
融合注意力机制的多阶段舌象分类算法
2021-06-28 12:41:48翟鹏博宋婷婷马龙祥黄向生
计算机工程与设计 2021年6期
翟鹏博,杨 浩,宋婷婷,余 亢,马龙祥,黄向生
(1.中国科学院微电子所 健康电子研发中心,北京 100029; 2.中国科学院大学 电子电气与通信工程学院,北京 100049; 3.中国科学院自动化研究所 军民融合中心,北京 100190)
0 引 言
传统中医舌诊往往依靠医生的个人经验,并且容易受到光照、温度等环境因素的影响。随着电子技术的发展,部分科研人员将图像处理技术应用到中医舌诊当中,试图来解决以上问题。
张艺凡等[1]利用舌象的RGB图,从中提取特征,然后借助支持向量机,成功实现了对于舌色和舌苔的分类。张静等[2]提取舌质和舌苔的颜色特征与纹理特征,借助多标记学习算法,对舌象进行分类。尚文文等[3]借助RGB和CLE Lab色彩空间之间的关系,提取相应的色彩离散特征,对舌象进行分类。由于以上算法大多采用手动设计的方法提取特征,提取的特征较为简单,无法深层次挖掘不同类别舌象的特征差异,不能很好表征舌体特性,因而分类的准确率有待提高。
近几年,随着深度卷积神经网络的飞速发展,计算机视觉领域也获得了巨大的进步[4]。Hou等[5]首先将卷积神经网络应用到舌象分类当中,实现了通过深度学习网络对舌象进行分类。胡继礼等[6]采用MobileNet[7]网络对舌象进行分类,提高了分类的精度,并且提高了分类速度。杨晶东等[8]采用Inception-V3[9]网络,借助迁移学习训练数据,减少了训练所需的样本,提高了训练速度。Huo等[10]提出了一种基于卷积神经网络的舌形识别方法,采用边界检测方法识别齿痕舌。但是由于以上算法大多直接将成熟完整的深度学习框架移植到舌诊领域,缺乏对于舌诊问题的针对性考虑,没有对网络框架做出改进,因而无论从速度上还是精度上都有待提高。
1 算法设计
1.1 整体方案设计
由于实际环境的限制,研究人员往往获得的是带有面部干扰信息的舌象图,这样在对舌象进行分类的时候,容易受到面部嘴唇、脸颊等部位的干扰。例如,由于嘴唇颜色偏红,干扰舌色的判断;脸颊的皱纹干扰裂纹舌的判断等等。另外,舌部也存在着一些杂质信息,对舌象的分类产生影响。例如,在判断舌象是否为齿痕舌时,舌中凸起部分也会产生干扰。无论是基于机器学习还是深度学习的算法,都很难消除这些干扰,进而造成产生误差。
针对以上问题,本文设计了一种融合注意力机制的多阶段舌象分类算法,本文算法流程如图1所示。在舌部定位阶段,通过采集不同感受视野的特征,融合不同特征信息,获得舌部区域。在舌象分类阶段,通过注意力机制模块,自适应学习权重,获得精准的舌象特征。然后利用卷积层和池化层进一步提取与对应标签相关的特征信息。最后通过全连接层,将得到的特征信息进行分类,得到最后的结果。
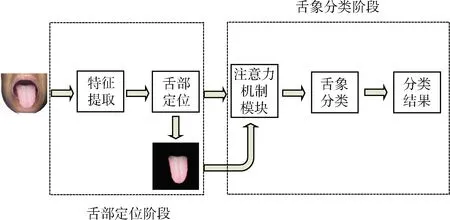
图1 整体方案
1.2 舌部定位阶段
因为人体舌部周围的嘴唇、下巴等位置颜色与舌体相近,并且不同患者的舌部颜色形状等差异较大,所以仅仅依靠简单的颜色、纹理、形状等特征并不能很好将舌体与背景区分,需要提取舌体复杂特征,对舌象整体建模。为此,本文采用了卷积神经网络进行特征提取。深度卷积网络通过模拟人类大脑的结构,根据训练数据借助卷积神经网络,自适应学习图像特征,并通过反向传播算法优化网络权重。深度卷积网络的出现打破了传统手动设计特征的局限性,使得提取的特征具有更强的表征能力,因而在很多问题上取得了进步。
本文设计的舌部定位阶段网络如图2所示。为提取舌部深层次的特征信息,增强算法对于不同患者舌体的鲁棒性,我们设计了两条路径采集舌象不同感受视野的特征信息。路径一采用ResNet[11]网络。ResNet网络采用残差结构,能够较好将浅层特征与深层特征融合,并且方便训练,容易收敛。本文采用从ResNet网络中输出的16倍下采样与32倍下采样大小的特征图,以获取较大的感受视野特征。路径二首先进行4倍快速下采样,然后采用膨胀卷积[12],保持一定感受视野的同时,又获得了较高的分辨率。最后将获得的两条路径的特征进行融合,这样最后的特征图就包含了舌象在不同感受视野下的特征信息,进而根据提取的特征,得到舌部的区域。
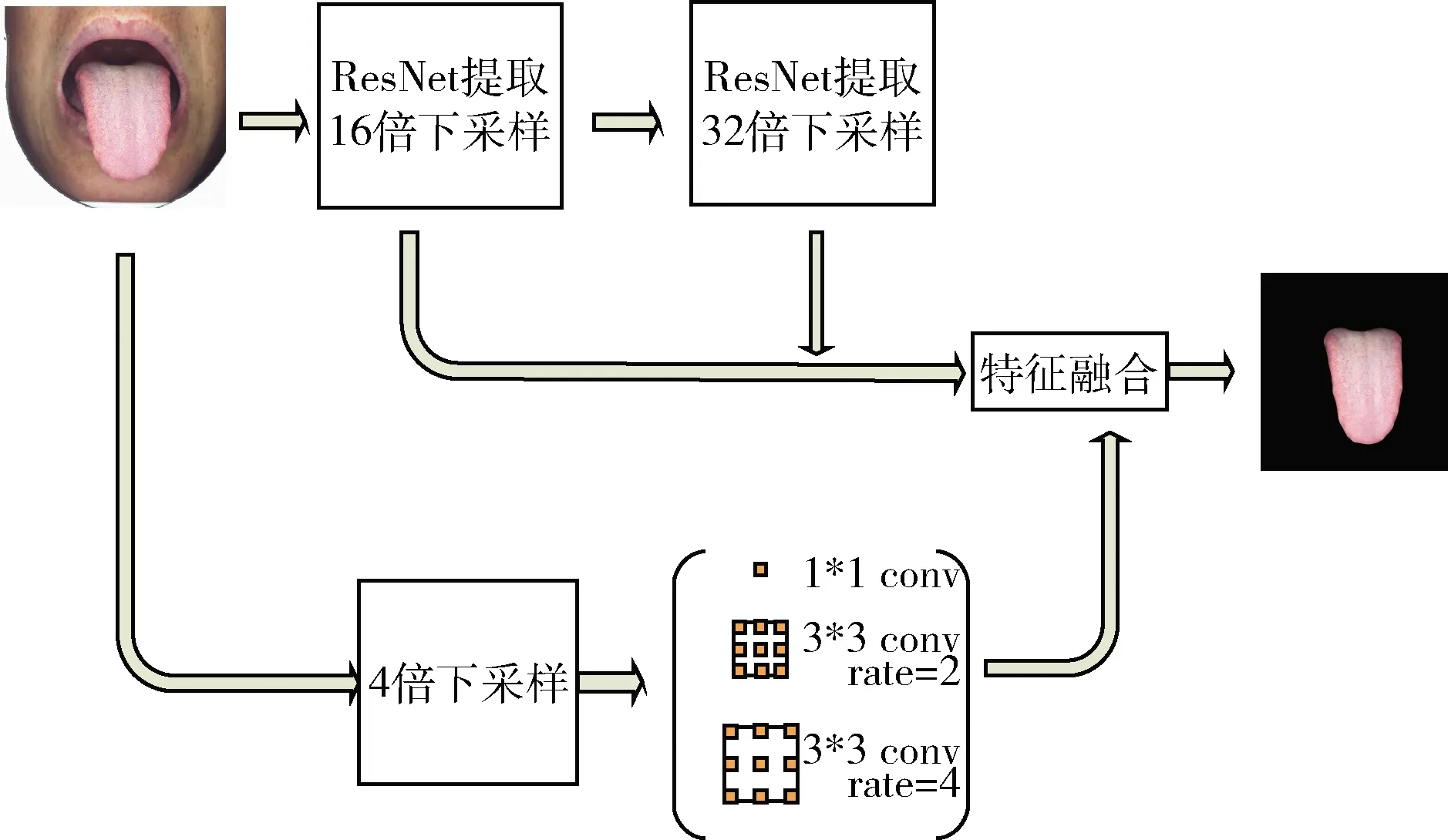
图2 舌部定位阶段
1.3 注意力机制模块
注意力机制模块是借鉴人类的视觉行为设计。人的眼睛每时每刻都会接收到大量的信息,人脑不会对这些信息逐一处理,而是通过视觉的注意力机制进行处理。人的视网膜的每一位置都有处理信息的能力,但是不同位置对于不同的特征敏锐度不同,其中视网膜中央地区的凹陷部分就有着最强的敏锐度。人的大脑在处理这些信息时,会有意地集中关注这些敏锐度更高的地方,而这些地方也恰恰包含着更多的视觉信息。因而人在对物体进行分类时,会抓住关键部位,给予显著特征更大的权重。例如,人类在区分啄木鸟与麻雀时,会更加关注嘴巴位置的特征;在区分黑熊和棕熊时,颜色特征会更加重要。深度卷积神经网络结构与大脑类似,同样面对海量的数据需要处理,因此同样需要注意力机制来过滤其中无效或者低效的特征信息,增强关键特征的显著性。本文设计的注意力机制分为通道注意力机制与位置注意力机制,具体结构如图3所示。

图3 注意力机制
1.3.1 通道注意力机制
在舌象分类任务中,不同类别舌象判定依据的特征不同。例如舌象舌色的判定取决于颜色特征;裂纹舌的判定取决于纹理特征。因而,提取的舌象特征依据判定任务的不同,重要性也不应相同。在卷积神经网络当中,特征图的每一个通道代表着一种特征。为了提取更精准的特征,抑制无关特征信息,本文设计了通道注意力机制,使得网络自适应学习每一个通道的特征权重。通道注意力机制表达式为
Oc=Ic*ac
(1)
式中:Ic代表输入特征图I的第c个通道,ac代表产生的第c个自适应权重,Oc代表经过通道注意力机制后输出的特征图。具体位置注意力机制权重产生的设计框架如图4所示。
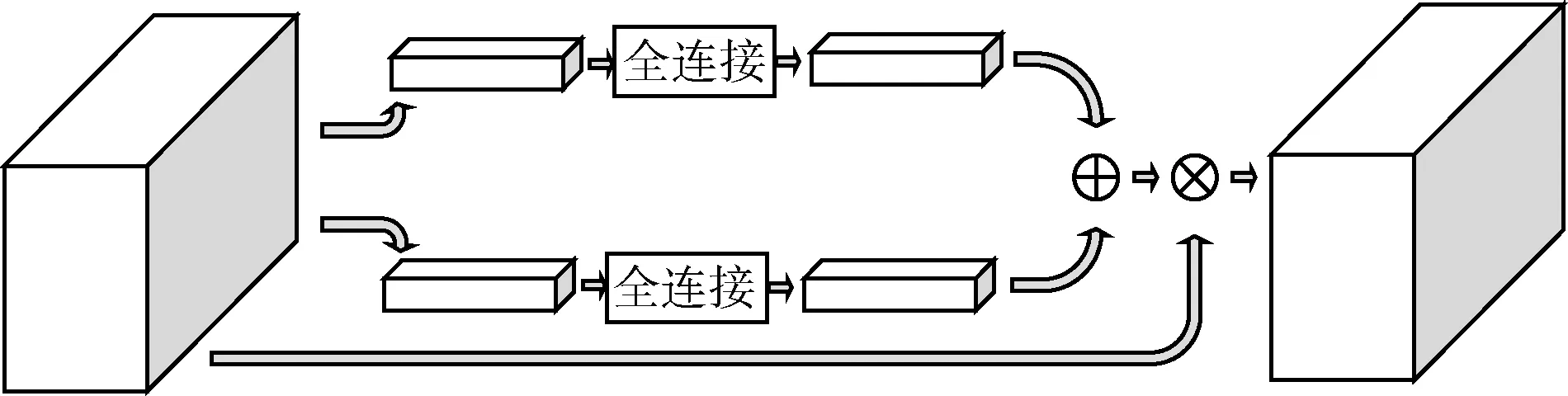
图4 通道注意力机制
为提取特征图每个通道的特征信息,更好的对不同种类的特征进行建模,我们首先对原始的特征图每一通道采用最大值池化和平均值池化。设原始特征图的维度为N×C×H×W,在通过最大值池化和平均值池化后变为N×C×1×1,这就是初始的通道注意力权重。但是初始的注意力权重仅仅代表了各自通道的特征信息,无法体现不同通道的重要性差异。为了更好地适应分类任务,使得网络可以自适应学习每一通道的权重,将初始权重通过全连接层进行细化,得到更加精细的权重。最后将初始的特征图与通道注意力权重相乘,为每一种特征分配权重。
由于通道注意力机制使用了最大值池化与均值池化这两种操作,所以模型的参数并不会增大很多,网络的计算开销也没有显著增大。通过通道注意力机制,使得对于舌象类别贡献度大的特征获得了更高的关注度,从而能够更好的针对不同的舌象类别,提取更加精准的特征。
1.3.2 位置注意力机制
在对舌象进行分类时,不同种类的舌象依据特征的位置也不相同。例如,在判断齿痕舌时,边缘位置的特征信息应当给予更多的关注;在判断裂纹舌时,舌中位置的特征信息更加重要。因此舌象的不同位置的特征重要性不同。本文设计了一种位置注意力机制,具体表达式为
P(x,y)=J(x,y)*b(x,y)
(2)
式中:J(x,y)代表输入特征图J的坐标为(x,y)处的特征值,b(x,y)代表产生的位置注意力权重在(x,y)处的值,P(x,y)代表特征图经过位置注意力机制后的输出。具体框架如图5所示。
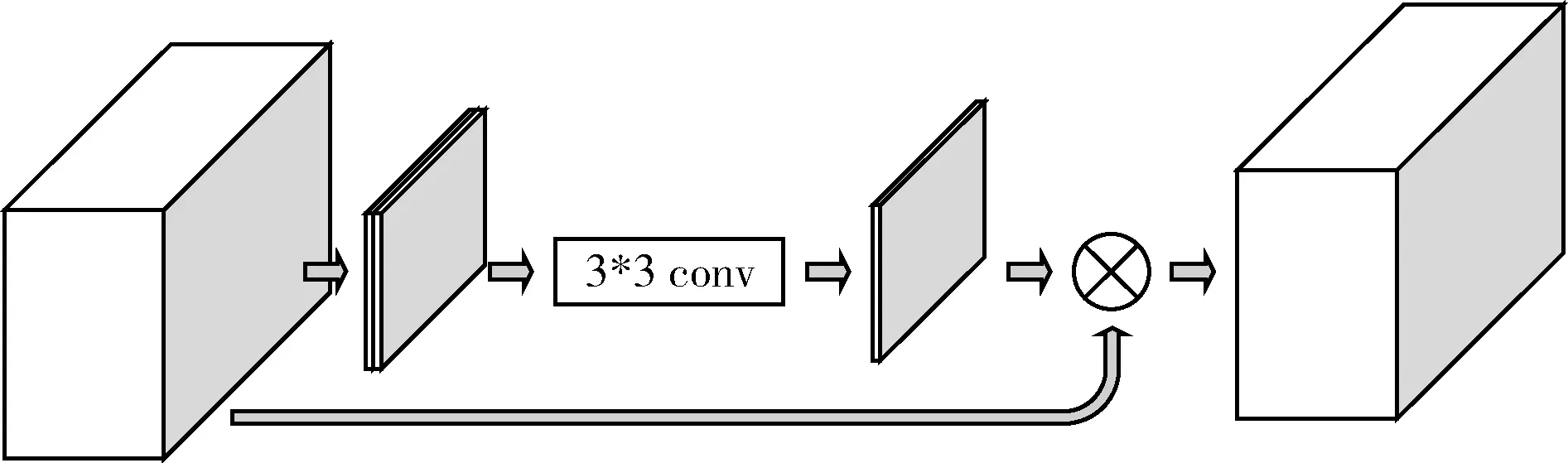
图5 位置注意力机制
首先将特征图通过最大值池化和平均值池化,通过这两次池化操作,我们提取特征图上每一个位置的特征信息。设初始特征图的维度为N×C×H×W,在通过池化操作后变为N×1×H×W。然后将得到的特征图作为位置注意力机制的初始权重,通过3*3大小的卷积核,这样做是为了将通过两种池化方式提取到的特征信息进行融合,并进一步自适应学习权重。最后将得到的权重与初始特征图相乘,为特征图不同位置分配不同的权重。
通过位置注意力模块,我们针对不同的舌象类别为每一位置的特征分配权重,使得显著位置的特征获得更大的关注,更加有效地处理特征信息,提高分类准确率。
1.4 舌象分类任务阶段
舌象分类算法大多是单标签分类,一般只是针对颜色、形状或者纹理其中一种考虑分类问题并没有考虑到多标签分类。如果要实现舌象的多标签分类,常规的做法是针对多标签训练多个单标签分类模型,这样做不仅极大增大了算法的复杂度,而且忽略了各个类别之间潜在的关系。这与中医考虑患者整体的思想不相符合,没有对多个标签整体建模。
为实现舌象的多标签分类,本文设计了舌象分类阶段网络如图6所示。为了使网络可以从整体对舌象进行建模,挖掘各个类别之间存在的隐形联系,我们令分类阶段各个标签共享舌象定位阶段获得的舌象特征图。然后我们针对不同的类别,将特征图均通过注意力机制模块,以根据不同的类别进一步挖掘与该类别相关的特征信息。最后将获得的特征信息送入全连接网络层,得到最后的分类结果。
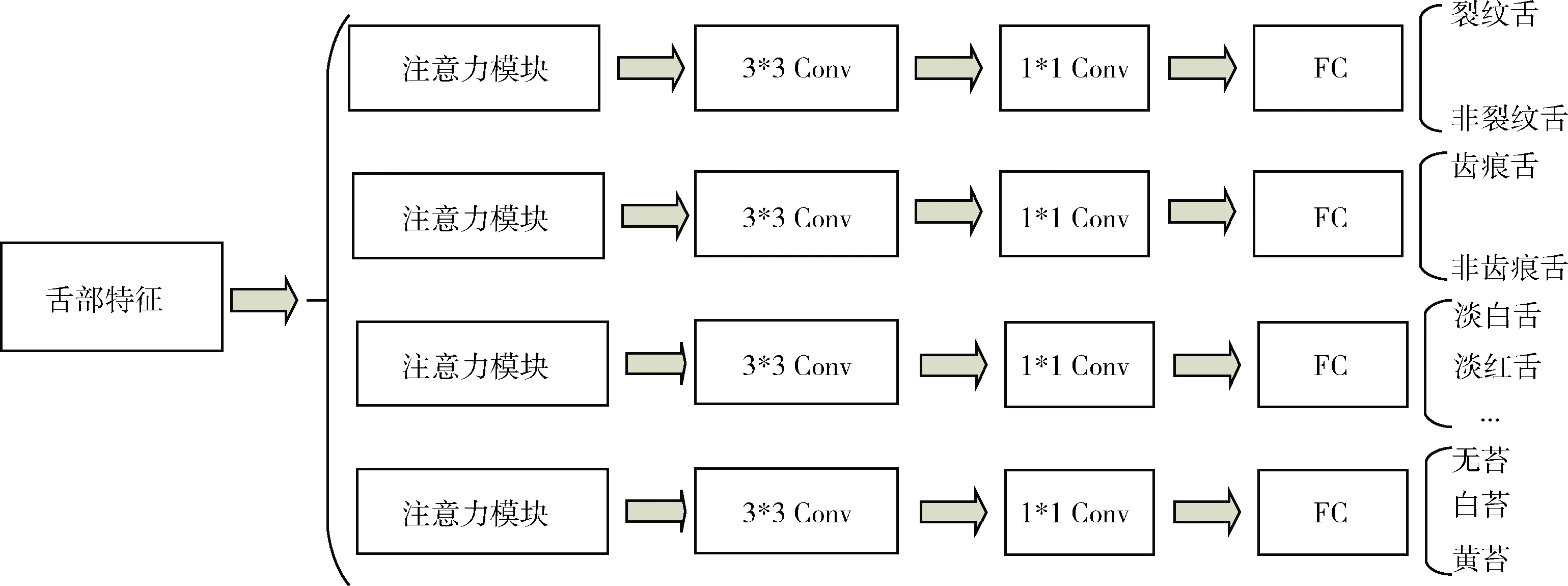
图6 分类阶段
1.5 网络训练
由于舌象分割与分类本质上都属于分类问题,故网络的舌部定位与分类阶段均采用交叉熵损失函数。交叉熵损失函数是常见的分类损失函数,在很多算法中都有使用,其具体公式如下
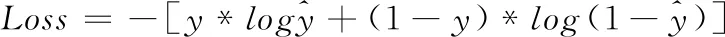
(3)
由于现阶段深度卷积神经网络的训练仍然需要大量的样本,但是对于舌象图来说,如果数据量不够,在训练网络时容易出现网络不容易收敛或者过拟合的问题,导致训练结果变差。
为解决以上问题,我们采用迁移训练和数据增强的方法。一般来说,卷积神经网络不同层级具有不同的特点,浅层网络提取的特征共性很大,在不同的数据集上表现比较相似,因此将网络的浅层部分通过参数的迁移进行学习是可行的。我们将在ImagNet上预训练得到的权重作为网络的初始权重,大大提高了网络的收敛速度。另外,我们通过对采集到的舌象样本进行随机的平移、旋转、镜像变换等操作,增加了样本的丰富性,解决了样本量不足的问题。
2 实验结果分析
2.1 舌象数据集
舌象采集过程容易受到光照等环境因素的影响,同一舌象在不同光照情况下可能会呈现出完全不同的状态。为解决这一问题,我们设计了专业的舌象采集系统使得采集舌象图片的环境保持稳定。采集系统内置了积分球装置,内壁涂有漫反射材料,可以使得光照均匀分布在积分球内空间。采集时,患者将舌部伸入到腔体当中即可完成拍摄采集。下图为采集到图片的实例。从示例图片中我们可以看出,通过我们设计的采集设备采集的舌象图片,舌面部分获得了均匀稳定的光照,从而消除了由于光照不稳定带来了分类误差。具体示例图如图7所示。
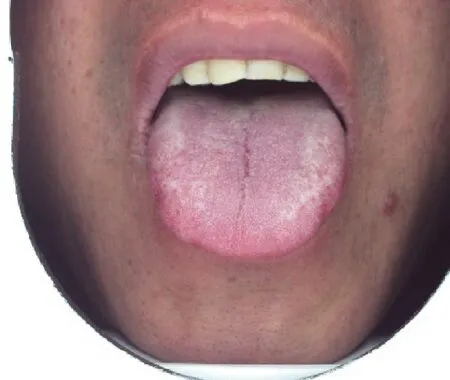
图7 采集图片
本实验采集到的舌象图片共有2300张,均由上文舌象采集系统采集,图片的大小为2300*1944,选取其中的2000张作为训练集,300张作为测试集。舌象特征分为裂纹舌、齿痕舌、舌苔、舌色,其中舌苔又分为无苔、白苔、黄苔,舌色分为淡白舌、淡红舌、绛红舌、红舌、紫舌。每种标签的图片数目见表1。
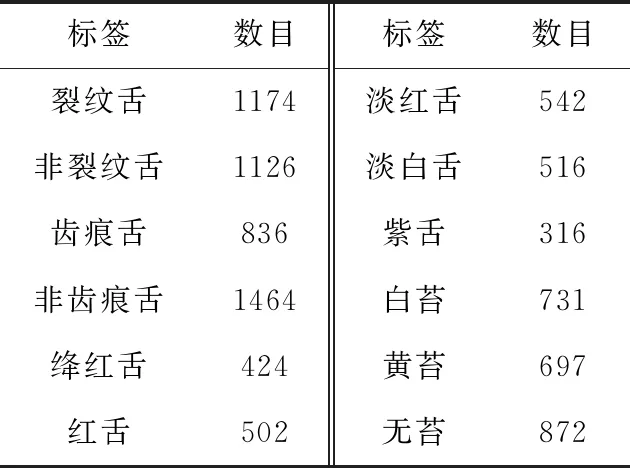
表1 实验样本数据
2.2 实验环境
本文具体的实验环境见表2。
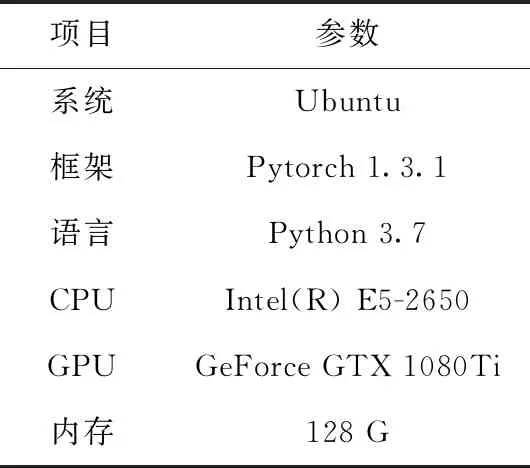
表2 实验环境参数
2.3 评价指标
由于本文网络的任务为分类任务,故选取了精确度P、召回率R、F值作为本文的评价标准。其中
(4)
(5)
(6)
其中,TP为预测为正值实际结果也为正值的数目,FP为预测为正值实际结果为负值的数目,FN为预测为负值实际为正值的数目。P为精确度,反映的是预测结果为正并且预测正确的样本占所有预测结果为正样本的比例,即为查准率,与错分率相对应。R为召回率,反应的是预测结果为正并且预测正确的样本占所有样本实际为正值的比例,即为查全率。F是综合精确度P和召回率R考虑得到的参数,反映了整体的准确率情况。3个参数都是分布在0-1之间,且越接近1效果越好。
2.4 舌部定位结果展示
舌体的定位结果对于后续的分类的结果有着极大的影响,如果定位阶段不能很好地提取舌部轮廓,消除背景,在分类阶段就会引入额外的误差,导致分类结果变差。为此,我们将本文网络得到的舌部定位结果输出如图8(b)所示。
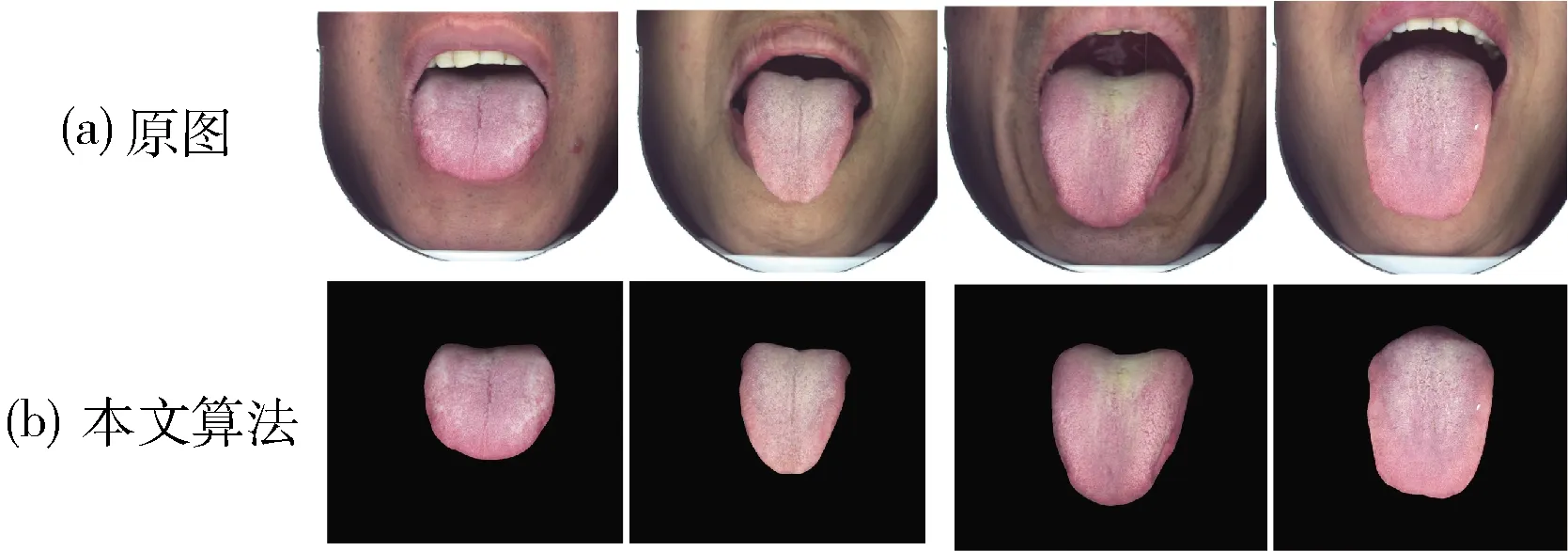
图8 舌象定位结果
从图8中我们可以看出本文算法提取了舌象深层次特征,能够更好对舌象部分建模分析,得到完整的不含干扰信息的舌象轮廓。
为了验证本文的舌象定位模块相较于其它算法能获得更加精准的舌象轮廓,我们将本文网络得到的结果与几种算法的结果作比较如图9所示。
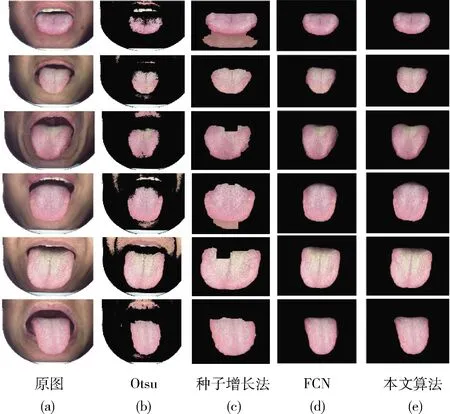
图9 舌象定位结果对比
从图9(b)我们可以看出,由于Otsu算法采用自动阈值分割方法,与舌部颜色较为相近的某些脸部区域尤其是嘴唇和牙齿等无法得到很好的区别,仍然保留在最后的定位图上,导致最后的定位结果引入了额外的误差。从图9(c)可以看出,种子增长法相较于Otsu算法有了很大的效果提升,但是仍然存在一些区域定位效果不好的现象,且最后的舌象定位结果出现了明显的矩形边界,边缘分割结果差。从图9(d)可以看出,基于深度卷积神经网络的全卷积(FCN[13])算法相较于以上两种算法,舌体轮廓提取更加完整,而且边缘部分更加精准,但是仍然存在一些干扰信息,导致边缘部位定位不准。而图9(e)显示本文舌象定位阶段算法融合了不同感受视野的舌象特征,并通过专用的特征融合模块进行特征融合,因而算法整体更加具有鲁棒性,得到的效果更好。
2.5 分类效果分析
本文以类别为基础,分别计算了算法在舌质、舌苔、裂纹、齿痕等类别上的P、R、F值,具体结果见表3。
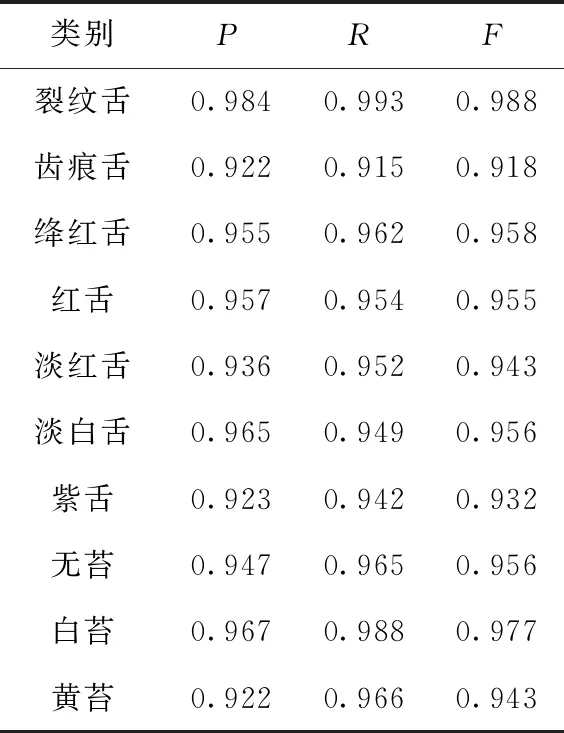
表3 本文算法结果
从表中可以看出,所有类别的P、R、F指标均超过了0.9,其中裂纹舌的P、R、F已经达到0.99,说明本文的算法能够对舌象正确的分类。但是其中齿痕舌的指标相对于其它类别偏低,一方面是由于齿痕位于舌部的边缘,而舌象的定位阶段对于边缘的划分仍然存在不足,导致边缘部分引入噪声,造成算法对于舌象是否包含齿痕产生误判。另一方面,由于某些样本的齿痕并不明显,齿痕部位与周围舌象较为接近,差异度较小,从而导致算法产生误判。
为了验证本文注意力机制的有效性,将未添加注意力机制网络得到结果的P、R、F值与添加注意力机制相比较得到结果如图10~图12所示。
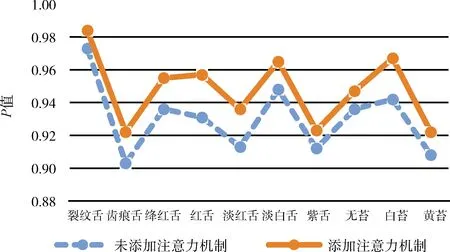
图10 是否添加注意力机制P值比较
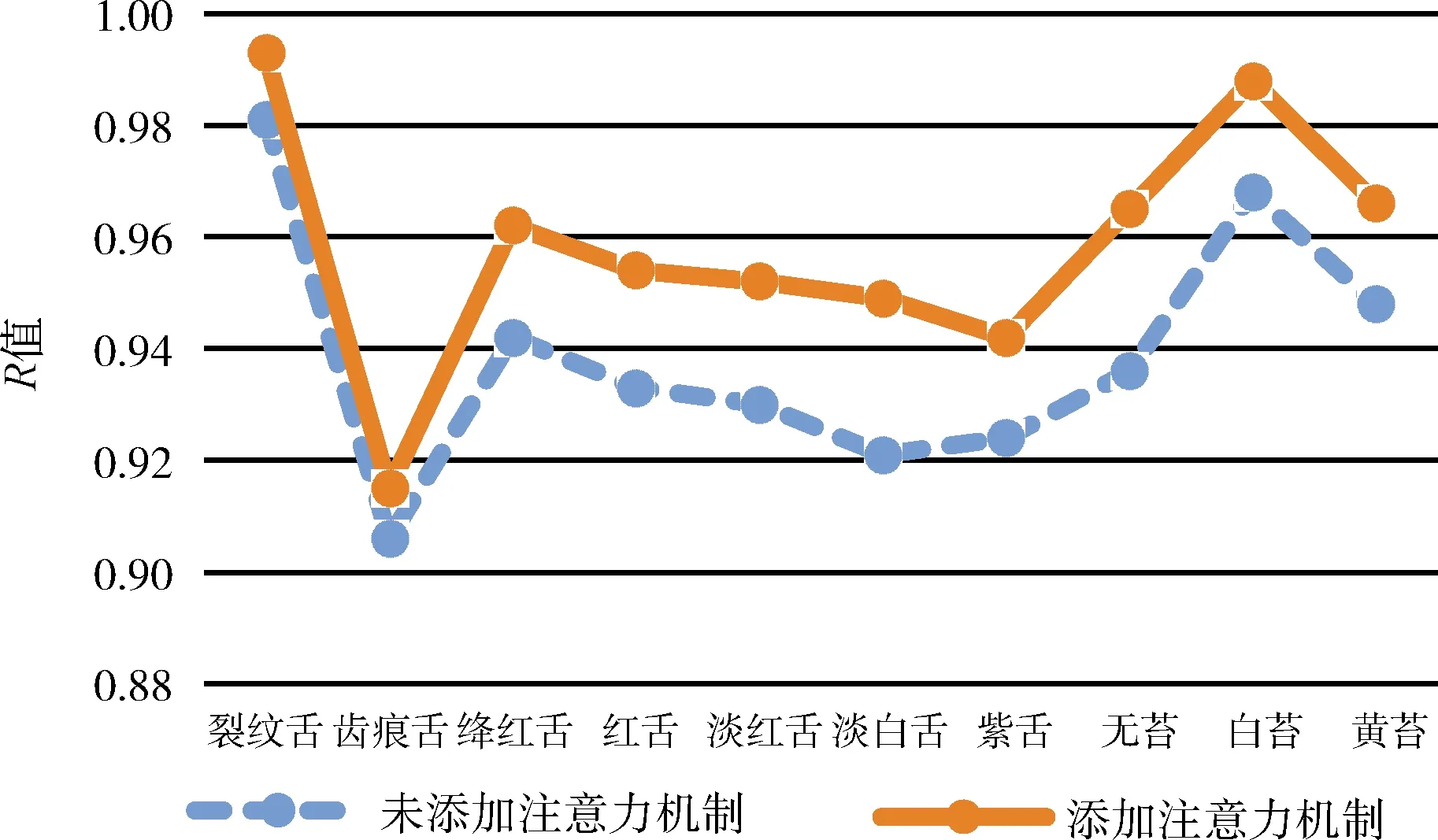
图11 是否添加注意力机制R值比较
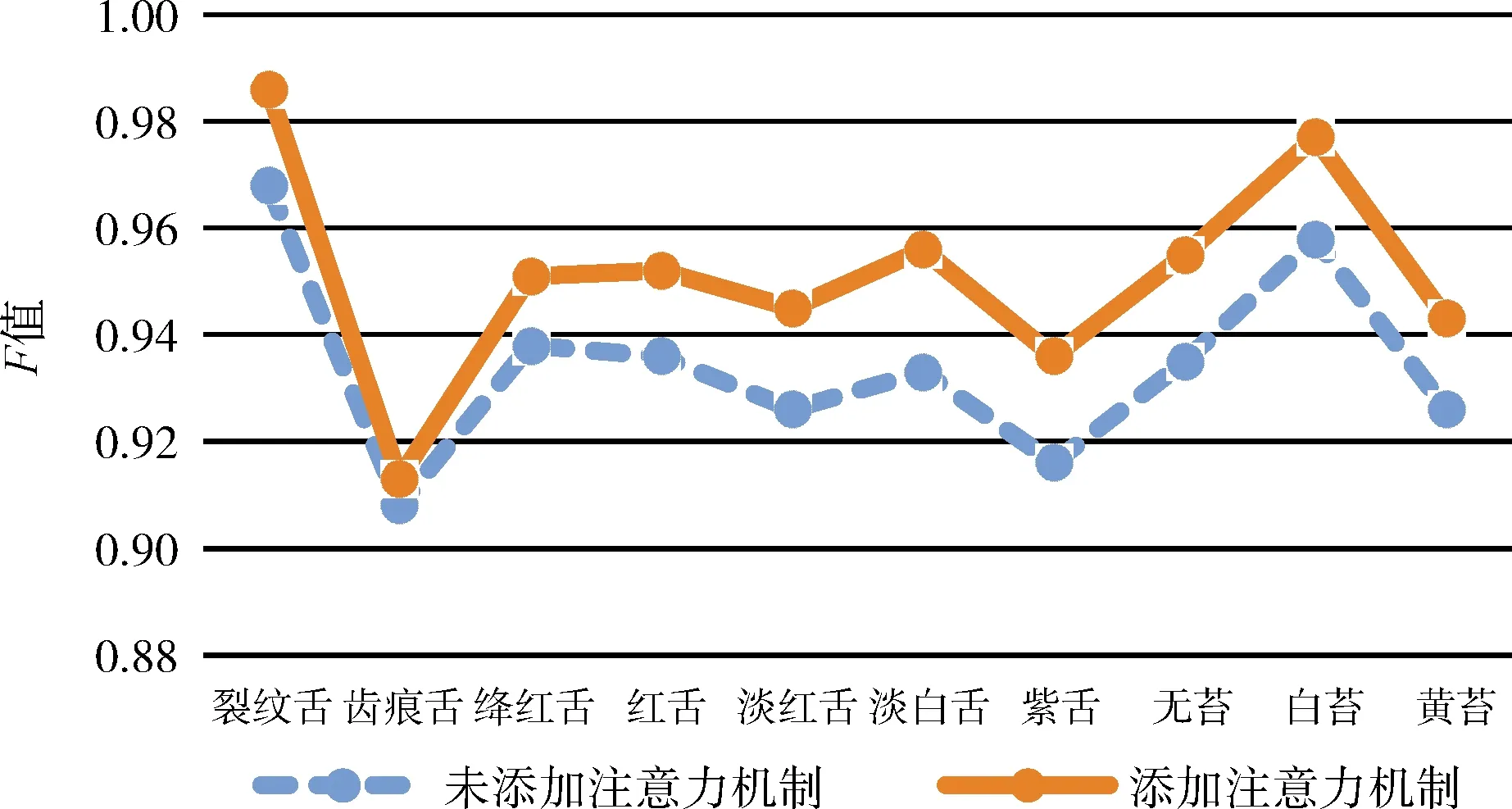
图12 是否添加注意力机制F值比较
从图10~图12可以看出,添加了注意力机制的P、R、F值均优于未添加。由此可以看出,通过注意力机制模块,网络抑制了无关特征的干扰,学到了更加精准的特征信息,改善了最后的分类结果。
为了验证本文算法相较于其它算法的优越性,本文选取了几种常见的舌象分类算法进行对比。首先选取文献[14]中的改进KNN算法,通过多次实验选取最优的实验结果。然后选取SVM算法,采用核函数技巧,并通过多次实验确定最优的C值。最后采用深度卷积网络Inception-V4[15],使用迁移学习训练网络,通过多次实验选取最优结果。具体的实验结果如图13~图15所示。
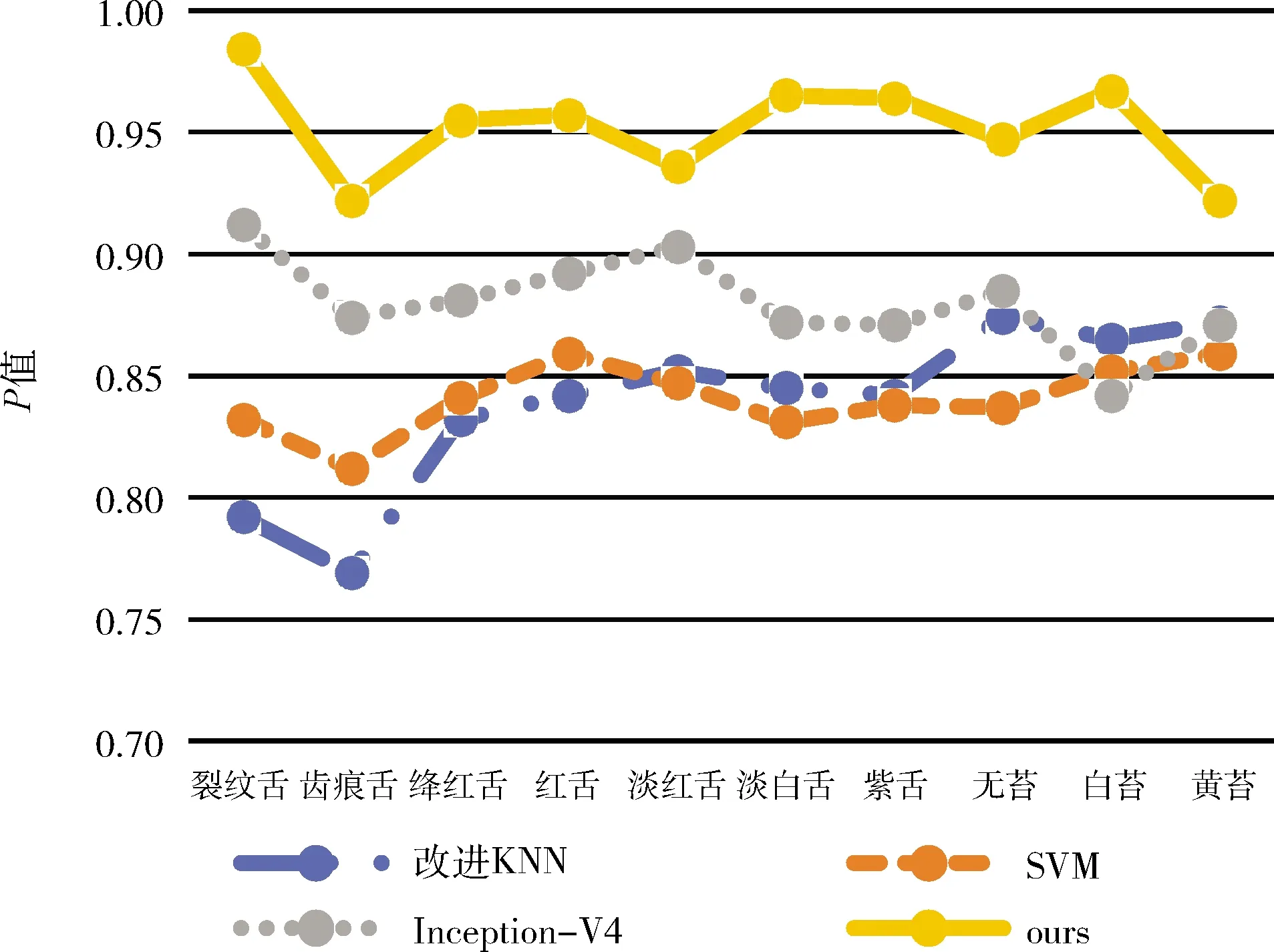
图13 不同算法的P值
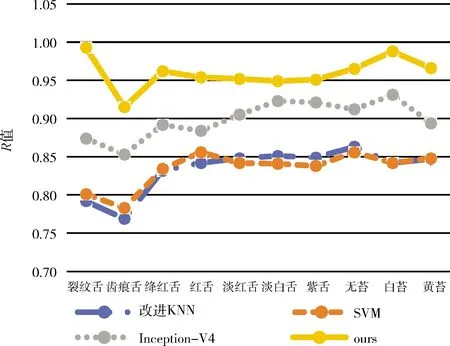
图14 不同算法的R值
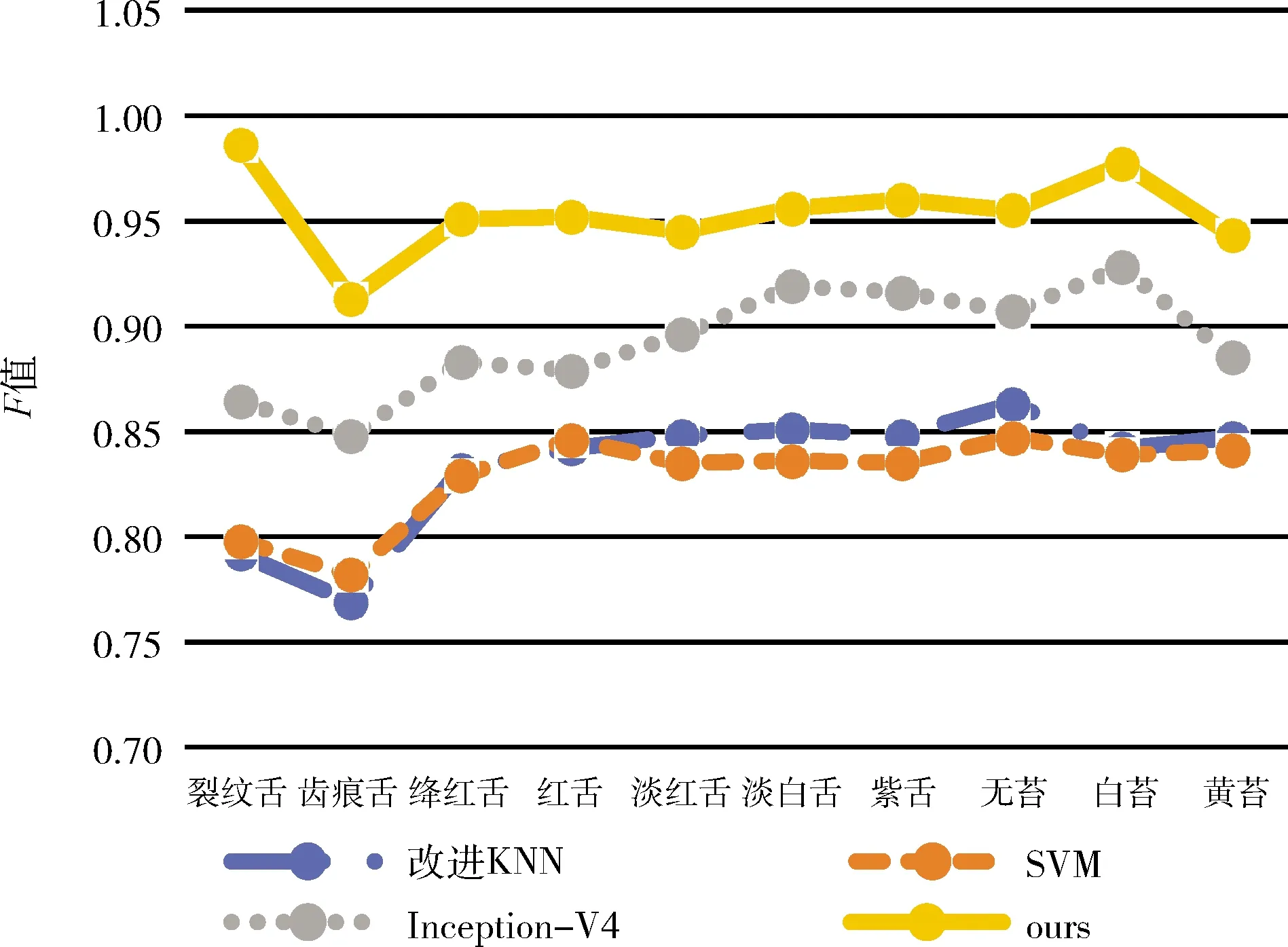
图15 不同算法的F值
从图13~图15可以看出,基于人工提取特征的KNN和SVM表现较差,因为人工提取的特征较为简单,表达能力欠缺,不能很好地体现类别的差异。另一方面KNN算法基于舌象整体的差异度,不能体现每个类别独特的特征差异,SVM基于线性分类器,不能适应复杂的舌象特征。而基于深度卷积神经网络的Inception-V4相较于传统算法,采用了自动提取特征的方法,能够获得更加深层次的特征,但是由于Inception-V4同时也提取了包含面部干扰信息的特征,造成误差。本文的算法排除面部干扰信息,融合多种层次特征,并且多标签联合学习增强了特征的表达能力,并且借助注意力机制,精准提取了每一类舌象的独有的特征,获得了最优的结果。
为了验证本文算法效率的优越性,将上面算法的运行时间与本文算法作比较,得到结果见表4。
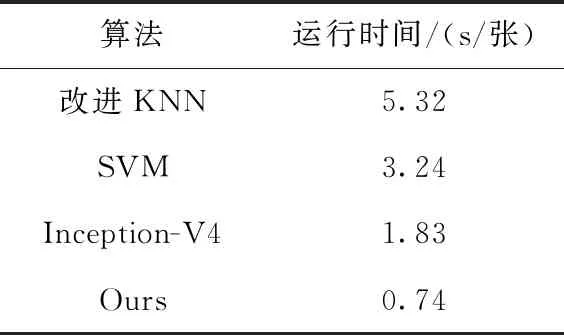
表4 不同算法的运行时间
由于以上算法多为二分类算法,进行多标签任务时需要训练多个模型,因而导致算法效率低下。而本文模型属于多标签分类模型,只需一个模型即可完成多分类任务,因而效率大幅提高。
3 结束语
本文设计了一种融合注意力机制的多阶段舌象分类算法。在舌部区域定位阶段,通过融合不同感受视野的舌象特征,改善了舌象定位效果,提高了算法的鲁棒性。在分类任务阶段,通过多标签样本联合学习,提取各个标签的共同特征。另外借助注意力机制,抑制了舌体内部的干扰信息,同时学习每个类别的独立特征,实现了舌象类别的多标签分类,并且提高了精度。
由于齿痕信息位于舌体的边缘,而在舌体定位过程中边缘信息容易引来误差,另外,由于有些患者的齿痕并不明显,且与周围舌体较为接近,所以导致齿痕舌的分类效果不如其它类别准确率高。接下来会进一步优化注意力模块算法,提升齿痕舌的识别精度。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:25:06
世界科学技术-中医药现代化(2022年2期)2022-05-25 13:15:24
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
世界科学技术-中医药现代化(2021年9期)2021-12-31 03:30:24
世界科学技术-中医药现代化(2020年2期)2020-07-25 02:06:32
中国实验诊断学(2018年4期)2018-04-24 02:12:06
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
吉林广播电视大学学报(2015年4期)2015-11-19 01:33:38
实用医药杂志(2014年12期)2014-04-05 22:27:46
