
Hybrid-随机森林财务危机预警模型研究
2021-06-25 14:18:20张俊涵
软件导刊 2021年6期
张俊涵
(上海工程技术大学数理与统计学院,上海 201620)
0 引言
随着经济全球化,世界各地的经济联系愈发紧密,市场竞争也愈发激烈,增加了企业陷入财务困境的可能性,而遭遇财务困境会使利益相关者蒙受损失,严重情况下会破坏市场环境。企业如果能够建立一个长期有效的财务预警机制,使财务状况刚出现危机时就能被及时发现,随后采取相关举措以避免财务危机,就能够在激烈竞争的市场中生存壮大。因此,利用上市公司公开的财务数据建立财务危机预警模型,对上市公司及其利益相关者预警非常重要。
财务危机预警相关研究有:Kim 等[1]利用bagging 和boosting 方法构建财务危机预警模型,实验结果表明,集成学习方法的预测能力要优于单一模型;温重伟[2]利用3 种不同的核函数构建支持向量机财务危机预警模型,实验结果表明,RBF 核函数的效果最佳,同时还构建了BP 神经网络财务危机预警模型并与之对比,结果证明,虽然在训练集上神经网络表现较好,但在测试集上支持向量机的表现远好于BP 神经网络模型;陈志君[3]以中国通信行业为研究对象,选取3 家被特别处理的公司(ST)和16 家财务正常的公司为研究样本,选取21 个财务指标利用KMO 检验和相关性检验进行筛选,最终得到6 个财务指标,利用逻辑回归算法构建财务危机预警模型,整体准确率达到79%;黄衍[4]将BP 神经网络、随机森林、SVM 支持向量机这3 种模型的分类性能进行比较,结果证明随机森林性能最好;孟杰[5]通过随机森林算法建立财务危机预警模型,与逻辑回归、SVM支持向量机模型、CART 分类树模型和神经网络模型的预测结果进行对比,结果表明随机森林模型预测精度更高;连晓丽[6]利用随机森林算法与Lasso-逻辑回归算法分别建立财务危机预警模型,实验结果表明,随机森林预测能力更胜一筹;游甜[7]将支持向量机与BP_Adaboost、KNN 模型相对比,结果证明支持向量机预测效果更佳;吴睛宇[8]通过主成分分析对初选指标进行降维,然后利用神经网络构建财务危机预警模型,对上市公司财务状况的预测效果良好;周廷炜[9]利用网格寻优算法与支持向量机 相结合对上市公司财务状况进行预测;邓旭东等[10]分别建 立逻辑回归财务危机预警模型与Z-score 模型,实验表明逻辑回归模型的预测正确率要高于Z-score 模型;张培荣[11]利用 因子分析对特征指标进行约简,然后利用Xgboost 与Logistic 分别建立财务危机预警模型,实验结果表明,通过Xgboost 算法建立的财务预警模型预测效果更好;范雍祯[12]分别构建PCA-Cox 模型和BP_Adaboost 模型,实验结果表明,BP_Adaboost 模型的综合正确率优于PCA-Cox 模型;石先兵[13]利用主成分分析方法对指标进行降维,得到4 个主成分因子,将这4 个主成分因子代入支持向量机模型中,实验表明通过主成分分析与支持向量机结合的模型具有良好的预测能力;Xu 等[14]在指标体系中引入非财务指标,通过因子分析进行降维,通过逻辑回归算法分析构建金融危机预警模型,实验结果证明,因子分析与逻辑回归结合构建的模型具有较高的预测正确率;李嘉东[15]利用随机森林构建财务危机预警模型,然后分别构建支持向量机模型、判别分析模型以及Logistic 模型进行对比分析,实证结果表明,随机森林构建的财务预警模型性能要优于其它3 个模型。
以上文献都是直接对比分类器性能的优劣从而确定模型,但是对指标筛选的关注较少。本文将3 种不同特征指标筛选方法分别与随机森林算法相结合,得到3 个不同财务危机预警模型,通过对比这3 个模型的优劣得到与随机森林算法结合的最优特征选择算法,最后将该模型与决策树模型、逻辑回归模型进行对比研究。
1 随机森林
随机森林是Bagging 的一个扩展变体。随机森林正如其名,是由许多棵决策树组成,同时在决策树模型训练过程中加入随机属性。
随机森林是树结构的分类器,由多个决策树集合构成。Θk是独立同分布的随机向量,当输入变量X 确定时,每个元决策树h(x,Θk)都会拥有投票权,通过选取得出最优的分类结果。
随机森林可以分成随机分类森林与随机回归森林这两种类型。随机分类森林应用更加普遍。随机分类森林最终得到的结果通过简单多数投票法得到,公式如下:

h(xm)代表第N 个最终样本的组合分类器结果,其中,I()是示性函数,Y 代表输出变量,hi是单个决策树模型。
2 数据准备
2.1 样本来源
本文将证监会特殊处理带有ST 或ST*帽子的上市公司判定为遭遇了财务困境的公司。样本选取A 股市场2016 年、2017 年、2018 年3 年被证监会特殊处理的上市公司,从国泰安数据库中查询到共计69 家上市公司,将其作为财务危机样本。2016 年有11 家被特殊处理的上市公司,2017 年有22 家被特殊处理的上市公司,2018 年被特殊处理的上市公司有36 家。
财务预警研究关于样本选取的方法主要有3 种:①采取配对抽样的方式进行选取,选取行业相同、规模相近的正常公司进行1∶1 配对;②一般用于非平衡数据,利用重抽样方法扩大ST企业的数量;③适当扩大配对比例,一般选取1∶3 的比例,然后随机抽取,不考虑行业与规模。
上述3 种方法各有千秋,本文研究的是不同特征指标筛选方法选取重要特征的能力,而不同行业企业的重要指标可能会略有不同,且规模不同会对财务指标造成影响,因此本文选择第1 种方法,即选取行业相同,规模相近的正常企业进行一比一配对。
关于数据的选取,公司被特殊处理的当年认定为T 年,选择该公司T-3 年数据。因为证监会是通过T-1 年的财务数据判断该公司是否被ST,所以用T-1 年的数据进行预测无法起到预测作用,而且上市公司连续两年出现亏损会被标记为ST*,因 此本文将采用T-3 年的数据进行预测。
2013 年抽取11 家正常公司,2014 年抽取22 家正常公司,2015 年抽取36 家正常公司,共计69 家正常公司。
2.2 数据筛选原则
有些上市公司在部分特征指标上存在数据缺失情况,对于有数据缺失的公司,如果该公司是正常公司,以行业相同规模相近为前提,尽可能选取数据较为完整的上市公司,如果该公司是被特别处理的公司(ST),由于财务危机的公司数量较少,那么对于缺失的数据就以该指标的平均值进行填充。最终得到138 个样本作为本文实验数据。
2.3 特征指标初选
特征指标的科学性是一个模型能够良好运行的首要条件,所以本文在前人基础上进行指标的初步选择,选取原则如下:在以往相关的文章中出现频率较高且该指标较显著,能够较好解释财务危机。初选特征指标如表1 所示。
2.4 数据处理
利用Python 计算出每个初选特征的各类指标:最大值、最小值、平均值、四分之一分位数、二分之一分位数、四分之三分位数,然后根据这些指标找出数据中的异常值,将异常值用上边缘的值进行替代。

Table 1 Summary of primary indicators表1 初选指标汇总
3 特征筛选
各个财务指标之间一般具有相关性。由于初选的指标较多,可能很多指标并不能很好地解释财务危机现象,所以要进行特征筛选。
本文采取Shuffle、Embedd、Hybrid 这3 种特征选择方法对初选指标体系进行筛选。
3.1 基于Shuffle 的特征选取
Shuffle 的特征筛选原理是基于AUC 指标进行筛选。Shuffle 利用控制变量法,通过控制所有特征指标对应的数据保持不变,选取其中一个特征指标,将该列的所有数据打乱后随机排序,然后查看AUC 是否变化,如果变化就认为该指标重要,保留该指标;反之,如果AUC 没有变化则去除该指标。基于Shuffle 选取出的特征指标如表2 所示。

Table 2 Characteristics of Shuffle screening表2 Shuffle 筛选的特征指标
3.2 基于Embedd 的特征选取
Embedd 特征提取原理主要是根据OOB(Out of Bag)原则。如果某个特征是重要的,那么在此特征的数据分布式中引入一定的噪声,仅对此特征变化之后的数据进行RF训练,则模型性能会有较大变化(较明显地变差);反之,如果某个特征不重要,重新训练后的模型性能变化不会太大。基于Embedd 算法得到的特征指标如表3 所示。
3.3 基于Hybrid 的特征选取
Hybrid 算法进行特征筛选原理主要是基于AUC 进行选取,逐个添加指标后观察AUC 是否变化,如果AUC 发生变化,则说明这个指标是重要的,予以选取;反之,如果AUC 没有发生变化则说明这个指标不重要,予以剔除。基于Hybrid 算法筛选的特征指标如表4 所示。

Table 3 Characteristic indicators selected by Embedd表3 Embedd 选取的特征指标

Table 4 Characteristic indicators selected by Hybrid表4 Hybrid 选取的特征指标
4 模型性能评估
对于分类模型的性能评估一般用混淆矩阵进行考察,以本文正常公司以及ST 公司为例,混淆矩阵可以将其分为4 类:
TP:将ST 公司判断为ST 公司
TN:将正常公司判断为正常公司
FP:将正常公司判断为ST 公司
FN:将ST 公司判断为正常公司
通过混淆矩阵计算出这4 个类别的所有数目,这样就可轻松得出模型分类的准确率。
准确率=正确预测的数目/总数
误分类率=错误预测的数目/总数
正例覆盖率=正确预测的ST 数目/实际ST 数目
正例命中率=正确预测的ST 数目/预测ST 数目
负例的覆盖率=正确预测的非ST 数目/实际非ST 数目
负例命中率=正确预测的非ST 数目/预测非ST 数目
企业利益相关者最重视的指标是正例命中率与正例覆盖率。正例覆盖率指预测到的ST 公司占实际被ST 公司的比例;正例命中率指被ST 企业的管理者发现财务预警时,采取合适的措施能使多大比例的企业摆脱财务危机。
4.1 基于Shuffle 的随机森林
本文随机抽取50% 的样本作为训练集,50%作为测试集,通过测试集的结果对模型性能进行评价,测试集的ROC曲线如图1所示。
从图1 和表5 可以看出,正例命中率为81.82%,正例覆盖率为72.97%,整体正确率为76.81%,AUC 为0.8666。如果根据测试集结果对这些被预测为ST 的企业提前3 年进行预警,那么这些企业通过采取正确措施将有81.82%可以逃离被ST 的命运。
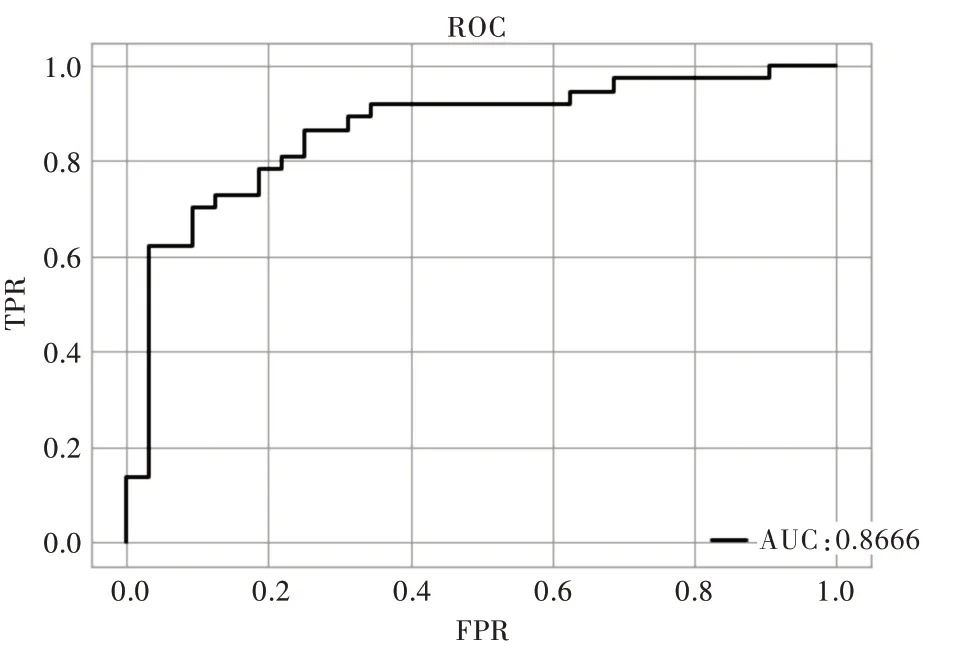
Fig.1 ROC curve based on Shuffle test set图1 基于Shuffle 测试集的ROC 曲线

Table 5 Random forest confusion matrix based on Shuffle表5 基于Shuffle 的随机森林混淆矩阵
4.2 基于Embedd 的随机森林
重复以上步骤,得到的ROC 曲线如图2 所示。从图2和表6 可以看出,根据测试集结果,如果对被预测为ST 的企业提前3 年给予预警信号,采取正确措施的企业将有84.85%可以逃离被ST 的命运。

Fig.2 ROC curve based on Embedd test set图2 基于Embedd 测试集ROC 曲线
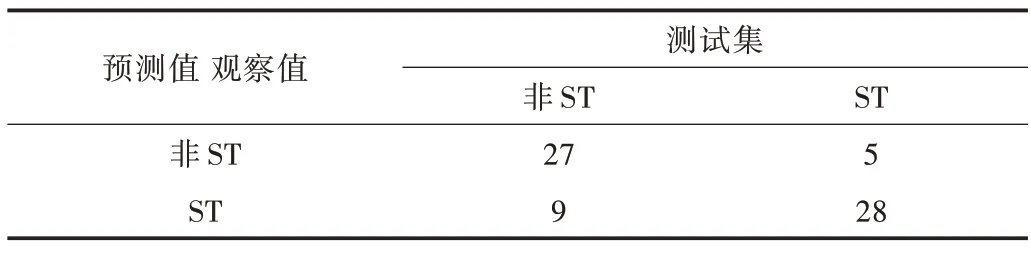
Table 6 Random forest confusion matrix based on Embedd表6 基于Embedd 的随机森林混淆矩阵
4.3 基于Hybrid 的随机森林
将数据代入Hybrid 模型得到ROC 曲线如图3 所示。从图3 和表7 可以看出,根据测试集的结果,如果对被预测为ST 的企业提前3 年给予预警信号,这些企业采取正确措施将有91.18%可以逃离被ST 的命运。
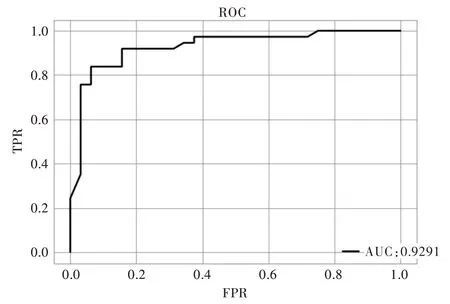
Fig.3 ROC curve based on Hybrid test set图3 基于Hybrid 测试集ROC 曲线
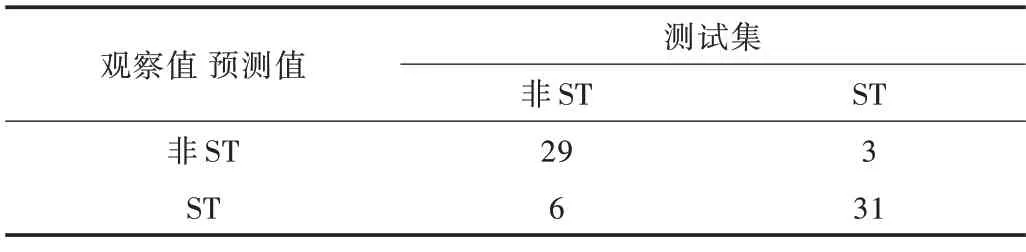
Table 7 Random forest confusion matrix based on Hybrid表7 基于Hybrid 的随机森林混淆矩阵
4.4 三种特征选取方法比较
由表8 可以看出,Hybrid-随机森林模型的正例命中率、正例覆盖率、整体正确率以及AUC 均明显高于Shuffle-随机森林模型与Embedd-随机森林模型。Hybrid-随机森林模型明显要比其他两个模型的分类性能优越。
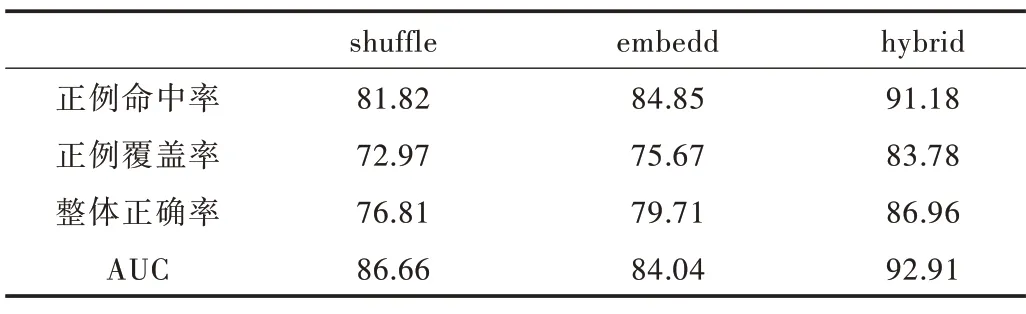
Table 8 Comparison of accuracy rate表8 正确率对比 (%)
因此得出结论:Hybrid 相比Shuffle 和Embedd 更能选取到显著特征,能帮助投资者更好地避免踩雷,帮助企业管理者更早发现企业的问题。
4.5 基于决策树构建财务危机预警模型
在Hybrid 建立特征指标体系基础上,利用该特征指标体系建模,得到基于Hybrid 的决策树模型。由表9 得知,TP 为27,TN 为26,FP 为6,FN 为10,其结果与Shuffle-随机森林模型相同,通过计算可知测试集正例命中率为81.82%,正例覆盖率为72.97%,整体正确率为76.81%。
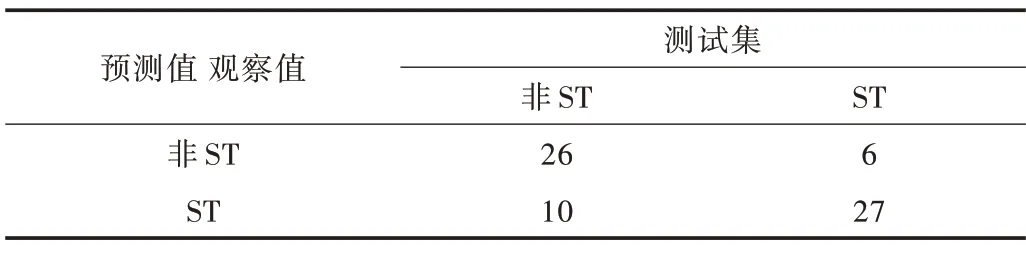
Table 9 Confusion matrix of decision tree model表9 决策树模型的混淆矩阵
4.6 基于逻辑回归构建财务危机预警模型
在利用Hybrid 特征选择算法得到的特征指标体系基础上,利用逻辑回归构建预警模型。
如表10 所示,TP 为20,TN 为22,FP 为13,FN 为14。通过计算可知,测试集的正例命中率为60.61%,正例覆盖率为58.82%,整体正确率为60.87%。
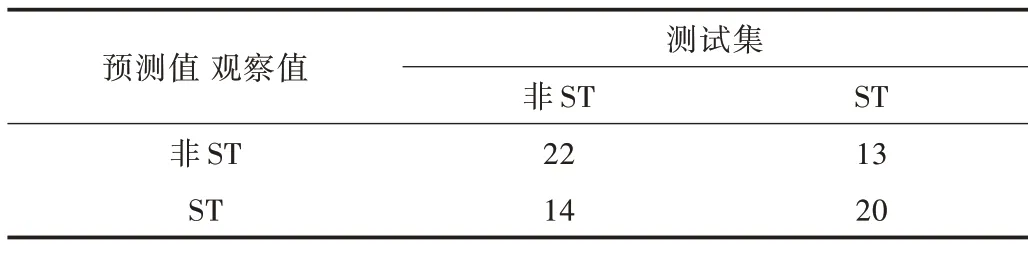
Table 10 Confusion matrix of logistic regression model表10 逻辑回归模型的混淆矩阵
5 结语
A 股上市公司的财务报表中有较多的财务指标,而且各个不同的指标之间具有相互关联的特点。本文运用Shuffle征择算法、Embedd特征选择算法、Hybrid特征选择算法,对初选的特征指标体系进行进一步的筛选,得到了三个特征指标体系并利用随机森林算法分别进行建模,得到三个财务危机预警模型,实验表明,Hybrid 与随机森林结合构建的财务预警模型效果较为优良,然后在Hybrid 建立的特征指标体系的基础上利用决策树算法与逻辑回归算法构建财务危机预警模型,实验表明,随机森林算法构建的财务危机预警模型效果更佳。
Hybrid-随机森林预警模型可以为上市公司进行准确预警,便于上市公司管理者提前制定防范风险的战略措施。投资者可对Hybrid 所约简得到的六个财务指标重点关注,且可利用有限的公开财务数据进行预测,具有一定的实际应用价值。
本文仍存在不足之处,如在开始进行特征指标筛选时是基于前人研究结果与经验初选特征指标体系,没有选入的指标不代表该指标对财务危机没有反应,但又不能将所有指标纳入选择范围,因为过多的变量会对建模分析结果造成影响。未来研究要考虑行业特性,构架一个全面的特征指标初选体系。
猜你喜欢
中小学课堂教学研究(2023年12期)2024-01-05 16:14:43
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
数学教学通讯·小学版(2019年7期)2019-09-09 01:07:24
安顺学院学报(2019年2期)2019-07-04 00:41:44
电子制作(2018年16期)2018-09-26 03:27:06
商周刊(2017年6期)2017-08-22 03:42:49
统计与决策(2017年2期)2017-03-20 15:25:24
通化师范学院学报(2016年11期)2017-01-15 14:02:46
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
新课程·下旬(2016年3期)2016-05-10 08:59:34
