
领域科研项目评审专家推荐算法
2021-06-28 11:38:58张仰森周炜翔黄改娟
计算机工程与设计 2021年6期
张 雯,张仰森,周炜翔,黄改娟
(北京信息科技大学 智能信息处理研究所,北京 100101)
0 引 言
2018年4月20日至21日,习近平主席在全国网络安全和信息化工作会议上发表讲话,强调“没有网络安全就没有国家安全”。网络与信息安全已经上升为国家战略,为促进网络与信息安全领域蓬勃发展,需要大力开展网络与信息安全领域科研项目的开发工作。在科研项目立项阶段,存在一个关键步骤——评审专家推荐。评审专家推荐即根据科研项目申请文档,确定项目研究领域,同时推荐相关领域的专家进行项目评审,以评估项目的实际意义及可行性。
目前,针对科研项目的评审专家遴选任务,大多数政府机构、科技部门、互联网企业仍然停留在人工选拔专家的阶段。这种人工遴选专家的方式具有很大的弊端。例如,各个机构的科研项目立项活动往往集中在同一时期进行,需要进行选拔的专家数量较多,同时需要考虑每个项目的专家分配情况,造成大量的人力资源消耗也会出现分配不合理的现象。在进行人工遴选评审专家的过程中,首先需要选拔专家的人员对待评审的科研项目进行研究方向的确定,依据确定的研究方向着手进行评审专家的遴选工作。但人的知识认知范围是有限的,科研项目文档中往往涉及多个研究方向,单纯的依靠人工进行所有科研项目的分析,无法保证遴选人员对科研项目所涉及领域具有正确的判断,因而将导致所邀请的评审专家研究领域与待评审的科研项目研究领域不匹配的问题。这在一定程度上会对项目评审结果造成不良影响。因此,为提升科研项目的评审质量,针对领域科研项目评审专家的推荐具有重要的研究意义。
1 相关工作
评审专家推荐系统以满足用户对专家这一特定实体的推荐需求为目的,是推荐技术的一种实例化形式。近年来使用频率较多的个性化推荐算法主要包括协同过滤的推荐算法[1-3]、基于图结构的推荐算法[4-7]和基于社交网络的推荐算法[8-11]。文献[12]参考用户项目矩阵中的评分资料进行用户与项目之间的相似度[12]。文献[13]基于申报项目论文及知识库论文,设计了一种通过计算文本余弦相似度来推荐评审专家的方法,解决了人工遴选评审专家中效率较低、主观选择专家等问题[13]。但是该推荐算法仅采用余弦相似度进行基于内容的相似度计算,未能充分考虑文本中的语义信息。文献[14]利用科技文献之间存在的引用及被引用关系,提出了一种学术平台相关学者以及相关论文推荐方法,并构建了基于Word2vec的学者与跨语言论文推荐模型[14]。文献[15]通过构建领域知识图谱、关键词特征向量抽取、领域节点向量的加权映射以及匹配相似度计算实现学位论文最为匹配的评审专家推荐[15]。文献[16]针对已有协同过滤推荐算法可解释性不高和基于内容推荐算法信息提取困难、推荐效率低等问题,提出了一种融合知识图谱和协同过滤的高效推荐模型[16]。
目前,推荐算法主要应用于电商、新闻、科技论文评审等领域,针对领域科研项目评审专家的推荐算法的研究较少。领域科研项目评审专家推荐与传统的推荐问题有很大的不同,原因在于:专家存在较为复杂的社会关系,在进行项目评审中,往往会存在一些感情因素。因此,在专家过程中不仅需要考虑专家的研究领域、学术水平是否与待评审项目相吻合,保证项目评审的科学性。同时,还要充分考虑专家的社会关系,避免与项目申请者存在关系强度较大的专家进入推荐专家评审组,进而保证项目评审的公正性。
综上所述,设计了一种基于领域标签体系的专家推荐算法。首先,依据高校主页专家个人信息,确定待分析领域专家集合。基于待分析专家集合,采集专家论文数据并进行分析,构建专家库;然后,利用领域论文数据,训练专业实体识别模型BiLSTM-CRF,为领域标签体系的构建提供帮助,采用关键词抽取及专业实体识别模型相结合的方式,实现项目申请文档的标签标注;最后,依据项目申请文档标签及专家标签标注模型,生成推荐专家候选集,同时基于专家库数据,进行专家关联关系分析,构建专家社会关系网络,实现专家回避,结合领域吻合度及领域权威度进行排序,完成最终的领域科研项目评审专家推荐。
2 专家库的构建
2.1 数据采集
本文采用Webmagic爬虫框架进行数据采集,采集的数据分为两类:专家基础数据、专家领域数据。专家基础数据的采集主要包括专家姓名、工作单位、性别、联系方式等;专家领域数据主要是针对专家论文数据的采集,基于论文数据,进行数据分析,获取研究领域、领域权威度等专家领域信息。
专家基础数据的数据源包括:高校主页、百度百科、百度学者库。分析不同数据源的网站页面结构,制定全面准确的分辨和解析策略,针对不同网站的特点设计对应的解决方案,如部分网站需要使用代码伪造登录口令进而获取cookie信息。在爬虫策略上,采用IP代理池并引入异常处理机制,以防止由未知错误引起的爬虫程序的中断。
专家领域数据的数据源包括:万方论文数据、知网博硕论文数据库、维普数据库。由于异质网络数据会存在数据重复的情况,进而导致计算资源负载不均衡。因此在专家论文数据采集方面,采用3个数据源爬虫同时采集,协同运作的方式,在提高采集效率的同时,避免了各个数据源之间数据不均衡的情况,更好地保证了数据的全面性及计算资源的合理利用。论文数据采集方法具体如下:
(1)从待爬取论文集合中取出论文a;
(2)查看论文a的可用数据源集合s;
(3)逐一查看集合s中各数据源当前的待爬取队列大小l;
(4)选择待下载队列最小的数据源,将论文a添加到该数据源的待下载队列末尾。
2.2 数据处理
专家数据中存在同名专家问题,为保证专家库中专家数据的准确性,需要对专家数据进行进一步的处理,对同名专家的属性数据进行数据消歧。我们充分利用同名专家的属性特征,通过对多种属性特征的综合考虑进行组合,从多侧面匹配的角度计算同名专家的相似度,弥补单一特征的不足之处,提高专家数据的准确性。
首先,构建3个消歧特征类。基本信息特征类(姓名、性别、邮箱、电话)、社会关系特征类(单位、毕业院校)、领域特征类(研究方向、论文信息等);然后,进行相似度计算。在每类消歧特征类中,采用编辑距离计算各个属性特征的相似度,并实行属性特征相似度的动态加权计算及归一化处理;最后,实现线性加权。根据每类消歧能力强弱赋予不同的权值,对每类相似度计算结果进行线性加权计算,得到最终相似度。与实验所得最优效果阈值进行比对,确定消歧专家,实现专家数据融合。
3 基于领域标签体系的推荐算法
3.1 领域标签体系的构建
当前信息安全领域没有成型的标签体系及技术名词命名规范,项目申请文档中存在专业名词命名不一致的现象,且项目申请文档的撰写角度无法固定,很多机构的文档撰写偏向于应用领域的角度,而专家的论文数据偏向于科研角度,这就导致了在进行专家推荐时直接使用项目申请文档的标签与专家标签进行匹配时,相似度计算困难。为解决这一问题,我们参考了目前国内较成熟的国家自然科学基金标签体系,同时采用《计算机科学技术百科全书》第三版对国家自然科学基金标签体系进行层级结构的调整,标签名词的扩充、归一与融合,结合了应用领域及科学研究两个角度,构建了一套面向网络与信息安全领域的标签体系,为项目申请文档的标签标注及专家标签标注模型提供对标功能。除此之外,专业领域标签往往具有独特的上下文语境,而经过关键词提取后的标签长度较短,不具有较多的语义信息。因此仅仅依靠字词级特征进行相似度计算的效果较差。

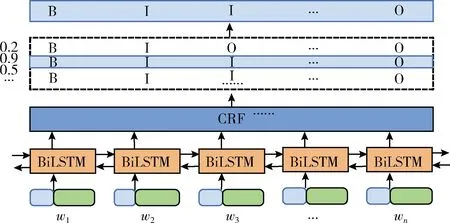
图1 专业领域名词识别模型
由于专家的标签标注主要依据专家论文,在后续推荐过程中,需要将专家标签与项目指南文档标签进行匹配,因此,本文基于论文数据及项目申请指南文档,进行专业领域名词识别模型的训练,确定标签词语概念粒度及层次结构。根据实验结果,参考国家自然科学基金体系,保留体系中“计算机科学”、“人工智能”、“自动化”、“信息与电子学系统”4个领域的一级、二级结构,同时依据《计算机科学技术百科全书》对三、四级标签名词进行补充及融合。最终本文的领域标签体系采用四级树状层级结构,标签总数为1780个。
3.2 项目申请文档标签标注算法
不同的科研机构设有不同的项目申请文档规范,文档的部分模块,如相关工作、相关调研等部分也会存在一些技术名词,但这些名词往往不是本篇文档所真正关注的技术领域。因此,本文根据特定的项目申请文档模板,进行分析区域的划分。结合领域标签体系,从字词和语义两个角度出发,提出了一种基于TextRank与BiLSTM-CRF相结合的项目申请文档标签标注算法,并采用词向量与词频相结合的方法实现标签体系标签词与识别出的专业领域名词的相似度计算任务,词频的加入可以降低区分能力较弱词语的权重。在此基础上,引入投票机制,从字词和语义两个层面分别选择不同的影响因子进行线性加权,最终确定标签名词的权重排序,获取自动标注的标签结果。具体算法描述如下:
算法1:项目申请文档标签标注算法
输入:项目申请文档A
输出:标签列表labelb
过程:
步骤1 专业领域名词识别:采用直接定位、Text-Rank、BiLSTM-CRF这3种方法进行识别,得到3个专业领域名词列表Entity;
步骤2 专业领域名词Entity与标签词相似度计算:采用词向量及词频相结合实现专业领域关键词与标签体系标签词的相似度计算,计算公式如式(3)所示,分别得到3种途径识别名词所确定的最终标签词列表labela
(1)
(2)
(3)

步骤3 投票机制:引入投票机制,将3种途径获取到的最终标签词进行投票,将最终的投票分数进行归一化处理;
步骤4 线性加权:选择投票计算结果、向量相似度计算结果、标签词词频计算结果为影响因子进行线性加权,计算公式如式(4)所示,按照最终标签的权重排序结果,得到标签列表labelb
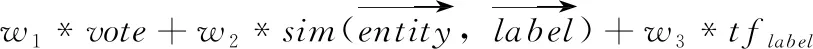
(4)
式中:score(label)表示标签分数,w1、w2、w3表示不同影响因子对应的权重,tflabel表示标签词label的词频。
3.3 基于三元组的专家标签标注方法
从实际应用背景出发,专家研究领域固定但研究方向可以包括很多,在每一研究方向的研究程度往往不一样,引入领域吻合度作为标注特征,用以表征专家在其各自研究方向的研究深度;除此之外,单纯地考虑专家的研究方向并不能较好保证评审质量,同时当一批专家均符合评审条件而评审专家数目却有限制时,往往需要进行择优推荐,引入领域权威度作为标注特征,描述专家在相关领域的影响力度。综上,领域吻合度为专家标签标注提供自身的纵向比较,领域权威度为专家推荐提供领域的横向比较。因此,本文选择专家领域吻合度及领域权威度两个特征作为择优推荐的参考指标,提出了专家领域吻合度计算模型,公式如式(5)所示,制定了专家领域权威度的评价指标,评价指标见表1。采用(专家标签、领域权威度、领域吻合度)三元组的形式进行专家标签表征。具体标注方法如下:

表1 领域权威度评价指标
(1)领域标签抽取:结合领域标签体系,从专家的论文数据中提取专家的领域标签;
(2)吻合度计算:依据标签在专家相关资料中出现的频次、论文的影响因子、论文引用数、专家发表的总文献数,进行吻合度计算
(5)
式中:scorei表示标签i的领域吻合度,wj表示论文j的影响因子,nij表示标签i在论文出现次数,tj表示论文j的引用数,N表示专家发表的总文献数。将每篇文献的各个特征值相乘,并进行求和,获得的平均值作为该研究领域的吻合度,为保证分母不为0,故对总文献数加1。
(3)权威度计算:依据领域权威度的评价指标,进行线性加权计算。
3.4 专家推荐算法
专家推荐过程中,不仅需要保证专家研究领域与申请项目的领域相匹配,还需要考虑专家的专业水平,以保证评审质量。依据实际评审需求,本文选取专家领域吻合度及领域权威度进行专家表征,以领域标签体系为标准,统一专家标签及项目申请文档标签提取的概念粒度及命名规范,构建了基于领域标签体系的专家推荐算算法。具体的算法过程描述如算法2所示:
算法2:基于领域标签体系的专家推荐算法
输入:项目申请文档A
输出:推荐专家名单Expertc
过程:
步骤1 分析项目申请文档A结构特点,确定进行分析的文本范围,进行项目申请文档的标签标注,得到项目申请文档的标签列表La;
步骤2 依据专家文献数据进行专家标签标注、专家领域吻合度、专家领域权威度的表征,得到专家表征三元组Triple(专家标签、领域吻合度、领域权威度);
步骤3 将步骤1所得项目申请文档的标签列表La与步骤2所得的三元组中的专家标签进行匹配,构建备选领域专家集合Experta;
步骤4 基于专家社会关系网络,构建专家回避模型,得到回避专家列表Lb,将步骤3中所得的备选领域专家集合Experta进行过滤,此时得到备选专家集合Expertb;
步骤5 结合专家表征三元组Triple(专家标签、领域吻合度、领域权威度),对步骤4得到的备选专家集合Expertb进行线性加权,将加权结果进行排序,根据项目需求,选取排序结果TopN的专家作为最终推荐专家列表Expertc。
3.5 专家回避算法
为保证项目评审的公平性,需要进行评审专家与项目申请人之间的回避问题。考虑专家实际生活场景及成长背景,对专家社会关系进行关联关系分析,抽取专家的社会关系,本文中所选取的社会关系分为直接关系与间接关系,直接关系包括:合作关系、同事关系、同学关系、师生关系、控股关系,间接关系由以上5种直接关系间接引起的二阶或多阶关系。将关系作为边,专家作为节点,构建专家社会关系网络,这类属性主要采用规则推理的方法进行提取,同时基于专家社会关系网络设计回避算法,具体算法描述如下:
算法3:基于领域标签体系的专家推荐算法
输入:项目申请人名单Avoida,推荐专家名单Experta
输出:回避专家名单Avoida
过程:
步骤1 依据构建的专家库数据,采用规则推理的方法进行专家关联关系分析,构建专家社会关系网络,具体规则见表2;

表2 社会关系规则
步骤2 基于专家社会关系网络,查询推荐专家名单Experta及项目申请人名单Applicanta每两者之间的全部关系路径,并进行两者间关系强度的计算,计算模型如图2所示,计算公式如式(6)所示;
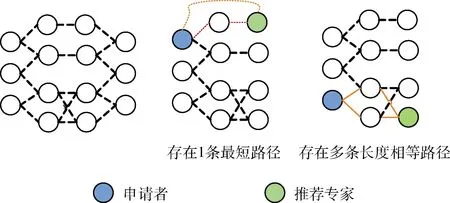
图2 回避模型
(6)
式中:Q(A,B)表示专家A与申请人B之间的关系强度,W表示关系权重,dec表示衰减比重。本文引入衰减比的概念,在专家社会网络中,连接两者的边数越多,其关系衰减避重越大。将关系强度的计算分为两种情况:当A与B之间存在1条最短路径时,直接进行权重与衰减比的乘积,结果作为两者之间的关系强度;当A与B之间存在多条长度相等路径时,对每条路径的权重与衰减比相乘后求和,结果作为两者之间的关系强度;
步骤3 选取关系强度计算结果中的最大值,进行回避阈值判断,实现专家回避,得到最终的回避专家名单Avoida。
4 实验及结果分析
4.1 数据集
本实验中所用的数据集为爬虫所得的网络与信息安全感领域的论文摘要,将数据集按照9∶1的比例分成训练集、验证集,项目申请文档作为测试集,语料规模见表3。

表3 数据集介绍
4.2 专业领域名词识别模型实验及结果分析
专业领域名词识别结果影响着领域标签体系构建的效果及项目申请文档的标签标注结果。针对模型设计,本文设计了两组对照实验。
实验1:基于Word2vec实现向量映射,将映射后的向量矩阵作为BiLSTM层的输入,经过降维后,选取BiLSTM层输出的分数最高的标签作为标签预测结果。该模型准确率达67.86%。
实验2:在实验1的基础上,添加CRF层。CRF层可以为自动学习一些约束条件,进而为预测标签的合法性提供保证,如通过引入CRF层可以学习到句子中的第一个词应该是以标签“B”或“O”开始;同时CRF中存在转移特征,它可以考虑输出标签之间的顺序性,以此来进行一些约束规则的学习。BiLSTM-CRF模型的准确率达77.96%。
4.3 项目申请文档的标签标注算法实验及结果分析
项目申请文档的标签标注是实现专家推荐的关键步骤,其标注准确率直接影响着推荐专家的结果。在进行项目申请文档标签标注算法的设计过程中,主要设置以下3组对照实验,实验结果见表4。

表4 项目申请文档标签标注实验结果对比
实验1:依据领域技术标签体系,采用直接定位、Text-Rank关键词及关键短语提取两种方法进行专业领域名词的识别,其中关键词及关键短语的提取借助Hanlp开源工具,利用Word2vec词嵌入向量计算识别出的领域标签词与标签体系词之间的相似度,进行阈值判断,确定项目申请文档的标签标注结果。
实验2:在实验1基础之上,专业领域名词识别过程不变,在经过词向量映射进行相似度计算过程中时,由于一个标签词的词嵌入向量由构成这个标签词的所有字向量拼接而成,标签词中的每个字的区分能力强弱不同,如“计算机木马”、“计算机通信协议”两个标签代表领域相差甚大,但由于词中均具有“计算机”这一子串,将会对相似度计算结果产生影响。因此,在进行相似度计算时引入字频特征,将字频取倒数后作为当前字的向量权重,之后进行向量拼接,以此降低标签体系中区分能力较弱的字在标签词中所占的权重。
实验3:针对专业领域名词识别过程,实验1和实验2仅考虑了字词特征,但是一篇项目申请文档中往往蕴含着大量的语义信息,同时专业领域名词的上下文语境较为独特,因此,本文在实验3中考虑了语义特征,引入在领域标签体系构建过程中训练好的BiLSTM-CRF专业名词识别模型,采用直接定位、关键词提取、BiLSTM-CRF模型3种方式进行专业领域名词的识别,有效地结合了字词及语义两个层面的特征。相似度计算与实验2保持一致,采用词向量与字频相结合的方式进行计算。同时,在结果统计策略上,我们引入了投票机制及线性加权,将3种途径获取到的最终标签词进行投票,选择投票计算结果、向量相似度计算结果、标签词词频计算结果为影响因子进行线性加权,获得最终标签标注的权重排序结果。
为保证实验结果的准确性,邀请了多位机构工作人员针对项目申请文档进行背对背标签标注,项目申请文档数为50篇,每篇文档标签标注数目为3个,综合多位工作人员标注结果确定最终的准确标签集合作为实验结果正确数据集,计算3种实验的标注准确率,同时,我们在整理人工标签标注结果时注意到人工标注的准确率仅达68%,算法的最终准确率达83.33%,远远超过人工标注效果。实验结果见表4。
4.4 基于领域标签体系的推荐算法的实验结果分析
随着网络技术的发展,将人类带入了大数据时代,利用网络数据资源实现各种形式的推荐已经成为学术界和商业界的研究热门。相比于其它推荐算法,本文所设计的算法在以下4个方面具有先进性及创新性。
(1)数据量方面
从数据量角度讲,相较于大多数推荐系统通常都是在小规模数据集上搭建起来的,本文开发相应的爬虫工具,依托于集群资源,进行多节点并行处理爬取任务。专家数据量破万,论文数据量破百万,此外采集信息中还包括专利信息、专家个人信息等,为专家库构建工作提供了强大的数据支持。
(2)领域标签体系构建
领域标签体系的数目众多且较为复杂,信息检索、计量评价等科研活动中存在领域标签著录混乱、层级结构模糊等瓶颈问题。很多机构无成型的领域标签体系,机构内部相关技术无统一命名规范及明确定义。目前,针对领域标签方面的相关研究较少,国家自然科学基金体系是国内较为成熟的领域标签体系,具有一定的参考价值,但是由于其面向的领域较多,体系层级结构划分与项目申请文档中的技术概念粒度不契合等问题,往往需要对部分层级结构进行扩充与融合。
本文考虑到推荐算法过程中涉及到的专家标签标注的数据来源及项目申请文档的标签标注两个关键步骤,利用论文数据进行专业领域名词识别模型的训练,以此统一标签名词概念粒度及命名规范,极大提高了专家标签与项目申请文档标签之间的匹配准确率。
(3)专家标签标注
考虑到实际应用场景,系统中需要评价的对象是人,因此需保证其描述维度的全面性。本系统中专家属性达40种,从专家特定信息、专家基础属性信息、专家论文信息、专家专利信息、专家基金信息、专家培养学生信息6个维度出发描述专家,且每个维度特征不少于6个,进而保证了专家属性的全面性。基于以上信息,在进行专家标签标注过程中,制定了领域权威度评价指标,提出了领域吻合度计算模型,不仅实现了专家研究领域的表征,同时也对专家研究水平进行表征。
(4)专家推荐及回避
专家推荐问题有着自身独有的特点,专家是有情感的人,所推荐的专家在进行项目或论文评审中,会带有一定的感情因素。因此,不但要考虑专家的专业特长、学术水准是否与被评审项目相吻合,以保证项目评审的科学性,同时还要考虑专家的社会关系,避免那些与项目申请人存在各种社会关系的专家进入项目评审组,以保证项目评审的公正性。
本文提出了一种基于领域标签体系的专家推荐算法,通过匹配专家的技术标签筛选初步推荐专家名单,根据专家多维度属性信息构建专家权威度和领域吻合度算法实现专家的排序,最终结合专家社会关系网络进行回避路径的计算,经过滤后完成最终的专家推荐。不仅考量了专家的权威度信息和领域吻合度信息,还引入了专家社会关系回避信息,使推荐的结果更具有可行性。
5 结束语
本文在领域科研项目评审专家推荐方面提出了一套基于领域标签体系的推荐算法。首先,进行了数据采集及处理工作,构建专家库;然后,采用BiLSTM-CRF专业领域名词识别模型构建了一套领域标签体系,基于领域标签体系,设计了字词与语义特征相结合的项目申请文档标签标注方法,针对专家专业研究水平,提出了一种基于三元组的专家标签表征模型;最后,利用专家库数据,构建专家社会关系网络,充分考虑评审专家与项目申请人之间的社会关系,提出了基于社会关系网络的回避算法,并结合专家标签与项目申请文档标签的匹配结果,进行专家的推荐与回避。
在接下来的工作中,我们计划引入专家评价体系及专家用户画像。进一步完善专家推荐过程中,专家择优推荐模型的表征方法,期望进一步提高专家推荐效果,进而保证领域科研项目的评审质量。
猜你喜欢
计算机应用(2022年2期)2022-03-01 12:35:06
中国新闻周刊(2021年26期)2021-07-27 04:02:12
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
信息安全研究(2016年4期)2016-12-01 06:06:54
公民与法治(2016年10期)2016-05-17 04:12:58
宠物世界·猫迷(2016年3期)2016-04-23 19:54:06
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
少儿科学周刊·少年版(2015年3期)2015-07-07 21:10:04
计算机工程(2015年8期)2015-07-03 12:20:27
