
一种基于对抗学习的实时跟踪模型设计
2021-06-18 07:32李志鹏
计算机工程 2021年6期
李志鹏,张 睿
(1.复旦大学 软件学院,上海 201203;2.复旦大学 计算机实验教学中心,上海 201203)
0 概述
目标跟踪是指在视频的每一帧中找到感兴趣目标的运动位置,其被广泛应用于人机交互、视频监控和自动驾驶等领域,也是计算机视觉的一个重要分支。在设计目标跟踪算法时,需要同时考虑复杂环境中的跟踪精度以及跟踪速度,以满足实时性需求。随着深度学习研究的深入,卷积神经网络(Convolutional Neural Network,CNN)大幅提升了跟踪算法的性能和稳定性[1],但是计算复杂度的提升使得单一CNN 算法难以满足实时性需求[2]。基于相关滤波器的目标跟踪算法一般具有较高的计算效率,现有实时跟踪算法大多使用基于图像卷积特征的相关滤波器[3],但是此类算法保持高跟踪速度的同时难以保证高跟踪精度。随着实际应用中对精度需求的不断提升,相关滤波器输入维数的增长也会限制算法的跟踪速度[4]。因此,设计同时具有高精度和高速度的目标跟踪模型具有重要意义。
在现有的跟踪算法中,研究人员应用迁移学习的思想[5],使用VGG-NET[6]等预训练卷积网络提取图像特征,大幅提高了算法性能。但是直接应用VGG-NET 并非最优方案,原因是对于特定跟踪场景,待处理的图像分布通常与VGG-NET 训练数据的分布不同,这类分布差异问题会影响图像特征的可靠性。为了解决这一问题,本文采用对抗学习方法[7],在不需要跟踪场景图像标签的情况下解决分布差异问题,使模型在特定任务中表现更稳定。另外,由于特征维数是限制模型计算效率的主要因素,本文利用自编码器将图像特征压缩到低维空间[8]。在实际应用中,模型要处理包含多类目标和环境风格的图像,因此,本文设计一种双通道自编码器结构并在训练时优化判别损失函数,以提高模型的泛化能力。在特征压缩后使用相关滤波器进行目标跟踪。具体地,本文提出一种应用深度压缩特征的相关滤波器实时跟踪模型(TDFC),使用对抗学习和特征压缩提高跟踪算法的精度和速度[9]。应用对抗学习方法优化图像特征提取过程,使得跟踪场景数据与 特征提取模型VGG-NET的预训练ImageNet[10]数据分布一致,得到针对任务场景的优化图像卷积特征。在此基础上,提出一种基于自编码器的双通道结构模型,将图像特征压缩到低维空间,并通过类别标签信息优化模型的训练过程。
1 研究背景
现有的目标跟踪算法主要分为两类:
1)第一类是基于相关滤波器的算法,此类算法一般具有较高的计算效率。文献[11]提出的KCF 算法利用快速傅里叶变换和循环矩阵降低算法的时间复杂度。SAMF[12]在KCF 的基础上,结合HOG 特征和CN 特征,并对目标尺度变化进行检测。文献[13]与SAMF 类似,除了聚合多种特征外,还提出一种三维滤波器结构,实现对目标尺度的自适应。STC[14]在贝叶斯框架下对跟踪目标及其上下文的时空关系建模,得到目标和周围区域的统计相关性。但是上述相关滤波器跟踪算法会在跟踪精度方面存在局限性。为了解决这一问题,HCF[15]算法在KCF 的基础上,将HOG 特征替换为分层卷积特征,在不同层训练相关滤波器以提高跟踪精度。DeepSRDCF[16]在使用卷积特征的同时还加入惩罚项以改善边界的影响。这些改进算法通过使用图像卷积特征使跟踪精度得到提升,但是图像卷积特征的通道数远多于原始图像的通道数,这会导致计算复杂度提升以及跟踪速度降低。
2)第二类是基于神经网络的算法。文献[17]提出的SO-DLT 算法使用CNN 作为获取特征和分类结果的模型,先在非跟踪数据上进行离线预训练,然后基于跟踪数据调整参数,以解决跟踪过程中数据不足的问题。文献[18]在SO-DLT 思想的基础上,在多域学习模型中使用带标注的视频数据。文献[19]用小型卷积网络将多层卷积特征稀疏化,得到用于跟踪的判别式特征。文献[20]使用循环神经网络对目标物体建模,提升模型鉴别相似物体的能力。文献[21]通过强化学习来学习物体的连续性动作,从而检测目标变化。虽然上述基于神经网络的算法能达到很高的跟踪精度,但随着网络复杂度的提高,跟踪速度不可避免地会有所下降,难以满足实时性的需求。
2 模型和算法
本文提出的模型主要包含特征提取、特征压缩、目标跟踪等步骤。在特征提取步骤中,首先使用对抗学习方法调整跟踪场景图像的分布,然后使用预训练的VGG-NET 提取图像的卷积特征。在特征压缩步骤中,采用基于自编码器的双通道网络结构,结合类别信息优化训练过程以降低图像特征维度,再对双通道特征执行聚合操作得到压缩特征。最后,将压缩特征作为相关滤波器的输入以实现目标跟踪。
2.1 特征提取优化
在使用VGG-NET 提取图像特征时,预训练数据与跟踪场景任务域数据存在分布不一致的问题,该问题会影响图像特征的有效性。因此,本文采用对抗学习方法优化特征提取过程,从而解决该问题。
2.1.1 优化方法的理论支持
为了解决VGG-NET 预训练数据(ImageNet 图像)与跟踪场景任务域数据分布不一致的问题,需要对齐跟踪场景图像和ImageNet 图像的分布,即降低VGG-NET 在跟踪场景数据上的迁移学习误差。根据文献[22]中关于迁移学习模型误差分析的理论,对于∀h∊H,迁移学习模型的期望误差ET(h)有如下性质:

其中,H表示假设函数族(亦可理解为模型族),h是H的一个实例,ES(h)表示迁移学习模型在源域(即ImageNet 图像服从的分布)数据集上的误差项,ET(h)表示迁移学习模型在目标域(即跟踪场景图像服从的分布)数据集上的误差项,dH∆H是衡量一对分类器之间差异的项,λ表示一对分类器间的共有误差。在式(1)右侧的各项中,ES(h)为模型在源域数据上的期望误差,是实验中得到的常量,dH∆H是变量,λ是常数。因此,为了降低VGG-NET 模型在跟踪场景图像上的期望误差(即式(1)左侧的ET(h))的大小,只需对式(1)右侧的dH∆H项进行分析,dH∆H定义如下:

其中,sup 表示最小上界,xS表示源域数据,xT表示目标域数据,E为求期望运算,I为布尔函数,其参数为真时输出1,否则输出0,x为输入样本,S表示源域(即ImageNet 图像服从的分布),T表示目标域(即跟踪场景图像服从的分布),h和h′表示不同的假设函数实例,等价于结构相同但参数不同的分类器模型,h(˙)表示模型输出。
在实际应用中,经过训练的分类器h和h′在源域数据上具有较高的分类精度,即对于∀x~S,h和h′关于输入x的预测值接近标签值,h和h′关于源域数据的输出总体趋于一致,故式(2)中的是接近于0 的较小数值,可从式(2)中移除。因此,式(2)可进一步简化为:

式(3)右边可理解为结构相同但参数不同的分类器h和h′对目标域数据∀x~T的预估值分布差导的期望的最小上界。通过上述过程,可将式(1)中误差项ET(h)的优化问题转化为式(3)中dH∆H的优化问题。
将式(3)中的最小上界改写为min max 形式,得到式(4):

引入本文设计的对抗学习模型结构后,将式(4)改写为:

其中,D1和D2表示结构相同但参数不同的判别器,G表示生成器。式(4)中的x被修正为原始样本经生成器处理后的输出G(x),h被具体化为判别器D1,h′被具体化为判别器D2。
按照式(5)给出的目标进行优化,可以使dH∆H趋近最低值,结合前文对式(1)右侧各项的分析,这一优化操作可以限制迁移学习模型在目标域数据上期望误差ET(h)的上界,从而有利于模型在目标域上的误差趋近最低值。更重要的是,训练后的生成器G可以将跟踪场景图像映射到ImageNet 图像服从的分布上。
2.1.2 优化模型设计
本节根据2.1.1 节中的理论推导设计优化方案。训练数据包含ImageNet的部分标签数据(记作{XS,YS})以及从跟踪场景采集的无标签图像(记作{XT})。
按照2.1.1 节的理论分析,与特征提取优化相关的对抗学习模型应当按照式(5)进行设计和优化,式(5)将式(4)中的模型输出项(h(x)和h′(x))具体化为生成器和判别器的联合输出项(D1°G(x)和D2°G(x)),其中,G、D1、D2三项为对抗学习模型包含的主要结构,G是生成器,D1和D2是判别器,由于式(4)中的h和h′来自同一假设函数族H,因此D1和D2是一对结构相同但参数不同的判别器。基于对抗学习的网络结构如图1 所示,生成器G的输入是从{XS,YS}和{XT}中采样的图像,分别记作(xs,ys)和xT。判别器D1和D2以生成器G的输出为输入,是两个结构相同但参数不同的图像分类器,由卷积层和全连接层组成,P1和P2分别是判别器D1和D2输出的预测向量,用于计算损失函数。
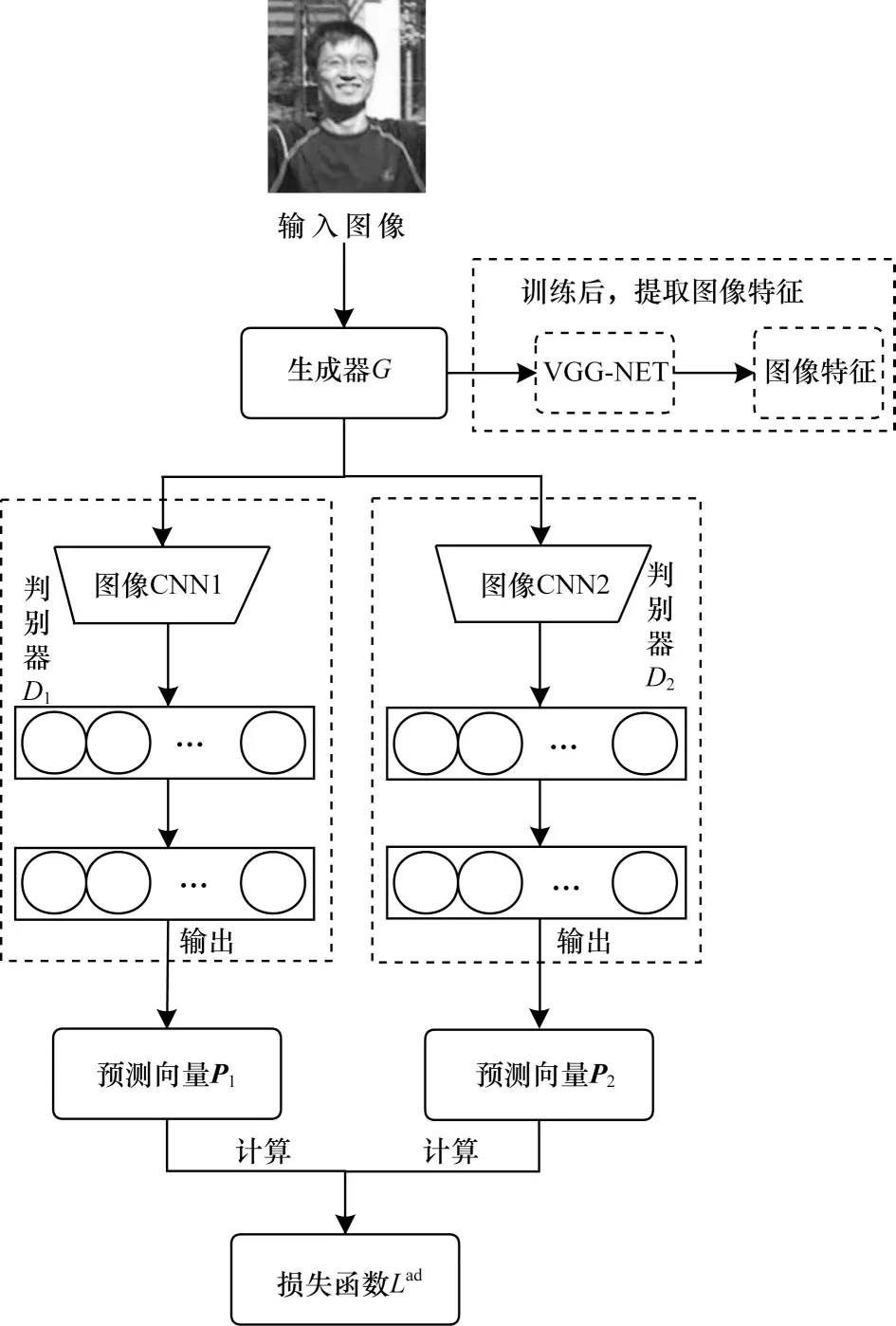
图1 基于对抗学习的网络结构Fig.1 Network structure based on adversarial learning
网络优化目标是降低VGG-NET 在任务场景数据上的误差,提高图像特征的有效性。为达到此目标,需要利用两个判别器间的差异信息,式(5)中的布尔函数项I(D1°G(x)≠D2°G(x))指定了判别器差异的衡量方式,即判别器D1和D2的输出向量差异。在保证整体模型在ImageNet 数据集上具有高分类精度的前提下,最大化判别器D1和D2的预测差异(式(5)中的max);对于生成器G,其输出应使判别器D1和D2的输出一致(式(5)中的min)。对生成器参数和判别器参数进行交替优化,即可优化式(5)中的dH∆H项,使得生成器G能够将任务场景图像映射到ImageNet 数据服从的分布上。
2.1.3 优化步骤
具体优化步骤如下:
步骤1以不同的参数初始化判别器D1和D2。根据2.1.2 节的讨论,首先需要保证整体模型在ImageNet数据集上具有高分类精度,因此,第一步的优化目标是最小化一个交叉熵损失函数,如式(6)所示:

其中,(xs,ys)表示带标签的ImageNet样本,n为类别数量,P1和P2分别是D1和D2的输出向量,i是向量索引。
步骤2固定生成器G,调整判别器D1和D2的参数。在这一步中,结合式(5)及相关讨论,优化目标是对于相同的输入数据,D1和D2输出的预测向量,即P1和P2之间的差异尽可能大。为了衡量这一差异,定义包含距离度量的损失函数,分别如式(7)和式(8)所示:
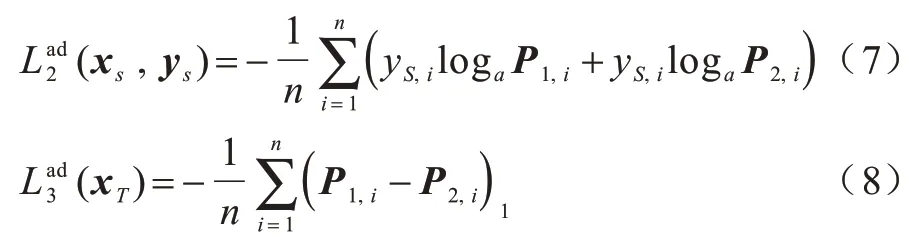
其中,|˙|1表示L1 范数。式(7)为分类损失项,适用于带标签的ImageNet 数据,由于模型优化依赖的式(5)的推导前提是模型实例h和h'在源域数据上具有高分类精度,因此需要式(7)来提升模型对ImageNet 样本的分类精度。式(8)为距离度量项,适用于无标签的任务场景图像。式(7)和式(8)共同构成本步骤的优化目标。
步骤3固定判别器D1和D2,调整生成器G的参数。在这一步中,优化目标是输入图像经G处理后,D1和D2的输出尽可能一致,损失函数如式(9)所示:

参考文献[23]中对抗生成网络的训练过程,特征提取优化模型具体的训练方法如下:
1)在ImageNet 数据上训练生成器G和判别器D1、D(2即上文步骤1)。
2)调整判别器D1和D2,最大化预测差异(即上文步骤2)。
3)调整生成器G,最小化预测差异(即上文步骤3)。
4)重复上述第2 步和第3 步,直至达到最大迭代次数。
随着损失函数的收敛,经过调整的生成器G可以将任务场景图像映射到ImageNet 数据服从的分布上,从而解决数据分布不匹配的问题。
经过本文设计的优化方案,对于给定的跟踪场景图像,使用生成器G对其处理后,将G的输出作为VGGNET 的输入,即可得到更有效的图像卷积特征。
2.1.4 特征提取模型实现细节
本文生成器G采用全卷积结构,判别器D1、D2是包含一组卷积层和两个全连接层的图像分类器,每一个卷积层中卷积核空间上的大小为3×3,全连接层的神经元数量分别为2 048 和1 024。取VGG-NET的第二层feature map 作为图像特征,因此,输出维度是224×224×64。模型训练时批量大小为16,采用ADAM[24]优化算法来优化损失函数,学习率设置为10-4,其他超参数取文献[24]中的默认值。
2.2 双通道自编码器
自编码器是一种无监督特征压缩方法,通过优化重构成本,能在保留重要信息的同时去除数据中的冗余。为了实现高压缩率,自编码器包含多个隐藏层,第i个编码器层的计算方式为:,从而将图像卷积特征的通道数逐层降低。本文方法采用双通道自编码器结构和特征聚合操作来提高模型的泛化能力。
双通道自编码器的模型结构如图2 所示。模型以端到端的方式进行训练,输入是VGG-NET 输出的图像卷积特征。编码器1 和解码器1 组成一个卷积自编码器,每一个卷积层中卷积核空间上的大小是3×3,激活函数是relu 函数。编码器2 和解码器2 组成一个去噪自编码器,样本输入到去噪自编码器之前,按照一定概率对其加入噪声,噪声分三种:第一种是随机将图像特征中的值置为0 或高斯噪声,这类似于信息传输中的随机扰乱;第二种是随机选取特征中的一个通道,将该通道上的值置为0;第三种是随机调换特征中两个区域位置下所有通道的值,由于卷积层平移等变的性质,这相当于在原始图像中执行区域互换,可以修正位置因素对特征的影响。在上述过程中,每个样本至多被加入一种噪声。

图2 双通道自编码器网络结构Fig.2 Network structure of dual channel autoencoder
深度自编码器在应用时容易出现过拟合问题,本文方法采取两个措施来防止过拟合:
1)第一个措施源自压缩特征应保留足够判别式信息的思想,即压缩后的特征可通过线性分类器预测其原有的类别标签。具体的实现方式如图2 所示“,压缩特征1”和“压缩特征2”经“特征聚合”(聚合函数的具体形式在下文介绍)操作后输入到一个“线性分类器”中,该“线性分类器”预测输入的类别标签,然后根据预测结果计算判别损失,损失函数如式(10)所示:

其中,cS表示带标签ImageNet 样本xS的压缩特征,yS是xS的标签,w是线性分类器的参数矩阵,表示平方L2 范数。
2)第二个措施是引入多级重构误差函数,除了考虑完整自编码器中输入和输出间的重构误差,还考虑自编码器子结构的重构误差,损失函数如式(11)所示:
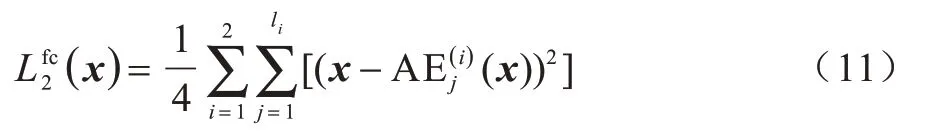
其中,x表示ImageNet 样本特征或跟踪场景样本特征,i是双通道分支索引,AE(i)指代图2 结构中的两个自编码器之一,li表示相应自编码器中编码器结构的层数,由于自编码器结构对称的特点,解码器的层数也是li,AEj表示自编码器的子结构,即AE1表示保留编码器的第一个隐藏层、解码器的最后一个隐藏层而组成的子结构,AE2表示保留编码器的前两个隐藏层、解码器的最后两个隐藏层而组成的子结构,AEj表示保留编码器的前j个隐藏层、解码器的最后j个隐藏层而组成的子结构,AEl则表示完整的自编码器结构。
结合式(10)、式(11)可以得到特征压缩过程的整体优化目标:

其中,超参数α衡量损失函数各部分的重要程度。
经过以上两个措施,能够有效防止模型出现过拟合问题。此外,训练过程还应用数据增强方法进一步防止过拟合问题,包括水平翻转、竖直翻转、色调变化、对比度变化等操作。
在图2 中,双通道自编码器输出的降维特征还需要经过特征聚合操作,以提高模型的泛化能力。聚合函数中的参数能够与模型其他部分一同进行端到端的训练,其具体形式如下:
1)线性聚合,这种聚合方式假设每一个自编码器起到同等作用,如式(13)所示:

其中,c是聚合后的压缩特征,i是双通道分支索引,f是对应分支的降维特征,m是变换矩阵。
2)加权线性聚合,简单的线性聚合不能反映每个特征的重要性差异,因此,加权线性聚合方式为每一种特征赋予一定的权重,如式(14)所示:

其中,w是权重向量。
3)加权非线性聚合,这种聚合方式引入非线性变换,提高聚合层的表达能力,从而建模更复杂的统计相关性,如式(15)所示:

其中,σ表示sigmoid 函数。
对于上述三种聚合方式,线性聚合的参数量最少,因此,其聚合能力最弱;加权线性聚合和加权非线性聚合对模型总体性能的影响差别不大,这是因为先前的特征提取优化和特征压缩都是非线性过程,所以加权非线性聚合中σ函数的作用不是特别明显。
本文卷积自编码器的层数为4 层,去噪自编码器为6 层。特征样本输入到去噪自编码器前,被添加噪声的几率为30%。特征融合方式选择线性加权聚合。训练时的批量大小为16,采用ADAM 优化算子,学习率设置为2×10-6,算子超参数取文献[24]中的默认值。
基于本节设计的模型结构和优化方法,可以实现图像特征的高效压缩,提高算法的计算效率。
2.3 相关滤波器
傅里叶域循环矩阵的性质使得经过训练的相关滤波器能以较低的计算开销完成目标跟踪任务。在本文模型中,为了对场景中的目标进行跟踪,需要将2.2 节得到的压缩特征输入相关滤波器,以得到跟踪结果。相关滤波器的参数可表示为:

其中,w是相关滤波器参数,F-1是逆傅里叶变换,c为图像特征,r为响应窗口,c′和r′为相应向量经过傅里叶变换的结果,为共轭向量,λ为常数。
按照式(16)更新相关滤波器后,给定待跟踪的图像特征,计算得到的响应窗口如式(17)所示:

其中,cnew是待跟踪图像特征,是共轭向量,w′是w经傅里叶变换的结果。
通过响应窗口r即可得到目标跟踪结果。相关滤波器是本文算法在功能实现时的重要一环,相关滤波器的原理和其他细节本文不再赘述。
3 实验结果与分析
3.1 训练集和评估方式
本文模型的训练数据来自ImageNet[10]和OTB-100数据集[25]。为了评估算法的性能,在实验中统计算法的跟踪精度和跟踪速度(FPS)信息。实验中算法的跟踪精度基于“Location error threshold”和“Overlap threshold”计算而得。其中,基于“Location error threshold”的跟踪精度指算法估计的目标位置与人工标注中心点间的距离小于给定阈值的视频帧所占的百分比;基于“Overlap threshold”的跟踪精度指算法估计的目标范围与人工标注框间重叠比例大于给定阈值的视频帧所占的百分比。
实验中所使用的软硬件平台设置:硬件环境为Intel i7-7700K CPU @ 4.20 GHz,16 GB 内存,NVIDIA GTX1080Ti GPU;软件环境为Python3.6,keras,tensorflow,Matlab。
3.2 模型性能分析
在OTB-100 数据集上验证本文跟踪算法及其他算法的效果,相关量化指标结果如表1 和表2 所示,表中记录的跟踪精度是基于“Location error threshold”为20像素所计算,默认的特征聚合方式为加权线性聚合。
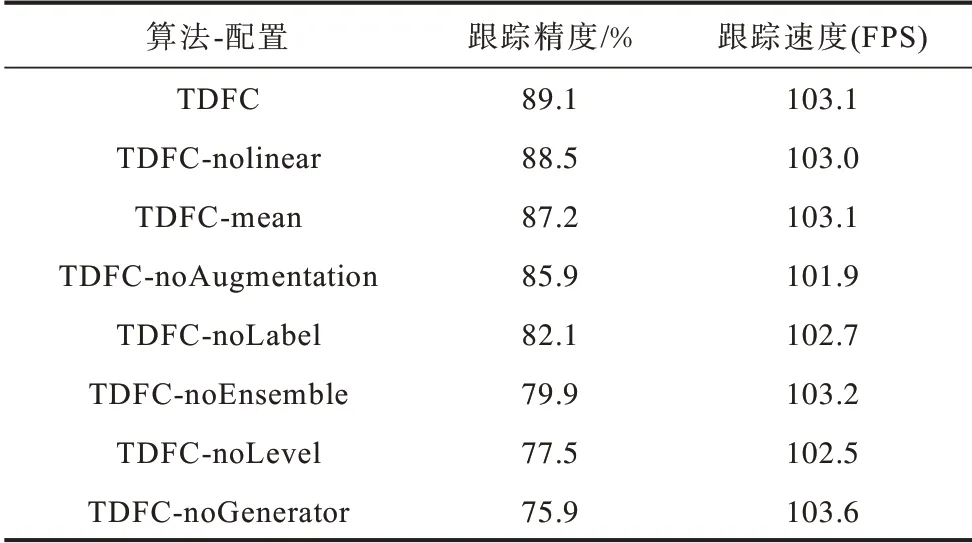
表1 本文算法在不同配置下的性能比较Table 1 Performance comparison of this algorithm under different configurations

表2 不同跟踪算法的性能比较Table 2 Performance comparison of different tracking algorithms
表1 统计本文算法在不同配置下的跟踪精度和速度,TDFC 是本文算法的最优配置,TDFC-nolinear 将聚合函数改为加权非线性聚合,TDFC-mean 将聚合函数改为线性聚合,TDFC-noAugmentation 中移除了2.2 节提到的数据增强处理,TDFC-noLabel 中训练双通道自编码器时忽略了判别式损失,仅考虑重构损失,TDFC-noEnsemble 中移除了双通道自编码器结构和特征聚合操作,仅使用两个分支中的去噪自编码器,TDFCnoLevel 中训练双通道自编码器时将多级重构损失简化为完整自编码器结构输入层和输出层间的重构损失,TDFC-noGenerator 在提取图像卷积特征前移除了基于对抗学习的优化步骤。表2 统计本文算法以及其他跟踪算法的跟踪性能,对比算法包括SCT[26]、SiamFC[27]、DSST[13]、KCF[11]、ADNET[21]、SANET[20]、FCNT[19]、DeepSRDCF[16],以上算法均按照原参考文献设计实现。其中,SCT、SiamFC、DSST、KCF 是实时跟踪算法,ADNET、SANET、FCNT、DeepSRDCF 是非实时跟踪算法,从表2 可以看出,与现有跟踪算法相比,本文算法的跟踪精度损失不超过3%。图3 所示为本文算法在不同配置下的性能统计信息,其中,图3(a)的横轴统计量为“Location error threshold”,图3(b)的横轴统计量为“Overlap threshold”。

图3 本文算法在不同配置下的跟踪精度统计Fig.3 The tracking accuracy statistics of the algorithm under different configurations
对比上述结果可以看出:聚合函数的选择对跟踪效果有一定影响,使用非线性聚合的TDFC-nolinear 由于σ函数引起的梯度消失,模型更难以训练,其精度比使用加权线性聚合的TDFC 略低;与使用线性聚合的TDFC-mean 相比,TDFC 有1.9%的跟踪精度提升,线性聚合的参数量相对更少,不能充分反映模型间重要程度的差异;与TDFC-noAugmentation 的对比说明应用数据增强方法给模型带来了3.2%的跟踪精度提升;与TDFC-noLabel 相比,TDFC 有7%的精度提升,说明通过保留判别式信息,能够有效防止自编码器出现过拟合,提高算法的性能;与TDFC-noEnsemble 相比,TDFC的跟踪精度有9.2%的提升,表明双通道自编码器结构和特征聚合提升了模型的泛化性,得到的压缩特征有助于提高跟踪精度;与TDFC-noLevel 相比,TDFC 有11.6%的精度提升,说明2.2 节定义的多级重构损失函数有助于改进自编码器模型的训练,提高最终的跟踪精度;与TDFC-noGenerator 相比,TDFC 有13.2%的精度提升,说明2.1 节提出的迁移学习分布不匹配问题确实存在,基于对抗学习的优化方法能够解决此问题,有助于提高跟踪算法的精度。
图4 所示为特征提取优化模型的收敛情况,可以看出,在距离损失逐渐降低的同时,判别器D1和D2对训练数据的平均分类精度逐渐升高,当迭代(epoch)次数达到45 时,模型趋于收敛。以上数据和分析结果表明本文设计中的各步骤具有有效性。

图4 距离损失函数的收敛情况Fig.4 Convergence of distance loss function
为了进一步验证2.1 节中对抗学习方法的有效性,用t-SNE[28]工具对部分ImageNet 数据和跟踪场景数据进行降维处理及可视化操作,数据集可视化情况如图5 所示。

图5 ImageNet 数据和跟踪场景数据分布的可视化效果Fig.5 Visualization of distribution of ImageNet data and tracking scene data
图5(a)展示了未经2.1 节对抗学习方法优化的图像数据分布,其中,ImageNet数据展现出一定的可分性,跟踪场景数据的分布特征并不明显,与ImageNet 数据显示出不一致的分布情况;图5(b)展示了经过2.1 节对抗学习方法优化后的数据分布情况,可以发现,优化后数据的分布趋于一致,虽然跟踪场景数据与ImageNet数据分布未完全匹配,但跟踪场景数据呈现出与ImageNet 数据聚类中心保持一致的趋势,并呈现出一定的可分性,进一步验证了对抗学习方法对解决数据分布不匹配问题的有效性。
选择最优算法配置TDFC(本文模型)并与其他目标跟踪算法进行对比实验。图6 所示为各算法的性能统计信息,其中,图6(a)的横轴统计量为“Location error threshold”,图6(b)的横轴统计量为“Overlap threshold”。

图6 不同跟踪算法的跟踪精度统计Fig.6 Tracking accuracy statistics of different tracking algorithms
通过上述跟踪算法的性能比较结果可以看出,本文设计的对抗学习方法和高效特征压缩使得TDFC 的跟踪精度和速度均高于SCT、SiamFC 和DSST 算法。与KCF 相比,TDFC 有14.6%的跟踪精度提升,虽然跟踪速度低于KCF,但103.1FPS 的跟踪速度足以满足实时跟踪的需求,符合精度与速度兼具的特点。综上,与其他跟踪算法相比,本文算法能以更高的精度对目标进行实时跟踪。
图7所示为本文算法以及其他跟踪算法在OTB-100数据集上的部分跟踪效果。

图7 不同算法的跟踪效果对比Fig.7 Tracking effect comparison of different algorithms
4 结束语
本文提出一种基于对抗学习和特征压缩的高精度实时跟踪算法。使用对抗学习方法优化图像特征提取过程,设计双通道自编码器结构压缩图像特征并结合类别信息优化训练过程。实验结果表明,相比现有的实时跟踪算法,该算法具有明显的精度优势,且在有限的精度损失下能够取得较大的速度提升。下一步将降低本文算法在跟踪时的计算复杂度,并将其扩展到DCF、SO-DLT 等其他跟踪框架中。
猜你喜欢
现代临床医学(2022年5期)2022-09-28
北京航空航天大学学报(2021年9期)2021-11-02
昆明医科大学学报(2021年4期)2021-07-23
电子制作(2019年11期)2019-07-04
成都信息工程大学学报(2018年3期)2018-08-29
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年7期)2018-01-19
电子器件(2015年5期)2015-12-29
电子设计工程(2015年16期)2015-02-27
电测与仪表(2014年13期)2014-04-04
