
机器学习在奶牛临床疾病预测中的应用
2021-06-24 01:11:26高志天郑炜缤杨仲涛
动物医学进展 2021年6期
冯 妍,高志天,郑炜缤,杨仲涛,董 强
(1.西北农林科技大学信息工程学院,陕西杨凌 712100;2.西北农林科技大学动物医学院,陕西杨凌 712100)
机器学习(Machine learning,ML)是研究如何使机器通过识别和利用现有知识获取新知识的一门多领域交叉学科。ML可通过学习已有数据,建立一种模型或学习器,对未知的数据进行分析和预测。当今的农业生产会产生大量的数据,利用ML技术分析这些数据并建模将是农业大势所趋[1]。在奶牛业,随着奶牛养殖的精细化和人工成本的增加,仅靠牛场的管理人员无法完成高质量的群体化和个性化管理工作,使ML在奶牛精准育种、群体管理和疾病监测等领域有着广泛的研究和应用前景[2-3]。在这些领域中,利用ML算法学习和训练奶牛疾病的特有风险因素以预测和监测奶牛疾病已成为精准乳业的研究方向[4-6]。应用ML预测奶牛代谢性疾病、乳房炎、传染病、热应激和跛行等疾病已成为国际上的研究热点[5,7-10,4,6],但我国在此领域的研究起步较晚。本文就ML在奶牛临床疾病预测方面的研究做一综述,为我国开展这方面的研究提供参考。
1 研究方法和原理
1.1 ML简介
ML利用数学方法和计算机技术对历史数据进行分析得到规律并构建模型,对未知数据进行预测和分类。建模时,先将预处理好的奶牛数据输入到ML分类器进行训练,然后得到对未知数据进行预测的模型,对预测结果具有较大贡献的特征可作为奶牛患病的潜在特征[11]。这个过程包括数据收集、数据预处理、模型训练、模型选择和结果预测,具体建模流程如图1所示。常用的ML编程语言有Python,R,MATLAB和Octave等,均有处理数据的统计软件包,使分析数据变得容易。
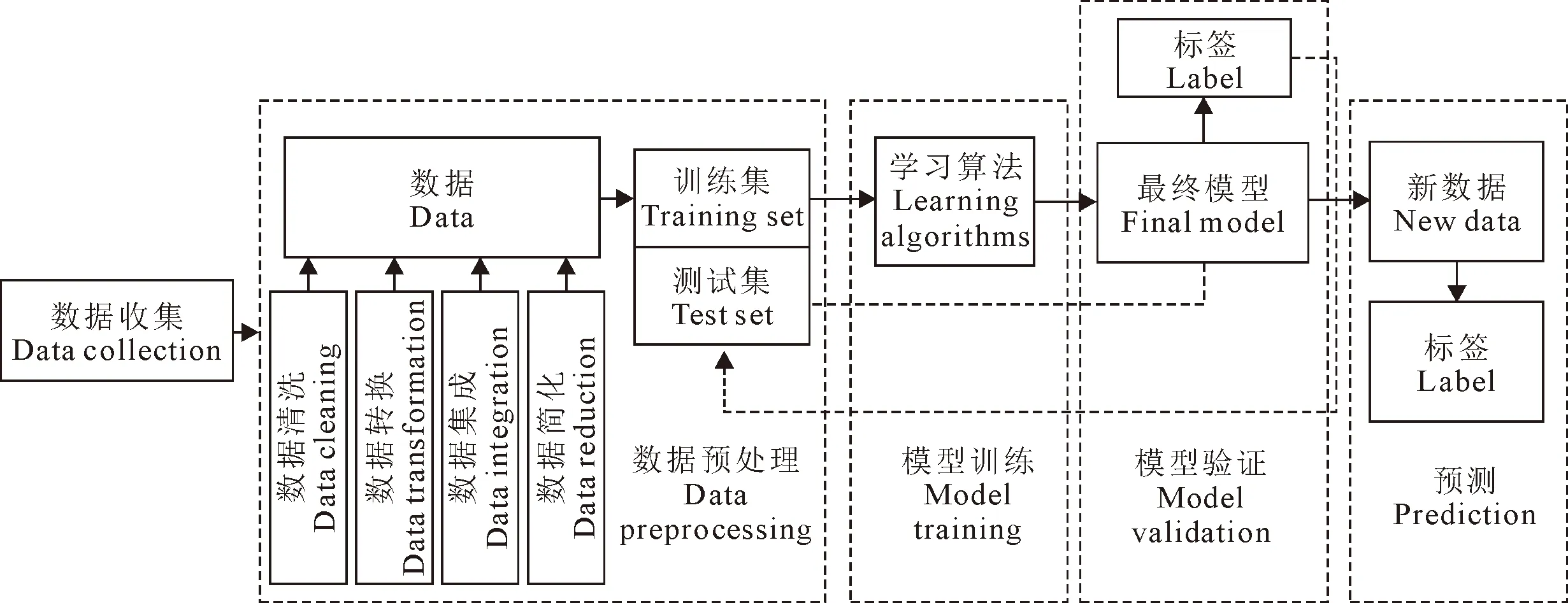
图1 机器学习建模流程
1.2 数据处理
用于奶牛疾病监测的数据通常包括农场存储的数据、生理特征数据、喂养过程中的数据、饲养管理软件数据和传感器采集的数据等。在实际应用中,因为以上数据存在不完整、重复、人工录入错误和数值缺失等情况,为了获得更好的预测结果,必须对数据做预处理。数据预处理通常先进行数据清洗、数据变换、数据集成和数据简化等,再将数据集划分为训练集和测试集两部分。其中训练集用于模型的训练和构建,测试集用于预测结果的评估,比例一般为70%和30%,很多时候还会多划分出验证集(60%,20%和20%)[11]。
1.3 ML在奶牛疾病预测中的常用算法
ML包括有监督学习、非监督学习、半监督学习和强化学习,ML常用的算法分类如图2所示。监督学习需要标记数据和训练数据集,而非监督学习在未标记数据的情况下独立评估数据;半监督学习方法使用的数据集只有一小部分标记数据。应用ML预测奶牛疾病的主要算法有基于树模型算法、人工神经网络算法(Artificial neural network,ANN)(简称神经网络)、回归算法和聚类算法等。使用最为广泛的是基于树模型算法,比如决策树(Decision tree,DT)和随机森林(Random forest,RF)。ANN在各类应用中均有使用,另外常用的算法还有朴素贝叶斯(naive bayes,NB)、K最近邻算法(K-nearest neighbor,KNN)和支持向量机(support vector machine,SVM)等[12]。
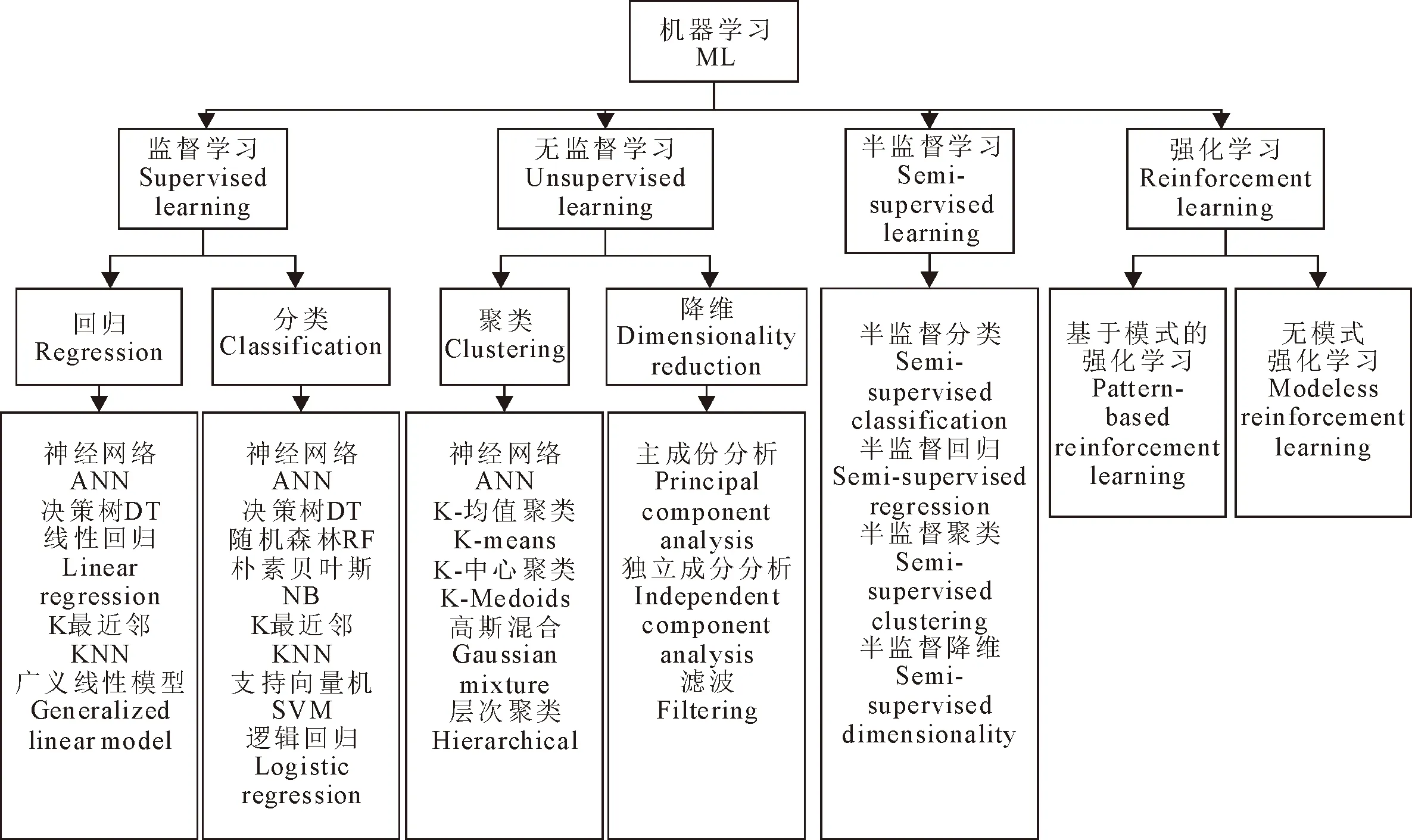
图2 机器学习常用算法分类
1.3.1 基于树模型算法 预测奶牛疾病基于树模型的算法主要有DT[13]、RF[5]和梯度提升决策树(gradient boosting decision tree,GBDT)等。DT是一个倒立的树形结构,算法利用训练集从树的根结点开始,通过对疾病关键指标进行自顶向下依次的定性判断来诊断和预测疾病。DT在使用时速度快,精度高,模型简单易懂,因此在实际预测中实用性强,效果好[11]。此外,RF因可改善DT易拟合的特点也被广泛应用。
1.3.2 人工神经网络 ANN是一种模拟生物神经网络进行信息处理的数学模型,由输入层、隐含层和输出层组成。常用的ANN算法有反向传播(back propagation,BP)神经网络、径向基函数(radial basis function,RBF)神经网络、模糊神经网络和自适应神经网络等,其中BP神经网络和RBF神经网络由于其良好的非线性逼近能力在疾病预测中被广泛应用[14-15]。
1.3.3 聚类分析算法 聚类分析是指样本在没有分类标准的情况下,根据样本本身的属性,用数学统计方法按照某种相似性或差异性特征,定量确定样本之间的相似度或距离,并按照这种相似度或距离的远近关系对样本进行聚类,从而筛选出疾病的特征。常用的聚类算法有K均值(K-means)聚类、模糊C均值聚类和层次聚类。聚类分析模型直观简单,适用于处理多种不同类型的样本量小的数据集合,在奶牛跛行诊断[16]、代谢性疾病[17]和传染病的预测[18]均有应用。
1.3.4 回归算法 回归算法是一种对数值型连续随机变量进行预测和建模的监督学习算法。回归算法要建立确定疾病相关的危险因素和疾病之间的映射关系的函数,使得参数之间的关系拟合性最好,得到与疾病相关的危险因素,从而筛选出预测疾病的输入变量,建立最优回归方程进行建模。常用的回归算法有线性回归和逻辑回归,线性回归主要用来解决连续值预测的问题,逻辑回归用来解决分类的问题[11]。
1.4 模型评价
样本集训练完成后需要评估预测模型的性能,常用的评价指标有准确率、精度和召回率等。
1.5 性能优化
在特征和模型确定后通过调整模型的参数来提高疾病预测模型的准确率。常用的调参方法有手工搜索、网格搜索、随机搜索和贝叶斯搜索等。
2 ML在奶牛临床疾病中的研究进展
2.1 代谢性疾病
ML预测代谢病时,首先采集奶牛生理指标和生产数据,再根据需求筛选可分析生理指标或生产数据和疾病之间关系的模型,最后建模。比如,为了研究干奶期、胎次、产奶性状和体重等数据能否预测产后代谢状态,Xu W等[5]比较研究了DT、NB、贝叶斯网络、SVM、ANN、KNN、Bootstrap聚合和随机搜索等8种算法的建模效果,发现RF和SVM预测效果较好。在代谢病预测方面,通过ANN对基因组和代谢信息建模,在产后1、3、4、5周能较为准确预测亚临床酮病[14]。筛选危险因素时,DT和RF算法有运算快的优势,通过分析奶牛健康记录就可筛选出导致淘汰的原因依次为乳热、皱胃变位、临床乳腺炎、子宫炎和双胎。并且,当两个疾病叠加时,淘汰的风险会进一步增加[14]。若要分析血液代谢产物和疾病之间的关系,ML需结合统计学方法进行聚类、回归或建立线性模型。Tremblay M等[7]通过主成分分析和K-means聚类分析,发现非酯化脂肪酸水平与代谢适应不良综合征显著正相关。Van Hoeij R等[17]利用广义线性模型分析发现代谢状况差的奶牛干物质摄入量低,易发生能量负平衡。
2.2 跛行
ML分析跛行时,主要是对奶牛运动时不同部位的运动图像进行步态分析,筛选出特征参数后建模,最后进行分类验证。采用聚类和KNN分类算法可以分析奶牛站立、步数和躺卧并建模预测跛行的模型,总体检测准确率可达到87%,敏感性为89.7%,特异性为72.5%[16]。筛选不同部位的特征参数时,宋怀波等[19]提取奶牛的头部、颈部以及与颈连接的背部轮廓线拟合直线斜率数据,KNN分类算法预测跛行的检测正确率可达到93.89%。但以腿的运动指标为跛行诊断的标准时,短期记忆网络(long short-term memory,LSTM)、SVM、KNN和DT算法中,基于LSTM的跛行检测准确率最高,为98.57%[20]。
2.3 乳房炎
ML预测乳房炎时,奶产量、挤奶时间和乳腺炎等标志物数据是主要的数据源,SVM和DT是常用的算法[21]。RF可以建立对环境性与传染性乳腺炎进行区别诊断和对干奶期和泌乳期感染区别的模型[8]。深度学习(deep learning,DL)、DT、RF、NB、GBDT、广义线性模型和逻辑回归算法预测亚临床乳腺炎时,GBDT和DL有较高的预测灵敏度[9]。如果数据源为乳汁电导率,使用DT建模预测乳腺炎的特异性可高达99.2%[22]。不同的DT算法预测乳腺炎的准确性也有差异,DT、树桩DF、并行DT和RF 4种算法中只有RF诊断奶牛乳腺炎的准确率可达到90%,并有望在实践中使用[23]。此外,通过DT算法对大肠埃希氏菌感染诱发乳腺炎转录组分布进行建模,可筛选出大肠埃希氏菌乳腺炎的标志物基因[24]。
2.4 热应激
奶牛热应激由极端的气候环境造成,监测环境的指标为温度-湿度指数(temperature-humidity index,THI)。但仅通过THI并不能直接反映奶牛机体的热应激程度[25],还需要呼吸频率、呼吸评分、体温、躺卧率、站立时间和饮水时间等生理指标[26]。在算法方面,回归分析,RF和ANN使用最多。Gorczyca M T等[10]比较了线性回归、RF、GBDT和ANN建模预测热应激时奶牛的呼吸频率、皮肤温度和阴道温度的效果,发现RF和ANN的预测效果较好。Slob N等[12]使用RF和ANN算法建模后认为气温对热应激影响最大而风速的作用最小,但由于预测会受环境影响,准确性可能难以保证。为筛选出最优模型,有研究者采集了THI、呼吸频率、卧床时间、躺卧期、总步数、流涎、呼吸评分、阴凉处或喷淋处停留时间、体细胞评分、网胃温度、洁净度评分、奶产量以及乳脂率、乳蛋白率等数据,使用逻辑回归、高斯NB和RF 3种ML算法进行预测并发现准确率都很高,逻辑回归效果最好,这表明非线性的方法效果好[27]。Brown-Brandl等[28]在利用呼吸频率和体表温度建模预测热应激时发现,两种回归模型、两种模糊推理系统和一种神经网络模型都过度预测低强度热应激或高估高强度热应激时动物的热应激,其原因可能是因为ML模型无法提前预测天气。
2.5 传染性疾病
ML在传染病的研究上,主要集中在利用传染性疾病的流行病学特征进行聚类分析,筛选出关键风险因子,构建预测和监测传染性疾病的模型。比如,利用逻辑回归分析奶牛的年龄、品种和出生时间对奶牛感染副结核的影响,判断这些因素是否是副结核的风险因素,结果发现出生日期与副结核感染有着显著的相关性(P<0.05)[18]。在算法方面,RF和ANN仍是常用的方法。有研究者利用RF和增强回归算法,分析奶牛细菌基因组数据和研究细菌在不同物种间的传播速度[29]。通过ANN分析牛奶中红外光谱数据并构建奶牛结核病预测模型时,深度卷积神经网络的预测准确性可以高达95%[15]。此外,也可以利用分类和回归树模型,分析多个传染病风险因子之间的关联性和高危群体的发病可能性,从而确定疾病的患病率、事件检出率和病史[30]。
3 展望
通过综述ML在预测奶牛疾病的研究的相关文献发现,ML在代谢性疾病和跛行方面的应用最多,而DT算法因其简单易行,并且运行速度快,在奶牛疾病领域应用最广。目前,虽然基于ML的奶牛疾病预测已成研究热点,但由于数据的有限性和复杂性,研究也遇到很多困难。在算法方面,聚类分析、深度学习和强化学习等算法的应用将会成为奶牛疾病监测领域的主要研究方向。此外,利用ML和基因组学研究奶牛疾病也是未来可关注的方向。
猜你喜欢
今日农业(2022年3期)2022-11-16 13:13:50
今日农业(2021年10期)2021-07-28 06:28:00
中国生殖健康(2020年8期)2021-01-18 03:05:36
小天使·一年级语数英综合(2019年12期)2019-01-13 01:32:29
中国生殖健康(2018年3期)2018-11-06 07:20:14
养生保健指南(2016年2期)2016-11-28 09:37:25
兽医导刊(2016年12期)2016-05-17 03:51:34
中国继续医学教育(2015年6期)2016-01-07 07:38:37
黑龙江八一农垦大学学报(2015年2期)2015-12-08 09:26:15
小天使·三年级语数英综合(2014年9期)2014-09-12 14:45:46
