
基于大数据分析技术的数字图书馆信息检索模型设计
2021-06-29 10:33吴荣
数字技术与应用 2021年5期
吴荣
(火箭军工程大学图书馆,陕西西安 710007)
1 数字图书馆信息领域本体的建立
通过运用大数据分析技术,对数字图书馆信息领域本体进行有效建立,然后在知识库中,对用户需要进行检索的信息进行搜索。当用户将查询请求输入数字图书馆信息领域本体领域时,推理机便会对输入的语句或者关键词进行语义推理,以构成逻辑表达式,然后会在检索系统中上传逻辑表达式。在进行检索过程中,还应选用RDF等工具来对实例推理进行详细描述,根据相关推理规则与推理要求,同时结合实际情况,由系统程序员来合理构建规则。最后,在数字图书馆信息资源中,对用户所需的有关文献资源进行搜索,不过因为存在多种不同类型的领域本体,所以应根据各种类型的领域本的开发层次,对领域本体进行有效建立。其中,选用的本体建立方法为[1-3]:
第一,选用单本体方法,表明共享词汇集是由全局本体所提供的,全局本体一定要与全部的信息源产生联系,确保语义的一致性。针对某一特定领域,当需要对其进行映射时,可以选用单本体方法,不过存在一个前提条件,即信息源变化不会影响单本体。其中,单本体结构,如图1所示。
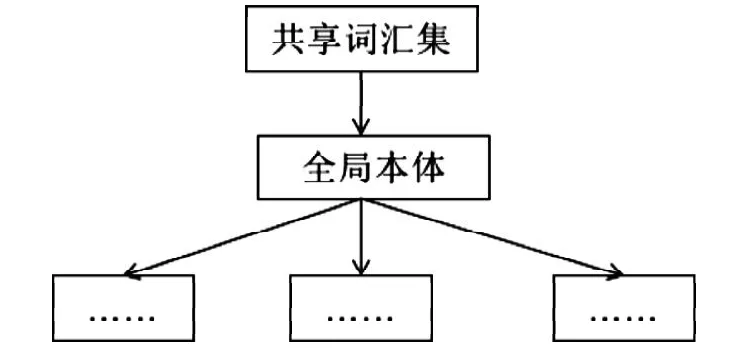
图1 单本体结构Fig.1 Single body structure
第二,选用多本体方法,对各种信息源进行详细描述,同时保证全部的本体均具有自己的词汇集。当信息源发生变化时,并不会较多影响本体结构,本体结构仅会发生较小程度的改动,这也是多本体方法的一大重要优势。其中,多本体结构,如图2所示。
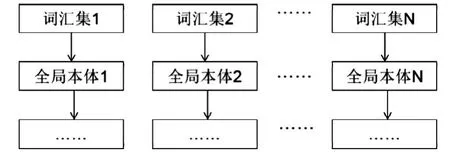
图2 多本体结构Fig.2 Multi-ontology structure
针对以上两组方法,应根据领域本体的实际需求,选取相应合理、可行的分类方法,能够在数字图书馆信息资源中,将用户所需的文献资料精准搜索出来。
2 用户查询信息的有效处理
在完成数字图书馆信息领域本体的建立以后,接下来需要对用户查询信息进行有效处理,选用统一模式,对文本形式进行详细解析,然后在文档数据库中将其储存起来。根据数字化文档元数的规范定义,在遵守MARL标准的原则下,将文档数据库中的文档信息提取出来。为能够共享数据信息,选用XML,在元数据库中储存提取出来的元数据组织[4]。其中,文档元数据提取流程示意图,如图3所示。
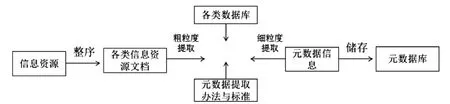
图3 文档元数据提取流程示意图Fig.3 Schematic diagram of document metadata extraction process
根据MARL 元数据提取的标准,对不同类型的数据库信息进行提取与细化,最后提取文档信息元数据。不过,针对XML,由于它没有语义描述功能,因此需要建立相应合理的概念模型。
当以上工作全部完成以后,通过运用一些工具来对程序进行有效简化,包括主题词、语义字典等,有助于元数据建立工作量的减少。
3 数字图书馆信息的有效检索
在将用户查询信息处理工作完成以后,需要对数字图书馆信息检索模型进行建立,具体操作流程为[5-7]:
第一步,选用智能算法,对上下文单词进行有效处理,对候选术语的长度、候选术语的出现频率、候选术语的出现次数总和进行计算,其中,计算公式为:
C-Value={log2|a|*f(a)} (1)
在公式(1)中:智能算法用C-Value来进行表示;字符串长度用log进行表示;候选字符串用a进行表示;出现频率用f进行表示。
在利用智能算法对术语进行抽取过程中,需要先对C-Value值进行计算,然后对词性过滤规则进行建立,最后对与词性过滤规则相符合的术语进行搜索。
第二步:当获取候选术语列表之后,应对可接受的精度进行有效计算,利用智能算法NC-Value,对上下文加权因子的权重进行有效计算,其中,计算公式为:
Weight(w)=t(w)/n (2)
在公式(2)中:上下文中的词汇用w进行表示;全部术语总数用n进行表示;术语数目用t(w)进行表示;上下文加权因子用weight(w)进行表示。
第三步:对数字图书馆信息检索模型层次架构进行有效建立,具体内容,如表1所示。

表1 数字图书馆信息检索模型层次架构Tab.1 Hierarchical structure of information retrieval model of digital library
其中,第一层,应用层,就是指入口集合,利用了人工智能服务技术,便于用户在不同功能界面中得到自己所需的信息;第二,服务层,这是数字图书馆信息检索模型的关键部分,主要功能就是向用户提供个性化服务,如个性化信息推送服务、智能信息检索服务等;第三,支持层,这是数字图书馆信息检索平台的引擎部分,能够对信息进行储存、分类、检索、采集等;第四,资源层,在数字图书馆数据库中,资源层是重要支撑。
基于大数据分析技术的数字图书馆信息检索模型,如图4所示。
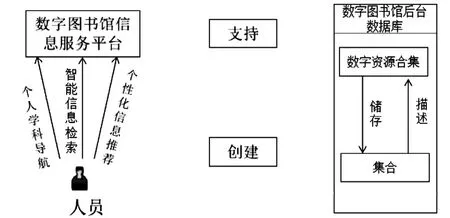
图4 基于大数据分析技术的数字图书馆信息检索模型Fig.4 Digital library information retrieval model based on big data analysis technology
基于大数据分析技术的数字图书馆信息检索模型的基本工作原理为:第一,利用概念检索技术,在领域专家的指导下,对领域本体进行建立;第二,根据MARL元数据标准,通过选用大数据分析技术,对信息源中的数据进行收集,同时构建元数据库;第三,将用户查询请求提交到检索界面,对检索需求进行有效处理;第四,对领域本体的语义相似度进行有效排序,相似度大的排在前面,排序结束以后,向用户进行提交。
4 仿真结果与分析
针对本文设计的基于大数据分析技术的数字图书馆信息检索模型,为对其的可行性进行有效验证,选取与SaaS领域有关的500篇文本做为前景语料,包括文化领域、新闻领域等。本次分别选用建立的模型与传统检索模型来进行检测,检测获取的检索匹配结果能否获取效果十分好的平均权重、召回率、准确率[8-9]。以确保本次实验具有足够的说明性,其中,传统检索模型的检测结果,如表2所示,新建检索模型的检测结果,如表3所示。通过对表2、表3 进行深入分析后发现,与传统检索模型相比,通过利用新建检索模型来进行检索,能够获取效果更好的平均权重、召回率、准确率。究其原因,即:第一,与检索角度有关系,通过利用新建模型进行检索时,需要先对全部检索词进行语义化处理,对所有数字图书馆信息的有关索引进行计算;第二,与查询SaaS领域有关系,能够获取较高准确率的抽取检索结果[10]。
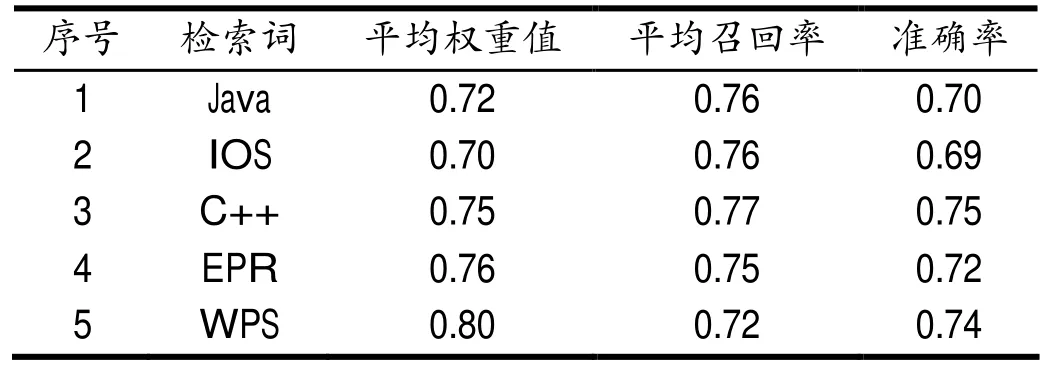
表2 传统检索模型的检测结果Tab.2 Detection results of traditional retrieval models
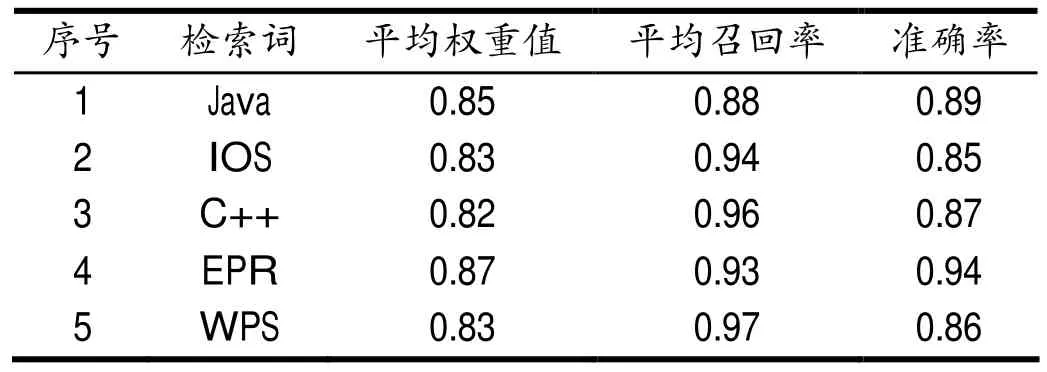
表3 新建模型的检测结果Tab.3 Test results of the newly created model
5 结语
综上所述,为有效解决传统数字图书馆信息检索模型中存在的问题,本文设计了一种新的模型,即基于大数据分析技术的数字图书馆信息检索模型。在数字图书馆信息检索模型中,通过运用大数据分析技术,能够构建共享平台,与传统检索模型相比,大数据分析技术具有非常多的使用价值与使用功能,能够实现智能信息检索与个性化推荐。本文对基于大数据分析技术的数字图书馆信息检索模型设计进行了详细分析与阐述,希望能够对相关工作人员起到一定的借鉴作用[11]。
猜你喜欢
哲学分析(2023年4期)2023-12-21
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
中国音乐学(2020年4期)2020-12-25
信息安全研究(2016年4期)2016-12-01
新闻传播(2016年18期)2016-07-19
现代计算机(2016年11期)2016-02-28
文学教育(2016年27期)2016-02-28
河南科技(2014年11期)2014-02-27
