
基于机器学习的软件运行缺陷检测方法研究
2021-06-27 03:25吕静贤吴子辰王晨飞
电子设计工程 2021年12期
吕静贤,韩 维,吴子辰,王晨飞,徐 胤
(1.国家电网有限公司客户服务中心信息运维中心,天津 300300;2.国网江苏省电力有限公司信息通信分公司,江苏 南京 210009)
针对软件运行缺陷检测方法的研究,传统方法采用一种基于秩和检验的算法,该算法首先收集训练集和检测样本集的特征信息,分析出不同特征间的差异,并在开放源码系统中进行实验,由分布特征得到的相似性权重与不对称误分类的代价密切相关[1]。通过效应值A-统计检验来评价检测程度,评价显著性检验采用Wilcoxon 秩和检验方法,由检验结果可知,该方法检测变量在目标工程上的分布差异较大,无法达到较高的检测精度[2]。使用静态软件缺陷检测方法时,先根据不同实际应用场景设定软件模块的粒度,并从已标记的软件历史仓库中提取出相应的实例;其次,基于相关信息提取并分析软件开发过程和软件源代码的特征,设计一种能有效反映软件缺陷属性的缺陷测量仪,利用缺陷测量仪设计一组软件,并构造一组软件缺陷检测数据;最后,利用预处理方法构造缺陷检测数据集,并在应用阶段进行测试。
针对不同的应用场景,上述方法受数据集噪声影响较大,检测精度较低。为解决传统方法中存在的问题,提出了一种基于机器学习的软件运行缺陷检测方法。
1 软件运行缺陷联合表示分类
软件运行缺陷联合表示分类需先对无缺陷训练数据集进行采样,以构建类别平衡训练数据[3];然后通过联合表示法构建基于联合表示分类的学习器,获取样本数据;最后,设计分类流程[4]。
1)采样
构建不同度量元特征向量最近邻图,在两个度量元特征向量中增加一条结点变换曲线,计算邻图中的权重矩阵:

式(1)中,ai、aj分别表示两个度量元特征向量;λ表示常量[5]。通过权重矩阵可构建一个数据空间局部结构,利用该权重估计无缺陷训练数据集中候选软件局部保留能力,只有少量度量元特征选入新构建的平衡训练集中,使采集样本平衡化[6]。
2)分类
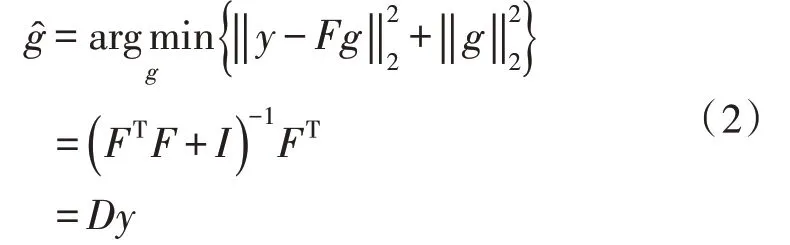
式(2)中,‖y-Fg‖2表示类残差[7-8]。令:
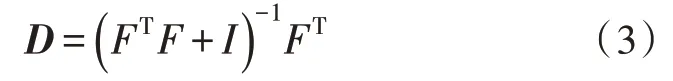
式(3)表示联合投影矩阵,由于D独立于y,所以可将其作为一个投影矩阵计算出来[9]。由于类残差具有一定的鉴别能力,因此可计算每个类的正则化残差值:

根据不同类的正则化残差值,可将软件缺陷样本分配到最小正则化残差值所对应的类[10-12]。
2 软件运行缺陷检测
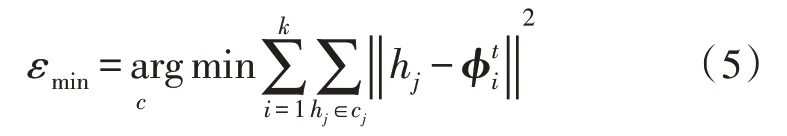
采用施瓦茨信息准则:
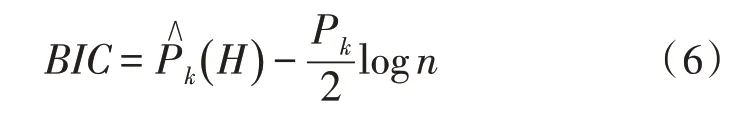
聚类是在全局范围内搜索的,具有良好性能,但对数据噪声较敏感,如果数据存在噪声,则将导致聚类不合理[16]。
数据集中所有样本都是0~1 之间的模糊数值,属于不同聚类形式,最终优化目标函数为:

其赋值计算公式为:
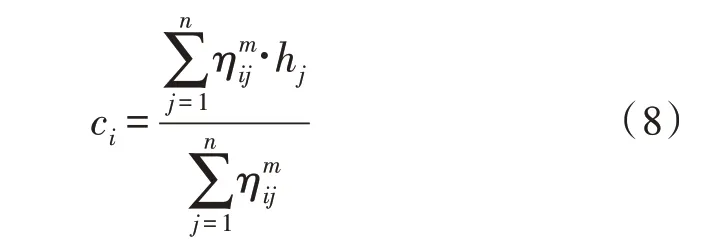
更新计算公式为:
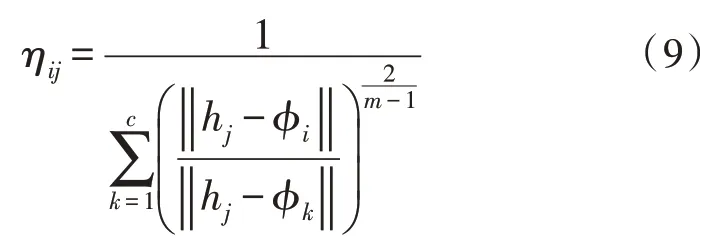
为了消除依赖,将所有有缺陷模块作为异常情况进行处理,如果所有属性都小于其相对应的阈值,则该软件模块是无缺陷的;反之,如果所有属性都大于相对应阈值,那么该软件模块是有缺陷的[17-18]。
3 实验分析
为了验证所提方法的有效性,进行了对比实验。所研究的基于机器学习的软件运行缺陷检测方法使用Python 语言来实现,方法中涉及的来源包括baksmali.jar、androguard。在检测方法有效性时,对现实软件中收到的800 个非恶意程序进行检测。实验系统主机内存为4 GB,处理器型号为Intel Core i5-2400,开发环境为Ubuntu 15.10。
3.1 评价指标
以表1 所示分类检测结果作为评价指标。

表1 评价指标
真正例与总例的比值即为查准率,计算公式为:

检测总例与正例比值为查全率,计算公式为:
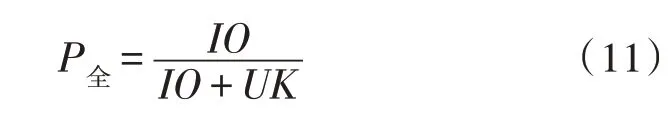
3.2 实验数据集
使用10 个开源数据集,分别为Ar1~5、JEdit4.0、JEdit4.2、JEdit4.3、Ant1.7、Tomcat6.0。这些数据来自于某家白色家电制造商嵌入式软件,其中包含了30维向量,数据集中的软件实体是否存在缺陷类别是已知的。在对这些数据集分析的基础上,降低软件实体特征集维数,确定相关软件度量。表2 描述了实验过程中使用的数据集。
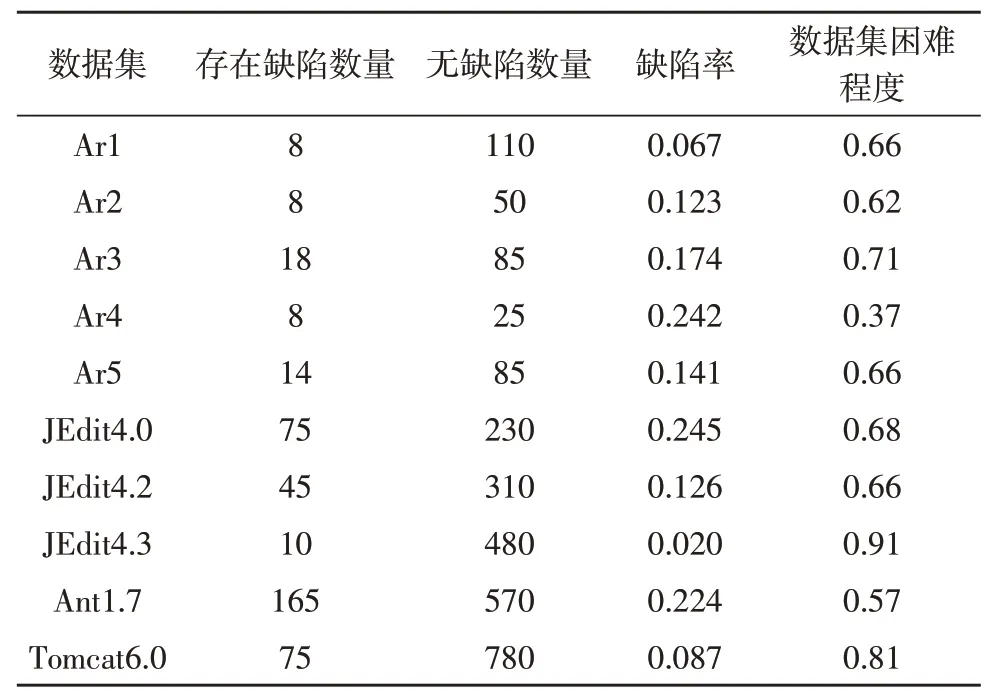
表2 实验过程中使用的数据集
数据集困难程度是衡量数据集分类任务的一个指标,当缺陷数据集分类难度高时,区分存在缺陷和无缺陷软件实体更难。由表2 可看出,所有数据集都是不平衡的,存在缺陷实例数量要小于无缺陷实体数量。从缺陷分类角度分析,JEdit4.3 和Tomcat6.0 是分类最难的数据集,由于其难度较高,因此,在数据集中所占比例较小。
3.3 实验结果与分析
对包含所有数据集的每一对特征进行检查,检查结果如图1 所示。
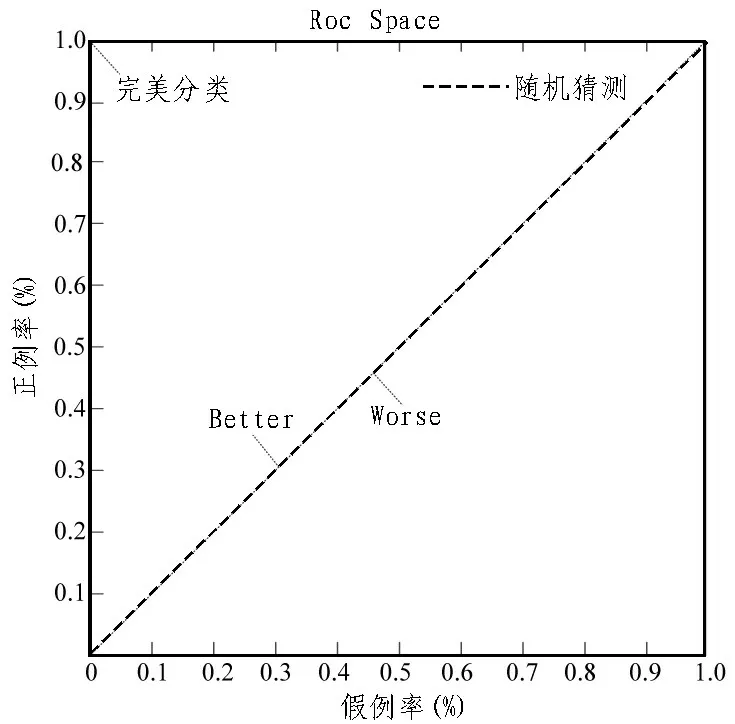
图1 AUC曲线
该曲线经过(0,0)、(1,1)这两个点时,AUC 值是被曲线包围的下方面积,AUC 值越大,数据属性就越稳定。由曲线可确定软件度量之间的依赖关系,得到p-values(1%×1%)都小于0.000 1,从而在显著性水平为0.01(检验要求较高时,要求显著性水平小于0.01)时,确定不同缺陷特征统计的依赖关系。
对于真正例、假正例、假负例、真负例、查准率、查全率进行分析,结果如表3 所示。
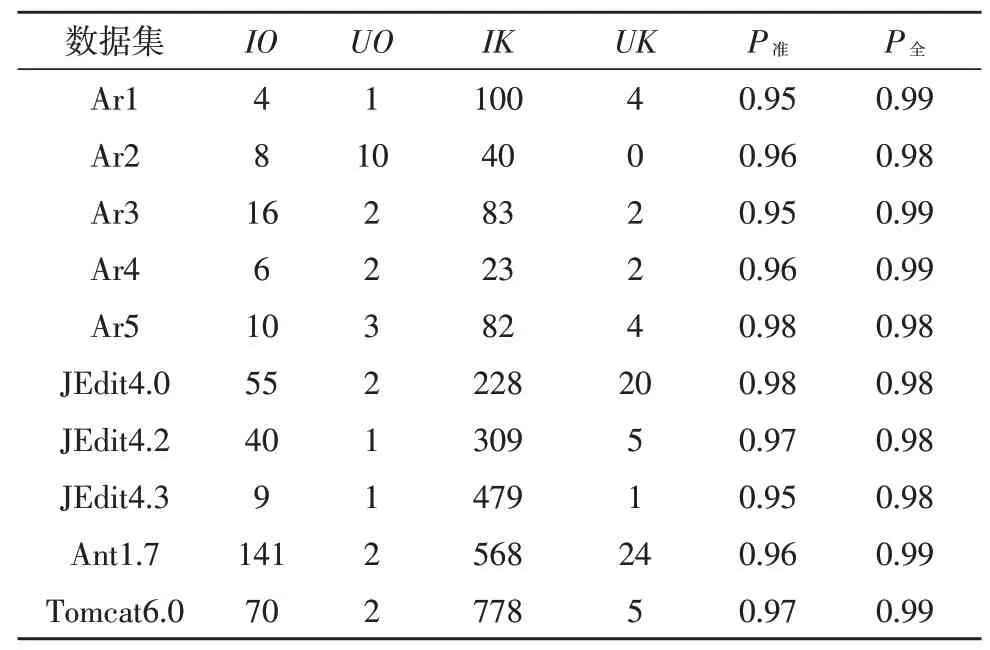
表3 10个数据集检测
在10 个数据集中,查准率和查全率均高于0.95,这说明基于机器学习的软件运行缺陷检测方法性能较好。
4 结束语
基于机器学习的软件运行缺陷检测通过分析历史数据、提取软件特征建立缺陷检测模型,进而挖掘软件中隐藏的缺陷。软件运行缺陷检测主要分为两个部分,首先是数据的处理,该方法主要通过对数据集中影响训练结果的特征进行提取,去除不相关和冗余特征,减少噪声数据对训练结果的影响;其次是模型的训练,在待测测试数据集上应用训练好的模型,使模型能够根据测试数据集检测软件系统中的缺陷。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
网络安全与数据管理(2022年3期)2022-05-23
数学年刊A辑(中文版)(2022年4期)2022-02-16
数学小灵通(1-2年级)(2021年4期)2021-06-09
北京航空航天大学学报(2020年10期)2020-11-14
数学年刊A辑(中文版)(2019年3期)2019-10-08
自动化学报(2019年6期)2019-07-23
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
