
启发式联合PCD快速降噪算法
2021-06-19 06:46:50何选森
电子科技大学学报 2021年3期
何选森,徐 丽,许 莹
(1.广州商学院信息技术与工程学院 广州511363;2.湖南大学信息科学与工程学院 长沙 410082)
在对信号的描述中,基于冗余字典的稀疏表示提供了一种强有力的信号模型,它是将获得的观测信号近似为字典中少量原子的线性组合[1]。由于噪声无处不在,纯粹的干净信号是无法得到的,对信号降噪已经成为信号处理最重要的任务之一。稀疏表示本身具有潜在的降噪能力[2],特别是联合稀疏表示(joint sparse representation,JSR)[3]和同时稀疏近似(simultaneous sparse approximation,SSA)[4]在信号降噪领域都获得了广泛的应用。另外,收缩是建立在稀疏表示基础上的具有吸引力的降噪技术[5],著名的小波收缩使用正交变换实现降噪[6]。然而,新的趋势是采用超完备变换,它对信号的分解不是唯一的。例如:帧方法、匹配追踪法、最佳正交基法等,而基本追踪(basis pursuit,BP)[7]法是通过优化技术将信号分解为字典元素的最佳(叠加)表示,且使表示系数的l1范数(或l0范数)最小化[8]。将BP应用于含噪声的信号,即基本追踪降噪(BP denoising,BPDN)[9]方法对于消除高斯白噪声非常有效。同样地,冗余字典的发展也催生了高效的数值技术,即迭代收缩(iterative shrinkage, IS)算法[10]。为解决BPDN问题,文献[11]提出了4种IS算法,分别是启发式收缩、基于迭代重加权最小二乘、阶段式正交匹配追踪、并行坐标下降(parallel coordinate descent,PCD)算法。其中PCD的搜索速度最快。因此,文献[12]又对PCD进行了算法的收敛性分析,并引入了一种正则化函数形式,使得PCD能对坐标优化提供解析的解。
利用PCD对每个含噪声的音频(语音)帧进行降噪能获得整个信号很好的降噪效果。然而,若信号很长,则分割的音频帧数量就很大,用PCD对每帧分别进行降噪将导致繁重的计算负担。为此,本文建立了一种以信号矩阵为操作对象的时域处理框架,并提出了基于SSA和JSR的启发式联合PCD算法(Joint-PCD)。在此框架中,每个音频帧作为一个列向量生成信号矩阵,Joint-PCD算法每次是对一个信号矩阵(而不仅仅是对一个音频帧)进行降噪,从而极大地降低了算法的运行时间开销,提高了算法的收敛速度。
1 稀疏信号的降噪
在对信号进行表示时,最常用、最简单的方法就是对信号进行线性变换。用s∈RN表示N维信源矢量,x∈RN表示对应的观测矢量,T表示N×N变换矩阵,则x=Ts。由于变换后的信号数量等于信源的数量,则T称为正交变换。信号的另一种重要表示是线性稀疏表示。假设在同一时刻只有少量的分量xi∈x是非零的,其他绝大多数分量都为零值,则称x服从稀疏分布。若信号x被高斯噪声v污染,通过对x的稀疏分量进行软阈值收缩可实现x的降噪[6]。
信号x∈RN一般由几个单位能量原子dk的线性组合近似表示,所有原子组成的集合{dk,k=1,2,···,K}构成一个字典D∈RN×K。观测向量x可以表示为:

式中,z∈RK是稀疏的,是K个系数的列向量。当K=N时,D为正交,其表示也是唯一的;当K>N时,D为冗余,式(1)存在无限多个可能的系数集。冗余字典的优势体现在可以从众多的可能性中选择最适合的一种表示,其中最吸引人的表示法是求具有最少数量的非零的系数解:
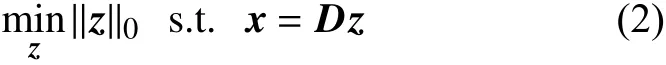
式(2)是寻找欠定线性方程组x=Dz的最稀疏解[13]。优化式(2)还可以等价地表示为[13]:
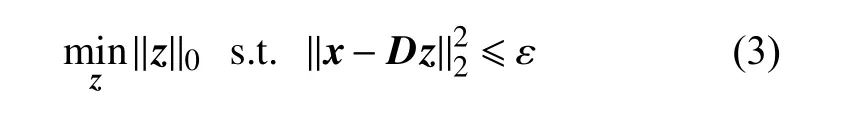
式中,ε是误差容限;||·||p表示lp范数;l0范数是对一个向量非零元素的计数;l2范数采用欧几里得范数。式(2)和式(3)可用正交匹配追踪法求解[11]。式(2)还可表示为[7]:
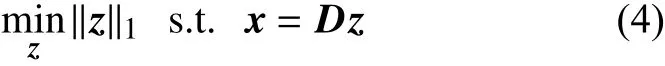
式中,l1范数是求一个向量元素绝对值的总和。由于l1范数是l0范数的凸化[13],因此,式(4)可以看作是式(2)的凸化。
对于含噪声的观测信号矢量:

式中,x∈RN是干净的信号向量;v∈RN是能量为δ的高斯零均值白噪声向量。对信号y降噪的优化问题表示为[8]:
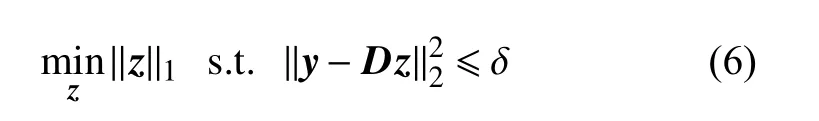
优化式(6),可由拉格朗日形式代替[8]:
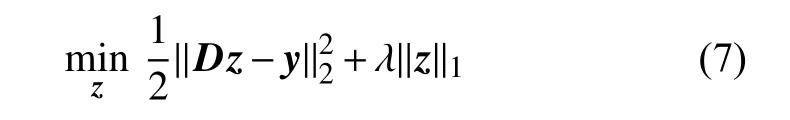
式中,λ是用于调节近似误差与系数向量稀疏性之间关系的一个参数。实际上,式(7)就是PCD算法的目标函数[11]。
一般地,从含噪声信号矢量y中去除高斯白噪声的过程可归结为对下式函数的最小化[11]:
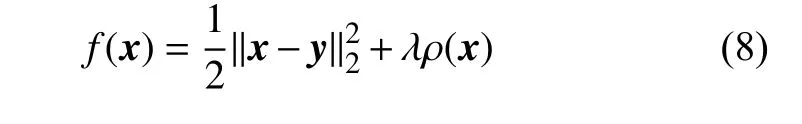
式中,第一项为对数似然,它描述了干净信号x与含噪声向量y之间的关系;第二项的ρ(x)表示x的先验值,不同的ρ(x)对应于不同的f(x)展开式。将式(1)代入式(8)中,得到信号降噪的目标函数为[11]:
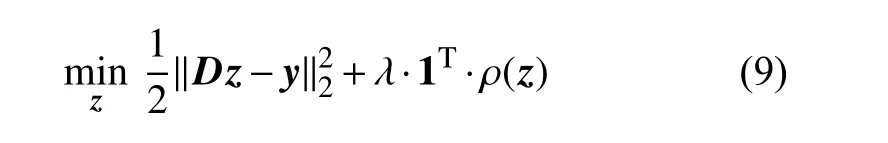
式中,1K表示元素为1的K×1矩阵(列向量)。
迭代收缩(IS)算法是为了解决目标函数为式(9)这样的混合l2−lp(p≤1)优化问题而产生的新型高效数值技术。比较式(9)与式(7)可知:在PCD算法中,函数ρ(z)是l1范数。
式(7)表示的PCD算法的操作对象是向量,在音频信号降噪过程中,PCD每次是对一个音频帧(列向量)降噪。若音频帧数量巨大,则PCD算法的运行时间将急剧增加。特别对于大规模数据和实时信号的降噪问题,分别用PCD对每帧降噪是不现实的,必须寻找新的方法同时(并行)对多个列向量降噪,以减少算法的计算负担。
2 Joint-PCD启发式算法
用冗余字典原子的线性组合近似表示一个音频帧,称之为简单稀疏近似(simple sparse approximation);对于被相同信道噪声污染的多个帧(矢量),用相同字典原子的不同线性组合同时近似表示,称之为JSR。通过对多个向量同时稀疏表示的理论分析和研究[14],从而就产生了求解SSA问题的策略[15]。对于音频(语音)信号在加性高斯白噪声(additive white Gaussian noise, AWGN)信道的传输与降噪,SSA具有重要意义。
为了对一个音频信号的所有帧同时进行降噪,需建立新的时域框架以区别传统的帧处理模式。这种框架的基本思想为:把信号中每个被分割的帧按顺序作为一个矩阵的列向量,信号与矩阵唯一对应。由于矩阵中的各个列向量是同一个音频信号的不同帧,因此具有相同的稀疏性。基于新的时域框架,就可将简单稀疏近似推广为SSA,并将向量形式的PCD扩展为矩阵形式的Joint-PCD,从而利用冗余(超完备)字典原子的不同线性组合,实现对一个音频信号所有帧同时进行降噪处理。

对于Z和D两个变量,式(12)并不是一个凸优化问题,只有当其中一个变量给定时,它才是凸优化[3]。本文中超完备字典D是给定的,通过优化Z来构造Joint-PCD算法。式(12)还可以推广到多个(大于2个)信号矢量的情况。
对于多个观测信号的矩阵模型:

式中,X∈RN×P是包含了P个向量(音频帧)x i∈RN的干净信号矩阵;V∈RN×P是P个噪声向量v i∈RN组成的矩阵;Y∈RN×P是含噪声的观测信号矩阵。基于联合稀疏表示(JSR)[3],干净信号矩阵X可以由超完备字典D表示为X=DZ,则含噪声的观察信号矩阵为:


式中,||·||F是矩阵的Frobenius范数。如果系数矩阵Z中的非零行向量能正确地辩识出z i中的非零元素,就可利用线性的方法估计z i值。因此,可以把向量形式的降噪优化式(9)扩展为如下的矩阵形式:

式中,ρ(·)是任意标量函数,而ρ(Z)是衡量矩阵Z稀疏性的惩罚函数。式(16)是Joint-PCD算法的目标函数。
综合考虑式(15)和式(16),可以归纳出构造Joint-PCD算法的基本思想为:通过最小化Z中非零行的数量来限制参与对Y进行逼近的字典原子的总数。采用两方面的措施来实现。首先,希望参与对Y近似的原子数量越少越好;其次,希望每个参与近似的原子要尽可能多地对矩阵Y的各列向量做出贡献。对于系数矩阵Z,希望它的大多数行向量都是全零元素,而它的每个非零行(向量)都应包含尽可能多的非零元素。基于这种考虑,将函数ρ(Z)设置为行−l0准范数(row-l0quasi-norm)的松弛版:式中,||Z||rx范数是把矩阵Z每一行中的最大绝对值项相加。本质上,将l∞范数应用于Z的行以促进它的非稀疏性,而将l1范数应用于所得向量z i以促进其稀疏性。若矩阵Z退化成一个列向量,则松弛范数降为l1范数,此时SSA的松弛条件与简单稀疏近似的松弛条件相同。
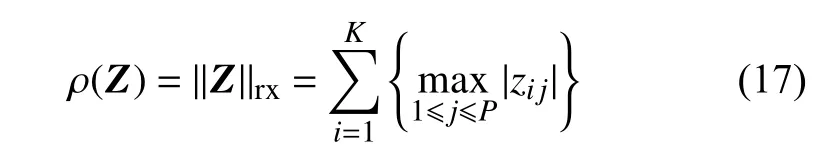
把式(17)代入式(16)中,得到信号矩阵的降噪优化问题:
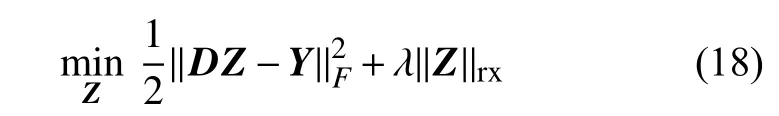
同样地,从优化式(12)可知,函数ρ(Z)是矩阵Z的l1范数,本文对ρ(Z)的l1范数使用偶对称的函数:
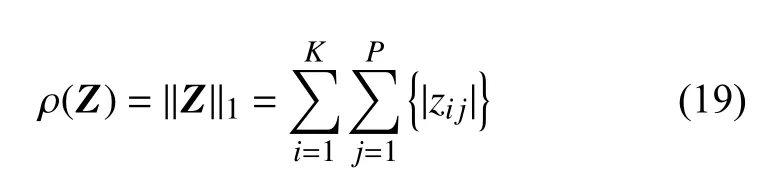
式中,zij是矩阵Z的第(i,j)个元素。另外,式(12)是将两个列向量推广到多个列向量的情形,即式(12)中的系数矩阵一般是P个列向量组成的矩阵Z∈RK×P,而不仅仅是由2个列向量组成的矩阵Z∈RK×2。
为方便起见,把||Z||rx称为矩阵Z的rx-范数。求解式(18)的算法称为rx-范数的Joint-PCD,求解式(12)的算法称为l1范数的Joint-PCD。在给定系数矩阵的当前解Z k(其中k是迭代次数)条件下,定义矩阵U(D,Y,Z k)为:

式中,µ 是迭代步长;λ是收缩函数S(·)的阈值;从启发式收缩算法[11]的推导过程可知,式(23)中的收缩函数S(·)是一个软阈值函数[11],其定义为:
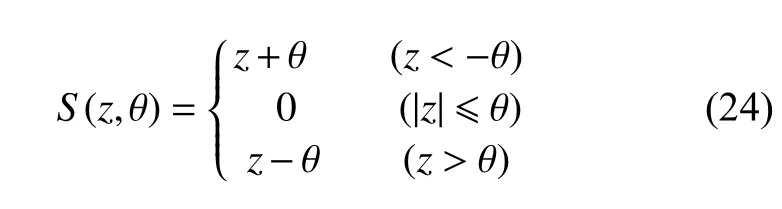
式中,θ为软收缩函数S(·)的阈值。
式(22)中的步长参数µ对算法的性能影响很大;对足够小的µ >0,步长必须导致惩罚函数ρ(·)的可行下降。本文使用线搜索[10]寻找最佳µ值。线搜索作为一维优化寻求迭代步长,用于解决以下的优化问题:
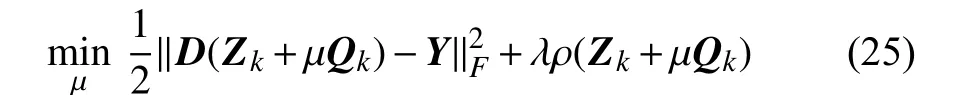
式中,ρ(·)可以是rx-范数,也可以是l1-范数。
如果信号矩阵Y退化为一个列向量y,系数矩阵Z也仅仅是一个列向量z,则Joint-PCD算法将退化为PCD算法。因此,将Joint-PCD称为一种启发式算法。
在音频信号处理中,经常使用两个超完备字典[16],即离散余弦变换(DCT)字典和Gabor字典。
一个加窗的Gabor字典为D G=[d(k,φ)](k,φ)∈Ψ,其原子以连续的参数集Ψ=[1,K]×[0,2π]为索引,其定义为:
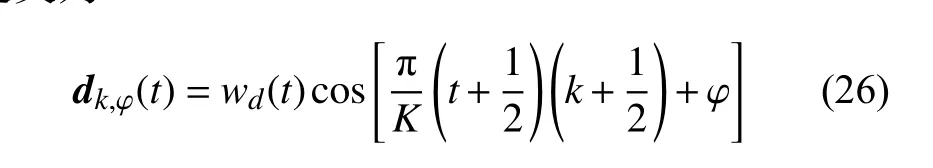
式中,1≤k≤K,0≤t≤N−1,K是Gabor字典的大小;φ是相位;wd是加权窗口。d(k,φ)的分解可以用离散字典中的原子对表示:
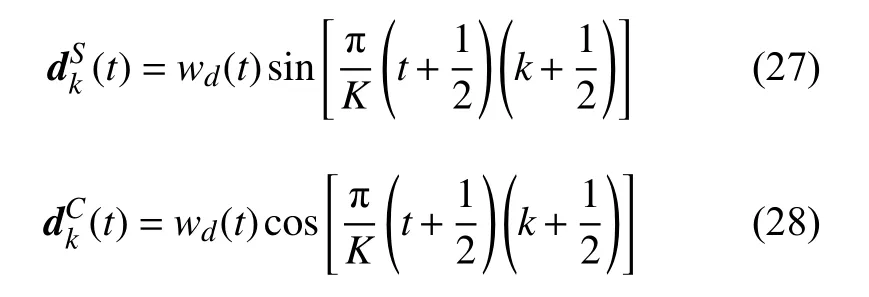
以上两式中,成对的原子是相同频率且相位为零的余弦和正弦对。为简化计算,词典的列都做归一化处理,即Gabor字典的正弦和余弦原子都使用其单位范数的版本。
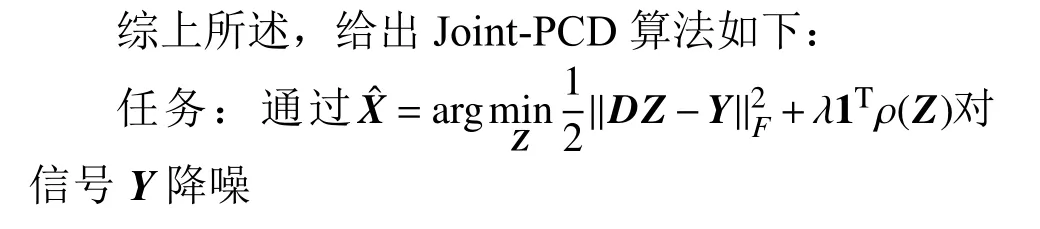
输入:观测矩阵Y;字典D;阈值λ;函数ρ(·);迭代次数M
开始:设置k=1,迭代开始
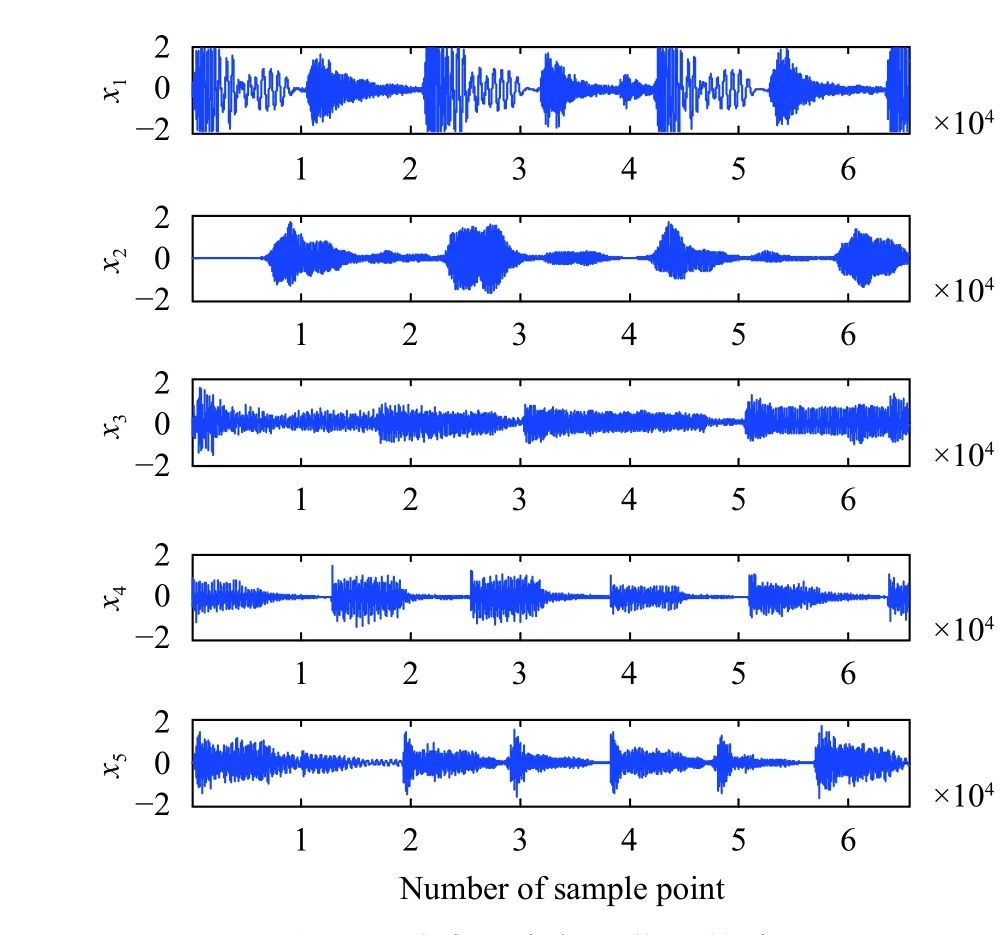
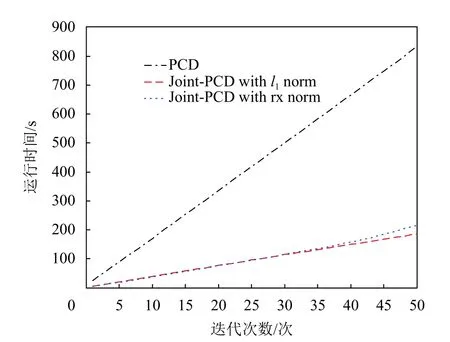
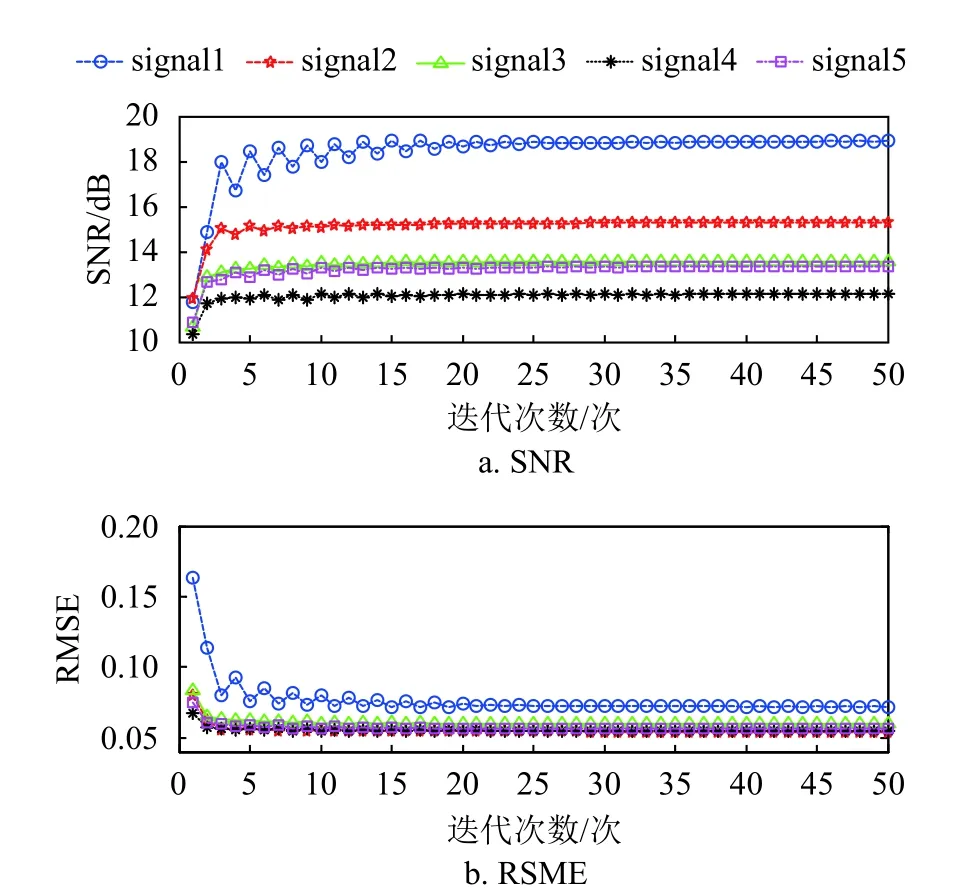
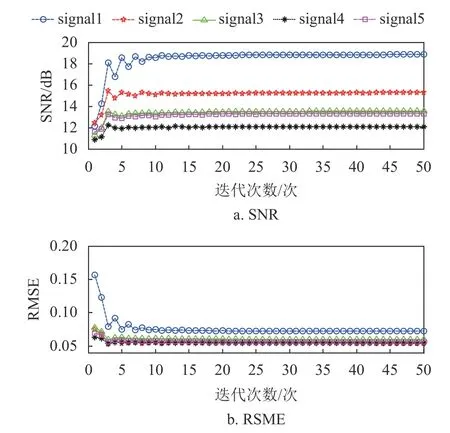
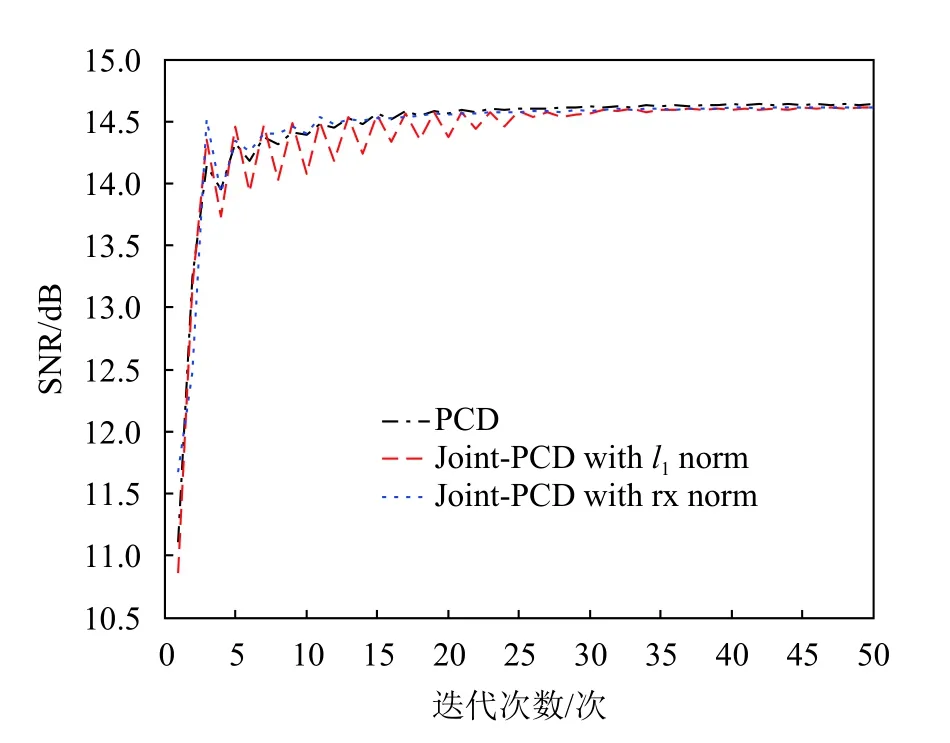
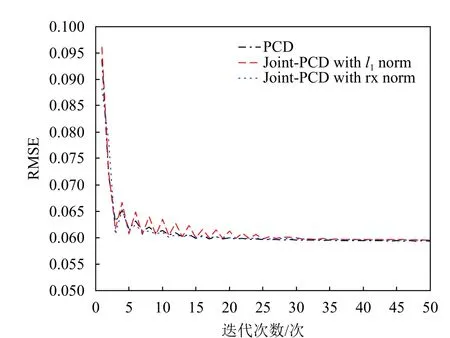
If:k 误差:计算E=Y-DZ k 映射:计算E T=DTE 收缩:计算E S=S(E T+Z k,λ) 线收缩:寻找µ0以获得Zk+µ (E S-Z k)的下降 通过仿真对矩阵形式的Joint-PCD与向量形式的PCD算法的性能进行全面比较,各算法的仿真实验环境完全相同。 测试用的5个音频音乐信源取自著名的音频网站[17]。源信号类型为wav,采样率为44 100 Hz。每个信源的样本数量为L=216=65 536。5个音频信源矩阵为X=[x1,x2,x3,x4,x5]T,其时域的波形如图1所示。 图1 5路音乐音频源信号的波形 仿真实验的硬件平台:笔记本电脑,其CPU为Intel (R)Celeron (R)1007U CPU-1.50 GHz,内存为4 GB,PC机操作系统为Windows10。软件平台为MATLAB9(R2016a)。 降噪性能通过信噪比(signal to noise ratio,SNR)和均方根误差(root mean square error,RMSE)来衡量: 式中,x为干净信号;xˆ为降噪后信号;L为x的样本数。 对信源X施加一定强度的高斯白噪声后形成含噪声的观测信号Y,噪声强度一般采用高斯随机变量的标准差σ来度量。显然,信号Y中噪声强度的大小对降噪算法的性能带来很大影响。另外,在PCD和Joint-PCD算法中,软收缩函数S(·)的阈值λ以及所采用的超完备字典(DCT或者Gabor)也都会对降噪性能造成一定影响。这几个参数的最佳值分别为:噪声强度σ=0.1;软阈值λ=0.1;选用Gabor字典,其尺寸为N×K=64×1 024,加权窗为N=64的对称正弦窗。 在PCD和Join-PCD算法中,惩罚函数ρ(·)的形式、算法迭代步长µ也都需确定。不同形式的ρ(·)使用不同的矩阵(向量)范数。对于PCD,采用向量的l1范数来求解优化式(7);对于Joint-PCD,使用矩阵的l1范数来求解优化式(12),使用矩阵的rx-范数来求解优化式(18)。对于PCD和Joint-PCD算法的迭代步长µ (0<µ<1),在算法的运行过程中使用线搜索来获得最佳值,即在每次迭代中,用MATLAB函数fminbnd在线搜索µ值作为更新的步长。 音频信源与高斯噪声相加生成含噪声信号,其降噪仿真过程如下。首先,每个含噪声(时域)信号乘以长度为64的汉明窗生成语音帧,并使相邻两帧之间的重叠样本数为32,即每帧的前后各有16个样本与相邻帧的样本重叠,分帧使用Voicebox[18]中的MATLAB函数enframe实现。然后,用PCD和Joint-PCD算法分别对分割后的含噪信号实施降噪。执行PCD是对音频信号的一帧进行降噪;Joint-PCD执行一次是对一个信号(而不仅仅是一帧)进行降噪。最后,重建降噪后的信号,经过降噪的音频信号乘以逆汉明窗,在每一帧与相邻两帧重叠的样本中,分别在两边各去除16个样本,仅保留每一帧中间部分的样本;将经过处理的各个音频帧简单串联起来即可得到重新合成的音频信号。 对PCD和Joint-PCD算法的性能分析从两个方面进行:1)算法在相同条件下所消耗的运行时间成本;2)算法降噪性能指标(SNR和RMSE值)的比较。 为了全面分析PCD和Joint-PCD算法的性能,在第一个仿真中,设置算法的最大迭代次数M=50。为便于表示,把Joint-PCD两种范数对应的算法分别表示为Joint-PCD with rx norm和Joint-PCD withl1norm。算法Joint-PCD和PCD的运行时间指标如图2所示。 图2 算法的运行时间比较 从图2可以看到,随着迭代次数的增加,算法的运行时间几乎都是呈线性增长,但不同算法对应的直线斜率(增长率)是不同的。对于Joint-PCD with rx norm和Joint-PCD withl1norm算法,随着迭代次数的增加,它们的运行时间增长率几乎是相同的;PCD算法运行时间增长率却远大于Joint-PCD的增长率。显然,与PCD算法相比较,Joint-PCD算法能够极大地降低运行时间。 为了便于比较PCD和Joint-PCD的降噪性能,在每次迭代后,分别计算每种算法对每个信号的降噪指标值。图3给出了PCD算法的输出SNR和RMSE波形。 图3 PCD算法对每个信号的输出SNR和RMSE指标 同样地,图4和图5分别给出了Joint-PCD withl1norm和Joint-PCD with rx norm算法的输出SNR和RMSE波形。 图4 Joint-PCD with l1 norm算法对每个信号的降噪指标 比较图3、图4和图5可知,对于每个信号,PCD算法的降噪性能几乎与Joint-PCD with rx norm和Joint-PCD withl1norm算法的性能完全相同。经过25次迭代,PCD和Joint-PCD算法对每个信号的输出SNR和RMSE值都逐渐收敛到其稳定值。这表明从降噪性能的角度来看,用Joint-PCD算法代替PCD算法是完全可行的。 图5 Joint-PCD with rx norm算法对每个信号的降噪指标 为了更直观地观察PCD和Joint-PCD算法的平均降噪性能,在每次迭代后,计算并记录了每种算法对于5个信号的平均SNR值。其结果如图6所示。 图6 5个信号的平均SNR指标 同样地,PCD和Joint-PCD算法对5个信号的平均降噪性能指标RMSE的值如图7所示。 图7 5个信号的平均RMSE指标 从图6和图7可以看出,PCD和Joint-PCD算法的平均性能指标随着迭代次数的增加具有一定的波动,特别是在算法的初始迭代阶段,其波动更为明显。这是因为每个信源的幅度值不同,而施加到各个信源上的高斯白噪声的强度却一样,这就造成每个信号受到噪声的干扰程度不同。另外,在降噪过程中,由于每个信号被噪声污染的严重性不一样,它们输出的SNR和RMSE值(如图3~图5所示)就具有不同的波动范围。当把这5个信号的降噪性能平均之后,其对应的平均SNR和RMSE值有波动就是一种很自然的现象,不可能消除这种平均性能的波动。将5个信号的降噪性能进行平均是为了研究算法稳定收敛的条件。从图6和图7还可看出,对于PCD和Joint-PCD with rx norm算法,平均SNR和RMSE值的波动在大约20次迭代后结束;对于Joint-PCD withl1norm算法,其波动在大约25次迭代后结束。这表明Joint-PCD和PCD算法在经过大约25次迭代后能稳定收敛。 为了更精细地分析不同算法的降噪性能,通过第二个仿真分析PCD和Joint-PCD算法的差异性。从上述的结果可知,PCD和Joint-PCD算法在经过25次迭代后能稳定收敛,因此,在这个仿真中,将算法的最大迭代次数设置为M=25。比较PCD和Joint-PCD算法达到稳定收敛所需要的运行时间,其结果如表1所示。 从表1可以看出,Joint-PCD withl1norm算法的运行时间最少,而Joint-PCD withrxnorm算法的运行时间比前者仅多了0.379 2 s,因此,两种Joint-PCD算法的运行时间几乎相同。与之相反,PCD算法收敛所花费的运行时间大约是Joint-PCD算法的4.6倍。这充分说明Joint-PCD算法比PCD算法具有更高的计算效率。 表1 PCD和Joint-PCD算法的运行时间s 对于PCD和Joint-PCD算法的降噪性能,采用每种算法对每个信号在整个迭代过程中输出SNR和RMSE的平均值来度量,其结果如表2所示。表中粗体数字为相应的最佳降噪性能指标。 从表2中的数据可以看出,对于第2、第4和第5个信号,Joint-PCD withl1norm算法的平均SNR和RMSE值是最优的;对于第1和第3个信号,PCD算法的平均指标是最优的。另外,从表2还可以看出,PCD和Joint-PCD算法平均SNR值的差异仅发生在小数点后面第二位;而平均RMSE值的差异仅发生在小数点后面第四位。这表明,用Joint-PCD代替PCD,对音频信号降噪性能几乎不产生任何影响。 表2 每个信号在整个迭代过程的平均SNR和RMSE值 综合表1和表2的结果可知,在降噪性能基本相同的情况下,Joint-PCD算法的计算复杂度大幅度降低。 本文定义了一种音频信号的时域处理框架,即将每个被分割的音频帧都作为一个列向量从而生成信号矩阵。在联合稀疏表示(JSR)和同时稀疏近似(SSA)的基础上,利用新的处理框架,提出了以信号矩阵为操作对象的Joint-PCD算法。仿真实验的结果表明:Joint-PCD算法不仅能够提供与向量形式的PCD算法几乎完全相同的降噪性能,更重要的是,Joint-PCD算法提供了更高的计算效率。与传统的PCD算法相比,Joint-PCD算法在大规模数据处理和实时信号处理应用方面具有巨大的潜在优势。
3 仿真实验及结果分析
3.1 仿真环境和性能指标
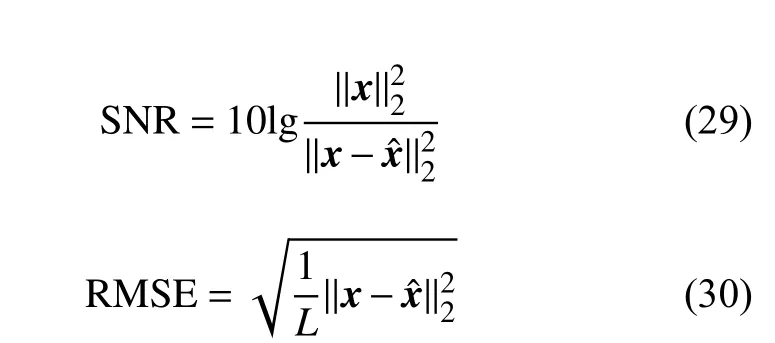
3.2 参数设置及仿真过程
3.3 性能分析

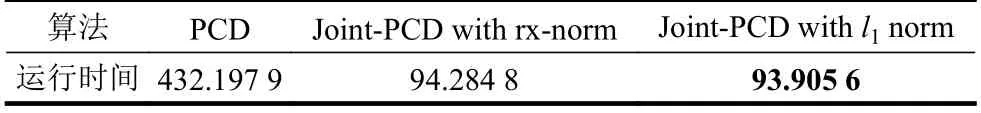

4 结束语
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
中国校外教育(下旬)(2017年8期)2017-10-30 17:32:36
数学物理学报(2017年3期)2017-07-01 16:18:48
电子制作(2017年9期)2017-04-17 03:00:46
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
读者(2016年14期)2016-06-29 17:25:50
人间(2015年8期)2016-01-09 13:12:42
