
基于多特征提取的图像语义描述算法
2021-07-02 08:54赵小虎
计算机应用 2021年6期
赵小虎,李 晓*
(1.矿山互联网应用技术国家地方联合工程实验室(中国矿业大学),江苏徐州 221008;2.中国矿业大学信息与控制工程学院,江苏徐州 221008)
(∗通信作者电子邮箱ts18060032a31@cumt.edu.cn)
0 引言
图像语义描述一直是人工智能领域中最重要的研究方向之一,是图像理解的高级任务。它首先需要识别图像中的对象和场景,描述目标类别、属性以及对象和其在场景中位置之间的关系,然后将描述信息转化为一个有一定的语法结构和语义的句子,这样人们可以在没有看到图像的情况下很快地理解图像内容。因此图像的语义描述设计了多种模型,根据句子生成方法的不同,可分为基于模板的方法[1-4]、基于检索的方法[5-8]和基于神经网络的方法。目前,基于深度神经网络的图像语义描述方法在这一领域取得了重大突破,尤其是卷积神经网络(Convolutional Neural Network,CNN)与递归神经网络相结合的语义描述生成模型。此模型生成的句子与人工标注的句子非常接近,在多个数据集上都取得了良好的效果。
Mao 等[9]创造性地将卷积神经网络和递归神经网络相结合,解决了图像描述和句子检索等问题。自此之后,基于深度神经网络的图像语义描述方法得到了广泛的发展。Kiros等[10]率先将编码-解码框架引入图像语义描述研究,利用深度卷积神经网络对视觉信息进行编码,同时利用长短时记忆网络对文本数据进行编码。Szegedy 等[11]提出了一种基于GoogLeNet 和长短时记忆(Long Short-Term Memory,LSTM)网络的图像标语义描述模型,该模型只需要将整个图像特征放入LSTM 的初始时间步长,以此降低模型的复杂度。为了生成与图像内容密切相关的图像标题,Jia 等[12]提出了一种扩展的LSTM 模型g-LSTM(guiding-LSTM),提取图像的语义信息来表示图像与描述之间的关系。在图像语义描述生成阶段,该模型利用语义信息指导LSTM 的每一步生成。实验结果表明,语义信息可以显著提高描述性能。Xu等[13]首先提出了一种基于注意力机制的图像标题方法,该方法将图像平均分成14×14图像块,利用“soft”和“hard”注意力机制对图像的突出区域进行自动搜索,生成图像标题。Li 等[14]提出了一种基于全局-局部注意机制(Global-Local Attention,GLA)的图像语义描述方法,该模型将注意机制分解为目标级局部表示和图像级全局表示,从而在保持图像全局上下文信息的同时,更准确地预测突出目标。Luo 等[15]利用从图像中检测出的语义概念实现图像语义描述。He 等[16]使用词性标注引导长短时记忆网络生成单词。Yang 等[17]提出了情感概念,用以增强文本描述的情感表达能力,通过将适当的情感概念组合到句子中来实现。
综上所述,现有方法主要是依靠卷积神经网络(CNN)获取固定的全局图像特征向量,并通过循环神经网络(Recurrent Neural Network,RNN)对其进行解码。然而全局图像特征不足以表示完整的图像信息,需要进一步获取图像中的场景类型、位置信息等以增强图像的语义表达。其次,在RNN 中存在梯度消失问题,利用LSTM 可消除梯度消失现象,但是LSTM 只能够捕捉单向时序信息,未实现真正意义上的全局上下文。为了解决以上问题,本文提出了一种基于多特征提取的图像语义描述算法,在图像视觉特征提取时加入了图像属性提取,利用图像的全局特征和附加的高级语义信息来建立图像和句子之间的关系。此外,在解码阶段使用了双向长短时记忆(Bidirectional LSTM,Bi-LSTM)网络,使得模型能够捕捉双向语义依赖,有效地提高了模型对图像的语义描述性能。
1 本文模型
本文的模型是基于深度神经网络框架下的图像语义描述模型。如图1 所示,该模型包括三个部分:图像特征提取[18]、图像属性提取以及用于单词生成的双向长短时记忆网络。其中,采用Resnet-50 残差网络架构的卷积层与平均池化层提取图像的全局特征Vimg。Resnet-50 残差网络在ImageNet 分类数据集上预先训练。
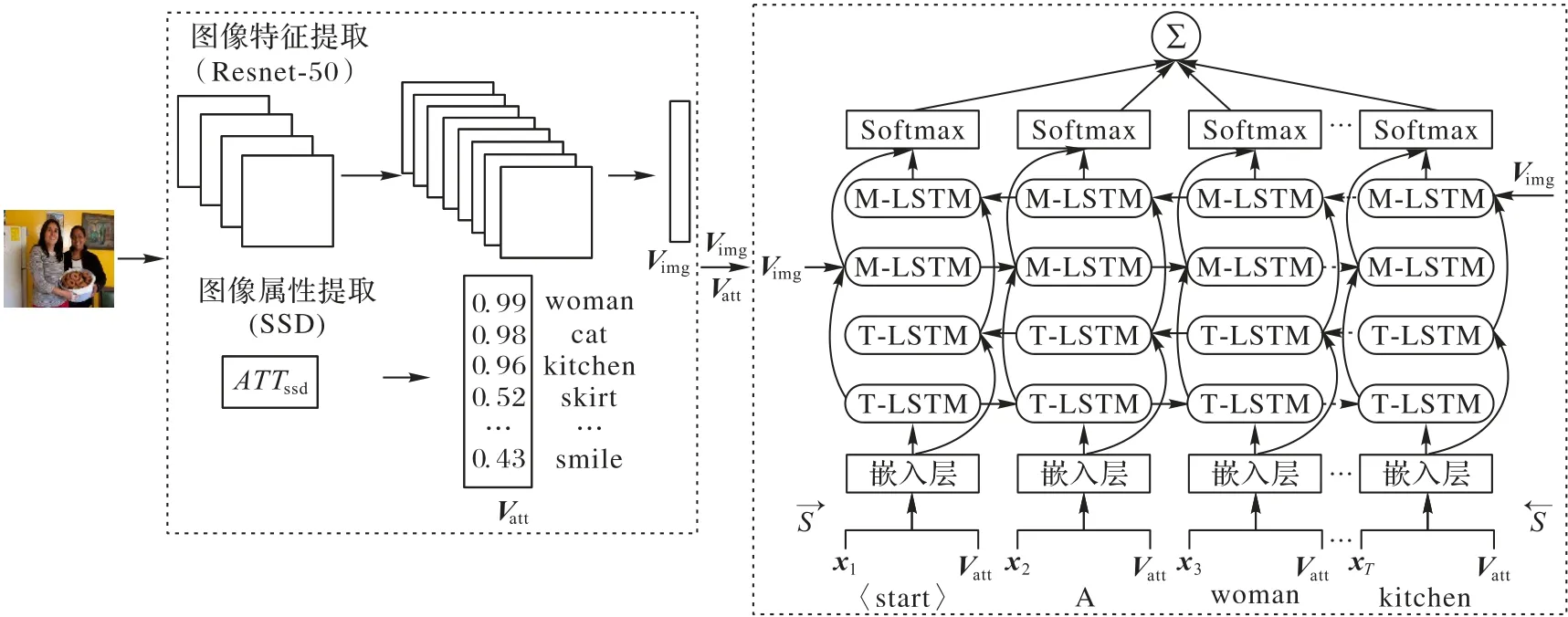
图1 本文模型整体结构Fig.1 Overall structure of proposed model
1.1 图像属性提取
图像语义描述成功的关键在于良好的图像特征表示。根据人类对图像的直观描述可知,良好的图像特征能够准确地反映图像的内容和属性信息,如场景类型、位置信息等。但是只提取图像全局特征过于粗糙,会丢失很多重要信息,难以满足上述要求,因此在句子生成过程中会产生对象误差预测的问题。针对以上问题,本文采用SSD(Single Shot multibox Detector)模型对图像的属性信息进行提取以增强图像特征表示,从而提高图像语义表达性能。和一般方法不同的是本文对SSD 进行进一步的改进,使其不仅可以准确地描述目标细节,还可以更加准确地描述目标的行为及其所在场景,极大提高了其在真实场景中的应用。
SSD 网络[19]用于检测图像属性特征。如图2 所示,选用Resnet-50[20]残差结构为其前置网络,代替了原来的VGG16网络,解决目标尺度小、分辨率低等问题,并且相较于原来的网络增加了一层特征提取层,提高了网络的特征提取能力。选取的特征提取层为Conv2_x、Conv3_x、Conv4_x、Conv5_x 以及Conv7_x、Conv8_x、Conv9_x,共提取7 个特征图。输入图像大小为224×224。
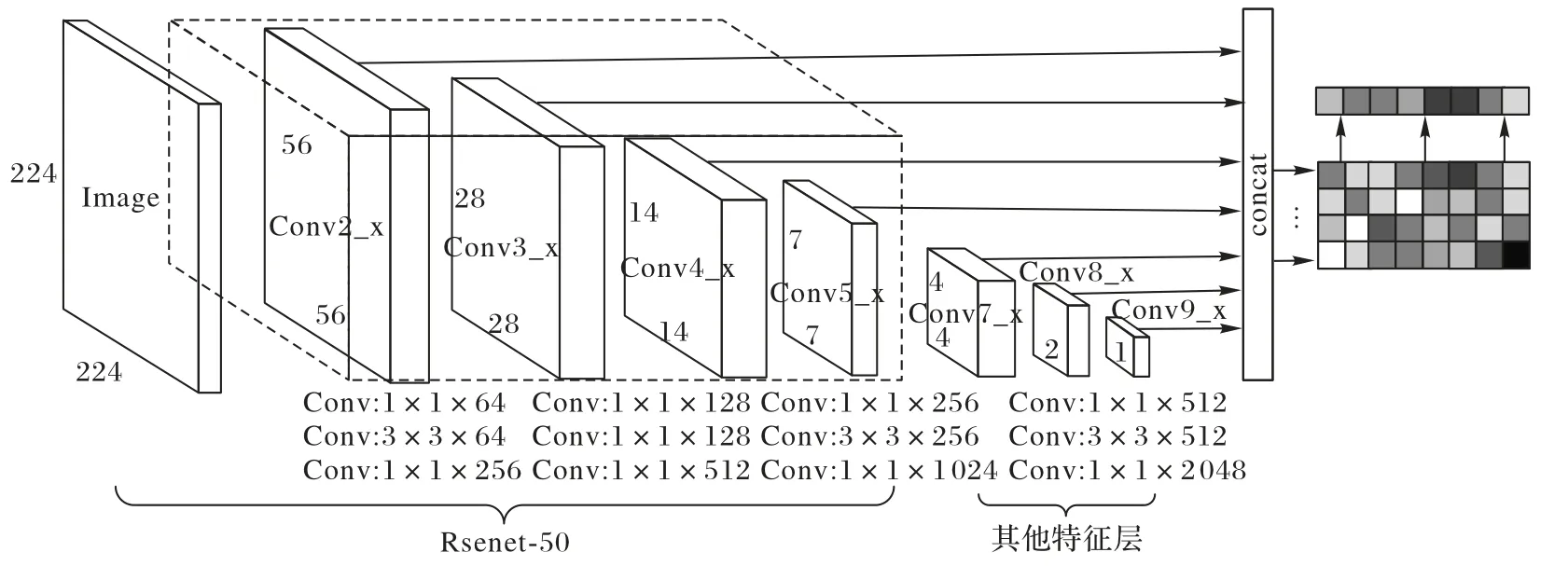
图2 图像属性提取结构Fig.2 Structure of image attribute extraction
为了能够检测到图像中不同尺寸的物体,此网络使用若干不同输出尺寸的特征图进行检测。位于不同层的特征图设置的先验框数目不同,其参数包括尺度和长宽比两个方面。先验框的设置遵守线性递增规则:
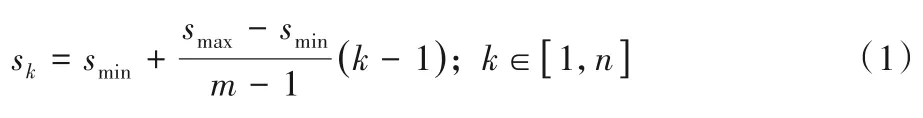
其中:n为特征图个数;sk表示先验框相对于图像所占的比例,smin、smax分别为0.2、0.9。对于先验框长宽比,一般选取ar=则每个先验框的宽、高分别为:先验框的中心点为为第k个特征图的大小。
先验框的参数设置直接影响着模型检测不同尺度物体的性能,先验框长宽比的分布也同样影响模型检测目标的准确率。为了达到最高准确率,并且减少不必要的计算量,对先验框长宽比的选择进行了实验,结果如图3所示。
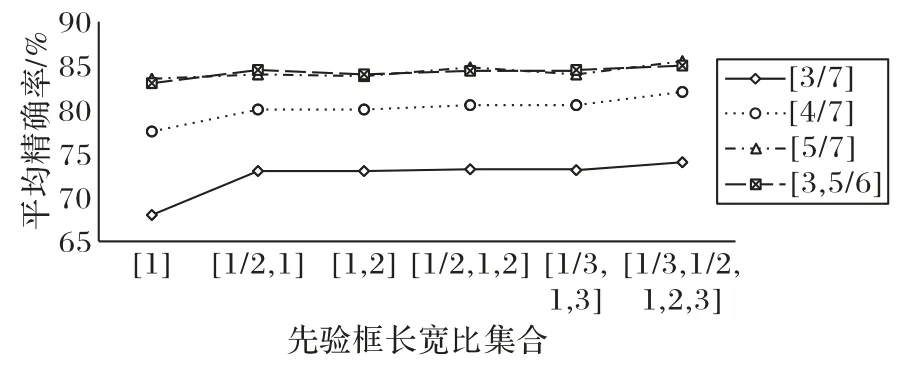
图3 不同先验框长宽比的平均精确率对比Fig.3 Comparison of mean average precision of different anchor box length-width ratios
图3 中,横坐标为使用的先验框长宽比的集合,例如,[1/2,1]表示针对当前图像采用的先验框的长宽比分别为1/2和1。折线[3/7]表示7个卷积层的先验框都是3个,即先验框长宽比为[1/2,1,2]。从图3 可知,折线[3,5/6]和[5/7]在此实验中的平均精确率(mean Average Precision,mAP)较高,分别为85.2%和85.4%。相较[3,5/6]卷积层长宽比的分布,[5/7]的分布需要多计算6 272 个先验框,增加了计算复杂度,但mAP值却只增加了0.2个百分点。因此本文选择的先验框参数如表1所示。
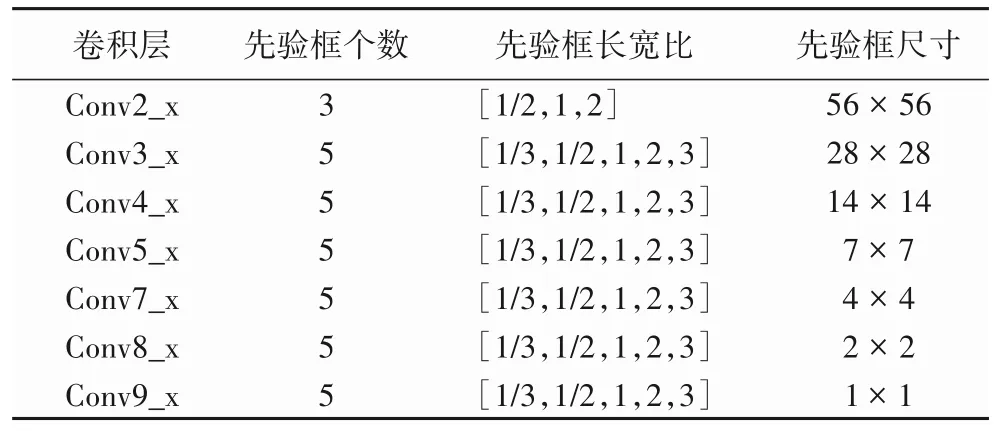
表1 先验框参数Tab.1 Anchor box parameters
属性提取得到矩阵Matt,将输出矩阵通过式(2)计算得到图像属性Vatt:

其中:m为输入图片上的边界框个数,m=14 658;c为检测类别数,在Visual Genome 数据集上训练属性提取模型(ATTribute extraction model,ATT),令c=300。
1.2 双向长短时记忆网络
在传统的图像语义描述中,循环神经网络随着时间步长的增加,存在梯度消失的问题,缺乏前一时刻的指向性信息;并且该网络只能利用单向时序信息,未实现真正意义上的全局上下文。为了解决以上问题,本模型使用了双向长短时记忆网络,能够充分利用句子过去和将来的上下文信息预测语义,生成涵盖丰富的语义信息的语句,并且更加符合人类表达习惯。
Bi-LSTM[21]模型建立在LSTM 单元上,LSTM 单元是传统递归神经网络的一种特殊形式。图4 为长短时记忆网络单元示意图。读写存储单元c由一组sigmoid 门控制,当时间步长为t时,LSTM的输入来源有:当前输入xt、所有LSTM单元之前的隐藏状态ht-1以及记忆单元ct-1。对于给定的输入向量xt、ht-1和ct-1,t时刻门的更新如下:

图4 长短时记忆网络单元Fig.4 LSTM network unit
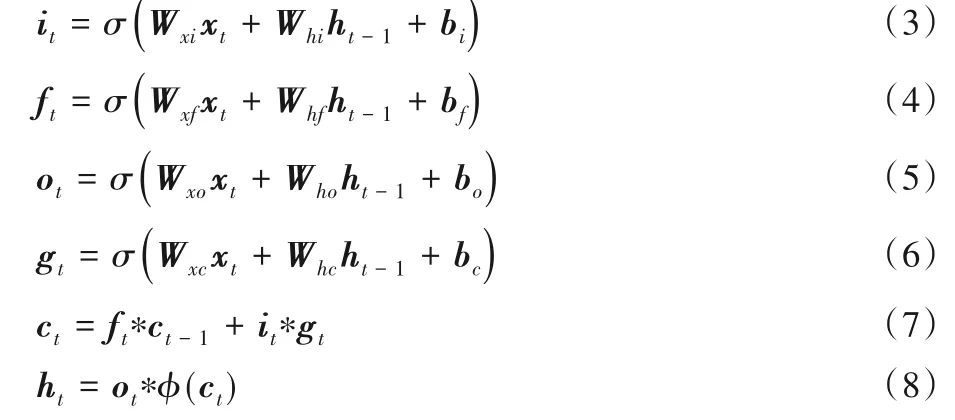
其中:W为网络的权重矩阵;b为偏置向量;σ是sigmoid 激活函数,即σ(x)=;φ是双曲正切函数,即φ(x)=;“∗”表示门值计算。LSTM 隐藏层输出ht=,ht和权重矩阵Ws、偏置向量bs通过Softmax 函数被用于预测下一单词的概率:
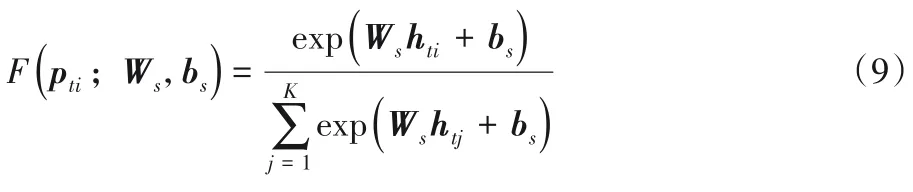
其中pti为预测词的概率分布。
如图5 所示为Bi-LSTM 模型,该模型由三部分组成:图像全局特征Vimg、用于编码句子输入的T-LSTM(Test LSTM)、用于将视觉和文本向量嵌入到公共语言空间的M-LSTM(Multimodal LSTM)。输入向量xt与图像属性Vatt共同作为Bi-LSTM的输入,因此T-LSTM层的输入Vt可表示为:

图5 Bi-LSTM结构Fig.5 Structure of Bi-LSTM

其中:fv(•)为全连接层;“⊕”表示级联运算。
Bi-LSTM 是由两层分开的LSTM 组成,用于计算前向隐藏层序列和后向隐藏层序列。前向LSTM 开始于t=1,后向LSTM开始于t=T。模型工作中,对前向句子和后向句子编码表现为:

其中:T代表T-LSTM,Θl是它们相应的权重;{x0,x1,…,xT}={xT,xT-1,…,x0}。为从网络中学习得到的双向嵌入矩阵。之后将编码的视觉和文本表示通过以下计算式嵌入到M-LSTM:

其中:M为M-LSTM,Θm为其权重。目的是在不同的时间步长的情况下,捕捉视觉语境与词汇之间的相关性。在每个时间步长向模型中输入可视化向量Vimg,以捕获强大的可视化单词相关性。在M-LSTM 的最上层是Softmax 层,通过该层计算下一个预测词的概率分布:

其中,p∈RK,K为字典大小。
1.3 损失函数
本文模型通过采用随机梯度下降(Stochastic Gradient Descent,SGD)的方法实现端到端的训练。在训练中,通过给定的图像上下文I和前向顺序P(wt|w1:t-1,I)或者后向顺序P(wt|wt+1:T,I)中的先前的单词上下文w1:t-1预测单词wt,分别设置w1=wT=0 时为前向和后向的起点。联合损失函数L=是累加前后向的Softmax损失得到。
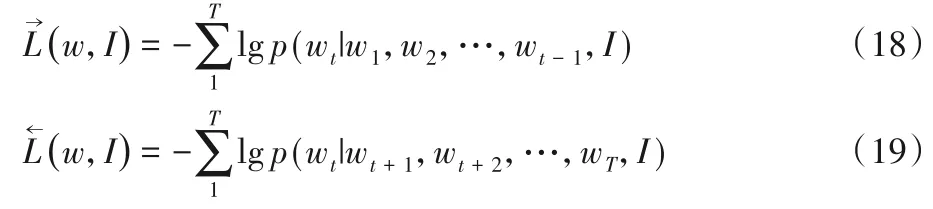
其中,T为生成序列的长度。本文的目标是最小化L,这就相当于最大化生成正确句子的概率。最后可从两个方向生成句子,本文根据句子的单词生成概率确定给定图像p(w1:T|I)最终的句子。
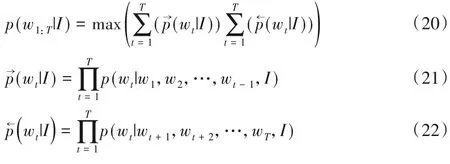
2 实验与结果分析
2.1 训练细节
在训练过程中,每张图像都有3 个相关的注释。首先通过提取图像属性得到Vatt,Vatt被用于计算Bi-LSTM 网络的每个时间步长。符号〈start〉是一个句子的开头,〈end〉是句子的结尾。本文使用了双层循环神经网络Bi-LSTM,隐藏单元数为512,权重衰减率为0.000 5。优化器学习速率为0.001,设置batch size为64、动量为0.9来训练本文的模型。
2.2 数据集
本文使用的数据集为Flickr8k、Flickr30k 和MSCOCO 数据集。Flickr8k数据集中有6 000张训练图像、1 000张测试图像和1 000张验证图像。Flickr30k数据集包含31 000张图像,随机将其中29 000 张图像用于训练,1 000 张图像用于测试,1 000 张图像用于验证。两个数据集中的每个图像对应五个人工生成的描述。MSCOCO 数据集包含82 738张用于训练的图像,40 504 张用于验证的图像,每个图像有5 个由AMT(Amazon Mechanical Turk)得到的句子。
2.3 结果分析
为了评估属性提取模型(ATT)和Bi-LSTM 的有效性,分别在Microsoft COCO Caption 数据集和Flickr8k、Flickr30k数据集进行实验,将本文的模型与当前流行的图像语义描述方法进行比较,结果如表2~3 所示。所用的评估指标为BLEU(Bilingual Evaluation Understudy)、METEOR、ROUGE-L 和CIDEr(Consensus-based Image Description Evaluation),具体内容如下:
1)BLEU 是一种基于精确度的相似性度量机器翻译评价指标,用于分析候选译文和参考译文中n元组共同出现的程度。
2)METEOR是基于单精度的加权调和平均数和单字召回率,其目的是解决一些BLUE 标准中的缺陷,与BLUE 相比,其结果和人工判断的结果有较高的相关性。
3)ROUGE-L 是基于最长公共子句的度量方法。参考译文与待评测译文的共现性精确度越高,则生成的句子质量越高。
4)CIDEr 是专用于图像语义描述的度量标准,通过TFIDF(Term Frequency-Inverse Document Frequency)计算每个n元组的权重来衡量图像语义描述的一致性。
表2 为不同模型在MSCOCO(Microsoft COCO)数据集上的结果。评价指标有BLEU、METEOR、ROUGE-L 和CIDEr。其中,模型Bi-LSTM+ATT+CNNR以及Bi-LSTM+CNNR在BLEU-1、BLEU-2、BLEU-3、BLEU-4 指标上分别达到了74.5%、59.3%、45.5%、36.3%和74.0%、57.2%、44.5%、33.6%。由此可知,两种类型的图像语义信息能更准确描述图像信息。由表2 还可以看出,本文模型的性能显著优于其他方法,表中用于对比的方法为最新的方法,分别为:NIC(Neural Image Caption)[22]、LRCN(Long-term Recurrent Convolutional Network)[23]、Deep-Vis(Deep Visual-semantic)[24]、m-RNN(multimodal Recurrent Neural Network)[9]、g-LSTM[12]、Hard-Attention[13]、Soft-Attention[13]、HMA(Hierarchical Multimodal Attention-based)[25]、VLM(Visual attention based on Long-short term Memory)[26]、GLA[14]和PSG(Part of Speech Guidance)[16]。这些方法使用了不同的特征提取方式[27],NIC 和g-LSTM 使用GoogLeNet 获得图像特征;LRCN 利用AlexNet 来提取图像特征;Deep-Vis、m-RNN、Hard-Attention、Soft-Attention利用VGG16获得图像特征。不同的卷积神经网络提取特征的能力是不一样的,以上所有模型均未使用高级语义信息。实验结果表明,与仅用单一的语义信息特征的模型相比,两种类型的图像信息能够有更好的描述效果。递归神经网络的使用也是不同的:NIC、g-LSTM、Hard-Attention 和Soft-Attention 使用LSTM 网络作为语言模型生成图像句子描述;m-RNN 利用基本的RNN作为解码器;LRCN 使用一个堆叠的两层LSTM 将图像转换成句子描述;在本文的模型中,使用了Bi-LSTM 得到图像语义描述。

表2 Microsoft COCO 数据集上不同模型实验结果对比 单位:%Tab.2 Experimental result comparison of different models on Microsoft COCO dataset unit:%
不同模型在Flickr8k 和Flickr30k 数据集上的结果如表3所示。同样地,在Flickr8k 和Flickr30k 数据集上,本文的模型也获得了BLEU和METEOR指标的最佳性能。
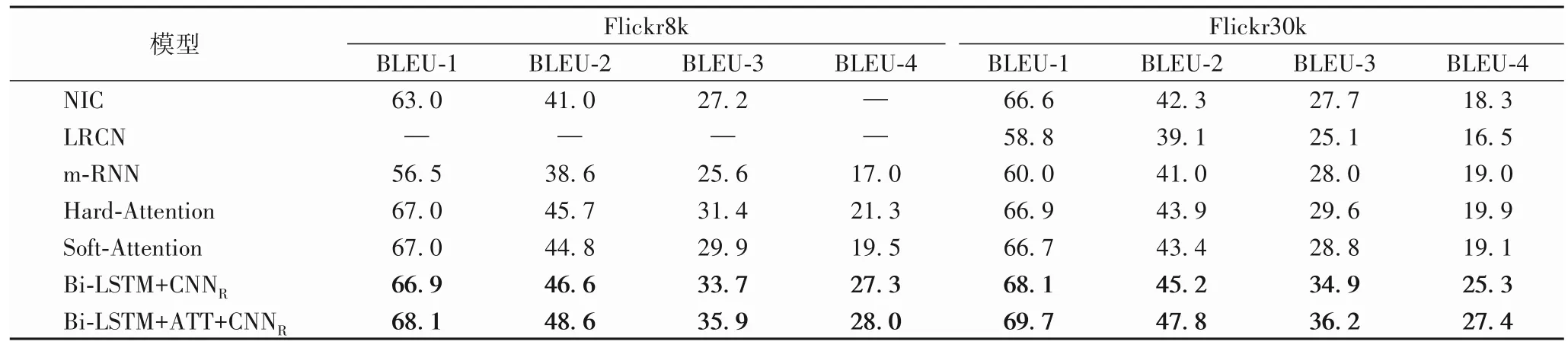
表3 Flickr8k、Flickr30k数据集上不同模型实验结果对比 单位:%Tab.3 Experimental result comparison of different models on Flickr8k,Flickr30k datasets unit:%
由表2~表3 的结果可知,本文的模型在Microsoft COCO数据集和Flickr8k、Flickr30k 数据集上是有效的,表明将Bi-LSTM 网络与ATT 相结合可以提高图像语义描述性能,使用两种语义信息能够有效地提高模型的表达能力,拥有较强的竞争力。
2.4 描述效果对比
图6 为图像在前向LSTM 和后向LSTM 生成的语义描述。从图6 中可以发现两者的一些区别:1)在棒球和橘子汁图像中,一个描述静态场景,另一个描述在下一个时间可能发生的潜在动作或运动。2)生成的语句与标注语句有很高的相似度,例如在火车图像中,前向描述与标注语句“A passenger train that is pulling into a station.”相似,后向描述与标注语句“A train is in a tunnel by a station.”相似。由此可以看出,本文的模型具有较强的视觉语言关联学习能力和生成新句子的能力。

图6 不同LSTMs的图像语义描述效果对比Fig.6 Image captioning effect comparison of different LSTMs
图7 为不同图像在模型中生成的句子。虽然这三幅图像不同,但都可以通过模型生成与图像密切相关并且语言流畅的句子。以厨房图像为例,人物可以很容易识别,但人物的运动状态却很难被识别。与m-RNN 模型生成的句子相比,本文的模型生成的“Two cooks cooking with pans in a restaurant kitchen.”可以准确地描述图片中人物的动作。此外,在食物和沙滩图像中,本文的模型能准确地识别出“doughnuts”和“seagull”,而不仅仅只是描述成“baked goods”和“bird”。结果表明,本文的模型可以更准确地识别出图像中的物体,并且能够准确表述出图像中各个物体之间的关系,生成更相关、更连贯的自然语言句子来描述图像。

图7 不同模型的图像语义描述效果对比Fig.7 Image captioning effect comparison of different models
根据以上实验分析可知,本文所构建的模型能够准确地识别图像中物体,并且能细致地描述所检测到的物体之间的关系;对于图像中较小的物体,本文的模型识别更精确,可以根据图像中人物和场景推测出图像中的人物动作;相较于其他图像语义描述方法,本文的模型在衡量指标上的描述效果更好。
3 结语
本文提出了一种多特征提取的图像语义描述算法,在Flickr8k、Flickr30k和MSCOCO 数据集上的实验结果表明了本文算法在图像语义描述任务中的有效性。与现有的算法相比,本文算法通过提取图像高级语义信息和利用生成语句的双向信息,不仅能准确地描述目标细节,而且能更准确地表现行为和场景。简单的图像语义描述算法有很多局限性,更倾向于捕获全局特征信息,难以在现实场景中应用,未来考虑细粒度图像语义描述生成,如图像段落描述、图像和语言的双向检索等。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
海外文摘·艺术(2020年22期)2020-11-18
校园英语·下旬(2017年4期)2017-06-07
文物鉴定与鉴赏(2017年5期)2017-05-16
成长·读写月刊(2017年2期)2017-03-21
岁月(2016年5期)2016-08-13
长江学术(2015年1期)2015-02-27
北京心理卫生协会学校心理卫生委员会学术年会论文集(2014年1期)2015-02-07
