
领域自适应研究综述
2021-06-18 07:31李晶晶孟利超申恒涛
计算机工程 2021年6期
李晶晶,孟利超,张 可,2,鲁 珂,申恒涛
(1.电子科技大学 计算机科学与工程学院,成都 611731;2.电子信息控制重点实验室,成都 610000)
0 概述
在海量数据的支撑下,机器学习尤其是深度学习算法在计算机视觉、自然语言处理等领域得到广泛应用并取得了较大成功。机器学习的理想应用场景是有大量带标记的训练实例,并且训练数据与测试数据具有相同的分布。然而,在许多现实应用中,收集足够的带标记训练数据通常耗时、代价昂贵甚至无法实现。同时,在机器学习被使用的诸多领域中,数据独立同分布的假设往往并不成立。数据分布存在差异导致传统的机器学习算法训练得到的模型往往不能在相似的新领域中取得预期结果,这限制了机器学习模型的泛化能力和知识复用能力。
迁移学习和领域自适应技术可以改善机器学习模型在跨领域任务中的性能。当目标领域中无法获得大量带标签数据用于训练具有良好性能的机器学习模型时,可以考虑在不同但相关的有大量带标签数据可以被获取的辅助领域进行模型预训练,然后对训练好的模型进行调整并应用于目标领域,这克服了实际应用中目标域难以获取带标签数据的困境。然而,跨域的数据分布差异成为了模型迁移的障碍。领域自适应旨在学习一个模型使得在辅助领域获取的知识能够在目标领域较好地得到泛化,引入领域自适应技术可以减小辅助领域与目标领域的数据分布差异,从而实现领域不变知识的跨域迁移和复用。领域自适应是机器学习与计算机视觉范畴内的前沿研究方向之一,在生物信息学等方面有极大的应用前景。迁移学习和领域自适应技术有望处理目标领域标注数据稀缺的问题,避免从头进行模型训练的高额成本,从而提高机器学习模型的普适性和知识迁移复用的能力,因此,迁移学习与领域自适应具备较大的理论研究价值和广阔的应用前景。
本文总结国内外学者对领域自适应技术的研究现状,介绍领域自适应的相关概念、算法分类、代表性方法、典型应用以及目前存在的挑战,在此基础上,对领域自适应技术的发展趋势及未来研究方向进行展望。
1 研究现状
迁移学习试图让机器学习人类的类比学习和“举一反三”的能力,迁移学习受到人类可以智能地应用以前学习到的知识来更快更好地解决新问题这一事实的启发。1995 年,NIPS 关于“学会学习”的研讨会讨论了机器学习领域的迁移学习基本动机,自1995 年之后,迁移学习以“学会学习”“知识迁移”“终生学习”“多任务学习”“归纳迁移”“增量学习”等不同的名称出现,逐渐引起人们的关注。2005 年,美国国防部高级研究计划局(DARPA)的信息处理技术办公室(IPTO)对迁移学习进行新的定义:一个系统对先前学习到的知识或技能进行识别并将其运用于新任务的能力。2010 年发表于TKDE(IEEE Transactions on Knowledge and Data Engineering)的综述论文A Survey on Transfer Learning 系统阐述了迁移学习的研究历程,提出迁移学习的形式化定义及分类,并将领域自适应对应于迁移学习的子领域之一。
在随后的理论研究中,浅层域适应的常用算法主要分为基于实例的DA 和基于特征的DA[1]。文献[1]将深度DA 分为基于差异、基于对抗和基于重建三大类。文献[2]将其分为基于实例、基于映射、基于网络和基于对抗四大类。文献[3-4]从数据和模型的角度对迁移学习和领域自适应的多种代表性方法进行概述。文献[5]关注单源无监督的域适应场景,特别是该设定下的深度域适应方法,根据域偏移损失和生成/判别设定的不同,将深度域适应方法归类为基于差异的方法、基于对抗生成的方法、基于对抗判别的方法和基于自监督的方法四类。文献[6-7]侧重于从特征选择、特征空间对齐的角度对域适应算法进行研究,文献[8-9]基于对抗学习的思想进行算法的拓展和改进。文献[10]结合元学习、对抗学习、正则化的思想,提出基于元学习的权重时序正则化域对抗网络。文献[11]从领域分布差异、对抗、重构和样本生成4 个角度对深度域适应方法进行综述,并对跨域标签空间不同的复杂场景进行概述。
在域适应的应用方面,文献[12]总结域适应在诸如图像分类、目标检测、语义分割、姿态估计、视频动作检测等计算机视觉领域中的应用,文献[3]总结域适应方法在医学影像与计算机辅助诊断、生物序列分析、交通场景识别、推荐系统等领域的应用。此外,域适应在文本分类、情感分析、相关性提取、机器翻译等自然语言处理领域也得到了广泛应用[13]。
本文在上述研究的基础上,围绕域适应的概念、分类、代表方法、典型应用、现存挑战等方面进行研究和分析。
2 领域自适应
2.1 问题定义与基础理论
参考文献[14],本文先给出域、任务、迁移学习这3 个相关概念的定义,随后给出领域自适应的形式化定义。
定义1(领域D)一个领域D 由d 维的特征空间X 和边缘概率分布P(X)两个部分组成,其中,X 是n 个样本的集合,每个样本对应d 维特征空间X 中的一个特征向量,即X={x1,x2,…,xn}⊂X,因此,可用D={X,P(X)}来表示一个领域[14]。
定义2(任务T)给定一个特定的领域D={X,P(X)},一个任务T 由标签空间Y 和类别预测函数f(˙)两个部分组成,给定一个实例的特征向量表示,类别预测函数f(˙)可以预测其对应的类别标签f(x),从概率的角度,可表示为边缘概率分布P(y|x),因此,可用T={Y,P(Y|X)}来表示给定领域后的一个任务[14]。
进一步定义源域DS和目标域DT,源域数据定义为,其 中,表示源域的数据实例,为对应的类别标签。同样地,目标域数据定义为,其 中,表示目标域的输入数 据,为对应类别预测函数的输出。在通常情况下,源域中数据量丰富且类别标签可获取,而目标域中数据量较少,且往往无法获取其真实的类别标签,即通常存在0 ≤nT≪nS。
定义3(迁移学习)给定一个源域DS和源学习任务TS,目标域DT和目标学习任务TT,在DS≠DT或者TS≠TT,即源域和目标域不相同的设定下,迁移学习旨在利用源域DS和源学习任务TS的知识来帮助提高目标域DT中目标预测函数fT(˙)的学习性能[14]。
定义4(领域自适应)在迁移学习的设定中,假定2 个域待解决的任务相同,即TS=TT,通常这一任务为分类任务,假定标签空间在2 个域中共享,即Y=YS=YT,本文研究这一设定下知识的跨域迁移复用[12]问题,领域自适应作为迁移学习的子领域之一而出现。
2.2 算法分类
领域自适应的研究场景可按照不同维度进行划分,本文将从数据标签是否可获取、参与域的数量、跨域数据特征空间的构成3 个维度对域适应算法进行分类,并简要介绍与域适应相关的其他领域。图1所示为算法分类的整体框架。
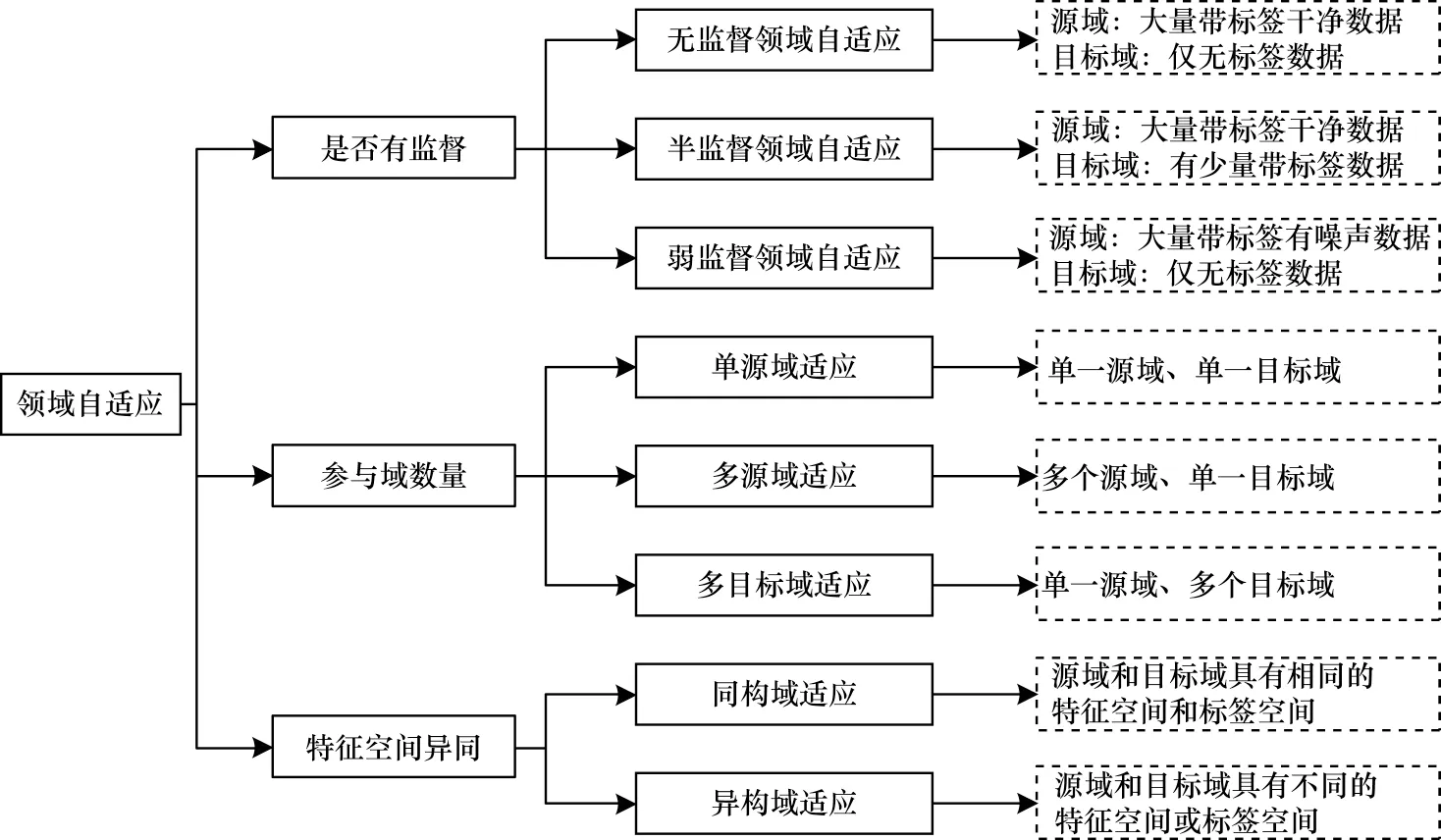
图1 领域自适应算法分类整体框架Fig.1 Overall framework of domain adaptation algorithms classification
2.2.1 有无监督分类
根据源域和目标域数据标签是否可获取及其质量,可将域适应分为无监督域适应(Unsupervised Domain Adaptation,UDA)、半监督域适应(Semi-Supervised Domain Adaptation,SSDA)和弱监督域适应(Weakly-Supervised Domain Adaptation,WSDA)3类,具体如下:
1)无监督领域自适应目前得到广泛研究,其主要研究源域有大量带标签的干净数据、目标域仅有标签不可获取的少量数据的情景,即。
2)半监督领域自适应研究源域有丰富的带标签数据、目标域有标签不可获取的数据和少量带标签数据的情况,即,其中,DT和DU分别代表目标域带标签样本和无标签样本的集合[15-16]。半监督领域自适应与无监督领域自适应的区别在于,进行跨域适配时利用目标域少量带标签的样本信息。当目标域带标签数据样本很少时,半监督域适应也被称为少样本域适应[17]。
3)弱监督领域自适应考虑源域数据不纯净、存在噪声的情况,其基本设定仍为,即源域数据标签可获取,目标域数据标签不可获取,但放宽了源域数据是清洁的这一假设,源域的数据样本可能在特征和标签中包含噪声,其目标是训练模型以降低源域噪声对迁移的负影响,实现无噪声源域样本的正向转移[18]。
2.2.2 参与域数量分类
按照源域和目标域的数量,可以将域适应分为单源域适应、多源域适应和多目标域适应3 类,如图2 所示。

图2 域适应分类示意图Fig.2 Schematic diagram of domain adaptation classification
单源域适应只关注将单一源域的知识迁移到单一目标域的情景。传统的无监督、半监督领域自适应大多属于这一类别。
多源域适应指带标签的数据来源于多个不同的源域,不仅存在源域和目标域数据分布的差异,同时多个源域之间的数据分布也可能不同。文献[19]提出一种分布加权组合的规则,用多个源域分布的加权组合来构建目标分布。DCTN(Deep Cocktail Network)将这一规则用于对抗设置[20]。文献[21]使用多源域自适应的矩匹配网络(M3SDA)来对齐多个源域和目标域之间的分布差异等。
多目标域适应研究将源域的知识迁移到多个无标签目标域的情况,且设定源域和目标域之间、不同的目标域之间均存在数据分布的差异。针对这一设定,文献[22]提出模型参数自适应的方法,文献[23]使用信息论的方法找到所有域的特征共享子空间,以实现源域知识在多个目标域上的迁移。
2.2.3 同构异构分类
根据源域和目标域数据的特征空间是否相同,可将域适应分为同构领域自适应和异构领域自适应两类。
同构领域自适应指源域和目标域样本具有相同的特征空间和标签空间,即XS=XT且YS=YT,并且具有相同的维度,即dS=dT。此类方法主要关注不同领域下的单一相同任务,减少跨域数据分布偏移带来的性能下降问题,从而实现模型或知识的跨域迁移复用。
异构领域自适应指源域和目标域具有不同的特征空间,通常也不重叠,源域和目标域不共享特征/标签,其维度也可能不同,即XS≠XT和/或YS≠YT,且dS≠dT。异构领域自适应更具挑战性,因为在应对跨域数据分布差异的同时,还需要进行特征空间和标签空间的转换,从而适应知识跨域迁移的需求[24]。
2.2.4 领域泛化与小样本学习
本节介绍领域泛化和小样本学习2 个与领域自适应相关的概念。
领域泛化的目标是在目标域不可见的情况下,利用多个源域的带有类别标签和域标签的数据训练得到一个领域泛化的模型[25],其与领域自适应的区别在于,领域泛化在训练阶段不可获取目标域的样本,而领域自适应在训练阶段可以获取无标签的目标域样本。
小样本学习旨在根据给定的少量带标签样本和带标签的基类学习新的类别[15]。小样本学习和半监督领域自适应问题具有不同的假设:小样本学习不使用无标签的数据,其目标是获取关于新类别的知识;半监督领域自适应问题使用目标域无标签的样本用于训练,并且其目标是对新的领域中具有相同类别的样本进行适配。
2.3 基于距离度量的方法
为了减少源域和目标域的数据分布差异,可以基于某种差异度量指标将源域和目标域特征映射到一个公共的再生核希尔伯特空间(RKHS)中,通过最小化域间分布差异的度量指标学习特征变换,实现源域和目标域的分布对齐,这便是基于距离度量的方法的基本思想。度量域间分布差异的指标包括KL 散度、最大均值差异(MMD)、Wasserstein 距离等。基于距离度量的典型方法及其特征总结如表1 所示。

表1 基于距离度量的方法Table 1 Methods based on distance measurement
2.3.1 KL 散度
KL 散度是两个概率分布间差异的非对称性度量。给定两个概率分布P∊Rk×1、Q∊Rk×1,Q与P的KL 散度表示用Q近似P时所丢失的信息,定义[26]为:

文献[27]将KL 散度与原型网络的思想相结合,提出可迁移原型网络(Transferrable Prototypical Networks,TPN),用于解决无监督领域自适应问题,其基本思想是:首先将目标域中的每个样本与源域中最近的原型进行匹配,并为其分配“伪标签”;随后在仅基于源域数据、仅基于目标域数据、基于源域和目标域数据3 种情况下分别计算得到各个类的原型;接着进行端到端的训练,同时最小化不同设定下类原型的差异以及每个样本在三种类原型下分类的类别概率分布差异。在TPN 中,可以使用MMD 度量类原型的差异,通过KL 散度度量样本在不同类原型下分类的概率分布差异。
2.3.2 最大均值差异
最大均值差异(MMD)是度量跨域分布差异时被广泛使用的度量指标。给定源域和目标域的数据分布XS、XT,MMD 定义为[1]:
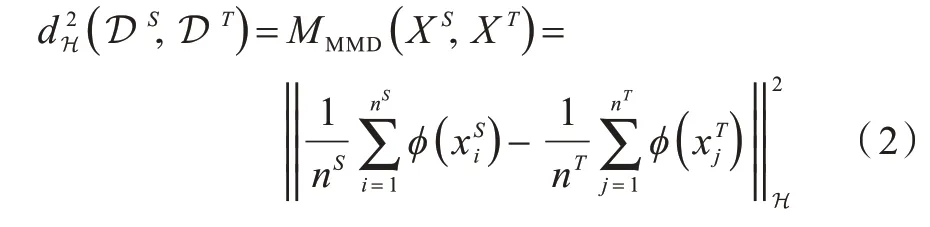
其中,ϕ表示将原始数据映射到一个再生核希尔伯特空间中的核函数。MMD 通过计算在再生核希尔伯特空间中域间实例均值之间的差异来代表数据分布的差异。
在浅层域适应方法中,文献[28]提出迁移成分分析方法(TCA)[28]。TCA 以MMD 来度量边缘分布的差异,以散点矩阵作为约束条件来学习一个从经验核特征空间到低维特征空间的线性映射。此外,文献[29]在TCA 的基础上引入MMD 和流形学习的思想,提出局部保留联合分布适配的方法LPJT。LPJT 期望训练得到一个特征变换矩阵,将两个域的样本映射到一个低维特征空间,并在这个特征空间中同时实现边缘概率分布和条件概率分布的最小化。
在深度域适应中,文献[30]提出深度适应网络(DAN),在假设条件概率分布保持不变的前提下,在AlexNet 网络的后3 层全连接层上添加对域间分布差异的度量,将最大均值差异(MMD)度量延展为多核最大均值差异(MK-MMD)度量,其网络架构如图3 所示。
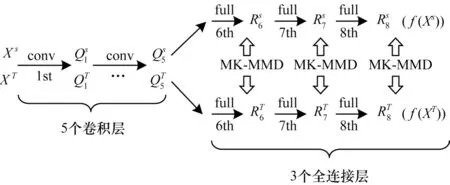
图3 深度适应网络架构Fig.3 Architecture of deep adaptation network
进一步考虑条件分布的偏移,联合适配网络(JAN)[31]根据联合最大平均差异(JMMD)度量,对输入特征和输出标签的联合分布差异在多个领域特定层中进行适配。JAN 网络架构如图4 所示。
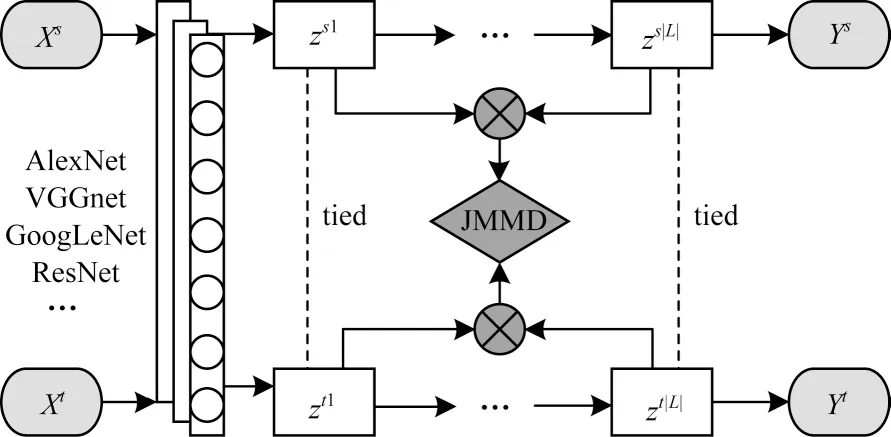
图4 JAN 网络架构Fig.4 Architecture of JAN network
文献[32]提出基于MMD 对边缘分布和条件分布进行适配的DTN。除了使用MMD 进行特征的适配外,残差迁移网络(RTN)[33]还添加了残差模块用于分类器的自适应。RTN 网络架构如图5 所示。

图5 RTN 网络架构Fig.5 Architecture of RTN network
2.3.3 Wasserstein 距离
相比于KL 散度、JS 散度等分布差异度量指标,Wasserstein 距离考虑概率空间的基本几何性质,并且能够比较无重叠的分布之间的差异。两种分布PS和PT之间的Wasserstein 距离或推土机距离定义[34]为:
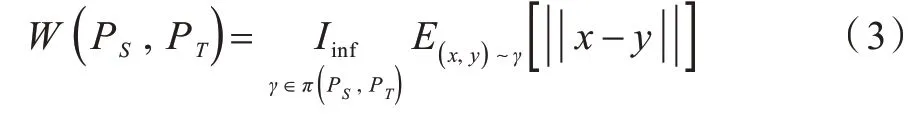
其中,Iinf表示最大下界,π(PS,PT)表示PS、PT中所有可能的联合分布。Wasserstein 距离可以理解为将概率分布PS转换为PT的最小传输质量,该极小值(最大下界)难以处理,因此,可以使用Wasserstein 距离的Kantorovich-Rubinstein 对偶性,其定义[34]为:

其中,Ssup是所有1-Lipschitz函数f:X→R 的最小上限。
文献[35]提出一种基于Wasserstein 距离减小跨域特征分布差异的领域不变特征学习方法,命名为Wasserstein 距离引导下的表示学习(WDGRL)。WDGRL 训练一个领域评价网络,以估计源特征表示与目标特征表示之间的经验Wasserstein 距离,同时以对抗的方式训练特征提取网络以最小化经验Wasserstein距离。通过迭代对抗训练,最终学习到跨域的领域不变特征表示。文献[36]提出分层Wasserstein 差异(SWD),旨在捕获特定于某一任务的分类器的输出之间自然的差异性概念,其基于几何理论,提出检测远离源域支持的目标样本的方法,并能够以端到端的可训练方式进行有效的分布对齐。
2.3.4 最大密度差异
给定源域DS和目标域DT,源域和目标域数据样本为XS和XT,源域和目标域的数据分布为P和Q,最大密度差异(MDD)定义为:
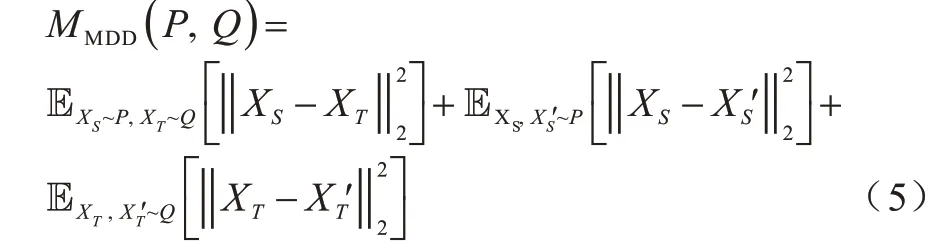
其中,和分别是XS和XT独立同分布的拷贝,表示欧几里得范式距离的平方。式(5)右侧第一项最小化P和Q之间的域间差异,后两项分别最大化P和Q中的类内密度。如图6 所示,MDD 在最小化域间差异的同时,能够最大化域内的密度,并且与广泛使用的MMD 不同,MDD 的实用变体可以被平稳有效地整合到深度域自适应体系结构中,并通过随机梯度下降进行优化。

图6 最大密度差异示意图Fig.6 Schematic diagram of maximum density difference
文献[37]提出最大密度差异(MDD)的概念,并将其简化后加入到对抗性领域自适应的框架中,提出一种既具有对抗性训练又具有度量学习能力的对抗性紧密匹配(ATM)领域自适应方法。
2.3.5 其他差异度量方法
文献[38]提出利用阶矩差来匹配概率分布的高阶中心矩,利用矩序列对概率分布的等效表示定义一个新的距离函数,称为中心矩差异(CMD)。文献[39]使用高阶统计量(主要是三阶和四阶统计量)进行域匹配,提出一种高阶矩匹配方法(HoMM),并将其进一步扩展到再生核希尔伯特空间中。
2.4 基于对抗学习的方法
借鉴生成式对抗网络的思想,可以在深度方法中引入对抗的思路来进行领域自适应。基于对抗的方法可分为对抗性判别和对抗性生成两类。文献[40]从所使用损失函数的类型、是否进行权值共享以及所基于的模型为生成式模型还是判别式模型3 个角度,对基于对抗学习的域适应方法进行归类,并提出一个通用的框架,如图7 所示。基于对抗学习的典型方法及其特征总结如表2所示。

图7 基于对抗学习的域适应方法通用框架Fig.7 General framework of domain adaptation methods based on confrontation learning
表2 基于对抗学习的方法分类Table 2 Classification of methods based on confrontation learning
2.4.1 基于对抗性判别的方法
基于对抗性判别的域适应方法虽然使用了不同的对抗策略,但其基本思想都是在域鉴别器上施加一个对抗性目标将域间分布差异的度量转化为在潜在特征空间中进行领域混淆,以此对特征提取器进行训练从而实现特征级的领域自适应。
用C表示利用带标签数据训练得到的样本分类器,用D表示领域鉴别器,用F表示特征提取与表示,θC、θD、θF为分别与之相对应的参数。生成对抗域适应方法的目标是通过对参数θF进行学习来最小化样本分类器的分类损失LC,同时最大化领域鉴别器的判别损失LD,使得特征表示F更具判别性和域不变性。此外,对抗训练的目标是最小化领域鉴别器D的判别损失LD。上述原理可概括为如下的目标函数:
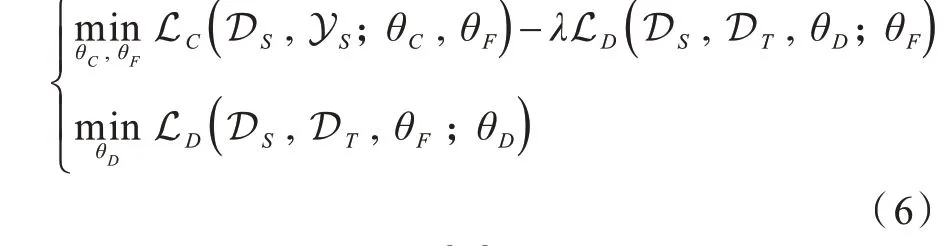
域对抗网络(DANN)[41]基于上述的通用框架而提出,其架构由一个特征提取器、一个分类器和一个领域鉴别器构成,如图8 所示。DANN 中融入了GAN 的生成对抗思想,其训练可以通过插入特定的梯度反转层(GRL)来实现。

图8 DANN 网络架构Fig.8 Architecture of DANN network
文献[40]提出对抗判别域适应(Adversarial Discriminative Domain Adaptation,ADDA)方法,使用一个标签翻转的GAN 损失将优化过程分为生成器和判别器两个独立的目标,其目标函数设置为:

其中,MS表示源特征提取器,Mt表示目标特征提取器。式(7)第一项计算源域样本类别标签预测的损失,第二项计算域鉴别器的损失,第三项计算经过域适应后目标域样本的分类损失。
除了对齐边缘分布外,文献[42]提出条件对抗域适应方法(CDAN),考虑对齐条件概率分布来促进两个域间的域适应。在DANN 的基础上,将分类器的预测g作为特征表示f所依赖的条件,通过联合变量h=(f,g)引入分类预测g来对域判别器D附加条件,同时对特征表示f和分类器预测g的跨域协方差进行建模,隐式地解决多模态结构识别问题,提升跨域分布适配的性能。
2.4.2 基于对抗性生成的方法
基于GAN 的生成式方法属于像素级的领域自适应,生成从源域到目标域的图像,并通过训练使得生成的图像与从目标域分布中采样得到的图像相同,从而实现领域的混淆。此外,基于CycleGAN 的损失,学者们提出了一些有效的域适应方法。
HOFFMAN 等[43]提出循环一致对抗域适应方法(CyCADA),在保证语义一致性的同时,在像素级和特征级都进行跨域适配。在适应过程中使用循环一致性损失匹配结构和语义一致性,并基于特定的视觉识别任务来实现语义损失。语义损失既指导总体表示具有判别性,又在映射前后保证了跨域的语义一致性。类似地,TZENG 等[44]使用像素级对齐和特征级对齐对目标检测任务执行领域自适应。
LI 等[45]扩展了先前基于CycleGAN 的研究,将条件对抗域适应方法与循环一致性损失相结合,提出循环一致条件对抗迁移网络(3CATN)方法来对齐两个域。利用特征与对应的类别预测的协方差来部署条件域判别器,以捕获嵌入在数据中的复杂多峰结构,同时考虑到域不变特征变换由两个域共享,可以相互表示的特性,训练两个特征转换器,一个将特征从源域转换到目标域,另一个将特征从目标域转换到源域,并基于两个特征转换器来计算循环一致性损失,由此在捕获数据复杂多峰结构的同时,避免由于条件不正确而造成的负面影响。
2.5 其他代表性方法
2.5.1 基于重构的方法
文献[46]设计基于重构的思想解决领域自适应问题的代表性方法,其提出了深度重构分类网络(DRCN),这是一种联合学习有监督地预测源域标签和无监督地对目标域数据进行重构的卷积网络。DRCN 的编码参数在两个任务之间共享,而解码参数彼此分离,目的是使所学的标签预测函数能够很好地对目标区域内的样本进行分类,从而将数据重构视为支持标签预测自适应的辅助任务。
2.5.2 基于样本选择的方法
在早期的浅层域适应方法中,对实例进行重加权来克服两个域间数据边缘概率分布的偏差从而实现领域自适应,这是最常见的方法之一,其核心思想是计算一个样本实例归属于源域实例或目标域实例的似然比,用这一比例来对样本进行赋权。
通过计算两个域间数据分布的最大均值差异(MMD)来对数据样本加权是常用的方法。此外,基于AdaBoost 的迁移自适应增强方法(TrAdaBoost)[47]也是实例权重法的典型代表,其训练过程如图9 所示,在训练目标分类器的过程中,与传统的AdaBoost方法相同,提高目标域中错误分类实例的权重,同时降低源域中错误分类实例的权重,从而缓解其对训练过程的影响,然后在权重更新后的实例上继续进行目标分类器的训练,如此迭代地更新源域和目标域的实例权重。

图9 TrAdaBoost 方法原理说明Fig.9 Principle explanation of TrAdaBoost method
考虑部分域适应的设定,即目标域的类别少于源域的类别(YT⊆YS)的情景,在这种情况下,具有不同标签的源域实例对于域适应可能具有不同的重要性,往往需要对源域样本加权以实现迁移样本选择。文献[48]提出一种部分域适应的方法,称为基于重要加权对抗网络的领域自适应(IWANDA)。IWANDA由两个特征提取器、两个领域鉴别器和一个标签预测器组成。首先,对源域特征提取器和标签预测器进行预训练;然后,在训练过程中将这两个组件固定;其次,根据第一个领域鉴别器的结果对源域样本加权,如果预测源域实例很可能属于目标域,则该实例极有可能与目标域关联,将被分配较大的权重;最后,对目标域特征提取器与第二个领域鉴别器进行类似于GAN 的对抗训练,以进行参数更新。此外,文献[49]也构建了类似的用于部分迁移学习的选择性对抗网络。
2.6 数据集与实验结果
本节介绍被广泛用于度量不同方法在跨域自适应任务中性能表现的标准数据集,并对代表性方法在典型任务中的实验结果进行总结。
2.6.1 数据集
Digits数字数据集包含MNIST[50]、USPS、SVHN[51]3个数据集,MNIST、USPS 为包含0~9 共10 个数字的具有不同分布的手写数字数据集,MNIST 包含共70 000 张28×28 的灰度图像,其中,60 000 张作为训练数据,10 000张用于测试。USPS包含尺寸为16×16的7 291张和2 007 张灰度图像分别用于训练和测试。SVHN 为街景数字图像数据集,其中的数字图像包含更为复杂的街景背景,该数据集共包含73 257张尺寸为32×32的彩色图像用于训练,以及26 032 张图像用于测试。上述3 个数据集图片样例如图10 所示。

图10 Digits 数据集图片样例Fig.10 Image examples of Digits dataset
Office-31 数据集[52]是经典的视觉域适应基准数据集,包含来自Amazon(A)、DSLR(D)和Webcam(W)三个不同的域、涵盖31 个类别的4 110 张图片,其中,Amazon(A)为电商网站中的展示图片,DSLR(D)为数码单反相机拍摄的图片,Webcam(W)为图像处理软件处理后的图片。A、D、W 数据集的样本数量分别为2 817、498 和795,数据集图片示例如图11 所示。

图11 Office-31 数据集图片示例Fig.11 Image examples of Office-31 dataset
Office-Home 数据集是一个相对较新的基准,包含来自4 个领域65 个类别的15 585 张图片。4 个领域具体如下:
1)艺术(Ar):以素描、绘画、装饰等形式对物体进行的艺术描绘。
2)剪贴画(Cl):剪贴画图像的收集。
3)产品(Pr):没有背景的对象图像,类似于Office 数据集中Amazon 类别的图像。
4)真实世界(RW):用普通相机捕捉到的对象图像。
Ar、Cl、Pr 和RW 域中分别包含2 421、4 379、4 428 和4 357 张图像[53]。
2.6.2 实验结果
在结果评测中,均采用目标域数据样本分类正确率作为算法性能的度量指标。表3 所示为Digits 数据集上几种代表性方法在MNIST→USPS(M→U)、USPS→MNIST(U→M)、SVHN→MNIST(S→M)3 个域适应任务中的测试结果,其中最优结果加粗表示。

表3 不同方法在Digits 数字数据集上的性能对比Table 3 Performance comparison of different methods on Digits digital dataset
表4 所示为在Office-31 数据集上构建的A→D、A→W、D→A、D→W、W→A、W→D 6 个域适应任务中各代表性方法的性能表现。表5所示为Office-Home数据集上12 个跨域适配任务中各方法的性能表现。

表4 不同方法在Office-31 数据集上的性能对比Table 4 Performance comparison of different methods on Office-31 dataset

表5 不同方法在Office-Home 数据集上的性能对比Table 5 Performance comparison of different methods on Office-Home dataset
2.7 典型应用
2.7.1 图像分类
图像分类是计算机视觉应用的基本任务,上述大多数领域自适应算法[32-33]在最初提出时都是用来解决图像分类问题的,并在诸如Digits、Office-31、Office-Home、VisDA-2017 等标准数据集的跨域图像分类任务中测试算法性能。
2.7.2 目标检测
近年来,基于候选区域的卷积神经网络(R-CNNs、Fast R-CNNs 和Faster R-CNNs)在目标检测方面取得了重要进展,然而,训练每个类别检测窗口需要大量带标签的数据,考虑到窗口选择机制与领域无关,深度域适应的方法可用于分类器的跨域适应。大规模自适应检测(LSDA)[54]对目标域的分类层进行训练,然后使用预先训练好的源模型和输出层自适应技术直接更新目标分类参数。文献[55]基于Faster R-CNNs 方法,从特征图和区域自适应两个角度切入,提出改进的域适应多场景目标检测模型,并将其应用于多场景道路车辆检测中。此外,文献[56-58]也致力于研究领域自适应在目标检测领域的应用。
2.7.3 自然语言处理
领域自适应技术已经在自然语言处理领域得到了广泛应用,包括情感分析[59]、文本分类[60]、关系提取[61]、问答系统[62]和机器翻译[63]等方面。
2.7.4 推荐系统
传统的推荐系统通常依赖于用户与项目交互矩阵来进行推荐和预测,这些方法通常需要大量的训练数据才能得出准确的建议。然而,诸如用户的历史交互数据在现实场景中往往稀少。领域自适应技术可以利用来自其他推荐系统(即源域)的数据来帮助在目标域中构建推荐系统。在基于实例的方法中,文献[64]利用源域不确定评级作为约束条件,帮助完成目标域上的评级矩阵分解任务。在基于特征的方法中,文献[65]提出一种称为“坐标系统迁移(CST)”的方法,同时利用用户侧和物品侧的潜在特征。文献[66]基于矩阵分解技术生成用户和物品的特征表示,然后使用深度神经网络来学习跨域的特征映射。此外,文献[67-68]也研究了域适应方法在跨域推荐系统中的应用。
3 现存挑战及未来研究方向
目前已有的领域自适应方法主要分为基于距离度量的方法和基于对抗学习的方法。基于距离度量的方法多使用已有的几种距离度量指标,如MMD等,通过变换形式不断重复使用,但是对度量指标本身的研究非常有限。已有的研究结果表明,仅使用现有的距离度量指标,很难取得令人满意的迁移学习效果。基于对抗学习的方法虽然在近年来得到广泛应用与关注,但是对抗网络中存在泛化和均衡等固有挑战,使得基于对抗学习的方法难以保证模型的泛化能力。
3.1 流式数据与在线持续迁移学习
在已有算法研究中,通常认为可在同一时刻获取大量的源域带标签数据,并且这些数据具有相似的分布,但是在现实应用中,源域的数据往往以流式形态而不断产生,并不能在某一时刻获得大量的数据,同时不同时间产生的源域数据也可能具有不同的数据分布。如何识别源域数据中的概念漂移以及进行增量域适应和在线域适应是有待研究的问题。同时,当数据以不断进化的方式产生时,如何处理不同时期的模型灾难性遗忘问题也成为迁移学习中的难点。当前已有一些学者针对持续学习展开研究,今后可将持续学习和迁移学习相结合,以应对流式数据中存在的挑战。
3.2 语义分歧与开放集迁移学习
目前大多领域自适应算法研究封闭集中的跨域知识迁移,即通常假设源域和目标域共享类别标签,但是在现实场景中,源域和目标域具有相同的类别标签空间这一假设往往并不成立,存在源域数据类别多于目标域、目标域数据类别多于源域等情况。针对前者,文献[48-49]尝试对源域实例加权来增强跨域共享标签实例的重要性;针对后者,可以通过零样本学习、小样本学习的技术学习关于新类别的知识[69-71]。目前,针对开放集的跨域迁移仍有待进一步研究。
3.3 数据隐私与数据访问受限的迁移学习
目前的领域自适应方法大多假设带标签的源域数据可以不受限制地获取,在现实场景中,与目标域相关的源域或辅助领域数据可能来自于另外的机构和个人,可能无法访问数据的全部信息。在此类情况下,如何在进行跨域知识迁移的同时保护数据的隐私是一个重要问题。开发基于模型参数而非数据特征的域适应技术以及开发基于加密数据的域适应技术是可供选择的研究方向。此外,领域泛化为目标域数据访问受限的迁移学习提供了一些思路。
3.4 负迁移
负迁移是领域自适应中被广泛讨论的挑战之一。领域自适应的目标是使用源域的知识来提升目标任务的性能,但是在有些情况下存在引入源域的知识会带来目标模型性能下降的问题,即产生负迁移现象,其原因是源域和目标域具有较低的相关性,相关性越小,则可供迁移的领域不变知识越少,学习到的跨领域噪声越多。如何衡量跨域的可迁移性以及避免负迁移仍是该领域的一个重要问题,未来可设计对应的相关性量化指标。
4 结束语
模型的迁移能力和泛化能力是通用人工智能所面临的两大挑战。领域自适应技术为当前人工智能迈向通用人工智能提供了可行方案,也是在有限标记数据的情况下最大化数据利用率的有效方法。本文针对基于度量学习的方法和基于对抗学习的方法,对领域自适应进行总结,阐述领域自适应的产生背景及国内外研究现状,给出相关概念和领域自适应的形式化定义,并从不同的视角对相关研究领域和方法进行分类。在此基础上,围绕基于距离度量学习的方法和基于对抗学习的方法介绍该领域代表性算法的技术细节,并分析域适应在学界和业界不同领域中的应用情况以及现存的挑战。今后将对领域自适应研究中的现实鸿沟、语义鸿沟、数据隐私和负迁移问题进行分析。
猜你喜欢
系统仿真技术(2022年4期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
上海文化(文化研究)(2022年3期)2022-06-28
读报参考(2022年1期)2022-04-25
数学年刊A辑(中文版)(2022年4期)2022-02-16
科学家(2021年24期)2021-04-25
计算机技术与发展(2020年11期)2020-12-04
数学年刊A辑(中文版)(2019年3期)2019-10-08
中国学术期刊文摘(2016年1期)2016-02-13
电子与信息学报(2015年12期)2015-08-17
