
结合表示学习与嵌入子空间学习的降维方法
2021-06-18 07:31鲍灵浪
计算机工程 2021年6期
陶 洋,鲍灵浪,胡 昊
(重庆邮电大学通信与信息工程学院,重庆 400065)
0 概述
在实际应用中,观察到的样本数据通常位于高维空间,这不仅增加了计算量和存储代价,而且会导致“维数灾难”问题[1]。因此,如何处理高维样本数据已成为计算机视觉领域的研究热点[2]。通过将原始高维数据映射到一个既包含大部分固有信息又保留区分能力[3]的低维子空间是非常具有挑战性的任务,而降维是获得观测数据紧凑低维表示的一种直接有效的方法。
从不同角度对降维算法有若干种分类方式,如根据降维过程是否使用标签信息可分为监督学习[4]和无监督学习。由于在现实场景中无标签数据的获取更为方便,因此无监督学习成为降维过程中的研究重点,如主成分分析(PCA)[5]、局部保留投影(LPP)[6]、领域保留 嵌入(NPE)[7]和 稀疏保留投影(SPP)[8]等算法,都可以被视为基于图的特征提取算法。
遮挡、照明和原始图像中的噪声会严重影响降维算法的性能,因此,基于低秩的特征提取引起了人们的重视,核主成分分析(KPCA)算法[9]和核线性判别分析算法(KLDA)[10]是其中的经典算法。文献[11]提出一种用于特征提取的低秩嵌入(LRE)算法,通过鲁棒线性降维来挖掘观测数据的潜在局部关系。低秩表示(LRR)[12]通过丢弃分解出的噪声部分,可以有效消除噪声、照明和遮挡的影响。考虑到稀疏性能够捕获局部结构的数据信息,低秩模型能够帮助获得全局结构信息,文献[13]提出一种低秩稀疏表示算法。文献[14]提出一种增强的低秩表示(ELRR)方法,其中流形结构被引入以充当正则项。LRR 假定子空间是独立的,但在实际情况下,这种假设是不正确的。为解决这个问题,文献[15]提出一种结构约束的低秩表示算法用于解决不相交的子空间聚类。文献[16]提出的低秩稀疏保留投影(LSPP)算法,则能在保留固有几何结构的同时学习鲁棒表示。
然而,上述算法仅考虑了数据的局部结构或全局结构,即使同时考虑低秩性和稀疏性来捕获数据结构,也无法处理训练样本外的新样本,这是因为目标函数不具有任何映射功能。良好的数据表示并不意味着良好的分类性能,应尽可能同时获得降维(映射函数)和最合适的信息判别表示,但是这两者都不是预先可知的。为解决上述问题,本文提出一种表示学习与嵌入子空间学习相结合的降维算法。利用投影样本的低秩表示对观测样本的相似性判别信息进行编码,同时通过加权稀疏的低秩正则化项来保持投影样本的全局相似性,从而更有效地保护数据的局部结构。在此基础上,通过迭代学习优化稀疏低秩表示和投影矩阵表示过程,最终实现有效分类。
1 低秩稀疏表示
由于本文的工作主要基于低秩稀疏表示,因此本节简要介绍低秩稀疏表示算法。令矩阵X=[x1,x2,…,xn]∊Rm×n是来自c个不同类别的n个训练样本的集合,其中,xi是代表来自X的第i个训练样本的列向量,m是特征维数,其值通常较高。降维算法的目标是获得最佳映射函数P=[p1,p2,…,pd]∊Rm×d,将m维空间中的数据转换为d维子空间数据,其中,d≪m。LRR 是用于从观察数据中保留子空间结构的子空间聚类算法,旨在捕获在给定词典中观察到的数据的最低秩表示。由于秩函数是NP 难问题,同时考虑到实际应用中观测到的数据通常会包含噪声和离群值,因此LRR 的目标函数可以表示为:

其中,‖Z‖*表示核范数,‖E‖l表示数据噪声,根据不同的噪声模型,‖·‖l可以选取不同的范数,λ是一个非负常数,A∊Rd×n代表由许多基向量组成的“字典”,它可以构造一个线性子空间来表示观测到的数据X。当获得式(1)中的最优解Z*和E*时,可以使用AZ*+E*恢复原始观测数据X。为简单起见,选择将观测数据X本身用作式(1)所示模型的“字典”,然后使用增强拉格朗日乘数(ALM)算法[17]获得该优化问题的解。尽管LRR 可以针对聚类问题实现更好的鲁棒性能,但其不能用于获取投影矩阵进行降维。因此,文献[16]提出一种用于寻找低维映射矩阵的低秩稀疏保持投影算法,其目标函数为:

其中,diag(Z)=0 用于约束矩阵Z的对角元素为0,γ是平衡参数。式(2)所示模型通过同时对表示系数施加低秩约束和稀疏约束来得到数据的全局结构及内部的局部结构。得到低秩稀疏表示矩阵Z后,将其嵌入低维子空间以寻找投影矩阵,即:

其中,zi是样本xi对应的低秩稀疏表示,P是投影矩阵,PTX即为降维后的低维空间。
2 本文降维算法
低秩稀疏表示算法虽然可以捕获数据的全局结构和内部子空间的局部结构,但该算法缺少映射函数,无法直接用于特征提取进行降维。本文提出一种表示学习与嵌入子空间学习相结合的降维算法,通过将低秩表示、稀疏表示和降维集成到一个统一的框架中,并设计一种交替优化策略,使投影矩阵和加权稀疏的低秩表示系数矩阵联合学习和优化。
2.1 目标函数构建
在本文算法中,低秩表示、加权稀疏表示和低维子空间可以联合学习,以实现更鲁棒的特征提取。其中,低秩表示可以获得观测样本的全局结构信息,加权稀疏表示可以更好地保持所观察样本的局部几何结构关系,低维子空间可以学习用于降维的映射函数P。本文算法的目标函数表示为:

其中,第1 项是低秩约束,第2 项是M⊙Z的l1范数,第3项表示对数据噪声E施加l2,1范数,第4项表示低维子空间学习。本文将加权稀疏约束条件集成到LRR 算法中以获得更具区分性的低秩表示。在目标函数中,参数γ、λ和β均为正数。对于权重M的构造,本文考虑使用[18]样本的形状交互信息。令样本X的瘦形奇异值分解为,r为矩阵X的秩,则每个样本xi的形状交互表示为Hi=。对Hi进行规则化处理,则形状交互权重表示为:

其中,第1 项是局部流形保持正则化项,其目的是在执行降维过程时,使投影样本在低维空间中保留原始样本在高维子空间中的局部流形结构。本文使用KNN 构造图权重矩阵W,其中元素表示为:
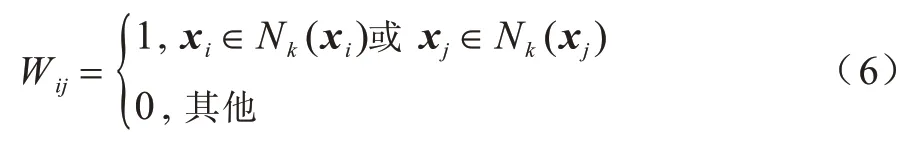
2.2 模型优化求解
由于式(4)所示模型中有多个变量,包括Z、E和P,因此不能直接求得最优解。本文提出一种迭代更新算法来优化该模型,主要思想是每次优化一个变量而保持其他变量不变,具体如下:
1)固定变量P,更新变量Z和E。
当固定变量P时,式(4)所示模型可等式于:

引入辅助变量J后,式(7)可以表示为:

式(8)所示的优化问题可以通过ALM 来解决,其对应的增强拉格朗日函数表示为:

其中,Y1和Y2是拉格朗日乘子。通过分别固定式(9)中的任何其他两个变量,使函数L最小化以交替更新变量Z、J和E,从而获得式(9)的最优解。每个变量的更新规则如下:

由式(15)可得P=[p1,p2,…,pd],其中向量pi对应于第i个最小特征值的特征向量。因此,可以通过迭代更新Z和P来获得式(4)所示目标函数的解。
为验证交替优化策略的收敛性,在Yale B[19]人脸数据库和COIL20[20]数据库上进行一组实验。图1显示了本文算法的目标函数值在这两个数据库上迭代次数的变化,可以看出,目标函数值随着迭代次数的增加而稳定下降。

图1 本文算法在两个图像数据库上的收敛曲线Fig.1 Convergence curves of the proposed algorithm on two image databases
3 实验与结果分析
为评估本文算法的有效性,将其与目前主流的特征提取算法PCA、NPE、SPP、SPCA[21]和LRPP[22]进行比较。这些对比算法在提取观测数据的特征后都使用最近邻分类器执行分类任务。为进行公平比较,每种算法在测试数据库上独立运行5 次。此外,对比算法的参数设置参考其文献出处或手动调整为最佳。
3.1 实验数据库
在Yale B 人脸数据库、CMU PIE 人脸数据库[23]和COIL20 图像数据库上验证本文算法的分类性能。3 个数据库的示例样本图像如图2 所示,其中每个对象的任意10 张或20 张图像都被用作训练样本,每个对象的其余图像被用作测试样本,具体设置如表1所示。

图2 3 个数据库的示例图像Fig.2 Sample images of three databases

表1 数据库设置Table 1 Setting of databases
3.2 参数选择
本文算法包含3 个相关参数,即γ、λ和β,本节在COIL20 数据库上进行实验,以验证这些参数对本文算法的影响。从图3 所示结果可以发现,参数γ和λ的变化对算法的性能影响很小,即本文算法对参数γ和λ非常鲁棒。此外还可以看出,参数β的最佳范围应为1.00~1.75,当参数β小于1.00 时,算法性能急剧下降。
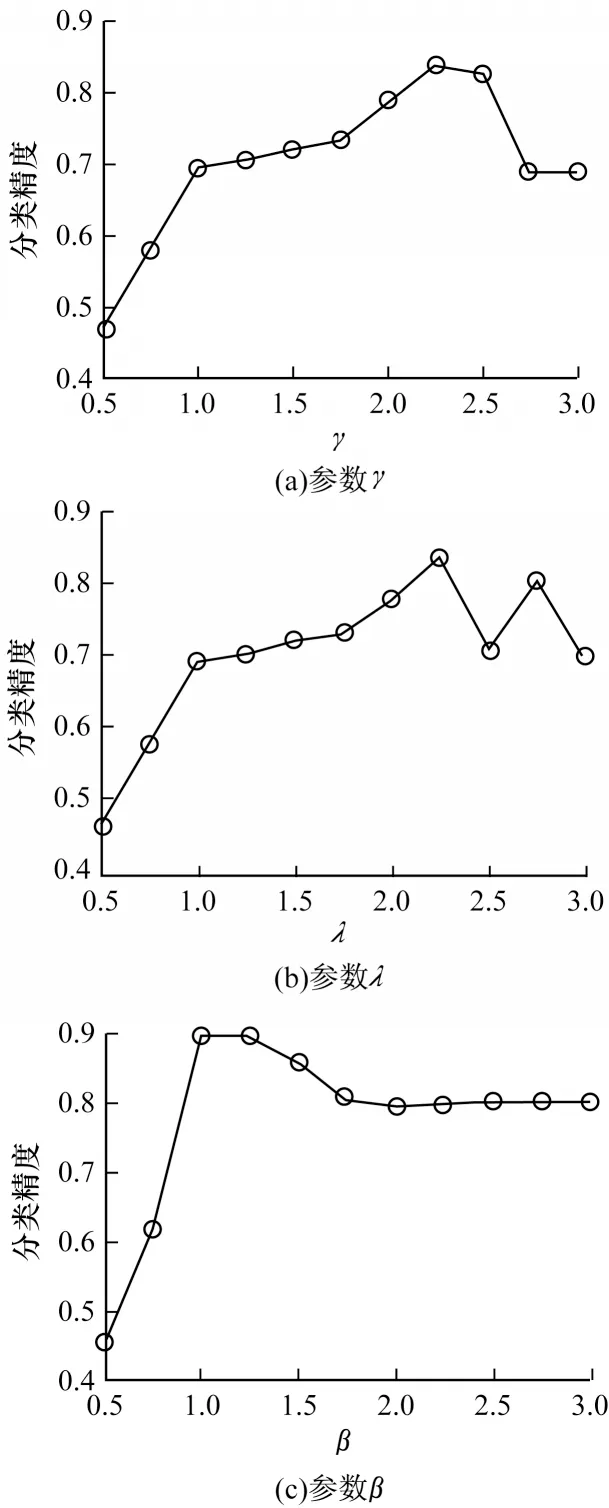
图3 本文算法分类精度与参数的关系(COIL20 数据库)Fig.3 The relationship between the classification accuracy of the proposed algorithm and parameters(COIL20 database)
3.3 实验对比分析
通过观察分类精度随不同图像数据库样本的特征维度d及训练样本数m的变化,验证本文算法的性能优势。6 种算法的平均分类精度如表2~表4所示,其中加粗数据表示最优数据,从中可以看出:
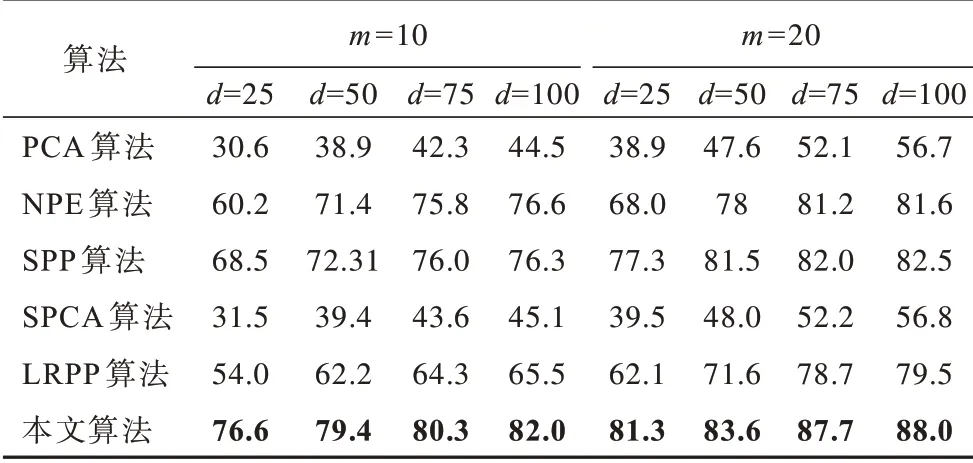
表2 不同特征维度下6种算法的分类精度(Yale B 数据库)Table 2 Classification accuracies of six algorithms under different feature dimension(sYale B database)%
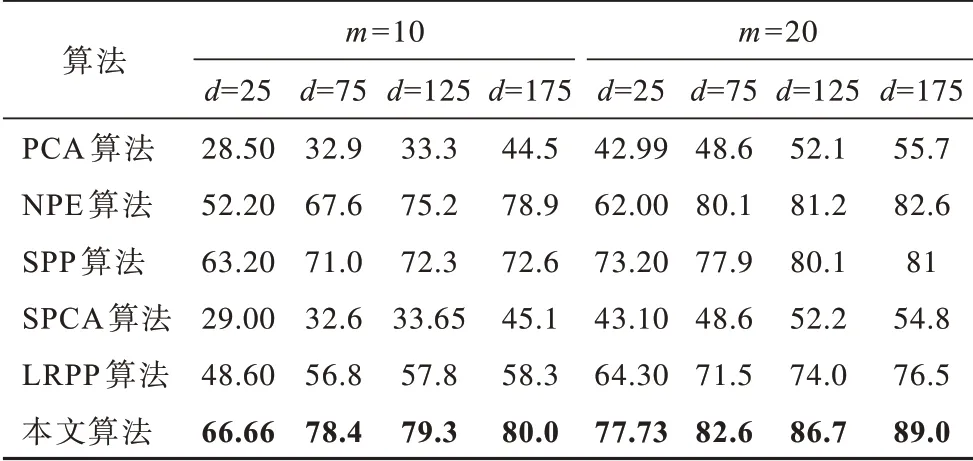
表3 不同特征维度下6 种算法的分类精度(CMU PIE 数据库)Table 3 Classification accuracies of six algorithms under different feature dimension(sCMU PIE database)%
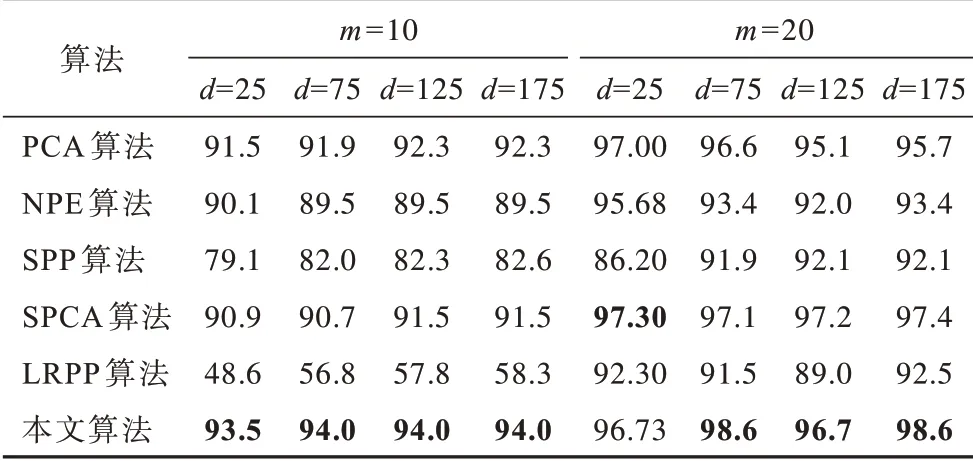
表4 不同特征维度下6 种算法的分类精度(COIL20 数据库)Table 4 Classification accuracies of six algorithms under different feature dimension(sCOIL20 database)%
1)本文算法能够在3 个公共图像数据库中实现最高分类精度。
2)无论样本特征维度如何变化,本文算法的分类精度均优于对比算法。
3)低秩表示可以很好地保留所观察样本的全局结构信息,加权稀疏表示也可以很好地保留局部邻域关系。
4)线性保留投影可以获得有效的低维投影空间,从而保留高维空间中的大部分数据信息。
由此可见,与对比算法相比,本文算法具有更强的鲁棒性和更好的分类性能。
4 结束语
本文提出一种联合表示学习和投影学习的降维算法。该算法同时获得观测样本的低维特征表示和稀疏表示,其通过交替优化策略,可以稀疏地进行低秩表示和投影学习,以实现合适的特征表示,得到更准确的相似性结构。基于公共面部数据库和对象图像库的实验结果表明,与其他的对比算法相比,该算法具有性能优势。但是在很多实际应用场景中,并不是所有的图像数据都是无标签的,这些图像数据往往带有少部分标签,因此,下一步将研究如何在降维算法中有效利用这些少量标签数据。
猜你喜欢
车主之友(2022年4期)2022-08-27
数学小灵通(1-2年级)(2021年4期)2021-06-09
数学物理学报(2021年1期)2021-03-29
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
海峡姐妹(2019年12期)2020-01-14
学生天地·小学低年级版(2019年5期)2019-06-05
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
学生天地(2019年15期)2019-05-05
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
