
基于卷积神经网络多特征融合的复杂背景字符识别
2021-06-28 19:10陈太阳
电脑知识与技术 2021年10期
陈太阳


摘要:近年来,计算机视觉领域的一个研究热点就是基于深度学习的文字识别。通过在深度网络中融合对字符图像采用K均值和PCA提取的特征信息,本文提出一种基于卷积神经网络多特征融合的复杂背景字符识别方法。该方法对测试集进行分组实验,实验结果表明该方法对复杂背景字符识别有较高的正确率。
关键词:卷积神经网络;多特征融合;复杂背景;字符识别
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2021)10-0192-02
Abstract: In recent years, the text recognition based on deep learning is one of the hot spots in the field of computer vision. The paper propose a complex background character recognition method based on convolutional neural network and multi-feature fusion by fuzing the character images feature information which extracted by the ways from K-means and PCA in deep network. This method picks brigade laboratory for test dataset, the results proved that this method has a higher recognition accuracy for complex background character.
Key words: Convolutional neural network; Multi-feature fusion; Complex background; Text recognition
1 引言
文字識别作为计算机视觉领域的热门研究课题之一[1],在人们的日常学习生活中具有重要的意义。传统的光学字符识别通常适用于具有特定格式的扫描文档[2],传统的光学字符难以对复杂背景字符有很好的识别效果。
随着深度学习的发展,卷积神经网络[3]在计算机视觉领域取得了很大的成功,但是目前的工作对复杂背景字符的识别研究还比较少。本文针对复杂背景字符识别问题,提出了一种多特征融合卷积网络模型(MFF)。该网络模型有三个输入通道来分别提取复杂背景字符的原图、K均值[4]及PCA[5]的特征信息,并将获取的相应特征进行融合,然后再将融合得到的特征放入后续网络[6]进行训练。本文用该方法来提高识别复杂背景字符的精度。
2 MFF网络模型
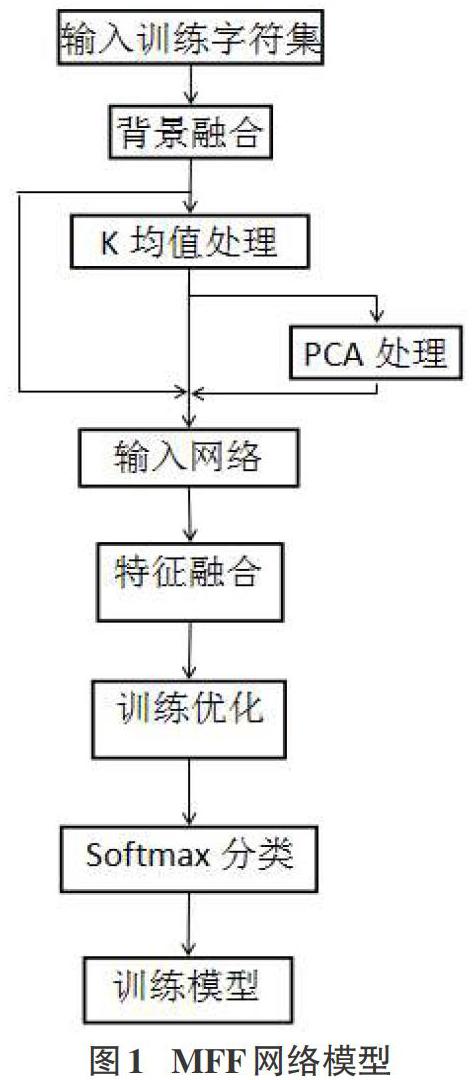
MFF网络模型的构建主要分为数据预处理模块、特征提取与融合模块、优化模块。数据预处理模块是为了提供足够的复杂背景字符图像来训练网络。特征提取和融合模块是MFF网络的核心部分,该部分将复杂背景字符的三个特征提取整合。优化模块是为了提高复杂背景字符的识别率。本文MFF网络模型的构建分为以下六个步骤,具体流程如图1所示。
1)输入训练字符进行复杂背景融合;
2)得到复杂背景字符图片后用K均值算法和PCA算法进行图片处理;
3)将相应图片集输入到网络中;
4)将获取的特征进行融合;
5)对得到的融合特征进行训练优化;
6)Softmax分类得出训练结果。
2.1 数据预处理模块
为了提高MFF网络的识别准确率,本文采用数据增广[7]的方式来支撑网络的训练。先对训练字符用不同复杂场景的图片进行背景融合,再对得到的图片用K均值算法进行处理,最后再用PCA算法对K均值算法得到的图片进行处理得到三类图片,确保网络有足够的数据进行训练。
2.2特征提取与融合模块
通过数据预处理模块处理后得到三类复杂背景字符图像,本文就要对其进行特征提取。通过K均值算法处理后,我们把复杂背景图像进行聚类,这样就能把复杂背景的干扰降低,凸显原本字符的特征。再对K均值算法得到的图片进行PCA处理,通过降维得到更便于理解的特征。将三类图片一起输入到网络中进行卷积池化提取特征,再将这三种特征进行融合。因为经过K均值算法和PCA算法处理后的特征是正向有利于识别的特征,所以融合后的特征比单独放入原图的特征更有利于网络的训练。得到融合后的特征,再进一步用卷积网络进行特征提取与处理,得到网络的输出。MFF网络Flatten层前的实现参数细节在表1中,按照网络层级顺序列出。其中原图,k均值和PCA输入通道用下标r,k和p标记.TF.concat[8]层对三个输入通道得到的特征进行融合,之后经过三次卷积一次池化的操作输入Flatten层。再将得到的结果输入全连结层进行优化处理。
2.3 优化模块
通过特征提取与融合模块得到了特征图后就可以将其输入到dropout层,该层可有效地避免过拟合的发生,达到正则化的效果。随机梯度下降法[9]可以加速收敛时的速度,减少计算梯度时候的冗余。最后就可以通过Softmax分类获得MFF网络的输出。
3 实验结果与分析
通过2.1数据预处理模块,本文在自定义数据37800张复杂背景字符图片下进行实验,测试数据与训练数据的比例为2:8。本文提出的方法对测试集进行三次分组实验对比分析,每组实验取五次测试集准确率的平均值。通过表2得出的测试结果可以看出,本文提出的MFF网络模型在复杂背景字符识别上可以通过提取不同的特征进行融合的方式来得到较好的识别效果。
4 结论
对复杂背景字符的识别对生活有实际的意义。文字识别作为计算机领域的研究热点,目前对复杂背景字符识别的关注度比较低。本文基于复杂背景字符的特征提出了一种针对字符的多特征融合卷积网络模型(MFF),这为复杂背景字符识别问题提供了一种解决思路。通过多次实验对比结果表明,MFF网络模型能够在复杂背景字符识别上取得较好的效果。
参考文献:
[1]王德清,吾守尔·斯拉木,许苗苗.场景文字识别技术研究综述[J].计算机工程与应用,2020,56(18):1-15.
[2] 郝亚男,乔钢柱,谭瑛.面向OCR文本识别词错误自动校对方法研究[J].计算机仿真,2020,9(37):333-337.
[3] 周飞燕,金林鹏,董军.卷积神经网络综述[J].计算机学报,2017,40(6):1229-1252.
[4] 焦志成,李洁,王颖,等.浅层模糊K均值图像分类网络[J].计算机科学与探索,2015,9(08):1018-1024.
[5] 安俊峰,刘海冬,潘雷,等.基于PCA和灰度直方图特征融合的交通标志的分类研究[J].公路,2018,4(4):178-185.
[6] Krizhevsky A,Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017,60(6):84-90.
[7] 汪权彬,谭营.基于数据增广和复制的中文语法错误纠正方法[J].智能系统学报,2020,1(15):99-106.
[8] SZEGED C,VANHOUCKE V,IOFFE S,et al。Rethinking the inception architecture for computer vision[C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,2016,2818-2826.
[9] 王功鵬,段萌,牛常勇.基于卷积神经网络的随机梯度下降法[J].计算机工程与设计,2018,39(2):441-463.
【通联编辑:唐一东】
猜你喜欢
成都信息工程大学学报(2017年3期)2017-11-09
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
河南科技(2014年3期)2014-02-27
