
基于用户模糊聚类的综合信任推荐算法
2021-06-18 07:31贾俊杰张玉超
计算机工程 2021年6期
贾俊杰,张玉超
(西北师范大学计算机科学与工程学院,兰州 730070)
0 概述
随着互联网技术的快速发展,全球信息数据量呈现爆炸式增长,使得互联网上的用户难以在海量信息数据中选择有用和重要的信息。推荐系统通过收集分析用户的历史偏好数据向用户提供更多的个性化信息,其中协同过滤推荐是一种应用比较广泛的个性化推荐算法[1],该算法的目标是寻找与目标用户具有相似兴趣爱好的其他用户,并通过这些用户的项目体验感受来对目标用户所未体验过的项目进行预测。针对协同过滤推荐算法存在的数据稀疏[2]和冷启动问题[3],研究人员提出了很多解决方案来提高推荐精度[4]。一方面,采用基于信息数据的聚类算法解决评分数据不足的问题,其中基于用户间信任的推荐系统旨在利用用户间的信任数据对用户缺失的评分数据进行补充,提高推荐性能[5-7]。另一方面,通过基于聚类的推荐算法缓解评分数据稀疏问题,其主要思想是将偏好差异较小的用户分为同一类别,偏好差异较大的用户分为不同类别,在推荐时选择与目标用户同属一个类别中的其他用户为推荐用户,可在不同程度上缓解数据稀疏问题,因此选择合适的聚类算法对推荐系统的推荐性能非常关键。本文主要研究用户间信任关系对推荐效果的影响,通过对信任数据、评分数据进行建模得到用户显式信任、隐式信任和全局信任,并将信任机制融入模糊C 均值(Fuzzy C-Means,FCM)聚类算法中以提升推荐质量。
1 相关工作
由于信任是用户产生决策的重要影响因素,因此基于用户信任关系的推荐系统得到广泛应用,目标用户将信任用户所推荐的内容作为决策影响因素之一[8]。融合社交网络的推荐系统通常将基于用户的协同过滤算法与信任模型相结合,不仅能够有效缓解传统协同过滤推荐算法中的数据稀疏和冷启动问题,而且能提高推荐结果的准确率和覆盖率[9]。融合用户之间的信任关系有利于提升推荐系统的性能,可有效防止恶意影响推荐精度的行为。
在基于社交网络的推荐算法中主要包括显式和隐式两种类型的信任关系,它们分别通过用户之间建立的社交网站收集得到[10]以及用户-项目评分数据推断得到。文献[11]利用用户间的信任数据取代传统协同过滤中的兴趣相似度进行推荐,其为典型的显式信任推荐模型,但由于未设置相应的信任传播阈值,因此使得大量不可信的信任路径得到保留。文献[12]将用户间的评分兴趣相似度作为隐式信任关系代替兴趣相似度进行协同过滤推荐,其为典型的隐式信任推荐模型,但忽略了随着时间的推移用户间信任关系的变化。近年来,研究人员在推荐系统中提出了一些显式信任与隐式信任混合模型。文献[7]提出利用二分图和隐式信任来预测用户偏好,通过用户间的信任关系取代用户兴趣相似度进行协同过滤推荐。文献[13]提出基于信任的矩阵分解算法TrustSVD,该算法不仅考虑了用户间信任数据和评分数据的显性影响,同时考虑了用户间的隐性影响。文献[5]提出一种融合Pareto 和置信度的信任推荐系统,当用户间显式数据过于稀疏时,利用用户间的项目评分数据进行补充,从而提高推荐系统的准确性。文献[14]所提出的算法考虑了信任的动态变化,将融合时间衰减函数的皮尔森评分相似度作为用户间隐式信任值,主要对信任传递进行了研究,但未充分挖掘评分数据中隐含的用户间信任关系。
协同过滤推荐算法适合运行在小型数据集中,并且运行效果较好,但现实生活中用户-项目数据量太大,很难利用其对用户进行准确推荐。为了解决这一问题,可在推荐系统中使用聚类算法将用户-项目分成若干聚类,从而缩小推荐系统搜索相似用户的范围。若用户被划分到同一类别,则表示其兴趣相似度较大,否则表示兴趣相似度较小。在众多聚类算法中,K-Means 是较为经典的聚类算法,每次对用户进行聚类时,都只能分配到一个类别中。但实际上,在聚类完成时,每个类别中都有和目标用户相似的用户[15],从而使得推荐结果精度降低。为了解决此类聚类问题,将模糊C-Means 聚类算法应用到推荐系统中[15],根据用户所属类别的隶属程度来确定用户属于一个或多个类别,从而获得更大的搜索空间寻找兴趣最为相似的用户。文献[16]为进一步提高文献[15]所提算法的推荐质量,利用模糊C 均值聚类算法将用户分成若干类别,采用传统欧式距离加权化来获得最佳聚类进行推荐。文献[17]利用用户评分过程中的潜在信任关系,提出一种基于信任机制的概率矩阵分解协同过滤推荐算法,通过构建用户-信任评分矩阵提高推荐准确性。文献[18]应用粒子群优化算法优化模糊C 均值聚类算法对用户进行聚类,有效提高了推荐准确率。文献[19]通过K-Means 聚类算法对用户进行聚类,然后利用Slope One 算法对评分矩阵进行填充,有效缓解了数据稀疏问题。上述推荐算法都是利用用户评分数据进行处理,而真实用户评分数据集通常极度稀疏,导致推荐质量依然较低。
通过以上研究可知,推荐系统中引入信任机制可有效提升推荐效率,但上述推荐算法均未充分挖掘用户间信任传递的关联性,且未综合考虑用户全局信任对每个用户信任关系的影响。由于用户的信任关系仅针对一小部分用户数据,因此无须浪费大量时间扫描全部用户数据。本文提出基于模糊C 均值聚类的综合信任推荐算法,旨在缓解数据稀疏与冷启动问题的前提下缩减搜索目标用户的最近邻,并提高推荐质量。首先通过对用户评分数据进行聚类,根据用户隶属情况得到用户所属类别,基于信任数据、评分数据计算所属类别中用户的显式信任值、隐式信任值并得到综合直接信任值;然后通过信任的可传递特性,获取用户间Jaccard 全局信任值;最后动态结合用户间综合直接信任与Jaccard 全局信任得到综合信任值,将综合信任值取代传统推荐算法中的兴趣相似度实现协同过滤推荐。
2 相关技术
本文主要通过用户-评分矩阵获得用户的聚类类别,根据聚类类别计算用户间的全局信任度,以此对用户进行协同过滤推荐,其中主要包括用户-项目构建、模糊C 均值聚类、近邻形成和评分预测4 个部分。
2.1 用户-项目评分矩阵构建
在推荐系统中,用户-项目评分数据是由n个用户和m个项目(音乐、书籍、商品等)所组成的n×m维的矩阵,其中,用户集合U=(u1,u2,…,un),项目集合I=(i1,i2,…,im),un表示用户集合中第n个用户,im表示项目集合中第m个项目。用户对项目的评分为R=(ru1,i1,ru2,i2,…,run,im),其中rij∊[1,5]中的离散值,表示用户ui对项目Ij的评分。本文中用户评分缺失采用评分0 来代替。如果用户对项目的评分为1,则表示用户对该项目非常不感兴趣,如果用户对项目的评分为5,则表示用户对该项目非常感兴趣。评分项目矩阵如表1 所示。
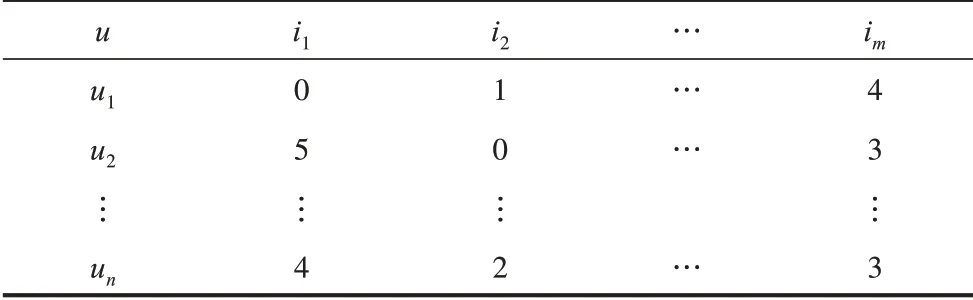
表1 用户-项目评分矩阵Table 1 User-project rating matrix
2.2 模糊C 均值聚类
基于用户属性向量对用户进行聚类,即用户-项目评分数据映射到n维向量上u=(r1,r2,…,rn),对用户属性向量进行模糊C 均值聚类。模糊C 均值聚类算法[20]原理为根据隶属度来表示样本点属于某个聚类的隶属程度。将样本集X={x1,x2,…,xn}中的每一个样本点模糊划分到K个聚类中,更新每个聚类中心ci(i=1,2,…,k),并使得划分代价损失函数达到最小值。划分代价损失函数的计算公式为:

为使式(1)取得最小值,对聚类中心ci与隶属度ui(xj)求偏导,得到损失函数取得最小值的必要条件如式(3)、式(4)所示。将必要条件通过迭代求解,得到聚类中心与样本点的隶属度矩阵。

算法1模糊C 均值聚类推荐算法
输入 用户-项目评分矩阵,聚类个数K,最近邻个数N,目标用户u
输出 缺失项目预测评分
步骤1输入用户评分矩阵,根据用户评分数据对用户进行模糊C 均值聚类。
步骤2计算每个用户对每个类别的隶属度,根据用户隶属度对用户进行聚类。
步骤3找到目标用户所在聚类,同一类中用户偏好相似度较高,不同类别中用户相似度较低,计算目标用户与类别中其他用户的偏好相似度。找到与目标用户相似度最高的K个用户为目标用户的最近邻。
步骤4对所得目标用户与最近邻进行缺失项目的评分预测或top-N 推荐。
2.3 近邻形成
协同过滤推荐算法的基本原理是通过分析挖掘目标的历史评分数据,找到与其兴趣偏好相似的用户,并为目标用户推荐未体验过的商品和项目。换言之,通过目标用户的历史评分数据找到相似用户,利用相似用户为目标用户进行推荐。度量用户间相似性是推荐过程中的重要流程,与推荐精确度密切相关,其主要度量指标为皮尔森相关系数、余弦相似度和Jaccard 相似度等,其中皮尔森相关系数是一种较常用的相似性度量系数[21],计算公式为:

其中,Iu,v表示用户u和用户v共同评分的项目,ru,i和rv,i分别表示用户u和用户v对项目i的评分。
2.4 评分预测
通过度量用户间的兴趣相似度可得到K个与用户兴趣最为相似的近邻进行评分预测,评分预测公式为:

其中,ru,i表示目标用户对缺失项目i的预测评分,表示目标用户对所有评分项目的平均评分值,NNK(u,i)表示具有预测项目i的目标用户的最近邻集合,sim(u,v)表示用户间的皮尔森相似度。
3 改进的模糊C 均值聚类推荐算法
模糊C 均值聚类推荐算法[15]运用聚类方法将兴趣相似用户划分到相同类别中,并选择与目标用户同属一个类别的其他用户作为推荐用户,以此来解决推荐系统中的数据稀疏与冷启动问题,但在推荐系统中遇到绝对数据稀疏与冷启动用户时推荐效率依旧较低。因此,本文将用户间信任机制融入该算法,进一步提高推荐效率。将协同过滤推荐算法中用户之间的联系拓展为用户间综合信任,其中:综合信任关系包含用户间显式信任、隐式信任、综合直接信任与Jaccard 全局信任,显式信任关系由用户间信任数据计算所得,隐式信任关系由用户间评分数据所得,综合信任关系是由显式信任关系与隐式信任关系融合计算所得;Jaccard 全局信任是指用户在整个推荐系统中的活跃强度,若用户在推荐系统中越活跃,则获得的Jaccard 全局信任度就越高。本文算法主要包含3 个阶段:1)通过模糊C 均值聚类算法对用户进行聚类;2)利用用户信任数据和项目评分数据得到用户间显式信任值、隐式信任值及综合直接信任值;3)由用户间综合直接信任值得到Jaccard 全局信任值,并加权结合Jaccard 全局信任关系组成综合信任值进行协同过滤推荐。本文算法流程如图1所示。

图1 本文算法流程Fig.1 Procedure of the proposed algorithm
3.1 用户间显式信任
信任在宏观上是指相信对方是诚实可信赖的,在推荐系统上的信任是指用户对对方所体验过的项目感兴趣。若用户之间存在显式直接信任关系,则T(ui,uj)=1,表示用户ui信任用户uj,否则T(ui,uj)=0,表示用户i没有直接信任关系。用户-用户信任矩阵如表2 所示。

表2 用户-用户信任矩阵Table 2 User-user trust matrix
用户间信任数据矩阵可使用有向图G=(V,E)来表示,其中,V为信任网络中的每个用户节点,E为信任网络中用户节点之间的有向边,表示用户之间存在信任关系。
用户信任网络如图2 所示,用户u1与用户u3之间有两条有向边,表示用户之间相互信任。用户u1与用户u4之间有一条有向边,表示用户u1信任用户u4,但用户u4不信任u1。用户信任网络上的边[22]可形象表示为。利用MASSA 等人[11]提出的信任计算方法计算用户间的显式信任值:
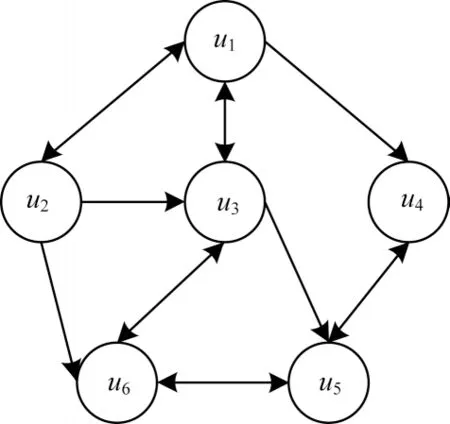
图2 用户信任网络Fig.2 User trust network

其中,dui,uj表示用户ui与用户uj的最短信任传播距离。例如,用户u1与用户u5没有直接信任关系,但他们可以通过信任传递的方式获取对彼此的信任,此时u1与u5的信任传播距离为dmin(u1u2u6u5,u1u2u3u6u5,u1u2u3u5,u1u3u6u5,u1u3u5,u1u4u5)=3,dmax表示用户间最大传播距离[23],计算公式为:

其中,n表示用户信任网络中用户节点的总数,k表示用户节点出入度的平均值。
3.2 用户间隐式信任
本文算法利用用户-项目评分数据、时间衰减函数综合推断出用户间的隐式信任关系。本文采用LATHIA 等人[24]提出的信任计算模型来计算用户间的隐式信任值,若用户间有相同评分项目,则表示用户互动一次,评分差异越小,用户间越信任,而互动次数越多表示用户信任程度越高,计算公式为:
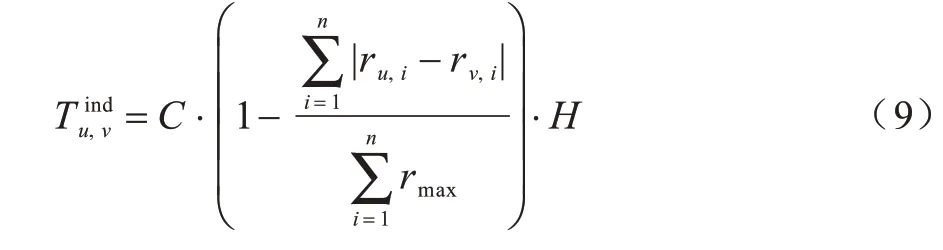
其中,ru,i和rv,i表示用户u与用户v对项目i的评分,表示用户间的可信度,|Iu|和|Iv|表示用户u和用户v对项目评分不为0 的数量,分子部分表示用户间共同拥有评分不为0 的项目。用户可信度越大,用户的隐式信任程度越高。如图3、图4 所示,用户u与用户v共同拥有评分不为0 的项目5 项,但用户u与用户v之间的隐式信任程度不同,且随着时间的推移,用户间的隐式信任的衰减速度会由快到慢,最后无限趋于0。时间衰减函数[14,25]H的计算公式为:


图3 互动程度相同的示例Fig.3 Example with the same degrees of interaction

图4 互动程度不同的示例Fig.4 Example with the different degrees of interaction
其中,k为影响时间的衰减因子,T为当前时刻,t为用户间的最后交互时刻,即用户最后一次共同拥有不为0 评分项目的时刻。
3.3 用户间综合直接信任值计算
将用户间显式信任与隐式信任进行结合,得到用户间综合直接信任值,计算公式[26]为:
1.3.2 B组31例患儿给予多次胰岛素皮下注射,患儿三餐前皮下注射短效胰岛素,根据患儿血糖检测情况适当调整胰岛素注射用量,患儿睡前给予中效诺和灵注射。

综合信任值由用户间综合直接信任值与Jaccard全局信任值组成,计算公式[27]为:

其中,α+β=1。
在聚类完成后,相同聚类中用户间最为信任。通过结合用户间综合直接信任关系、全局信任关系得到用户综合信任值,并找到目标用户所属聚类中最为信任的K个用户进行下一步处理。用户间Jaccard 全局信任值计算如式(13)所示:

式(13)表示用户u与用户v所拥有的共同信任用户越多(综合直接信任值大于0.5),则用户u和v间的全局信任值越高。
3.4 用户-项目评分预测
通过在用户所属类别中找到与目标用户综合信任值最高的K个推荐用户,利用用户间综合信任值取代传统用户间评分兴趣相似度进行推荐。应用式(14)对目标用户缺失项目评分进行预测[28]:
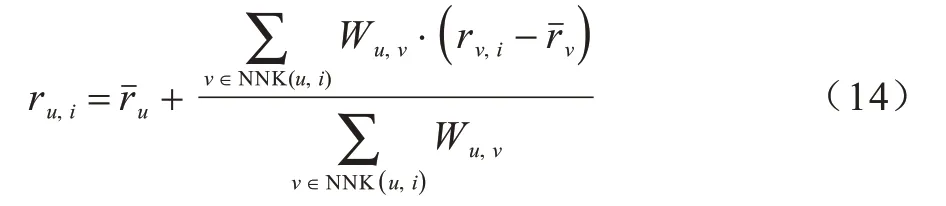
算法2基于模糊C 均值聚类的综合信任推荐算法
输入用户-用户信任矩阵,用户-项目评分矩阵,目标用户
步骤1根据用户属性向量,计算每个用户对每个类别的隶属度,根据用户隶属度进行聚类。
步骤2计算用户间显式信任值:

步骤3找到目标用户所在聚类,计算目标用户与类中其他用户的隐式信任值。利用用户间显式信任值、隐式信任值得到综合直接信任值,并采用综合直接信值计算出用户间Jaccard 全局信任值:

根据式(11)、式(13)计算用户间综合直接信任与全局信任值

步骤4将用户间综合直接信任值与Jaccard 全局信任值加权结合得到综合信任。利用式(12)计算用户间的综合信任值Wu,v
步骤5将目标用户与其他用户的综合信任值降序排序,选取前K个用户为目标用户的最近邻集合Un,利用用户间综合信任值取代传统协同过滤中的相似度进行缺失项目的评分预测及top-N 推荐。

利用式(14)对目标用户未评分项目进行预测评分及top-N 推荐
4 实验结果与分析
本节使用真实数据集并利用Python 语言实现本文算法,并在配置为Windows 7、2.50 GHz CPU 和8 GB 内存的计算机上进行实验。
4.1 数据集
实验使用FilmTrust 数据集(http://www.trust.mindswap.org/FilmTrust/),该数据集抓取自FilmTrust网站,包括1 508 名用户为2 071 部电影项目的评分情况,由评分数据ratings.txt和用户信任数据trust.txt两部分组成,其中:ratings.txt包含35 497条数据,评分范围为0.5~4.0,步长为0.5,密集度为1.044%;trust.txt 包含1 853 条数据,密集度为0.069%。
4.2 评价指标
为检验本文算法的有效性,采用平均绝对误差(MAE)、覆盖率(COV)和综合评价指标(F1)来评价推荐系统性能。平均绝对误差是指推荐系统为用户所推荐的商品评分与测试集中真实用户商品评分之差的平均值,其值越小表示预测评分越准确,计算公式如式(15)所示。覆盖率是指推荐系统能为用户预测评分商品数量占测试集总商品数量的比值,其值越高,表示算法挖掘长尾商品的能力越强,计算公式如式(16)所示。F1值是指推荐系统综合评价指标[28],其值越高表示性能越好,计算公式如式(17)所示。
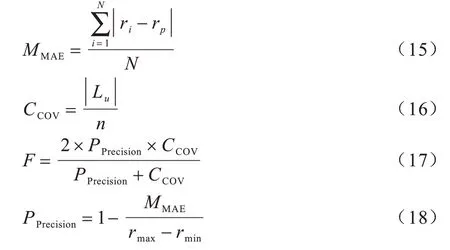
其中,ri为测试集中项目i的真实评分,rp为推荐系统为目标用户的商品预测评分,|Lu|表示推荐系统为目标用户预测评分商品的数量,n表示测试集中的总商品数量,rmax和rmin分别表示推荐系统中的最高评分与最低评分。
4.3 结果分析
实验选取FilmTrust数据集的80%作为训练集,20%作为测试集,使用推荐系统为用户所推荐的商品评分与已知的测试集中的商品评分做对比,利用所给出的评价指标来度量推荐算法性能。将本文算法与传统基于用户的推荐算法BUCF、基于模糊C 均值聚类的协同过滤算法FCMCF和基于隐式信任的推荐算法BTCF进行对比,在设置相同参数的情况下,通过评分和top⁃N预测来评估推荐算法的性能。
本文算法涉及参数α与β,其中,α为用户间综合信任值在综合直接信任值中所占比重,β为用户间全局信任值在综合信任值中所占比重。如图5 所示,不同α值对预测评分的平均绝对误差的影响较大,在α=0.1 和β=0.9 时,平均绝对误差值最小,覆盖率与F1 值最大,分别为0.45、0.593 和0.715,说明当数据稀疏和冷启动用户较多时,本文算法更依赖于通过用户之间的信任传递来获得最佳信任近邻以实现评分预测。

图5 α 值对推荐质量的影响Fig.5 The effect of α values on recommendation quality
图6 给出了本文算法在不同近邻个数时的推荐质量比较结果。可以看出,随着近邻个数的增加,推荐质量不断降低,最终趋于平缓,其中MAE 随着近邻个数的增加而增加,原因是随着近邻个数的增加用户间综合信任值不断减小,导致推荐质量不断降低,最终趋于平缓,而COV 和F1 值随着近邻个数的增加而降低,从而证明本文算法在近邻个数为5 时推荐质量较优。

图6 近邻个数对推荐质量的影响Fig.6 Influence of the number of neighbors on recommendation quality
图7 给出了本文算法与对比算法在不同近邻个数下的MAE 变化情况。可以看出,在不同近邻个数时,FCMCF 和BUCF 算法的MAE 均是先下降后上升,最终趋于平稳,且MAE 值都在1.0 以上,而本文算法与BTCF算法均是随着近邻个数的增加MAE值不断增加,最终趋于稳定,且MAE 明显要比FCMCF 和BUCF 算法小很多。
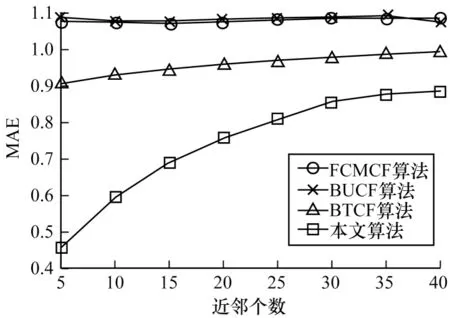
图7 4 种推荐算法的MAE 比较Fig.7 MAE comparison of four recommendation algorithms
图8、图9 给出了本文算法与对比算法在不同近邻个数时的COV 和F1 值变化情况。可以看出,4 种推荐算法随着近邻个数的增加,为目标用户推荐的长尾商品和个性化商品减少导致COV 不断减少。当近邻个数为35~40 时,本文算法与对比算法在COV 上没有很大差别,但当近邻个数为5~20 时,本文算法相比对比算法对于长尾商品的挖掘效果更好,并且具有更优的推荐效果。
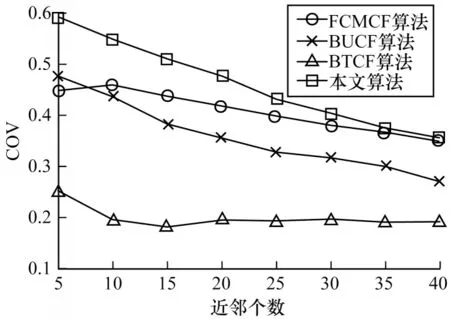
图8 4 种推荐算法的COV 比较Fig.8 COV comparison of four recommendation algorithms

图9 4 种推荐算法的F1 值比较Fig.9 F1 values comparison of four recommendation algorithms
综合以上实验结果表明,本文算法相比传统基于用户的推荐算法、基于模糊C 均值聚类的协同过滤算法和基于隐式信任的推荐算法在平均绝对误差、对长尾商品的挖掘能力以及综合评价指标上具有更好的性能表现,特别是在近邻个数较少的情况下,本文算法在数据稀疏、冷启动问题下仍能为目标用户进行精准推荐。
5 结束语
本文提出一种基于用户模糊聚类的综合信任推荐算法,使用用户信任数据构建信任网络计算用户间显式信任值,利用评分数据计算用户间动态隐式信任值,并将用户间显式信任与隐式信任相融合得到综合直接信任值,通过动态结合用户综合直接信任值与Jaccard 全局信任值得到用户综合信任值,同时利用综合信任值取代传统基于用户的协同过滤中的相似度对目标用户实现精准推荐。实验结果表明,本文算法相比传统推荐算法在平均绝对误差、覆盖率以及F1 值指标上具有更好的性能表现。后续将研究用户间的信任传播对推荐系统的性能影响,进一步提升推荐质量与用户体验。
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
桃之夭夭B(2017年2期)2017-02-24
电子设计工程(2015年6期)2015-02-27
高中生·青春励志(2014年11期)2014-11-25
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年2期)2008-04-01
中学英语之友·上(2008年1期)2008-03-20
