
巧用Python自制“词云”图
2021-06-25 07:46牟晓东
电脑报 2021年2期
牟晓东
所谓的“词云”图,指的是通过“关键词(KeyWord)渲染”的方式对高频关键词进行视觉凸显强调的图片,将绝大多数的低频文本信息进行了过滤,浏览者可以在短短几秒的时间内获得文章的最关键信息——“一图胜千文”。目前在互联网上有网站提供在线词云图的生成服务,用户只需将自己的文本内容粘贴上传,服务器很快就会生成并返回一张词云图(有的还提供有各种个性化形状)。其實,我们在本地通过Python编程也能够比较方便地制作出词云图。
1.jieba和wordcloud等库模块的安装准备工作
Python之所以功能强大,是与其丰富的标准库和第三方库的支持分不开的。想要进行词云图的制作,除了常规的numpy科学计算和PIL图像库之外,还需要在编写程序前进行jieba和wordcloud库模块的安装,操作方法是在命令行模式中分别输入命令“pip install jieba”和“pip install wordcloud”。如果无法安装成功(默认的国外更新源经常会因速度不稳而导致安装失败),建议更换安装源为国内的清华或是阿里云等镜像。

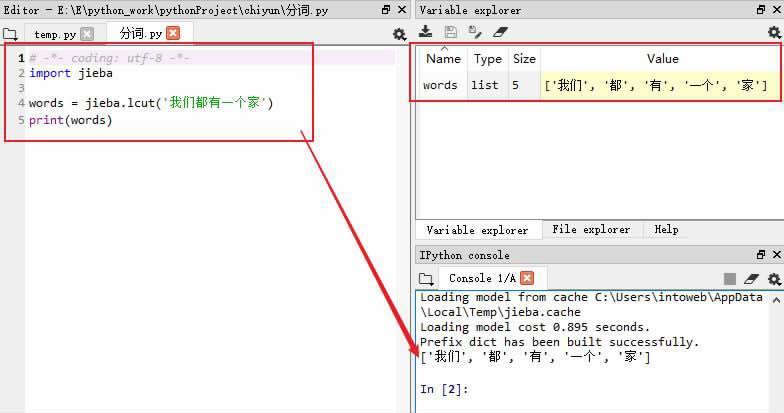
jieba模块是一个专门用于中文(也支持英文)分词的Python库模块,即将文本内容以单个词为单元进行“断句”,可以使用其中的jieba.lcut()进行分词并将结果保存于列表中。比如:“words = jieba.lcut(‘我们都有一个家)”和“print(words)”两行语句,执行后就会将“我们都有一个家”分解成“我们”、“都”、“有”、“一个”和“家”共五个词,保存在words列表中打印输出(如图2)。
2.提取高频词
我们以分析《三国演义》中著名的“火烧赤壁”片段为例(从第60章“诸葛亮舌战群儒”到第70章“诸葛亮智算华容”),将文本内容从网络上复制粘贴到本地,保存为文本文件“火烧赤壁.txt”。
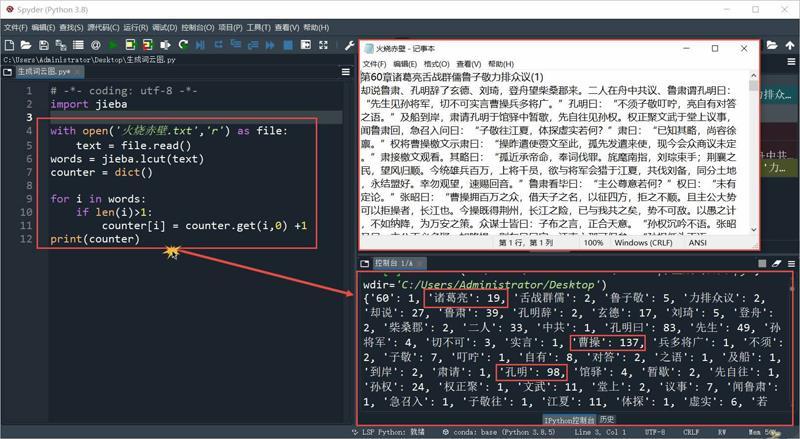
首先使用“import jieba”命令将jieba库模块导入,接着使用“with open(‘火烧赤壁.txt,‘r) as file:”将准备好的文本文件以只读形式打开,并且作为file文件对象;“text = file.read()”:建立text变量,赋值为file文件对象读取“火烧赤壁.txt”文件的所有内容;“words = jieba.lcut(text)”:使用jieba.lcut()将“断句”后生成的各分词内容保存至words变量中;“counter = dict()”:使用dict()建立一个名为counter的空字典,准备存放各分词内容及对应的出现次数;然后使用for循环在words中进行遍历:如果分词的长度大于1(if len(i)>1:),则进行“计数”(counter[i] = counter.get(i,0) +1),这样可以将“的”、“和”、“了”等出现频率极高的单个分词进行“过滤”;最后使用“print(counter)”将counter字典中的键(Keys)和值(Values)进行输出,运行程序——“诸葛亮”:19、“孔明”:98、“曹操”:137等等(如图3)。此时,我们已经得到了“火烧赤壁”中除了单个字之外的所有分词内容及出现次数,准备再借助wordcloud库模块进行词云图的生成。
3.渲染生成常规的词云图
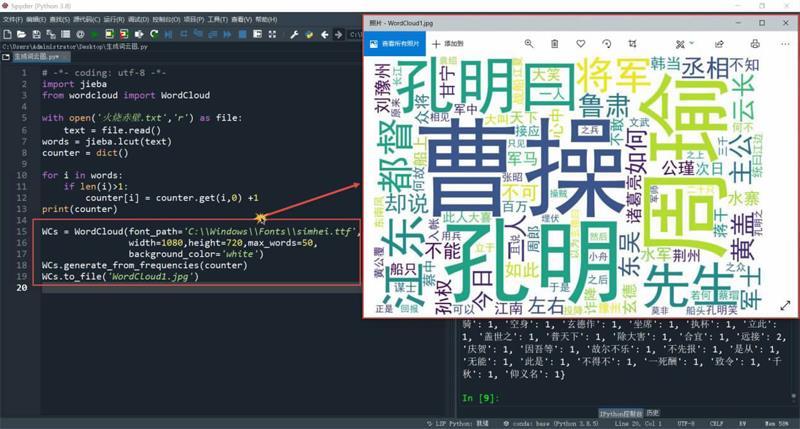
在程序开始部分补充“from wordcloud import WordCloud”,意思是从wordcloud中导入WordCloud;建立WCs变量,使用WordCloud为其赋值:“WCs = WordCloud(font_path=‘C:\\Windows\\Fonts\\simhei.ttf, width=1080,height =720,max_words=50, background_color =‘white)”,其中的“font_path”部分是指定词云图生成时各分词的字体设置,width和height是指定生成词云图的大小为宽1080、高720,max_words是指定从counter字典中取出现频率最高的前50个分词,background_color是指定词云图的背景是白色;“WCs.generate_from_frequencies(counter)”和“WCs.to_file(‘WordCloud1.jpg)”负责将counter字典中前50个出现频率最高的分词取出并渲染生成为WordCloud1.jpg词云图片文件。
运行程序,在同级目录中很快就生成了WordCloud1.jpg词云图,出现频率越高的分词,字就越大,比如“曹操”、“周瑜”、“孔明”(如图4)。
4.改进效果
观察WordCloud1.jpg词云图,不难发现其中像“孔明曰”、“却说”、“不可”、“次日”和“一人”等分词虽然出现的频率较高,但其內容出现在词云中并不能代表原文的关键信息,这就需要像处理单个字那样将这种分词进行人工过滤。还有,这种方形的词云图在展示时的视觉冲击度稍显单薄,是否可以将它做成诸葛亮手中的“羽扇”形状的词云图呢?
改进一:对过滤列表filter_list进行遍历
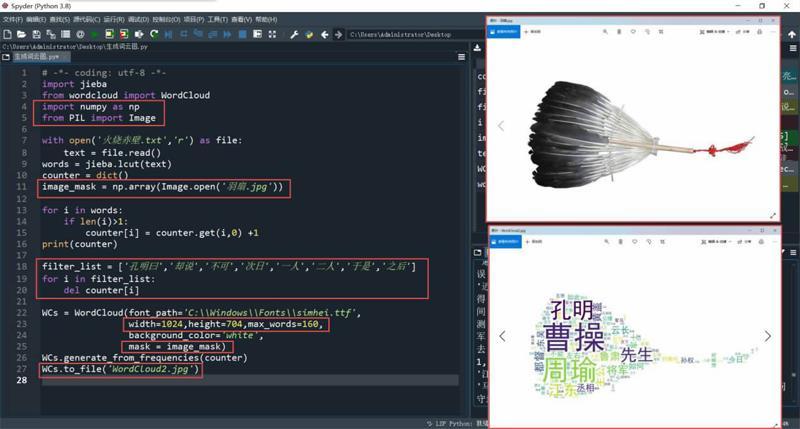
建立列表“filter_list”,为其赋值为“[‘孔明曰,‘却说,‘不可,‘次日,‘一人,‘二人,‘于是,‘之后]”,即将所有待过滤的高频分词作为其中的元素;接着使用for循环对counter字典进行遍历,将字典中保存有filter_list列表各元素的键和值均删除:“del counter[i]”。
改进二:个性化词云图轮廓
从网上搜索并下载一张羽扇图“羽扇.jpg”,要求背景为纯白(用PS处理);然后在程序开始添加“import numpy as np”和“from PIL import Image”,将numpy及PIL库模块中的Image导入;“image_mask = np.array(Image.open(‘羽扇.jpg))”:建立image_mask变量,赋值为先通过Image.open()打开的“羽扇.jpg”、再经numpy的np.array()矩阵转换后的值,这个值就是一个羽扇的轮廓;接着仍是在“WCs = WordCloud”中进行参数添加:“mask = image_mask”,指定词云图的“蒙版”mask,赋值为image_mask;接着,根据下载的“羽扇.jpg”图片文件的尺寸大小,将width和height参数分别设置为1024和704(width=1024,height=704);同时,为了保证最终生成的词云图各分词的紧密分布效果,可以在此将关键词的最大显示数量由之前的50修改为160(max_words=160);最后记得在“WCs.to_file”中将生成的词云图文件名设置为“WordCloud2.jpg”,防止将第一次生成的词云图覆盖。
两处改进修改完成之后,再次运行程序,生成了一张新的词云图,不仅之前的“不可”、“次日”和“一人”等高频无效分词消失了,而且形状也由中规中矩的形状变成了“羽扇”蒙版式(如图5)。
通过Python编程,我们可以将自己喜欢的整部文学作品(或是某篇专业论文)进行词云图的“私人定制”,效果非常不错,大家不妨一试。
猜你喜欢
安徽文学(2022年4期)2022-04-19
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中学生数理化·高一版(2017年1期)2017-04-25
中学生理科应试(2016年7期)2016-05-14
理科考试研究·高中(2016年9期)2016-05-14
智能制造(2015年9期)2015-10-15
小天使·四年级语数英综合(2015年3期)2015-04-20
数学教学(2013年9期)2013-12-12
