
基于改进区域推荐网络的多尺度目标检测算法
2021-06-28 09:58:08孙克雷
安庆师范大学学报(自然科学版) 2021年2期
张 莉,孙克雷
(安徽理工大学计算机科学与工程学院,安徽淮南 232001)
在对物体和场景的识别中,多尺度目标检测是指准确定位出图像中用户感兴趣的目标(该目标具有尺度不一的特性),并能准确判断出每个目标的类别、边界框的位置和大小[1]。由于目标检测任务中的目标存在较大的尺度变化,所以算法能精确框选出大小不一的目标框的问题亟待解决。区域卷积网络[2](Region-Convolutional Neural Networks,R-CNN)、金字塔池化网络[3](Spatial Pyramid Pooling Netwoks,SPPNet)、你只看一次网络[4](You Look Only Once,YOLO)、单次检测器[5](Single Shot MultiBox Detector,SSD)和基于区域的快速CNN[8](Faster Region-Convolutional Neural Networks,Faster R-CNN)等算法相继被提出。2015年,R Girshickj提出Fast R-CNN,利用感兴趣区域(Regions of Interest,RoI)提高目标检测质量,减少目标检测的运行时间[2]。2014年,K He等提出更新金字塔网络层(Spatial Pyramid Pooling,SSP),SSP层之前的卷积层和检测器无法共享卷积特征,从而限制了检测精度的提升[3]。2016年,J Redmon提出的YOLO运行速度可达每秒155帧图像,目标检测平均准确度均值mAP较高[4],但是YOLO的单元格仅预测两个边界框,且属于同一类别,故对于小目标的检测YOLO的检测精度下降。2016年,W Liu提出单次检测器SSD算法,它以牺牲检测精度为代价来提高检测速度[5],但在识别被放大的小物体时检测精度明显下降。综上所述,当下流行的目标检测算法在小尺度物体的目标检测场景有较好的检测效果;对于多尺度目标检测,受候选区域推荐和区域分类方法的影响,在检测极大或极小的目标物体时检测效果差强人意。
针对多尺度输入的图像既要检测精度高又要检测速度快,本文提出在Faster R-CNN的基础上对多尺度目标检测算法进行改进。针对目标检测速度慢的问题,提出基于改进的区域生成网络(Region Proposal Network,RPN),用候选区域网络RPNS和RPNB得到带有对象得分的矩形目标推荐;针对存在小目标检测精度低的不足,设置多尺度和多高宽比的锚点框计算并提取每个推荐的局部特征,用DOL设置阈值进行分类和回归。
1 R-CNN算法
目标检测算法的主要思想是从图像中检测并定位多个特定目标。R-CNN 采用端到端的方式训练CNN,其检测过程包含区域推荐、特征提取和区域分类[6]。R-CNN的成功在于两点:利用了卷积神经网络良好的特征提取性能;利用了有监督预训练、领域相关微调和目标类别分类3个有效训练步骤[7]。但计算量大、标注数据稀少,这导致了R-CNN检测速度很慢。基于R-CNN的目标检测过程如图1所示,首先输入一幅图像,然后自底向上提取推荐区域,并变化为固定大小的推荐区域,再用卷积神经网络计算每个推荐区域的特征,最后用支持向量机对推荐区域进行分类。

图1 R-CNN的目标检测过程
2 Fast R-CNN算法
针对训练过程中R-CNN标注数据稀少,研究人员提出在输入图像之后加入感兴趣区域RoI。RoI在Fast R-CNN结构中指卷积特征图中的一个矩形窗口,包含参数:左上角坐标(r,c)、高度和宽度(h,w),把这些参数放在一起定义一个四元数组(r,c,h,w)。RoI池化是利用最大池化把所有的RoI都转变成具有固定大小空间H×W的特征图,其中H、W是指层超参数,独立于任何特定的RoI。RoI最大池化的具体实现过程:先将h×w大小的RoI窗口划分成H×W个大小约(h/H)×(w/W)的子窗口,再把每个窗口的数字最大池化到相应的输出单元。预训练Fast R-CNN 会使用一个训练过的深层卷积神经网络来初始化。Fast R-CNN的目标检测过程如图2所示。由于每个RoI均有softmax概率和边框回归偏移两个输出向量,解决了R-CNN在训练过程中存在的标注数据稀少的问题,缩减了时空费用,并且提升了算法的检测精度。但是,Fast R-CNN因依赖耗时的RPN,多尺度目标检测效果不佳。
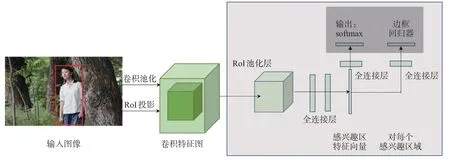
图2 Fast R-CNN的目标检测过程
3 改进的Faster R-CNN算法
为了克服区域推荐算法的局限,需要对Fast R-CNN算法进一步改进[8-10]。众所周知,Fast R-CNN算法的缺陷在于对目标位置的假设不准确[11-14],故首当其冲要解决的就是区域推荐算法RPN,用微调RPN的策略来解决算法产生的时空代价,从而解缓Fast R-CNN在目标检测过程中因使用耗时的区域推荐算法而产生检测速度慢和目标检测精度不高的问题。通过区域推荐算法,Faster R-CNN在面向多尺度、多目标的图像进行目标检测时检测精度相对高。实验中使用基于RoI的检测器模块,加入候选框重叠度DOL,该公式的核心是分别计算出大目标与小目标候选框的重叠面积和单独一个小目标的候选框面积,若前者超过后者的θ倍,就把相应的小目标候选框删除,从而达到减少目标检测时间和提升算法对不同尺度目标的检测效果。
3.1 区域生成网络RPNS和RPNB
传统的Faster R-CNN 算法在目标检测时,首先将要进行目标检测的图片输入到网络中,通过卷积层的卷积操作,产生不同尺度的特征图(Feature map),特征图一部分直接送到分类器进行分类,另一部分经过区域推荐网络RPN,生成多个推荐对象,分类器对推荐对象按照一定的分类标准进行分类。在此过程中,需对所有可能的候选框进行判别,这与依赖区域推荐网络来提供目标的精确位置有关,且为了提高准确率,需位置精修,最终的候选框相对稀疏,导致基于Faster R-CNN的目标检测算法在速度上不能满足实时性的要求。Faster RCNN的目标检测过程如图3所示。
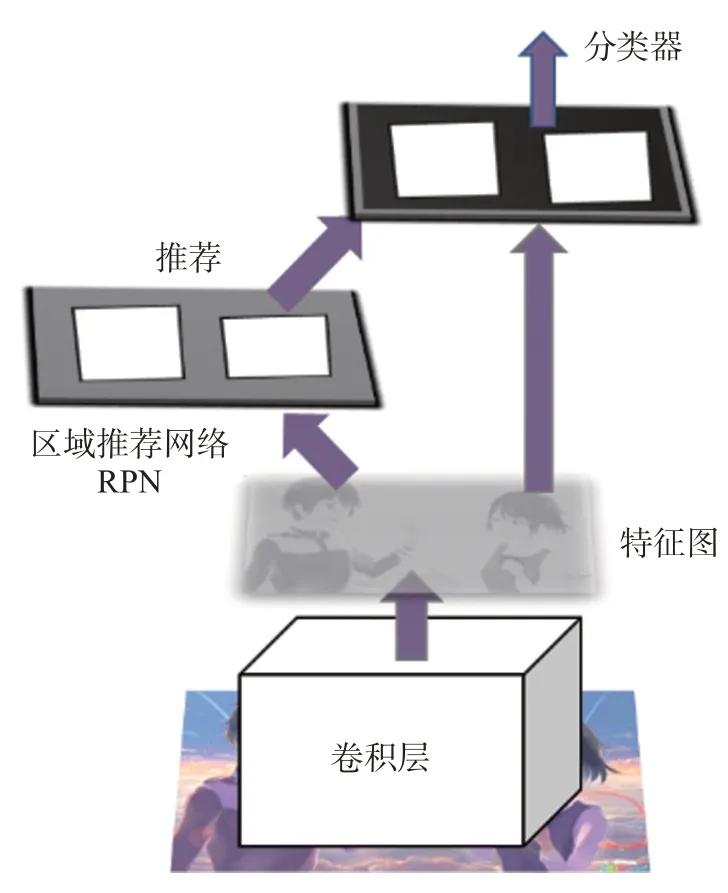
图3 Faster R-CNN的目标检测过程
针对多尺度问题,设计两个具有不同锚点的区域生成网络RPNS和RPNB。相比传统的网络用Selective Search 来提取候选框,用RPNS和RPNB来提取候选框一方面节约了时间成本,另一方面可作为卷积网络的一部分融入到网络结构中。区域推荐网络的运作机制:输入由卷积层得到的共享特征图,通过滑动窗口(Sliding Window)得到不同通道的特征图,实验中将滑动窗口设置为3×3。RPNS通过3×3的滑动窗口得到一个通道为256的特征图,RPNB通过3×3的滑动窗口得到一个通道为512的特征图。区域推荐网络后,做两次全连接(Full Connection)操作,一个全连接操作得到2个分数,另一个全连接得到4个坐标。2个分数对应目标图像的物体分数和背景分数,4个坐标是相对原图坐标的偏移量。最后,结合不同规格的锚点,得到用户需要的候选框。
本文的网络结构参考了MSO Faster R-CNN[1]网络结构,针对小尺度目标,在Convolutional5后,得到小尺寸特征图(Small Feature Map,Small FM),采用3×3 的滑动窗口选取对象,RPNS在此负责预测被放大的小物体,经过2次全连接操作得到维数为256的低维特征向量。与文献[1]不同的是,经过滑动窗口后,得到2 k个分数和4 k个坐标。Small FM通过RoI Pooling和3次全连接操作转化为维度一致的特征向量进行回归(Regression,REG)、分类(Classification,CLS),锚点尺寸分别设置为22×22、32×32、45×45和64×64。针对大尺度目标,方法相同,不同的是锚点尺寸分别设置为128×128、256×256 和512×512。RPNB负责预测被缩小的大物体,这样真实的物体尺度分布在较小的区间内,避免了极大或者极小的物体。改进的MSO Faster R-CNN的网络结构如图4所示。
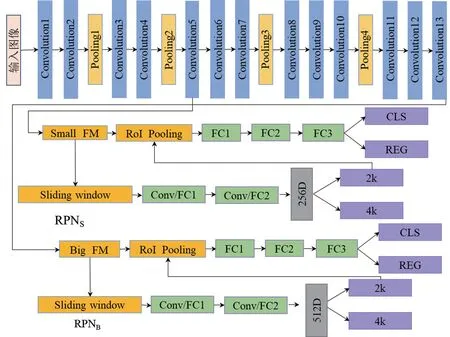
图4 改进的MSO Faster R-CNN的网络结构
对于一个锚点的情况,分类损失函数Lcls和回归损失函数Lreg的定义分别为:
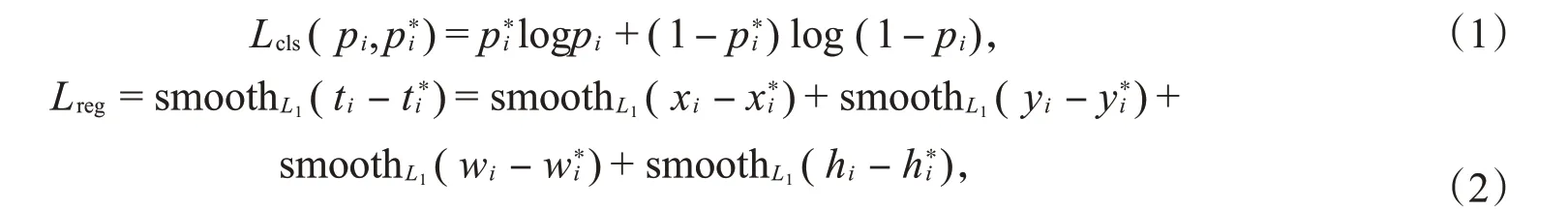
其中i是一个锚点索引,被用来定位锚点的位置,pi锚点i被预测为目标的概率值,向量ti=(ti,x,ti,y,ti,w,ti,h)表示预测边框坐标,向量表示正锚点真实边框坐标[14]。ti和的各分量还满足
其中,参数x、y、w和h分别代表边框的横坐标、纵坐标、宽和高。变量x、x*和xa分别代表预测边框、真实边框和锚点边框的相应坐标值(变量y、w、h的情况类似)。对于多个锚点的情况,分类层cls和回归层输出分别由{pi}和{ti}组成,将归一化分类损失函数LNCLS、归一化回归损失函数LNREG和总体加权损失函数L分别定义为:
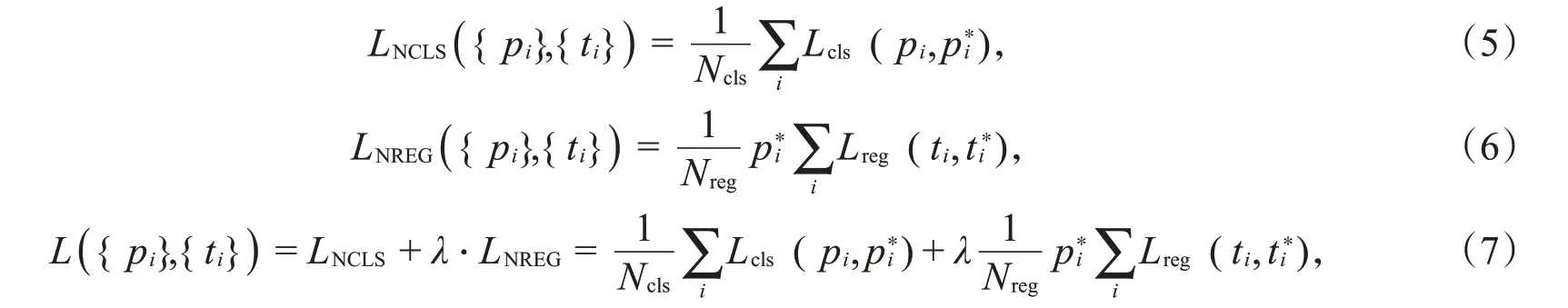
其中,Ncls和Nreg分别用来归一化分类损失和回归损失,Ncls=256,Nreg=2 400。参数λ用来在LNCLS和LNREG之间加权平衡。默认λ=10,可使LNCLS和LNREG之间的平衡保持在比较合理的水平。
本文采用Softmax分类器加候选框重叠度进行筛选,删除超过候选框重叠度给定阈值的小目标候选框,候选框重叠度

其中a(·)为目标候选框面积,b(·)为目标候选框位置,l和s分别为大、小目标候选框。分子表示的是大目标与小目标候选框的重叠面积,分母表示的是小目标候选框面积。若a(b(l)∩b(s))超过a(b(s))的θ倍,就把符合公式要求的小目标候选框删除。
4 实 验
4.1 实验环境与数据集
实验采用Intel(R)Core(TM)i5-8250U CPU@1.6GHz、8GB内存和NVIDIA GeForce GTX 1050 with Max-Q Design 的硬件环境,框架是TensorFlow,开发语言是python。实验图片采用开源数据集Pascal VOC2012,训练集和测试集的选取比例设置为8∶2,图片类别按相应比例随机分配。实验采用主干网络VGG-16,训练方法首先用ImageNet预训练去初始化RPN,对RPN端到端的区域推荐任务微调,利用上一步预训练的RPN 生成的候选框建议滑动窗口(Sliding window)、感兴趣区域RoI 池化、Full Connection、CLS和REG,再利用Improved Faster R-CNN检测网络初始化RPN训练,微调RPN的独有层,这里的RPN包括RPNS和RPNB,最后保持共享卷积层不变,微调Improved Faster R-CNN的独有层。
4.2 实验结果及分析
实验对比参照了R-CNN、SPPNet、YOLO和SSD等经典且应用广泛的目标检测算法,实验评价指标采用检测速度、平均精度(Average Precision,AP)和平均准确度均值(mean Average Precision,mAP)3 个指标。各算法在VOC2012 上检测速度比较如表1所示。
由表1可以看出,Improved Faster R-CNN检测速度高于R-CNN、SPPNet和Faster R-CNN等,检测速度达4.6帧·s-1。区域卷积网络R-CNN的检测速度较低的原因是在推荐候选框的时候运行在CPU 上,而不是GPU。Improved Faster R-CNN 低于YOLO 的原因是候选框的选择是根据图像的不同尺度分别训练了RPNS和RPNB,故检测速度慢于YOLO。YOLO速度达25.1FPS帧·s-1,优势是在训练过程中简化候选框的生成过程,以牺牲检测精度来提高检测速度。mAP 是预测目标位置以及类别的性能度量标准。各算法在VOC2012上mAP值比较如表1所示。
从表1可以看出Improved Faster R-CNN的平均精度均值优于其他算法,与R-CNN相比提高了18.1%,与SPPNet 相比提高了12.0%,与Fast R-CNN 相比提高了6.9%,与Faster R-CNN 相比提高了10.1%,与YOLO相比提高了30.4%,与SSD 相比提高了29.6%。YOLO的平均准确度均值比较低的原因在于它的网络结构在大尺度图像上的目标检测性能表现较好,对于小尺度图像上的目标检测表现效果不佳。

表1 各算法的检测速度、mAP比较
不同算法在VOC2012 上平均精度AP的比较如图5所示。

图5 不同算法在VOC2012上平均精度AP的比较
由图5可以看出,Improved Faster R-CNN的单一目标类别的AP值优于R-CNN和Faster R-CNN,原因是该算法针对大小尺度不同的目标设置了不同的共享卷积的感兴趣区域RPNS和RPNB,并且在特征提取模块,为了更好地提取不同尺度目标的特征图,设置不同规格的锚点,使用归一化损失函数和归一化分类函数进行区域分类。R-CNN和Fast R-CNN算法的Bottle类和Plant类的平均精度AP低于40%是因为对较小尺度的目标检测精度较低,Faster R-CNN的目标检测效果较R-CNN和Fast R-CNN略好,但对于检测Plant、Bottle和Chair等小类别目标时,其平均精度AP也在50%以下。Improved Faster R-CNN在相同训练下,该算法不仅关注了尺度较大目标的检测,也关注到了小尺度目标的检测,在多尺度目标的检测上有较好的表现力。
5 总结
针对当前目标检测算法存在检测速度慢和面向多尺度目标时检测精度低的不足,提出了一种基于改进区域推荐网络的多尺度目标检测算法,并在Pascal VOC2012数据集上进行了相关实验,实验在特征提取模块设置了不同规格的锚点,对于大目标的特征提取采用较少的锚点,对小尺度目标的特征提取采用较多的锚点来确定预测框的坐标、高度和宽度值,这样可以在图像目标检测过程中,有选择的对输入图像进行大小尺度的目标选择相应的感兴趣区域选取网络,提高算法精度的同时还能提升算法速度。简言之,针对Faster R-CNN依赖耗时的推荐算法,本文提出在卷积层之后分别针对大尺度目标候选区域选择的RPNB和针对小目标候选区域选择的RPNS,利用DOL将需要剔除的小目标候选框删除。在Pascal VOC2012 数据集上的实验表明,Improved Faster R-CNN 在检测速度和检测精度上表现了较好的性能,在目标被遮挡或特征残缺的情况下,目标检测性和目标检测速度仍有很大的进步空间,收敛性和算法的泛化能力还需加强。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
通信电源技术(2021年2期)2021-05-21 02:33:46
计算机工程与科学(2021年4期)2021-05-11 01:59:36
电子技术与软件工程(2020年22期)2021-01-30 05:29:42
数字技术与应用(2020年12期)2021-01-22 13:40:40
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
移动通信(2020年5期)2020-06-08 15:39:51
火力与指挥控制(2018年3期)2018-04-19 11:43:39
太空探索(2016年5期)2016-07-12 15:17:55
