
基于Spark平台的海量AIS数据k-means算法聚类分析
2021-06-28 08:36初秀民王志远
交通科技 2021年3期
初秀民 林 宏 王志远
(1.闽江学院物理与电子信息工程学院 福州 350108;2.闽江学院福建省船舶智能航行安全控制工程研究中心 福州 350108;3.闽江学院海洋智能船舶装备福建省高校工程研究中心 福州 350108)
当前,在经济全球化的影响下,低成本和大运输量的优势使水上运输成为世界各国之间贸易和运输的主要方式之一。自动识别系统(automatic identification system, AIS)是用于分析船舶航行状况的主要工具。随着水运的发展,AIS数据量呈指数增长,为了对这些数据进行分析,需要一个大数据平台来有效地处理这些数据。Spark因其速度快、通用性强等特点,逐步受到智能交通领域的青睐,例如曹磊[1]通过搭建基于Spark的通用型数据处理挖掘平台,以对AIS数据进行挖掘。
由于AIS没有完整的信息验证机制,在实际应用中AIS数据中存在大量的异常数据,因此需要进行有效甄别以保障船舶航行安全。目前国内外的研究主要集中在AIS数据的应用研究,而对AIS数据本身的准确性分析缺少。例如,Zhang等[2]使用AIS数据来评估遇船风险。Dobrkovic等[3]使用遗传算法对船舶位置信息进行聚类,并研究了船舶航向的特征。Altan等[4]使用AIS数据分析了伊斯坦布尔海峡的航运特征,为船舶航行风险的预测和分析提供了支持。田璐[5]考虑AIS数据的特征,设计了其处理流程和存储策略,并利用AIS数据实现船舶航迹重构、截面船舶流量统计、船舶出入口区域识别,以及船舶航行状态分析等。Mazzarella等[6]分析AIS数据,以确定故意关闭船载AIS设备的异常行为。LongépéN等[7]分析AIS数据以识别非法捕鱼。魏照坤[8]利用琼州海峡的AIS数据,获得行驶于该水域的船舶运动轨迹分布及各类轨迹中转向区域的分布。
为此,本文设计了一个基于Spark的大数据处理平台,使用k-means算法对AIS数据进行聚类分析,并将Spark建立AIS数据的聚类所需的时间与在机器上对AIS数据进行聚类所需的时间进行比较。
1 AIS数据处理平台设计与实现
1.1 总体框架
AIS数据处理平台主要包括数据存储层、资源管理层、计算引擎及接口、操作语言的运用。总体架构生态图见图1。
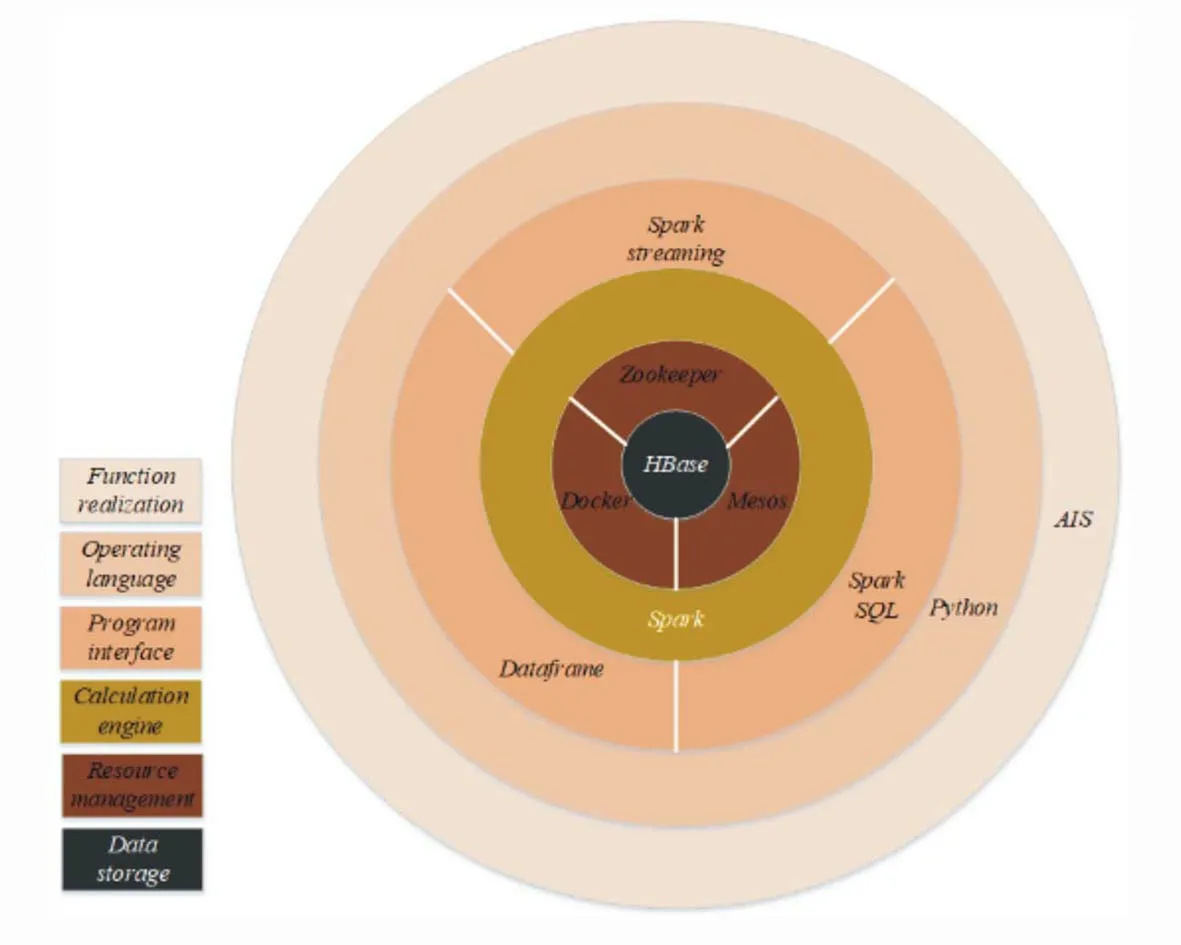
图1 总体架构生态图
1.2 数据存储层
AIS数据包括船舶的静态信息和动态信息。静态信息是船舶在航行过程中保持不变的信息,包括MMSI号、船舶名称、船舶类型、船舶的长和宽、吃水等信息。动态信息是船舶在航行过程中随着时间的推移,不断变化的信息,包括船速、船舶位置信息、船艏向、船舶状态等。
HBase是基于HDFS的NoSQL数据库,它的表是按列存储的、稀疏的、多维度的、有序的映射表,它的存储模式是KeyValue键值对存储,与纯粹字符串的Key不同的是:HBase的 Key由RowKey、Column Family、Column Qualifier和Timestamp 4个部分共同组成。以上这些特点使得Hbase具有易扩展、适合大量的查询与写入工作等特点。
针对AIS数据量大、数据信息复杂等特征,本文采用基于HBase数据库来存储AIS数据。对AIS数据进行分析的时候,一般通过时间和MMSI号进行数据的分类与切片,因此将“DateTime and MMSI”作为行,以其他信息为列,具体设计见表1。

表1 AIS数据结构表
1.3 资源管理层
为了对平台资源进行分配与管理,本文搭建了以Mesos、Zookeeper为主体的资源管理层。
Mesos对平台中CPU、内存、存储和其他计算资源进行合理的分配,使得弹性分布式系统使用起来更加方便。但是Mesos在运行过程中存在单点故障问题,为此本文采用Zookeeper来解决这个问题。ZooKeeper能够实现Master和Slave的容错。将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。资源管理架构图见图2。

图2 资源管理架构图
1.4 计算引擎及接口
Apache Spark是一种专门处理大数据的热门计算引擎,同时提供了Spark SQL、Spark Streaming、Mllib、GraphX等4个范畴的计算框架,其框架图见图3。Spark SQL是实现结构化数据操作的程序包,支持用户以SQL语句的方式来处理数据且支持多种数据源。Spark Streaming支持对实时数据进行流式计算。Mllib为用户提供了常用机器学习算法的实现库。GraphX实现了高效的图计算。Spark以将应用放到内存中运行的方式,提高了程序的运行数据,且具有计算速度快、易用性好、通用性高等优点。
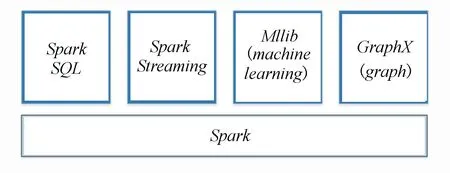
图3 Spark框架图
2 算法概述
k-means算法是一种常见的聚类算法,其基本思想是通过迭代找到k个聚类的划分方案,以便使用这k个聚类的平均值来表示相应类型的样本。
k-means算法的基础是最小误差平方和准则。成本函数为
(1)
式中:i为第i个簇;x为样本,μc(i)为第i个簇的平均值。直观地讲,每个类别中的样本越相似,样本与类别平均值之间的误差平方就越小。希望成本函数最小,如果将每个聚类划分为k个类别,则可以验证针对所有类别获得的误差平方和。
上式的成本函数不能通过分析方法最小化,只能使用迭代方法。k-means算法将样本聚类为k个聚类,其中k由用户指定。解决过程直观且简单。具体算法描述如下。
1) 随机选择k个聚类质心点。
2) 重复以下过程直到收敛。
①对于每个示例i,计算它应该属于的类别,计算方法如式(2)所示。
(2)
②对于每个k类,重新计算该类的质心,计算方法如式(3)所示。
(3)
3 试验
3.1 硬件平台搭建
平台使用4台计算机搭建,计算机配置为CPU为Intel(R) Xeon(R) CPU E5-2603 v4@ 1.70G Hz,内存为5.0 G,硬盘为200 G。用来搭建hadoop、Spark 集群,另外1台用来访问集群。架构图见图4。

图4 架构图
3.2 软件环境
4台计算机搭载的系统均为Centos 7,安装的JDK版本为openjdk version “1.8.0_252”,Hadoop版本为Hadoop 2.10.0,Spark版本为version 3.0.0,Mesos版本为1.10.0,ZooKeeper版本为3.4.6。集群搭建内容见表2。

表2 集群搭建内容表
4 实验结果分析
通过k-means算法分类可获得不同类型的轨迹点,其AIS轨迹聚类分析图见图5。
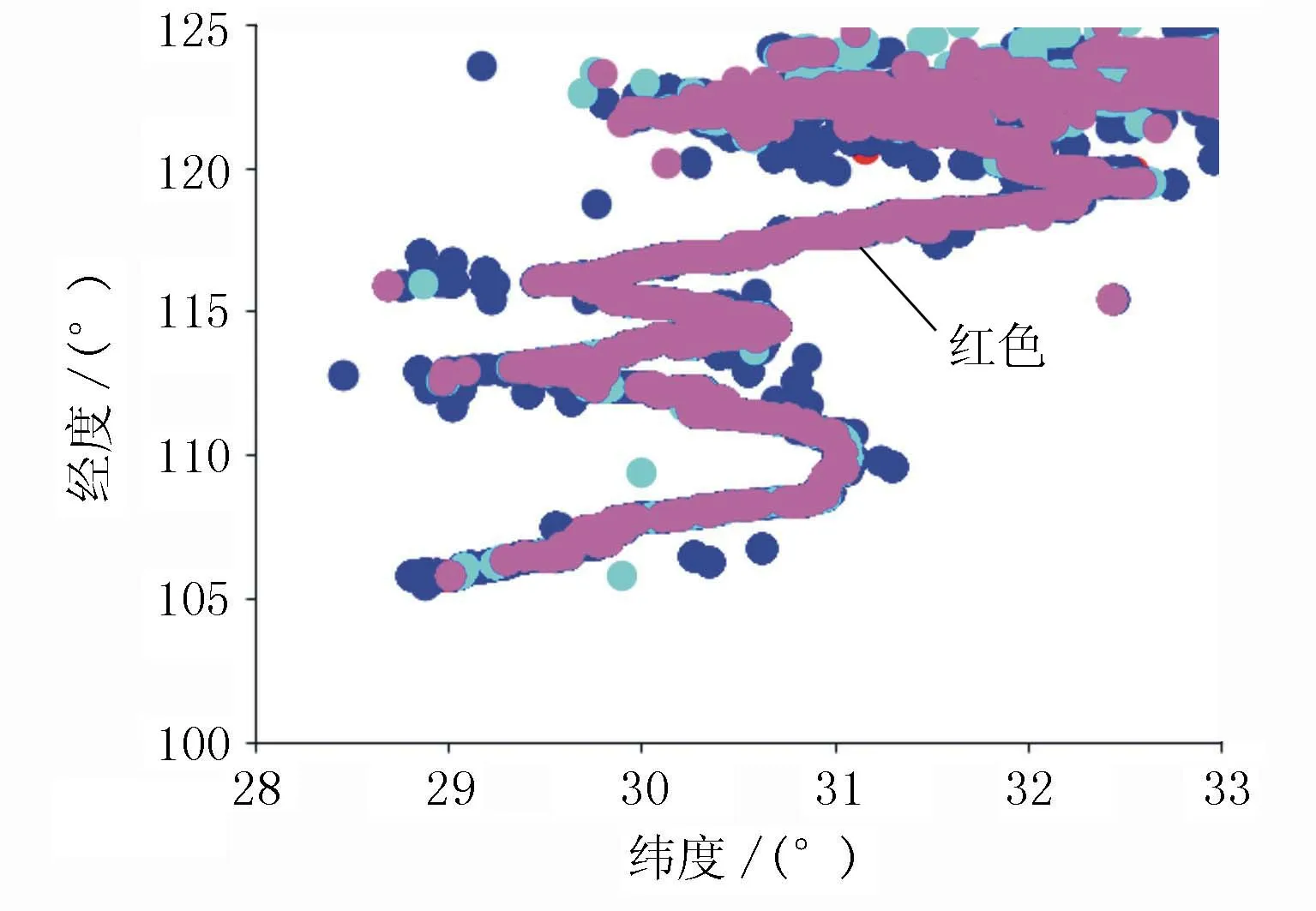
图5 基于k-means算法的AIS轨迹聚类分析图
图5中红色点表示正常点,主要落在航道中,其他颜色的点表示异常点。这些异常点中的一些分布在附近的陆地上,而有些则离得很远,因此无法正确表示船舶的轨迹。
王畅[9]采用Dbscan算法对天津港泊位点进行聚类,并与真实泊位对比,验证了聚类结果的准确性,为此本文采用Dbscan算法对k-means算法的有效性进行了验证。Dbscan算法对同一数据样本的聚类分析结果图见图6。
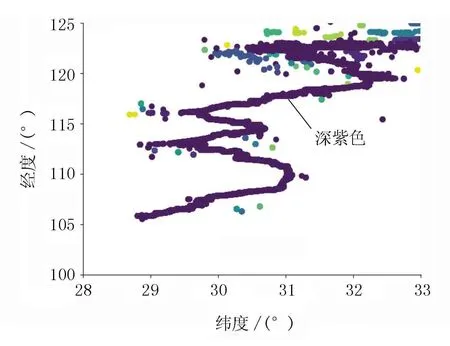
图6 基于Dbscan算法的AIS聚类轨迹分析图
其中,深紫色的点表示表示正常点,主要落在航道中。其他颜色的点表示异常点。这些异常点中的一些分布在附近的陆地上,而有些则相距很远,因此不能正确地表示船舶的轨迹。
图5中的红色轨迹线和图6中的深紫色轨迹线均表示集群的船只轨迹。2条轨迹高度一致,说明本文的k-means算法可以对AIS数据进行有效的聚类分析。
由Spark集群和没有Spark集群的计算机对AIS船舶轨迹进行聚类的运算时间比较见图7。
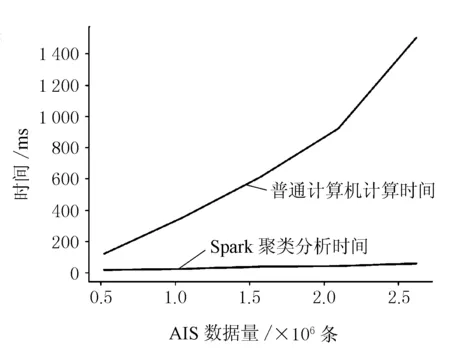
图7 运算时间比较图
由图7可见,未安装Spark集群的计算时间随着AIS数据量增加大幅度上升,而Spark聚类分析时间随着AIS数据量的增加略微增加,且远小于未安装Spark集群的计算时间,并随着AIS数据量的增加差异越大,故Spark聚类分析可大幅度提高运算速度。
5 结语
针对大量的AIS数据和信息处理,本文使用基于Spark、Hadoop和Mesos的大数据处理平台来分析AIS数据。通过对船舶航迹点的k-means聚类分析,对不同航迹点进行分类,并将本文构建的大数据平台与无大数据平台计算机的分析效率进行了比较分析。测试结果表明,该平台可大幅度提高AIS数据分析的效率。在AIS数据量不断增加的环境中,本文构建的平台可以提高数据处理效率,对AIS数据进行有效的聚类分析,为更深入的AIS数据分析奠定基础。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
电子制作(2019年13期)2020-01-14
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
