
基于排序学习的构件检索方法的研究*
2021-06-25 09:46:06陈华烨汪海涛
计算机工程与科学 2021年6期
陈华烨,汪海涛,姜 瑛,陈 星
(昆明理工大学信息工程与自动化学院,云南 昆明 650500)
1 引言
随着软件复用技术的快速发展,通过构件进行软件开发的方法已经成为了广大软件开发人员的主流开发手段。目前对构件的最新定义为在软件系统中构件具有独立功能,并且可以通过遵循相同接口规范来进行连接,从而实现复用。而实现复用最大的依赖对象是构件库,因此,构件库管理问题已成为构件技术中的研究热点。对构件进行描述和检索的方法很多,目前主流的构件描述方法都是采用基于特征或者XML的刻面描述方法[1]。然而,基于特征的方法缺少对特征模型组织框架的详细研究和解释,这在一定程度上导致了特征模型的冗余和混乱。针对通过特征模型产生的多维空间的向量,本文提出了一个使用潜在语义分析[2]对多维空间进行降维的方法,在去除了原始向量空间中“噪音”问题的同时,还凸显了文本的语义特征。
近年来,排序学习方法的出现受到了越来越多的研究者关注,其优点是:结合并优化了大量的排序特征,同时自动进行参数的学习,最终得到一个高效精准的排序模型。并且此方法已很好地应用于信息检索的检索模型中[3]。在信息检索中排序学习的训练实例是用户的特征标签,所以更多复杂的特征被应用到检索中,比如可通过网页的PageRank值、查询和文档匹配的单词个数、网页URL链接地址长度等特征来供排序模型进行训练。通过研究发现,目前具有代表性的构件检索技术主要集中于基于信息科学的构件检索技术,比如基于刻面的构件检索方法[4]、基于本体的构件检索方法[5]和基于规约描述的构件检索方法等,但构件检索在人工智能中的研究并不多。所以,本文通过研究机器学习中的排序学习方法发现,排序学习不仅可以用于信息检索,其特点及优势也适用于构件检索。因此,本文提出一种构件检索方法,以进行基于排序学习的构件检索方面的研究。
2 主要研究内容
传统的检索模型是依靠人工标注来拟合排序公式,并通过大量的实验来确定模型参数。而排序学习的方法与此不同,排序学习只需要提供训练数据给排序模型,排序模型使用训练数据和排序学习方法自动学习获得一个合理的排序模型,通过训练好的排序模型实现检索。排序模型的实现分为3个步骤:标注训练数据、文档特征抽取和训练排序模型。
在排序学习中,输入是查询和一系列标注好相关性的构件,每个构件由若干特征构成,所以每个构件进入排序学习模型之前先将其转换成特征向量,具体的构件特征将在下文展开。在信息检索中是通过利用用户点击记录来模拟人工标注机制得到标注训练数据[6]。本文先将构件转换成构件特征向量空间,将用向量空间模型表示的特征通过潜在语义分析映射到低维的空间中,这个映射是通过对构件-特征矩阵进行奇异值分解来实现的。然后通过余弦相似度计算来得到标注构件训练数据集。
在确定了构件的训练数据后,将构件转换为〈x,y〉的形式,x为构件的特征向量,y为特征向量对应的标注好的相关性得分,这样就形成了一个具体的构件训练实例。得到构件的训练实例后,通过训练数据及排序学习中的Listwise方法来训练模型的参数,从而训练出最优构件排序模型。在构件检索中,可以使用这个构件排序模型根据查询对构件库中构件的特征进行打分,得到检索结果。利用排序学习的优势改进构件检索方法,从而得到高效准确的构件检索方法。本文所提方法的整体框架如图1和图2所示。
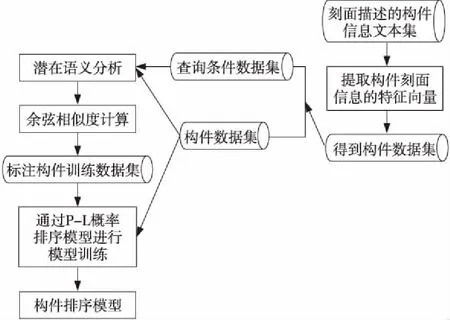
Figure 1 Flow chart of component scheduling model training

Figure 2 Flow chart of component retrieval system
3 构件相似度计算
本文采用刻面描述的方法,将刻面分为功能语义刻面和非功能语义刻面对构件进行全面描述。刻面分类方案需要遵循4个准则:全面性、一致性、刻面正交和精简原则[7]。基于以上准则参考3C模型、北大青鸟构件模型[8],选定以下3个刻面:功能刻面、环境刻面和性能刻面,其中功能刻面属于功能语义刻面,环境刻面和性能刻面属于非功能语义刻面。这3个刻面由它们的子刻面构成,每个刻面相互无影响,任意2个刻面之间是相互正交的,其术语之间也是相互正交的,本文所用刻面可以描述任意一个构件。具体刻面如图3所示。

Figure 3 Detailed description of three facets
功能语义刻面描述了构件的详细功能及其应用领域,如表1中的构件描述信息,出现的形式是一些对构件功能和领域进行描述的具有语义逻辑的自然语言文本段落。传统的刻面描述只是通过有经验的专家对文本段落建立构件的刻面值,但随着构件规模的扩大,越来越多的构件需要分类和检索,人工建立刻面值的方法越来越不现实和不准确。功能语义刻面也是用户查询构件条件的最主要依据。因此,为了减少人为主观因素,本文提出采用word2vec模型来提取构件的功能语义刻面特征,利用word2vec模型对功能语义刻面中的构件描述信息进行处理转换成词向量作为构件特征。而非功能语义刻面是一些特定术语,可应用于多个领域,通过权威文献[7,8]来设定非功能语义刻面的权重作为构件的非功能语义刻面特征。从构件库中获取构件的相关属性,部分构件表示如表1所示。
对每个构件进行刻面描述后,生成构件刻面描述的特征向量空间。每个构件被描述成由特征词组成的特征向量,然而此特征向量空间具有高维性和稀疏性,并且构件与构件间的描述特征通常存在一定的相关性,所以向量空间无法解决同义词和多义词引起的数据集冗余和词性歧义的问题[9]。因此,本文引入潜在语义分析中奇异值分解的方法,从而降低向量空间的稀疏性。将提取构件描述文本的特征向量[10]后生成的数据集称为构件数据集,对构件数据集进行潜在语义分析[6]的具体过程如下所示:
(1)将构件数据集X用成一个v×n的构件-特征矩阵来表示,如式(1)所示:
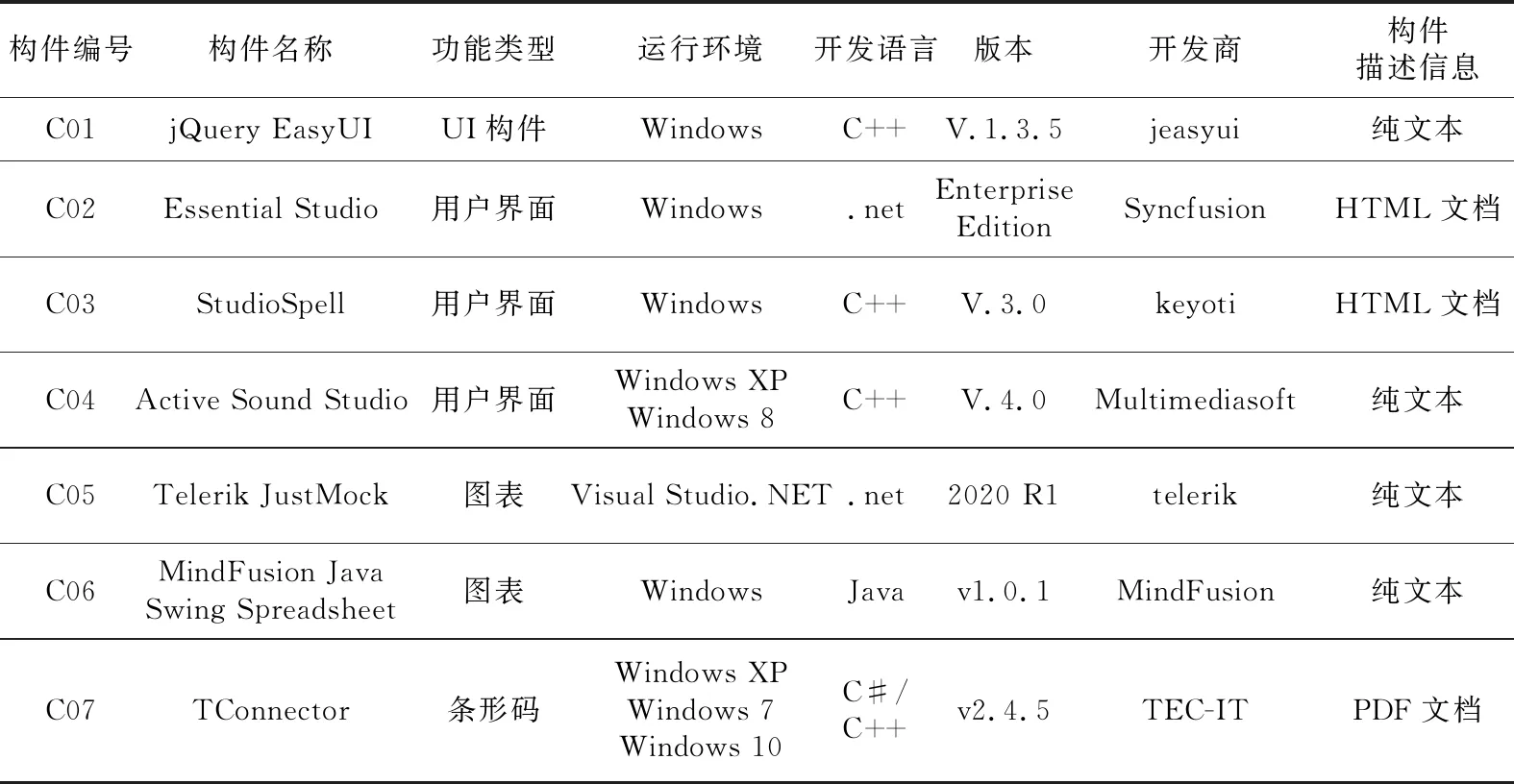
Table 1 List of component-related attributes
A[aij],v≫n,1≤i≤v,1≤j≤n
(1)
其中,矩阵A中v为构件的刻面个数,n为同一个刻面下的不同构件的特征向量个数;aij代表矩阵A中构件的特征值的权重。
(2)根据奇异值分解的性质,将矩阵A进行奇异值分解,可表示为:
A=USVT
(2)
其中,U和VT是左奇异向量和右奇异向量构成的矩阵,两两相互正交;S是奇异值构成的对角矩阵。
(3)将(2)中分解后的矩阵U、S、V进行降维,使用UK、SK、VK重建构件-特征矩阵:
AK=UKSKVKT
(3)
其中,SK表示矩阵S的前K个奇异值,UK、VK表示相应的保留矩阵U、V的前K个列向量。
使用构件数据集中的一部分数据作为查询条件数据集Q={q1,q2,…,qq},其中,q1,q2,…,qq为q个构件,将查询条件数据集也映射到潜在语义空间中。再利用余弦相似度计算查询条件数据集中的每个查询条件与构件数据集中的所有构件的相似度。采用余弦相似度的具体计算过程如下所示:
(1)将查询条件通过潜在语义分析的方式构造查询向量,并映射到语义空间:
(4)
其中,q*是映射到语义空间的查询条件向量。
(2)计算q*和xj的相似度:
(5)
其中,xj是第j个构件的特征向量,k是向量空间的维数,aqm,ajm分别为q*、xj中的第m维权值。
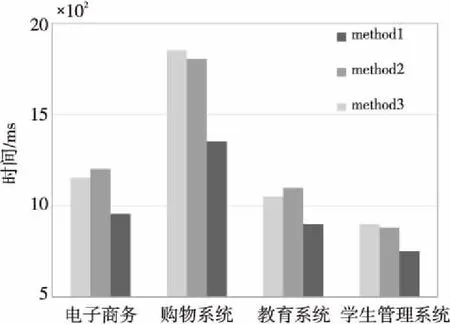
使用潜在语义分析与余弦相似度得到排序学习中准确度高的构件训练数据集,以利于排序模型训练得到高精确性的排序模型。当得到关于查询条件数据集与构件数据集中的相对关系后,将该关系进行标注。例如:若Sim(q*,xj) σ∈Ω,且σ={σq1,σq2,…,σqi},1 (6) 其包含T个独立查询条件数据集,Ω为构件数据集的全排序集合。 常见的排序学习方法分为3种,即逐点方法(Pointwise Approach)、成对方法(Pairwise Approach)和列表方法(Listwise Approach)[11]。其中,Pointwise方法将训练集中每一个文档视为一个训练实例;Pairwise方法将同一个査询的搜索结果中任意2个文档对作为一个训练实例;而本文采用的Listwise方法是将每一个查询的所有搜索结果列表整体作为一个训练实例[8]。 本文提出的构件排序学习模型,使用Listwise方法把训练的样本空间定义为对构件数据集的所有可能的排列,而每个排列出现的概率是在构件特征选择过程中对构件特征的打分决定的,所以可以合理地使用概率模型定义一个构件排序之后任意排序所出现的概率。因此,本文使用P-L(Plackett-Luce)概率排序模型[12]来训练构件排序模型,通过Listwise方法对P-L模型构造排序模型的损失函数,同时,通过增加次要函数对预测的特征得分进行约束,并将最大似然估计MM(Minorize-Maximization)算法用于P-L模型的参数估计,从而提高排序性能,得到最优构件排序模型。 Plackett和Luce提出的P-L模型是一种典型的基于分数的概率排序模型,本文采用Plackett-Luce概率排序模型进行模型训练。而P-L模型的另一个特点是可以处理训练实例的不完整信息的排序。 (7) 其中,M是评分向量的个数。 构件训练数据集并不是具有完整构件信息的排序,构件与查询条件相似度阈值的设置去除了相似度太低的构件排序信息。但是,P-L模型可以处理不完整信息的排序,基于式(7)表示如下: Boys enjoy rugby,but the most popular sport for girls is netball(无挡板篮球).It is similar(相似的)to basketball,but players don’t run with the ball. (8) 其中,k表示构件训练数据的排序构件数量,由式(8)可以看出,构件的排序数量是影响其概率分布的唯一要素。 通过Listwise方法来定义关于真实排序y(i)和预测排序的损失函数[13],并通过训练损失最小化来学习排序函数的参数。将所有构件训练数据集的可能性损失之和最小化,即可将似然损失函数定义如式(9)所示: l(〈w,x(i)〉,y(i))=-logP(y(i)|x(i),w) (9) 其中,logP(y(i)|x(i),w)可以通过P-L模型计算得到,所以,根据P-L模型得到以下关系: (10) 其中,y(i)表示真实排序,〈w,x(i)〉为u的分解向量,x(i)为构件训练数据集中的构件排序,R为构件训练数据集中每个构件排序中的排序数量,x(i,y-1(l))为当排序在y-1(l)时x(i)的排序,l和k′为计数变量,最大似然估计由最大化对数似然函数给出: (11) 为了拟合L(u),本文采用不等式来构造次要函数: -lna≥1-lna-a/b (12) 其中,向量a和b中各元素都大于0。使用w和w(t)来替换a和b,并采用MM 算法来求解P-L模型的最大似然估计参数[14],通过每次迭代最大化一个初始函数求解式(12)。通过构造次要函数改进P-L模型的对数似然函数,得到以下改进的对数似然函数: Qt(w|w(t))= (13) (14) 可以由排序空间Ω上的概率分布P(·|u*)得到与查询文本相关的预测排序,即具有最高后验概率的排序: x*∈arg maxx∈Ωp(x|u*) (15) 算法1构件排序模型 输入:查询条件集qi,构件数据集X。 输出:最优排序x*。 步骤1使用刻面描述方法得到构件信息文本集,通过word2vec模型和权重设定来提取构件信息文本集的特征向量作为构件数据集,将其作为输入数据,对构件数据集生成的特征向量矩阵使用奇异值分解构造潜在语义空间。 步骤5使用MM算法对改进的对数似然函数Qt(w|w(t))进行迭代更新参数wt+1,直到得到最大化参数w*,最后通过得到的参数w*按降序的关系对构件进行排序,得到最优构件排序模型。 实验分为2步,第1步是构件排序模型训练,使用潜在语义分析与余弦相似度得到的标注构件训练数据集,结合构件数据集通过P-L概率排序模型进行排序模型训练。第2步是实现构件检索系统,以构件排序模型为核心开发实现一个构件检索系统。 模型训练所用数据集为RepoReapers公开数据集,其中包含100多万条离线的GitHub数据镜像。本文在RepoReapers上随机收集了大约10万条构件数据集,采用word2vec模型将功能语义刻面的构件描述信息文本转换成词向量,所用的语料库是中文维基百科与构件训练数据中的描述信息语料。对每个构件描述信息文本的输入长度进行处理,设置输入序列长度为500,长度小于500的序列补零。通过word2vec模型和权重设定提取构件的特征向量作为构件数据集。设置数据集上的五折交叉验证范围,将构件数据集分为5个部分,在每次实验中,3/5用于训练,1/5用于验证,1/5用于测试,并将3/5的训练数据中的1/4的数据作为查询条件数据集。进行余弦相似度计算时设置相似度阈值为Ths。 本文使用改进的P-L模型(model1)、Mallows模型[15](model2)和广义线性模型[16](model3)进行性能对比。采用NDCG(Normalized Discounted Cumulative Gain)作为评估指标。NDCG是用来衡量排序质量的指标,实验设置排序列表中序列k分别为{5,10,15,20}的值进行评估。 该实验基于构件排序模型实现了一个构件检索系统,其开发环境为CPU:i7-9750H 2.60 GHz,操作系统为Windows 10,开发语言为Python,数据库使用MySQL;开发工具是PyCHarm,实验数据从CodeProject、GitHub网站和中国BIM构件库网上下载相关构件285个,其中包含以下几个领域:教育系统76个、网购系统82个、电子商务43个和高校学生管理系统84个。将285个构件通过刻面进行描述后入库,利用Python进行文本分词及关键字提取,采用TF-IDF方法计算构件描述文本中关键词权重。 实验中,主要使用基于刻面的构件检索方法(method1)、基于本体的构件检索方法(method2)和本文提出的基于排序学习的构件检索方法(method3)进行对比实验,评估标准主要是查全率(查全率=检索到的相关构件数/所有相关构件数)、查准率(查准率=检索到的相关构件数/检索到的构件数)[17]和检索效率。 对各个模型的排序准确度评估如图4所示,由图4可以看出,本文提出的排序模型在构件中的使用是有效的,采用3种概率模型对构件训练实例进行排序评估。图4中,Mallows模型(model2)与改进的P-L模型(model1)具有一定的竞争力。因为Mallows模型善于解决构件完整信息的模型分布,而P-L模型可以很好地处理不完整的排序信息,所以当设置相似度阈值后,出现不完整的标注信息时,P-L模型的准确度高于Mallows模型的。广义线性模型(model3)首先对训练数据进行分类,在预测每个构件的类别概率后进行排序,仅使用广义线性模型不能很好地处理复杂决策边界问题,因为线性方法的强偏差妨碍了数据的良好分离。因此,model3的排序性能低于model1和model2的。 Figure 4 Comparison of NDCG sorting accuracy 在大量实验的基础之上,本文将几个领域内的构件进行多次测试检索实验并与传统检索方法对比,综合数据统计检索结果如图5~图7所示。 Figure 5 Comparison of the recall Figure 6 Comparison of precision 从图5和图6可以看出,本文提出的基于排序学习的构件检索方法(method3)的查全率和查准率高于传统的基于刻面的构件检索方法(method1)和基于本体的构件检索方法(method2)。因为相比于基于刻面的构件检索方法和基于本体的构件检索方法,本文采用的潜在语义分析弥补了刻面描述的单一性,有效地改善了一词多义或者词性发生歧义的情况。在排序学习阶段,通过余弦相似度计算得到了高准确度的构件训练数据,在排序模型训练时训练数据集的数据越准确,训练出的排序模型的准确度就越高,所以使用排序模型也提高了构件检索的查准率。当构件检索系统根据用户查询条件进行检索时,每个领域的所有构件在通过构件排序模型时,都需要经过特征提取从而与查询相关的特征进行概率预测,因此也提高了构件检索的查全率。 从图7可以看出,本文提出的方法在时间性能上也优于传统的2个方法。将训练好的模型应用于构件检索,实现了训练模型与使用模型的分离,构件检索时使用训练好的模型不需要再次进行复杂的相似度比较,所以相对于传统的方法降低了时间复杂度,从而提高了检索效率。 Figure 7 Comparison of retrieval efficiency 本文提出了一种基于排序学习的构件检索方法,实验结果显示,本文将排序学习算法应用于构件检索的方法具有明显的优越性。在排序模型训练中,使用潜在语义分析和余弦相似度来为排序学习提供准确的标注信息;在排序学习中,为了减少模型估计时存在的偏差,将P-L模型进行改进并采用最大似然估计的方法补充标准拟合模型,进一步提高了排序模型的准确度。在构件检索实验中,用户查询条件直接通过排序模型进行构件检索,将所有构件都加入排序,与传统的基于刻面的构件检索方法和基于本体的构件检索方法相比,本文所提方法提高了检索的查准率、查全率和效率。 本文方法为构件检索研究提供了新方法,但仍有不足之处需要改进。例如,在得到构件相关性时,可使用现在最新的语义推理方法进行构件相关性判断,这样就不需要使用余弦相似度进行特征向量计算,从而降低得到训练数据的时间复杂度。因此,下一步将对构件的训练数据进行更深层次的研究。
4 基于排序学习的构件检索方法
4.1 排序学习方法
4.2 Plackett-Luce概率排序模型
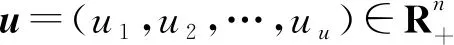

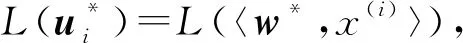
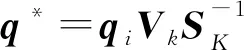

5 实验
5.1 构件排序模型训练
5.2 构件检索系统
5.3 实验结果及分析



6 结束语
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54保定学院学报(2022年2期)2022-04-07 02:26:50中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12科普童话·学霸日记(2020年1期)2020-05-08 16:45:11意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30许昌学院学报(2018年4期)2018-05-02 12:27:37儿童绘本(2018年5期)2018-04-12 16:45:32中华建设(2017年1期)2017-06-07 02:56:14专利代理(2016年1期)2016-05-17 06:14:36
