
指针生成网络和覆盖损失优化的Transformer在生成式文本摘要领域的应用
2021-07-02 08:54王卫兵尚学达
计算机应用 2021年6期
李 想,王卫兵,尚学达
(哈尔滨理工大学计算机科学与技术学院,哈尔滨 150080)
(∗通信作者电子邮箱wangweibing163@163.com)
0 引言
面临着信息过载问题的日益严重,对于各类文本信息进行“降维”处理显得格外重要,其中文本摘要是一个有效的解决方式。文本摘要旨在将文本或文本集合转换为包含关键信息的简短摘要。按照输出类型可分为抽取式摘要和生成式摘要。抽取式摘要从源文档中抽取关键句和关键词组成摘要,摘要全部来源于原文。生成式摘要根据原文,允许生成原文本中没有的词语或是进行同义替换来生成摘要。
目前工业领域所使用的抽取式摘要已经愈发成熟并得到了广泛的应用,与之相比生成式摘要难度更大且更具有挑战性。文献[1]提出的Seq2Seq(Sequence-to-Sequence)模型在生成式任务中取得了重大突破,随后基于长短时记忆(Long Short Term Memory,LSTM)神经网络的Seq2Seq模型在生成式摘要的任务中也得以广泛应用。随着文献[2]模型的提出,Transformer 在机器翻译等任务中的表现超越了基于LSTM 实现的Seq2Seq 模型,随后文献[3]也证明了Transformer 在抽取式的摘要中同样拥有良好的表现,所以本文旨在验证采用Transformer 来实现生成式文本摘要任务是否可以取得更好的结果。
然而无论是Transformer还是Seq2Seq,在生成式任务中都面临着两个相同的问题:第一点是生成的文本中含有大量的重复词,第二点是生成的词表无法覆盖(Out Of Vocabulary,OOV)全部的生成词汇,从而导致了生成的文本准确率降低。
本文基于文献[4-5]在机器翻译任务出现重复的问题所使用的Coverage Vector 同样适用于摘要任务中,实验结果表明引入Coverage 机制减少了重复率。文献[6]提出的CopyNet可以解决在机器翻译中所遇到的词表无法覆盖(OOV)的问题,同样本文采用类似的方法指针生成网络(Pointer Generator Network)来解决摘要中OOV 的问题。本文的模型基于Pointer Generator Network 同时具备生成新的词以及在原文中拷贝词的能力,如果待生成词汇生成词表中无法找到,便通过指针在原文中复制一词。
1 摘要模型算法设计
1.1 Transformer
Transformer 模型摒弃了以往深度学习任务中所使用到的卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN),其核心部分是注意力机制。注意力机制缓解了RNN 以往解决自然语言处理(Natural Language Processing,NLP)任务的两点不足:首先RNN 是一个自回归模型,时间片t的计算依赖于t-1 时刻的计算结果,这样忽略的t时刻之后的信息是无法捕捉到的,同时也限制了模型并行计算的能力。第二点是顺序计算的过程会信息丢失,尤其对于长文本任务捕捉全文信息的能力不足。虽然针对RNN 的缺陷提出了LSTM 及双向LSTM 用来缓解长期依赖问题以及捕捉t时刻前后的位置信息,但是在机器翻译、问答系统,文本摘要领域Transformer的表现都要优于基于RNN的Seq2Seq模型。
Transformer 分为编码器和解码器两个部分。编码器部分负责编码语义信息,经过词嵌入表达将词转换成词向量后,经过多头注意力机制来获取每个词与当前句子内的其他词的语意相关性。首先利用注意力机制来计算当前词与其他词的得分分布,再通过softmax 函数进行一次映射,经过映射后的得分越高说明两个词的相关性越强。Transformer的研究者提出多头注意力机制通过将词向量的维度切分,并行做注意力分布的计算从而加强语义信息的解析,计算式为:

其中:Wq、Wk、Wv是3 个可学习的参数矩阵;dk为词向量的维度,XEncoderInput为Encoder 输入的词向量,而自注意力机制中作线性变换的向量XEncoderInput来源相同,这也是和后续解码器中的编码器与解码器的多头注意力机制(Encoder-Decoder Multi-Head Attention)不同之处;at是通过自注意力计算后得到的每个词对同一句话中所有词的注意力分布;Context_vector是编码器阶段输出的隐向量。
在解码器结构中进行两次注意力计算:第一次是利用覆盖的多头自注意力机制(Mask Multi-Head Self-Attention)对解码器中的输入信息进行语意解析,然后通过Encoder-Decoder Multi-Head Attention 解码由编码器中输出的信息,这里的Encoder-Decoder Multi-Head Attention 计算式与式(1)~(2)中所给相同,但是做点积的元素略有不同:
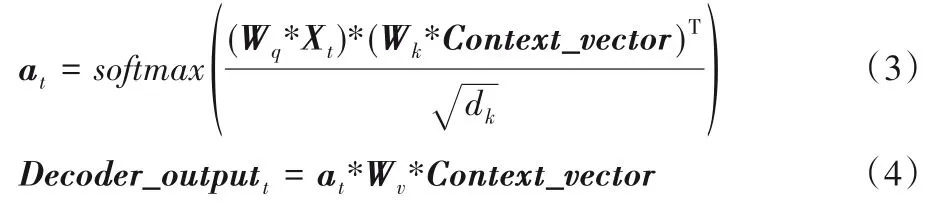
其中:Context_vector是编码器阶段的输出结果,而Xt则是解码器的阶段中的输入信息经过Mask Multi-Head Self-Attention后得到的输出结果。此处的at是生成的词向量对编码器中输出的Context_vector的注意力分布,Decoder_outputt是t时刻Encoder-Decoder Multi-Head Attention的输出。
将上面得到的Decoder_outputt,经过两层线性变换及softmax函数得到了最终的词表分布Pvocab:

其中:W'、W、b、b'都是可学习的参数;Pvocab是词表中所有单词的概率分布。利用最终的概率分布得到当前时刻预测的词w:

本文将上述模型部分作为实验中的Baseline 模型进行对比,模型结构如图1所示。
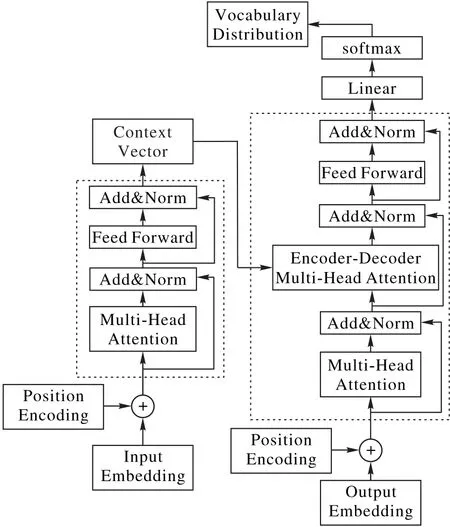
图1 Transformer摘要模型结构Fig.1 Structure of Transformer-based summarization model
1.2 Pointer Generator Network
Pointer Network 最开始被Vinyals等[7]所提出,目前被广泛应用于NLP 任务中,如机器翻译[8]和语言模型[9]。本文所提出的Pointer Generator Network 是介于Transformer 和Pointer Network之间的混合形式。
Pointer Generator Network 所解决的问题是经过Pvocab得到的词最终词表没有覆盖,也就是生成式任务中的OOV 问题。因此本文定义一个概率分布Pgen,将上面章节得到的Decoder_outputt、at,以及t时刻编码器中的输入Xt进行拼接(Concat)后进行一层线性变换后,再经过sigmoid 函数进行一次映射得到[0,1]区间的映射:
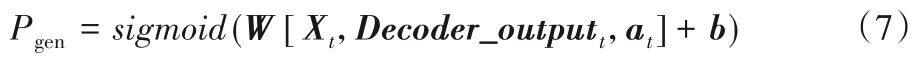
其中W、b是可学习参数。
在生成摘要的过程中,是通过Pvocab在词表中生成新的词汇还是根据得到的文本的概率分布at在原文中拷贝一个相关性最大的词,本文可以通过Pgen进行一次软性选择:

如果w是一个词表没有覆盖的词,则Pvocab(w)的值为0,相反如果w并没有在原文本中出现,则at为0。解决OOV 的能力是本文模型的一个重大优势,本文会在后续实验章节中将其与本文的baseline 模型的结果作比较。Transformer 摘要模型的主要模块如图2所示。
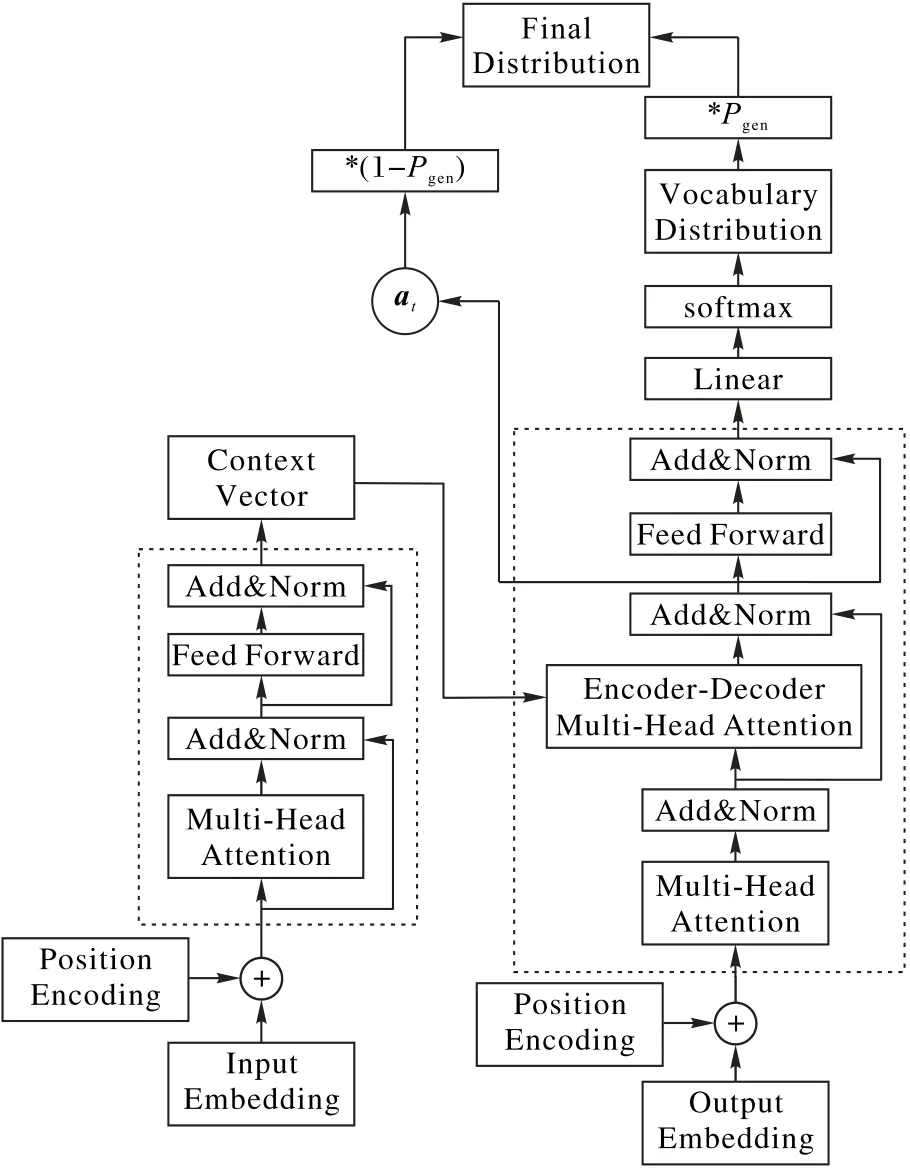
图2 Transformer+Pointer Network 摘要模型流程Fig.2 Flow chart of Transformer-based summarization model with Pointer Network
1.3 Coverage Loss
在生成式任务中,采用注意力机制的模型产生重复问题是一个常见的问题,尤其是产生多个句子的任务中。这一点文献[10-12]也都有提及。因为在按时间片t去逐个生成词时,很有可能连续几个时间片得到最高分的都是同一个词,从而导致了这个得分最高的词不断地重复,影响到语意的通顺性。

为此本文尝试在损失函数中加入覆盖损失(Coverage Loss)去惩罚不断重复位置。在本文的模型里,首先定义向量ct,它所表达的含义是t时刻之前t-1时刻分布的累加和:其中,ct所表示的是前t-1 时刻的词汇分布,即到t时刻位置这些单词从注意力机制中获得的覆盖程度(预测t时刻的单词时,让模型看到前t-1 时刻中原文本注意力分布的情况)。初始化c0是一个零向量,因为第1个时刻没有文本被覆盖。
本文希望模型更多地注意到之前没有关注到的信息,所以在ct、at之间取得一个最小值:

其中:at是t时刻的注意力分布,i代表了词向量的维度;min表示t时刻第i维词向量在和中取最小。在cov_loss中加入超参数λ,并得到模型最终的损失函数:
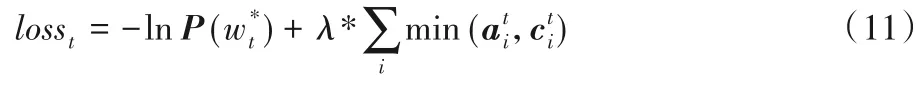
2 实验与结果分析
2.1 Beam Search算法
模型在生成概率分布之后,需要到词表中进行查询,在实验中本文使用束搜索(Beam Search)算法[13]进行查找。
由于模型最终可以学习到t时刻的条件概率分布,即p(yt|x,y1,y2,…,yt-1),并且该研究任务的目标是根据编码器阶段的输出x以及前t-1 时刻所生成的词寻找到t时刻生成概率最大的词,所以目标函数可表示为:
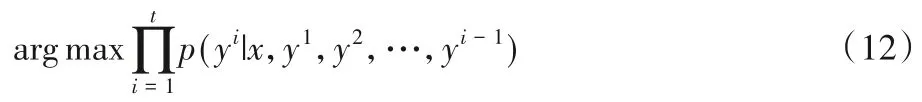
因为概率值都是在[0,1]内,连乘会导致数值下溢,为了方便计算及存储数值,取目标函数的对数值如下:
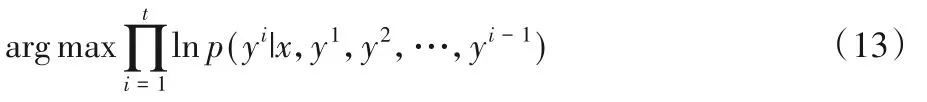
对于一个较长的句子,不断地对概率值进行连乘会得到一个很小的值,这样目标函数会倾向于生成一个较短的摘要。虽然上文中将概率分布取了对数值,但是数值的分布区间是小于0 的,多个负数进行累加同样会出现长文本生成较短摘要的问题。所以本文对目标函数进一步进行优化,将目标函数通过除以输出文本的长度的方式进行了归一化处理。最终可以取得每个单词的概率对数的平均值,很明显地减少了对输出长的结果的惩罚。在实验中本文加入了一个超参数软性因子α,作为输出文本长度Ty的指数:
这天一大早,我往那群“倒数前十”中间一坐,尽量忽视四周饱含各种意味的小眼神,表现得从容而友好。可我的内心实在是无比尴尬,感觉自己就像一个明晃晃的“间谍”。其实,作为同班同学,我们也在一起玩过,说不熟也不可能,但实在是交往不深。我自顾自地跟成绩较劲,他们垫底垫得默默无闻,大家相见客客气气。现在我这一来,一下子打破了后半间教室的“和谐氛围”——说“一粒老鼠屎坏了一锅粥”吧,真心不合适;说“鹤立鸡群”吧,勉强维护了我的自尊。

基于贪心搜索(Greedy Search)方法在生成每个词时都挑选概率最大的词作为当前时刻的最优解,但是在生成式任务中概率最大的词通常不是最优的表达方式。
Beam Search 算法可以看作是对于Greedy Search 的改进算法,相较于贪心算法扩大了搜索空间,但是时间开销又远小于穷举算法,可以看作是二者的折中方案。
Beam Search 存在一个超参数beam size,设为k。第一个时间步长,选取当前条件概率最大的k个词,当作候选输出序列的第一个词。之后的每个时间步长,基于上个步长的输出序列,挑选出所有组合中条件概率最大的k个,作为该时间步长下的候选输出序列。始终保持k个候选值,最后从k个候选值中挑出最优的。当k=1 时,Beam Search 等价于Greedy Search。
2.2 ROUGE评价函数
本文将Rouge 函数[14]作为模型生成的摘要的评价标准。ROUGE-N函数计算式如下:
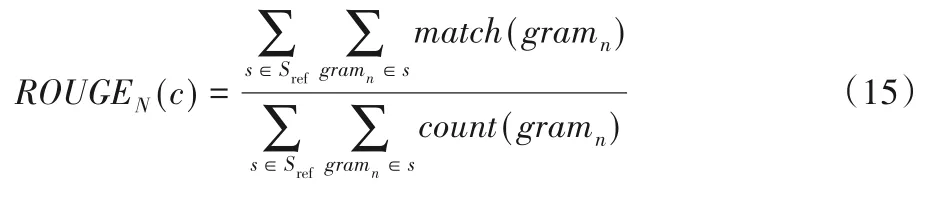
其中:c是生成的摘要文本;Sref是参考摘要;match(gramn)是在生成的摘要中n元词组(N-gram)出现的次数;count(gramn)是N-gram在参考摘要中出现的次数。
ROUGE-N 是从N-gram 维度去比较参考摘要和生成摘要,ROUGE-L是从最长子序列的维度去比较的:
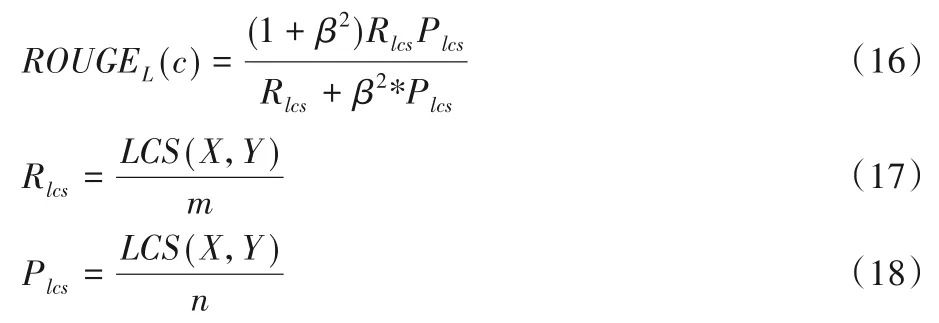
其中:LCS(X,Y)表示X、Y最长公共子序列的长度,X表示参考摘要,Y表示生成摘要;m和n分别表示X和Y的长度;Rlcs、Plcs分别表示召回率和准确率,β=Rlcs/Plcs。
2.3 数据集
本文实验采用的是Hu 等[15]提供的新浪微博数据集LSCST(Large Scale Chinese Short Text summarization dataset)。该数据集以微博短文及其摘要作为文本摘要对。整个数据集分为训练、验证和测试三部分。数据集中包含了人工对摘要和文本相关程度的打分(1~5分),经过打分不低于3分的筛选和采样,最终每个部分分别保留20 000、5 000和700条数据。
2.4 实验细节
实验过程中模型遵循标准的Transformer 结构,使用了6层编码器和解码器,Multi-Head Attention 中头使用了8 个。本文实现了Transformer 研究中所建议的衰减学习率,在热启动时学习率线性增加,之后随着时间衰减学习率。
Dropout 设置为0.3,batch size 设置为32,最大原文输入长度设置为512,生成摘要的长度设置为100,本文使用的损失函数是交叉熵损失函数。对模型一共训练了400个epoch。
作为对比,本文将Transformer 作为baseline,第二个对比模型是Transformer 中加入Point Generator Network,第三个对比模型是Transformer 中加入Pointer Generator Network 和Coverage Loss。其中Coverage Loss 中的超参数λ最终设置为1。
2.5 摘要结果对比
以一条数据为例,原文内容为:春运期间,盐城交警加大对客运车辆的检查力度大力开展“两客一危”专项整治行动2 月17 日14 时左右盐城交警高速三大队在盐城北收费站对一辆号牌为苏mj3940 驶进行检查时发现了客车狭小的过道里竟挤满了人,经过核查相关证件得知该车核载人数为53 人而车上竟有61 人超员8 人!在对车辆进行检查时民警发现车辆的前挡风玻璃上竟还有一道裂缝!民警杨星随后责令车辆驳载通知泰兴市运输总公司安全主管人员24 小时内到盐城交警高速三大队接受约谈。千万不要认为“挤一挤没事”下面这位网友的做法就值得表扬盐城交警也迅速反应,对涉事车辆进行了处罚不要为了赶时间而乘坐超员车不要认为挤一挤没有事不要认为自己有座就漠不关心拒绝超员车,平安回家路。
摘要内容为:核定53人,实载61人,前挡风玻璃竟然还有一道裂缝!你真的认为乘坐超员车只是“挤一挤没事儿”吗?安全问题不容忽略!
针对该短文各模型的结果展示如表1所示。

表1 Transformer及其优化模型的摘要结果对比Tab.1 Comparison of summarization results of Transformer and its optimization models
通过对比实验中得出的结果可知,Baseline得出的结果中存在大量的无法覆盖的字符([UNK]),表明词表没有覆盖的信息,这类无法覆盖的词大多是成语、人名或者一些网络自造词,这些词语通过预训练语料也是难以覆盖全面的。同时Baseline的结果中也存在大量的重复字词,由于生成长度的限制如果摘要中出现了大量的重复无意义的信息,必然会导致最后生成的摘要不完整,从而影响语意的通顺。
引入Pointer Generator Network 后的实验结果表明,解决了因为词表无法覆盖从而产生[UNK]的问题,语意大致连贯。但是由于重复造成的语意断层、前后衔接不连贯的问题仍然存在。
引入Coverage Loss 后的实验结果表明,Coverage Loss 在一定程度上可以解决重复问题,结果中重复频次大幅度减小,语意连贯性也显著增强,所以对比实验结果表明加入Pointer Generator Network和Coverage Loss后作用明显。
ROUGE函数评价不同模型的得分如表2所示。

表2 Transformer及其优化模型的摘要结果ROUGE得分对比 单位:%Tab.2 Comparison of ROUGE scores of summarization results of Transformer and its optimization models unit:%
3 结语
本文所提出的基于Transformer 实现文本摘要的模型,分别利用Pointer Generator Network 以及Coverage Loss 解决了OOV、表达重复以及不准确的问题。实验结果表明,每加入新的模块后得分都会相较之前有所提高,从验证集的结果来看,每加入新的模块得到的摘要内容也更加具有可读性,这也验证了本文后续加入的两个模块在Baseline 的基础上提升了模型的性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
新高考·高一数学(2022年3期)2022-04-28
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
数字技术与应用(2021年1期)2021-03-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
