(此时输入作为高频),首先对输入进行下采样得到低频特征,然后进行Octconv,得到高频输出、低频输出。2)common octconv(com-oct)。除了输入层和输入层,模型其他部分均采用com-oct,输入为高频、低频特征,直接进行Octconv,可以通过超参α控制输出高、低频的通道占比;3)final octconv(fin-oct)。在最后的输出层使用,输入为高频、低频特征,在卷积之后,将低频上采样与高频相加,输出高频。
在图1 的框架中,X00_[H,L]是输入张量(Input Tensor)通过init-oct 得到,U4 的解码最顶层X04_[H,L]经过fin-oct 后得到一个与原输入尺寸相同的X04,将X04 再进行1×1 的卷积分类输出。由于Octconv的高低频输出特性,网络所有层都有高频支线、低频支线平行处理,在每层的com-oct 处进行高低频信息交互,Encoder 和Decoder 通过拼接操作(Concat)进行特征融合。在模型底部时没有使用fin-oct 得到Bottom,是为了获得更高一级的抽象特征,所以通过融合操作(Merge)将低频上采样与高频相加。
2.2 Focal Tversky Loss
Tversky 系数是Dice 系数和Jaccard 系数(IoU 系数)的广义系数,它的计算式为:
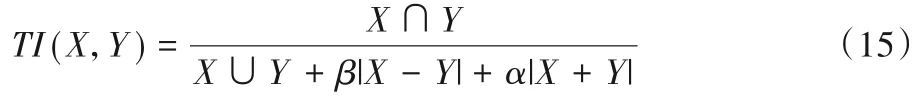
其中:X表示真值;Y表示预测值。α和β均为0.5 时,式(15)就是Dice 系数;α和β均为1 时,式(15)就是Jaccard 系数。实际上Dice Loss 是Tversky Loss 的一种特殊形式。医学图像分割中,特别是小病灶类分割,常使用Dice Loss 作为目标函数,它在样本极度不均衡的情况有良好的表现,但一般情况下使用会对反向传播有不利的影响,使训练不稳定。在项目中,心脏四腔体四类所占的目标区域与背景类相差不多,使用Dice Loss作为目标函数(Loss Function)效果并不理想,在训练中波动幅度比较大。
本文使用了Focal Tversky Loss[14-15]作为目标函数,它降低简单样本(预测概率大的样本)的权重,给难分类的样本较大的权重,从而加强对困难样本(Hard Examples)的关注。直观来说就是,对于正样本,使简单样本得到的Loss 变小,而困难样本的Loss变大。Focal Tversky Loss 引入γ系数,学习带有小目标感兴趣区域(Region Of Interest,ROI)的困难样本:

其中:TI是Tversky系数;γ∈[1,3]。
3 实验与结果分析
3.1 数据来源
实验数据来源于合作医院,采用飞利浦IE33 超声监测设备采集的术中超声心动图序列,并转换为.avi 视频。通过视频抽帧、数据筛选,过滤掉成像过度扭曲、目标区域清晰度太低的图像,最后保留了699 张图像,大部分都为心脏二尖瓣切面,包含有四个腔体。为了避免数据量太少导致网络过拟合,进行了数据增强,最终制作投入使用的训练集图片2 400 张,验证集图片800张,测试集图片295张。数据标注与预测中红色(深灰色)为左心房(Left Atrium,LA),黄色(浅灰色)为右心房(Right Atrium,RA),绿色(中灰色)为左心室(Left Ventricle,LV),蓝色(偏黑色)为右心室(Right Ventricle,RV)。
3.2 结果分析
3.2.1 CBAM性能分析
图像在层层下采样之后,不可避免地会丢失细节信息,Encoder-Decoder 和短连接的结构能够降低损失,但是通过上采样进行图像恢复后,在多噪声的影响下网络仍然会难以关注所需要关注的细节信息,不能准确定位目标类别的轮廓界限,所以SFDA-Net在每个stage特征拼接之后使用CBAM注意力模块,目的是让模型在接下来的特征恢复和提取中,更加关注目标区域,而不被背景类吞噬,从而实现更为精准的分割。图7展示了SFDA-Net及其在去掉CBAM的情况下的分割可视化对比,CBAM 对目标区域的类间像素分离是有效的,CBAM使网络的精度从92.28%提升至94.48%,Dice得分从90.53%提升到93.48%,效果明显。
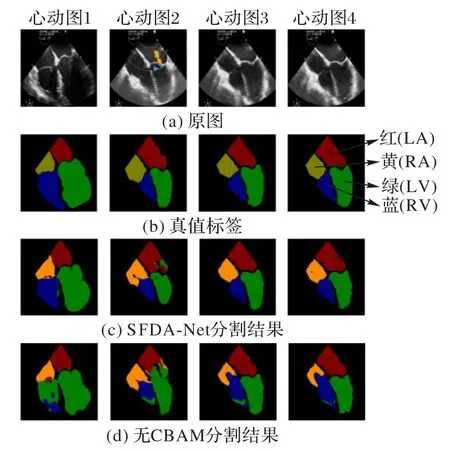
图7 SFDA-Net使用CBAM所带来的性能提升Fig.7 Performance improvement of SFDA-Net using CBAM
3.2.2 Focal Tversky Loss性能比较
实验对比了交叉熵损失函数、Dice Loss、Focal Tversky Loss作为目标函数时模型的表现情况,如表1和图8所示。
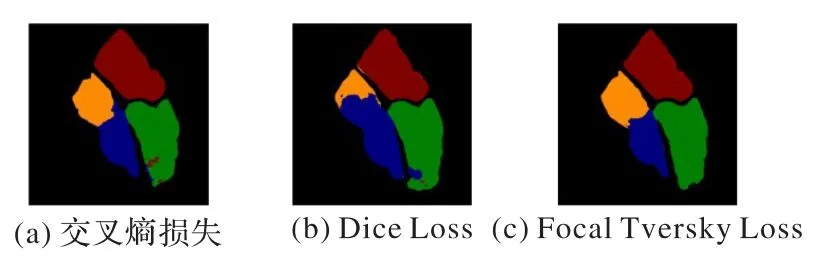
图8 三种损失函数输出的可视化结果对比Fig.8 Comparison of visualization results output by three loss functions

表1 不同损失函数时SFDA-Net的性能Tab.1 Performance of SFDA-Net with different loss functions
由表1 可以看出,交叉熵损失是多类分割常用的损失函数,它的训练数据精度能够达到0.968 2,Loss 能够低至0.100 7,但是验证Loss却比训练Loss高出接近0.2,模型的泛化性能不优秀,并且Dice 得分不高。Dice Loss 是医学图像中常用的、性能优秀的损失函数,它能够有效地降低训练Loss、提高训练精度。但在本实验中,模型使用Dice Loss 时训练过程不稳定,同时得到的验证数据和训练数据差距较大,有可能存在过拟合风险,对于难分类区域(RA、RV 之间)不能准确界定边界,分类误判较大,不稳健。所以本实验中将Dice Loss作为度量学习(Metric Learning)衡量方式。而Focal Tversky Loss不仅仅只是训练数据综合最优,验证数据也是最优的,它通过加大难分割区域的权重,让难分界的RA、RV之间有了明显界限。交叉熵损失和Dice Loss 在LV 左下角处存在像素类别误判,Dice Loss的LA 轮廓和噪声多的地方分类为RA,这些细节被Focal Tversky Loss 优化掉,极大降低了像素分类错误的可能。
3.2.3 不同方法的分类输出结果对比
本次实验在Ubuntu16.04 平台下进行,训练环境是基于Tensorflow 1.14.0 版本下的Keras 2.2.4 框架,训练使用NVIDIA Tesla P40 和GTX 1070 Ti。训练分20 个epoch,每个epoch 迭代100 次,模型在epoch=10 时训练精度上升到0.909 9;epoch=14 时逐渐趋于收敛,训练精度达到0.95 左右;epoch=17 时,训练精度稳定在0.96。图9 是在模型深度相同的情况下不同算法对于相同数据的预测输出可视化结果对比。
模型输入图像与标签(label)尺寸为460×600,本文使用labelme 3.16.7 标注得到JSON 格式封装的标签,随后对JSON文件解码得到.png格式的彩色可视化label,如图9(b)。但此时的label 是索引图,没有实际像素值,所以在把label 投入模型之前,需要将其转为灰度图。
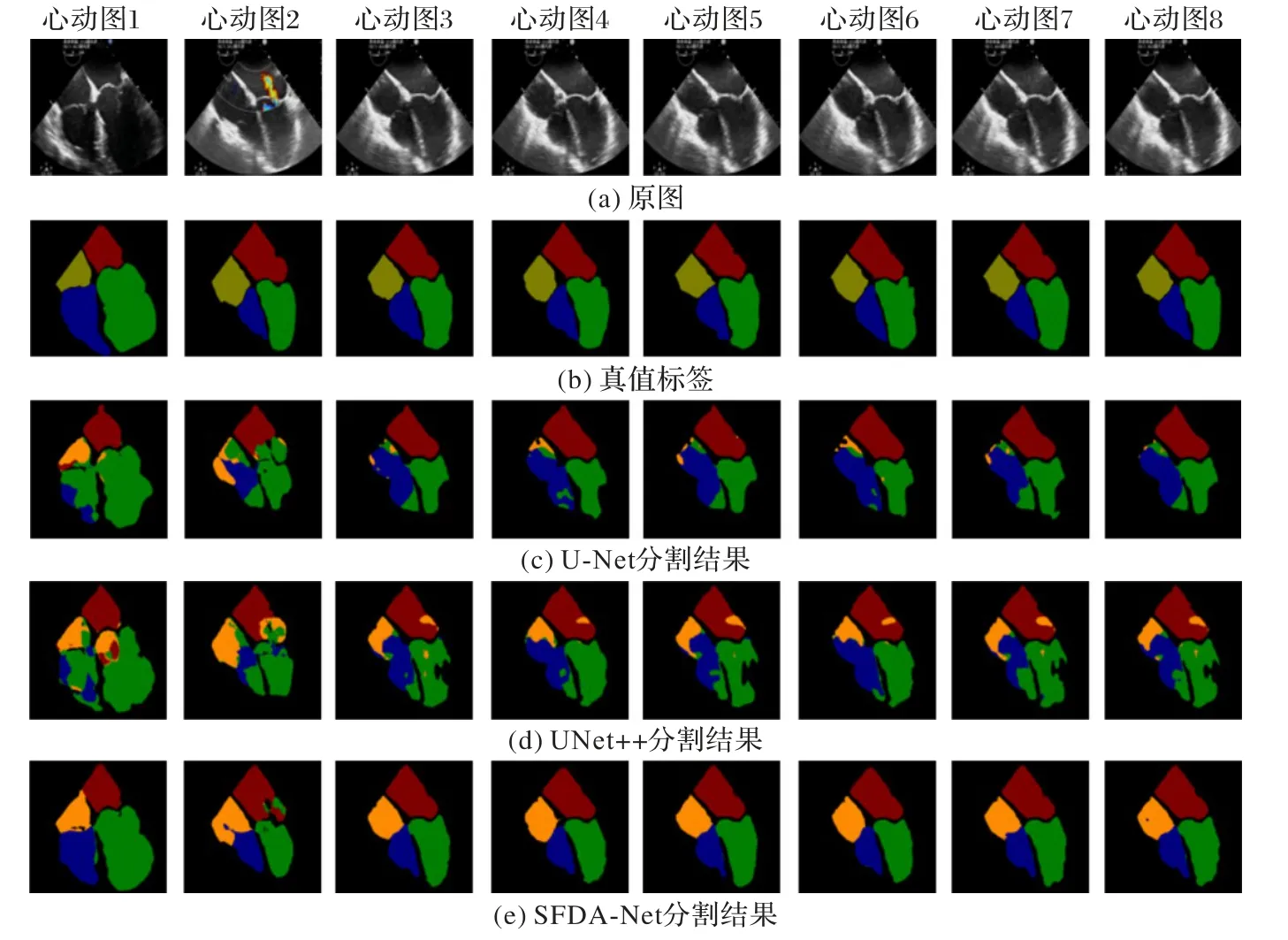
图9 不同算法的分割结果对比Fig.9 Segmentation result comparison of different algorithms
在本数据集上,U-Net 能够大致识别出心脏目标分割区域,但是无法准确区分各个类别,在大部分预测效果中没有分割出RA,被分类为RV,且LV 左下角缺失严重,四个腔体的中间“十”字边界不清晰。UNet++的短连接和多个分支U-Net联合的改进是有效的,在一定程度上弥补了U-Net 在LV 边界上的丢失,整体表现优于U-Net。
不同算法的参数量和精度如表2 所示。相较于U-Net 和UNet++两个算法,SFDA-Net 借助Octave 卷积实现了空间分频,以获得更加多元、丰富的信息,其高低频系数α设为0.5;在加入的CBAM 中,通道注意力部分需要调节参数共享的第一层MLP 神经元个数,通过实验得出设置r=8 时,模型有最优秀的性能表现。SFDA-Net 能够准确识别四个腔体的位置,类间分类误差极大降低,边界轮廓虽然存在缺失,但心脏四个腔体的大小形状预测是连贯完整的。U-Net的精度为86.8%,UNet++增加了2×106的参数量但是模型精度提升不到2 个百分点,基于UNet++改进的SFDA-Net 精度达到了94.5%,相较于UNet++提升了6.2个百分点。
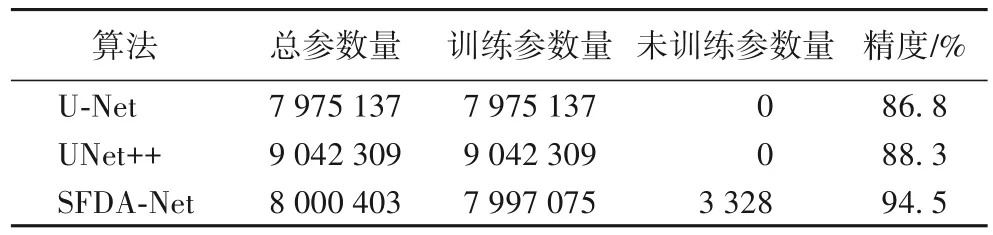
表2 不同算法的参数量和精度Tab.2 Parameter numbers and accuracies of different algorithms
3.2.4 评价指标
本文主要使用Dice 得分(dice score)、类别平均像素精度(mean Pixel Accuracy,mPA)和平均交并比(mean Intersection over Union,mIoU)三项指标评价算法性能。
Dice 得分是用来度量集合相似度的函数,通常用于计算两样本之间的像素[16],计算式如下:

其中:X是真值;Y是预测值;dice_score的取值范围是[0,1]。
mPA计算每一类分类正确的像素点数与该类的所有像素点数的比值,然后求均值,获得评价:

mIoU 是均值交并比,用来计算真值和预测值的交集和并集之比,将每一类的IoU 计算之后累加,再进行平均,得到全局评价:
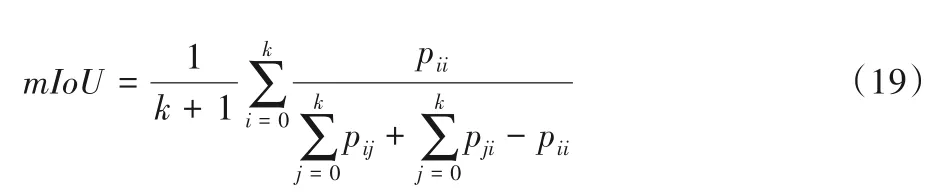
其中:i表示真值;j表示预测值表示真实情况下第i类表示预测为第i类的像素总数。的像素总数
由表3 可以看出,SFDA-Net 在三种评估指标上表现都优于其他两个网络。其中,U-Net的预测有心脏的大致轮廓与位置,但在各目标类别的像素误判较大,RA和RV几乎没有分开而被归为一类,LV 右下方出现了大量丢失而被判为背景类,所以它的mIoU 较低。UNet++虽然适当提升了U-Net 的性能,但是预测各类间的边界仍然不清晰,预测像素不连续,存在缺失。SFDA-Net 的预测也存在一定误差,各类像素间存在少量误判,但四个腔室独立而完整,相较于UNet++,它的mIoU 提高了10个百分点左右。
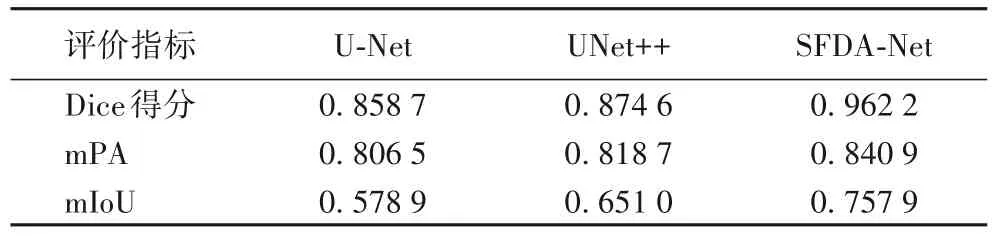
表3 不同算法的评价结果对比Tab.3 Comparison of evaluation results of different algorithms
3.2.5 SFDA-Net在CAMUS数据集上的表现
将SFDA-Net 应用于公开的CAMUS 数据集,实验结果如表4 所示和图10 所示。该数据集由500 名患者的临床检查组成,原始输入图像为.raw 和.mhd 文件格式,它的标注为左心室、左心房、心肌内膜。本文对原始数据进行相应处理后用于SFDA-Net得到了不错的效果,模型在epoch=18时接近收敛,训练精度稳定在0.94 左右。由表4 可以看出,SFDA-Net 并不只限于本实验数据集是有效的,对于其他的超声图像多类分割同样适用。
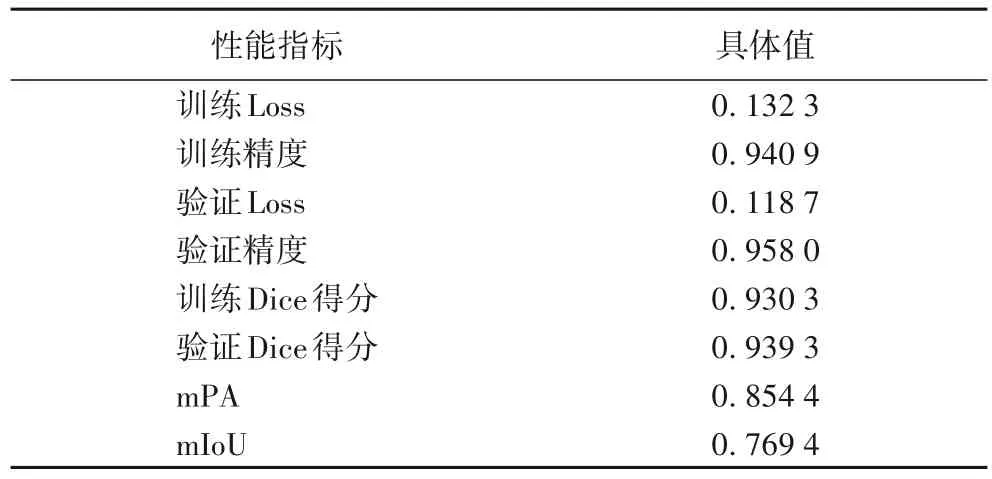
表4 SFDA-Net在CAMUS数据集上的性能Tab.4 Performance of SFDA-Net on CAMUS dataset
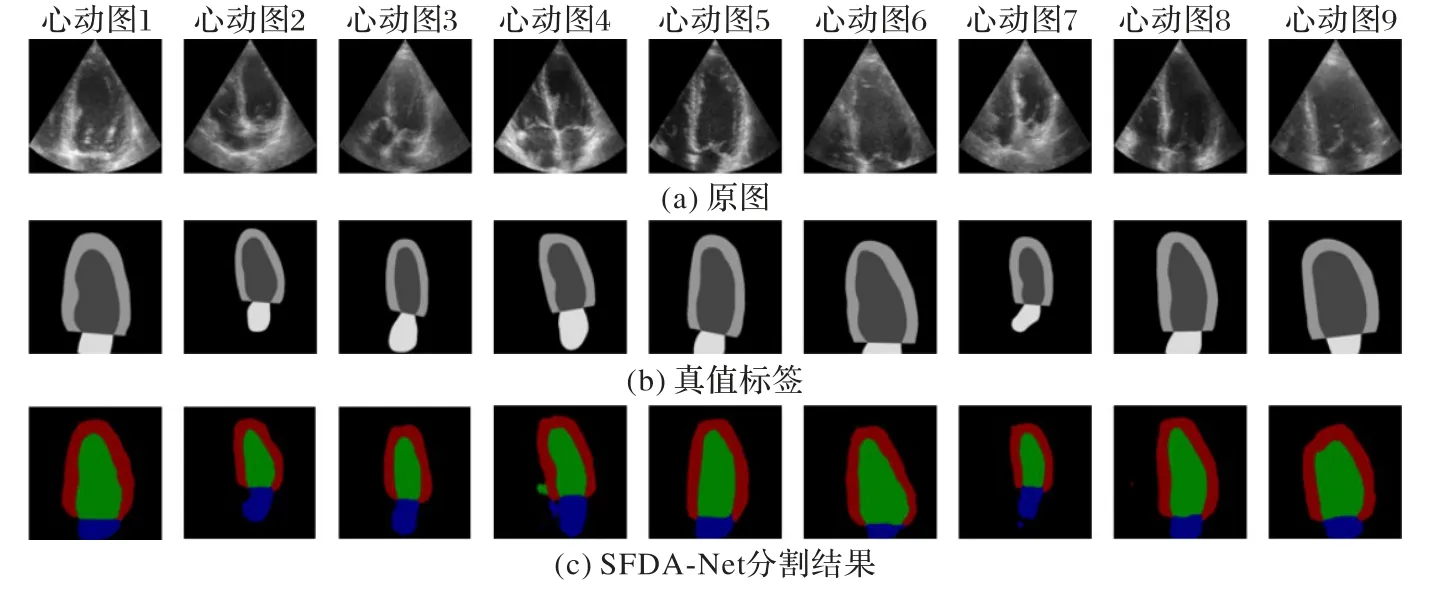
图10 SFDA-Net在CAMUS数据集上的分割结果Fig.10 Segmentation results of SFDA-Net on CAMUS dataset
4 结语
本文针对超声图像的特殊性提出了一种引入注意力机制的空间分频图像分割网络SFDA-Net,对心脏超声图像四腔体进行分割,并使用Octave卷积代替普通卷积,在降低参数量和计算量的同时,稳步提高了网络性能。同时SFDA-Net 使用CBAM 和Focal Tversky Loss 结合让模型更加关注难以分割的模糊目标区域,避免一些位置和边缘信息的损失,进行更为精准的图像恢复,相较于UNet++准确率提高了6.2个百分点。
实验所使用的数据是病人患病时的心脏彩超,所以超声心脏图就会有一些彩色高亮非心脏区域出现在图像上,且超声图源本身存在亮度低、像素多为黑色、边界不连续[17]的情况,这都会给分割带来困难。超声心脏数据太少,基于这个原因在数据清洗方面无法做到那么严格,使用的数据没有那么优质。同时数据标注是在医院专家的指导下完成的,标注的边界和轮廓没有专家的专业标注那么精准,所以在预测左、右心房边界时会出现一些边界像素点分类错误。尽管在数据上会给分割任务引入一些扰动,但是SFDA-Net仍然取得了不错的成绩,有益于对超声医学图像分割的实现和发展[18-19],后续将针对SFDA-Net存在的上述问题作进一步的研究。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
CHIP新电脑(2016年3期)2016-03-10 14:22:03
