
用户画像技术在图书个性化推荐中的应用
2021-06-30 01:43遵义医科大学陈锦秋狄思思
电子世界 2021年11期
遵义医科大学 陈锦秋 狄思思
在大数据环境下,如何利用用户数据提高服务质量是图书馆面临的重要课题。用户画像技术是挖掘用户需求、实现精准服务的重要技术手段。本文在图书推荐中引入用户画像技术,基于高校图书馆用户数据构建用户画像,将用户画像和协同过滤算法相结合,实现精准的个性化图书资源推荐。
随着信息技术的高速发展,传统的图书馆逐渐向智慧图书馆转型。智慧图书馆将物联网、云计算、人工智能等智能化技术运用到图书馆的建设中,实现智慧化的服务和管理,为读者提供更加高效、便捷、全面、精准的资源获取方式。
高校图书馆是学生和教师获取信息资源的重要来源之一,是高校办学的重要支柱。构建顺应信息时代发展和读者需求变化的高校图书馆智慧服务体系是高校图书馆建设面临的新挑战。在图书推荐和资源建设中引入智能化技术,能为读者提供更加精准、快捷和个性化的服务,能全方位提升用户体验,提高学习和工作效率,促进教学和科研工作的开展。
1 用户画像相关研究
用户画像这一概念最早由交互设计之父A.Cooper提出,他指出用户画像是基于与用户相关的真实数据建立起来的虚拟模型,是对真实用户的虚拟化。大数据时代背景下,用户的上网行为数据、交易数据、偏好数据等信息数据被各种信息系统记录、收集,利用这些数据信息去刻画用户的特征,挖掘不同类型用户的需求,从而实现精准的服务。图书馆的各种信息设备和信息平台收集、存储着读者的数据信息,这些数据信息反映读者阅读习惯和阅读需求等,利用这些读者数据构建虚拟用户模型,将用户标签化,从而实现智能化、个性化馆内服务。
目前,用户画像技术已被广泛应用于高校图书馆的智慧化服务领域。许鹏程等从自然维度、兴趣维度和社交维度等3个维度构建用户画像模型,并提出了图书馆用户画像的框架模型。刘漫等将用户画像模型与聚类、关联算法结合,探索阅读精准推广服务新模式。潘宇光从读者的属性信息、行为信息、兴趣偏好、社交关系等4个方面刻画用户画像模型,并生成可视化用户画像。
基于用户画像提升图书馆个性化服务的基本流程为数据采集、数据预处理、数据特征分析、用户画像模型构建、数据挖掘算法、服务应用,即首先通过图书馆的信息设备、信息平台和管理系统等采集读者的基本属性数据和行为数据。其中,基本属性数据指读者的年龄、性别、年级、专业、院系、借书证号、联系方式、所属校区等基本信息;行为数据指读者的借阅信息,如借阅时长、图书的书名、图书作者、图书分类等。收集数据后,需要对数据进行一些预处理,对数据的准确性、适用性进行判断和审核,筛选不符合要求的数据或有明显错误的数据,并予以清除。然后,基于用户数据对用户的自然属性特征、兴趣特征、社交关系等进行分析,并构建用户画像模型。最后,将用户画像模型应用于具体的服务。
在构建用户画像模型的过程中,需要利用数据挖掘算法对用户间的潜在联系进行深入挖掘,常用的算法有协同过滤算法、聚类、关联规则等。挖掘用户间的联系是分析用户需求、实现精准服务的关键。
图书推荐是图书馆最重要的服务之一,本文基于协同过滤算法构建用户画像模型,以期实现图书个性化推荐。协同过滤算法分为基于用户相似度协同过滤算法和基于物品相似度协同过滤算法,本文采用基于用户相似度的协同过滤算法。其原理是通过对目标用户的兴趣偏好进行分析、挖掘,找到与目标用户具有相似爱好的相似用户,根据相似用户的喜好向目标用户进行物品推荐。
2 构建用户画像模型
本文选取西南地区某高校图书馆2019年图书借阅量排名前300的读者,通过图书馆的用户管理系统和信息化设备获取读者的基本属性数据和行为数据,以及相关图书的基本属性数据,从自然属性、兴趣属性、社交属性三个维度构建用户画像模型。
2.1 自然属性模型构建
2.1.1 自然属性
用户的自然属性由基本属性数据刻画,本文选取性别、年龄、专业、读者类型作为自然属性模型构建的基础数据。如表1所示。
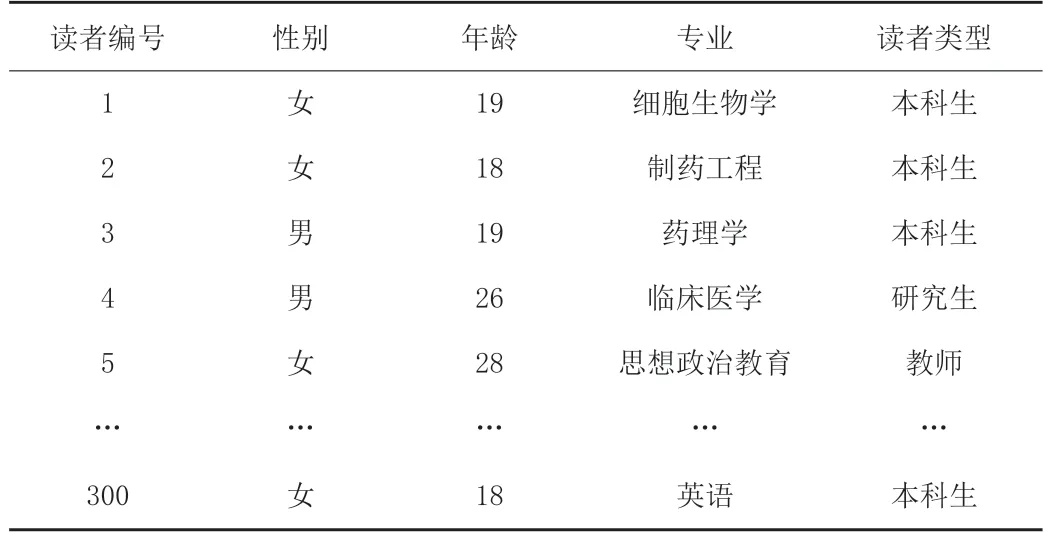
表1 部分读者及其基本属性数据
2.1.2 自然属性相似度计算
本文将每个用户的自然属性看作一个n维的向量,该向量被称为自然属性向量,向量不同的分量代表着不同的属性,第1和第2个分量代表用户的性别属性;由于用户的年龄在17-55之间,笔者按照3岁一个年龄段将用户年龄划分为13个区间,向量的第3至15个分量代表年龄属性;向量的第16至18个分量代表读者类型属性,分别为本科生、研究生和教师;向量的第19至n个分量代表专业属性。用户自然属性对应的分量值为1,其余的分量值为0。例如,向量的前2个分量代表用户的性别属性,如果用户性别为男,则向量第1个分量值为1,第2个分量值为0,如果用户的性别为女,则向量第1个分量值为0,第2个分量值为1。
本文采用余弦相似度方法计算自然属性的相似度,其计算公式如下:

其中,A和B分别表示两个用户的自然属性向量,Ai和Bi分别代表向量A和B的各分量。sim1代表两个用户间自然属性的相似度,其范围在0至1之间,其值越接近1,向量A和向量B间的夹角越接近0°,表明两个用户的自然属性相似度越大。
根据公式(1)计算不同用户间自然属性的相似度,得到的结果如表2所示。
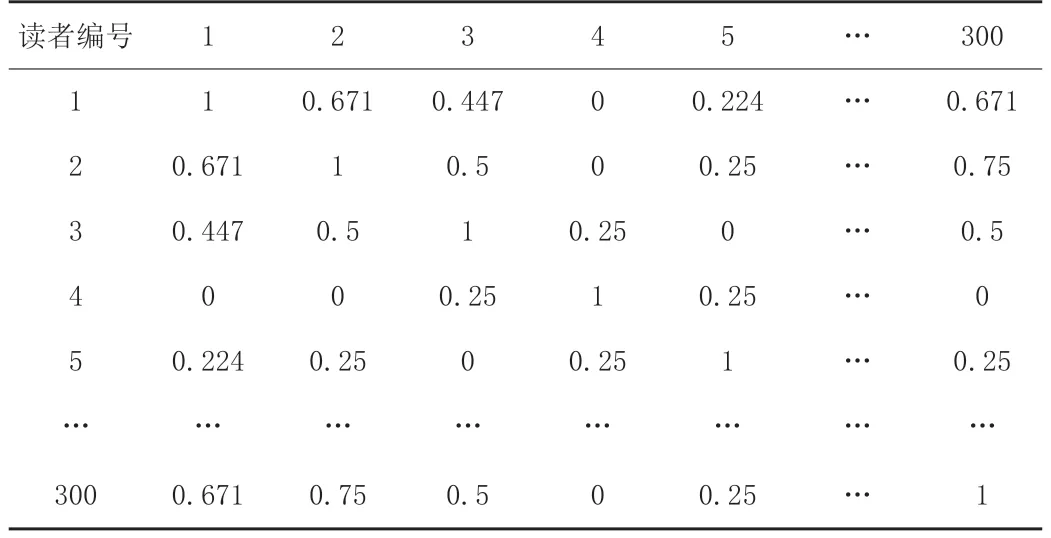
表2 部分读者自然属性相似度
2.2 兴趣属性相似度计算
用户对图书的常规操作有借阅、续借、归还、预约等,这些操作会被图书馆的信息系统记录,形成用户行为数据。用户的行为数据蕴含着用户对不同图书的兴趣偏好,本文对用户的图书借阅记录进行分析,基于兴趣属性特征计算用户间的相似度,从兴趣属性维度构建用户画像。
用户进行一次图书借阅操作将会在系统中产生一条借阅记录,如表3所示,每条借阅记录包含的字段有读者编号、题名、责任者、索书号等。300名读者2019年共形成了6511条借阅记录。
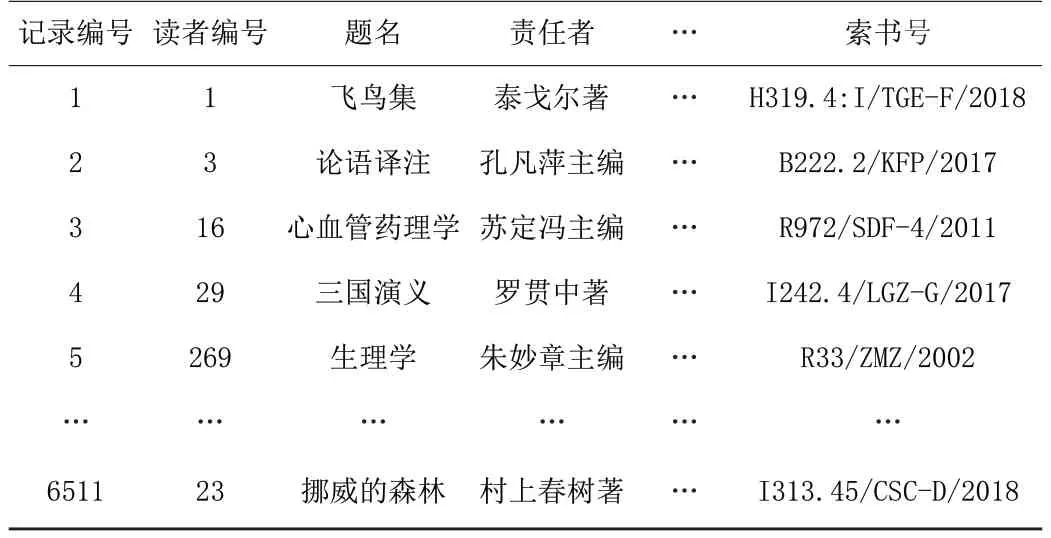
表3 部分读者借阅记录
笔者根据中国图书馆分类法将图书馆的藏书分为22大类,每本图书依据索书号被归为不同的类别,然后统计每个用户借阅不同图书类别的数量。将每个用户的借阅情况用一个向量表示,该向量被称为兴趣属性向量,该向量的维数为22,向量不同的分量代表着不同的图书类别,分量的值表示用户借阅该类别图书的数量。采用余弦相似度方法计算兴趣属性的相似度,其计算公式如下:
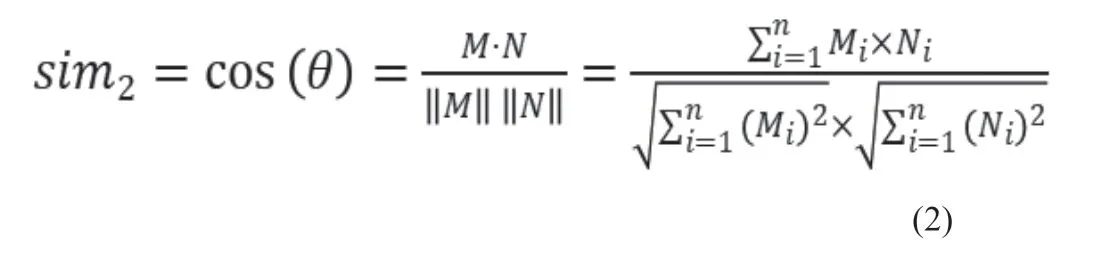
其中,M和N分别表示两个用户的兴趣属性向量,Mi,Ni分别代表向量M和N的各分量。sim2代表两个用户兴趣属性的相似度,其范围在0至1之间,其值越接近1,向量M和向量N间的夹角越接近0°,表明两个用户的兴趣属性相似度越大。
根据公式(2)计算不同用户兴趣属性的相似度,得到的结果如表4所示。

表4 部分读者兴趣属性相似度
2.3 社交属性相似度计算
社交属性是指两个用户借阅行为的关联性。通过观察用户行为数据可以发现,不同的用户之间可能存在着相似的借阅行为:不同的用户借阅同一类别的图书。若两个用户的借阅记录中有同一类别的图书就说明他们的借阅行为有着关联性。社交属性相似度刻画了用户借阅行为关联性的高低。本文通过计算用户社交属性相似度来发掘用户间的关联性,从社交属性维度构建用户画像。采用Jaccard系数来计算用户社交属性相似度,其计算公式如下:

其中集合A表示读者A的图书借阅记录,集合B表示读者B的图书借阅记录,A∩B表示读者A和读者B借阅同一类别图书的数量,A∪B表示读者A和读者B借阅图书类别数的总和。
根据公式(3)计算不同用户之间社交属性的相似度,得到的结果如表5所示。

表5 部分读者社交属性相似度
2.4 用户相似度计算
在计算用户的综合相似度时,为了能同时考虑用户的自然属性特征、兴趣属性特征和社交属性特征,本文采用一种改进的相似度度量方法,其计算公式如下:
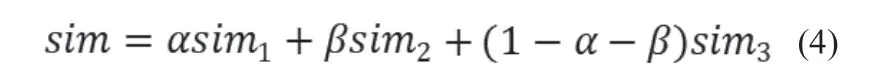
其中,sim1是根据公式(1)计算得出的用户自然属性相似度,sim2是根据公式(2)计算得出的用户兴趣属性相似度,sim3是根据公式(3)计算得出的用户社交属性相似度。参数α、β表示权重,取值范围在0至1之间,本文认为在计算用户相似度时,自然属性的贡献度小于兴趣属性和社交属性,因此设定参数α的值为0.2,参数β的值为0.4。根据公式(4)计算得出用户的相似度,如表6所示。
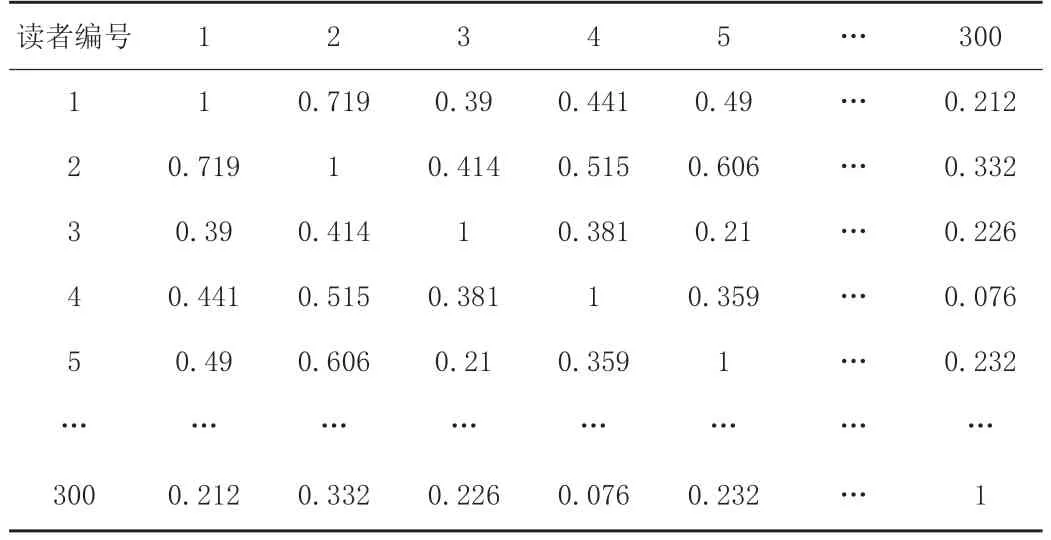
表6 部分读者的综合相似度
3 基于用户画像的图书推荐
根据用户相似度计算结果,得到目标用户与其他用户的相似度集合U,然后将集合U中的相似度排序,找出与目标用户相似度最高的5个用户。
在兴趣属性相似度计算过程中,对目标用户借阅不同图书类别的数量进行了统计,选取数量排名前3名TOP-3的图书类别作为目标用户最喜欢的前3类图书。最后,找出与目标用户相似度最高的5个用户的借阅记录中属于TOP-3类的图书,并将这些图书推荐给目标用户。
本文随机选取编号为43的用户为目标用户,展示基于用户画像的图书推荐过程。
根据表6得到与目标用户相似度最高的5个用户编号分别为268、257、35、297和107.目标用户借阅不同图书类别数量排名前3名TOP-3的图书类别为I(文学)、B(哲学、宗教)、H(语言、文字)。相似度排名前5用户的借阅记录中属于TOP-3类的图书如表7所示。最后,将表中的图书推荐给目标用户。

表7 推荐结果
在传统基于协同过滤算法的图书推荐研究中,大多数研究仅仅根据读者的历史行为数据计算用户相似度,只利用了读者的兴趣属性特征,而忽略了用户的自然属性特征和社交属性特征。本文在构建用户画像时,使用一种改进的用户相似度计算方法,从不同的维度刻画用户画像,旨在准确把握用户阅读习惯和偏好,实现个性化图书推荐。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
意林彩版(2022年2期)2022-05-03
新高考·高一数学(2022年3期)2022-04-28
好日子(2021年8期)2021-11-04
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
高中生学习·高三版(2016年9期)2016-05-14
