
智能医疗领域问答系统研究与实现
2021-06-18 03:41奕利泰通讯作者牛梓雨刘思嘉倪晓雅罗绍恺
信息记录材料 2021年5期
奕利泰,董 晨(通讯作者),牛梓雨,刘思嘉,倪晓雅,罗绍恺
(天津理工大学 计算机科学与工程学院 天津 300384)
1 引言
医疗大数据时代的到来,深度学习、自然语言处理等技术在医学领域发展迅速,基于人工智能的医疗问答系统正在改变医疗生态,具有重要的应用前景。如何快速、准确、简洁地用自然语言回答用户的提问,成为医疗问答系统中待解决的关键问题。传统的数据库查询反馈的结果难以满足速度和准确度的要求,基于自然语言处理的知识库问答相对于传统的搜索引擎,能快速反馈给用户精准的回答。本项目将分布在互联网中的非结构化的医疗相关数据整合起来,建立严格结构化的医疗知识图谱,保存在阿里云服务器端,使用基于双向Transformer的联合学习模型执行知识抽取,使用基于深度学习的Stack-propagation框架识别医疗输入问句,重新转化为知识图谱的查询索引,快速反馈给用户最精准的医疗答案。
2 系统架构及功能实现
系统采用阿里云服务器+客户端架构,以Android APP形式实现与用户交互。云服务器主要功能有:数据采集、知识图谱构建、联合学习模型构建、问句理解模型构建、医疗信息检索、用户安全管理以及系统性能评价。Android客户端主要功能有:智能医疗问答、好友社交推荐、饮食计划、运动健康推荐、医疗资讯推送及机构检索、医疗词条查询等。
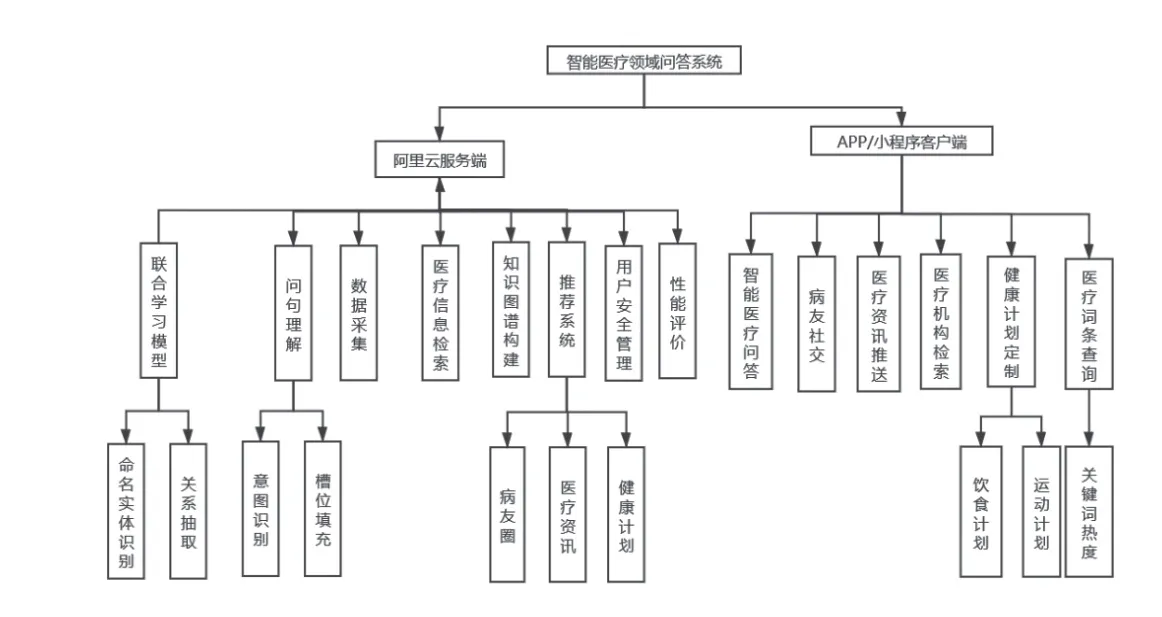
图1 系统功能模块
3 系统关键技术实现
3.1 构建知识图谱
本项目使用Scrapy框架和Webdriver爬取垂直医疗网站中的信息,使用Neo4j图数据库构建医疗知识图谱[1]供服务器检索,主要包括疾病、症状、药物、治疗方式、医疗器械等节点。结构化数据使用配合爬虫的脚本直接置入Neo4j图数据库中[2],非结构化以及半结构化数据需要经过知识抽取后,再置入Neo4j图数据库中。数据库规模涵盖33645个医疗信息实体节点以及290881个实体关系,足以提供问答系统的数据需求,通过构建知识图谱可进一步分担算法压力。
3.2 构建基于双向Transformer的实体识别和关系抽取的联合学习模型
由于医疗问题的特殊性,构建知识图谱要求精确度高。一般情况下,除少部分专门处理过的数据(例如百科)之外,对于同一疾病的症状的描述在语料库中过于多样化,需要设计模型筛取关键词,构建最精确最简洁的知识图谱。本项目使用基于双向Transformer的联合学习模型执行知识抽取。
深度学习模型将使用Python语言的Tensorflow2.0框架训练,再部署到阿里云服务器中运行。同时,引入stack-propagation框架的思想,令关系抽取的模型直接使用实体识别的输入,使两种任务不同的训练集和验证集同时调整一个模型,让神经网络最大化地贴合医疗应用。通过这种训练方式可让两个应用各自的网络层得到对方学习到的特征。相比流水线的任务,基于双向Transformer的实体识别和关系抽取的联合学习模型,构建的模型冗余参数更少,运行速度更快。
3.3 基于stack-propagation框架的意图识别+槽位填充模型
输入问句中的实体以及问句意图有较强的相关性,为了准确理解医疗输入问句,采用基于Stack-propagation的意图识别及槽填充算法[3]实现医疗输入问句解析。首先进行意图识别,由于问句的长短不统一,使用Bi-LSTM可以处理长度不统一的数据向量,Bi-LSTM即是双向循环的LSTM层。LSTM是在循环神经网络中增加了一条供先前节点学习到的特征流通的通路,由一个遗忘门和一个记忆门决定该特征的去留[4]。通过该方法循环神经网络,可以弥补不能保留上下文信息的缺点,输入经过Bi-LSTM层后计算自注意力C。
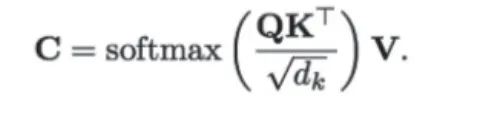
得到C后与Bi-LSTM]串联输出合并成一个向量,将意图分类转化为单词分类。
槽填充任务依赖于意图识别的结果[5],将分类后的单词填入槽位。仍采用单向LSTM作为解码器,对于第i时刻的隐层状态表示如下:
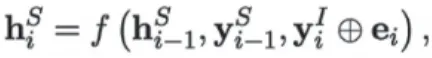
直接将第i个时刻的意图分类结果作为输入指导槽位的预测,提升问答的准确度。智能问答展示页面如图2所示:

图2 智能问答展示页面
3.4 推荐系统设计
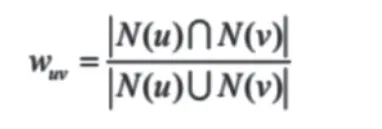
将用户x检索过的医疗健康等关键词集定义为N(x),则N(u)∩N(v)表示检索过的关键词,投票为1,未检索过的关键词投票为0。N(u)∪N(v)则表示检索过的关键词的并集的元素个数。Jaccard系数的实现是将医疗关键词向量堆叠成矩阵,将其中一方的矩阵转置。因为向量长度统一可以点积,点积后返回相似的关键词个数。系统定期抽取各个用户的检索历史存储在云服务器,利用Jaccard系数计算医疗、饮食和运动关键词之间的相似度,进行健康饮食、运动方案推荐。饮食推荐展示页面如图3所示:

图3 饮食推荐展示页面
4 系统实现
智能医疗问答系统架构分为五个层级,分别是中台、后台、数据分析、索引引擎以及数据库。中台主要拦截并捕获客户端请求。后台主要实现数据交互。数据分析层主要解析医疗输入问句。搜索层为Neo4j数据库服务器提供知识图谱的搜索索引。数据库层采用关系型数据库Mysql及图数据库Neo4j实现。采集3000条问答作为测试集,对比使用关键词匹配的医疗问答,智能医疗问答系统的问答准确率可达90%。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
少先队活动(2020年12期)2021-01-14
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
专利代理(2016年1期)2016-05-17
延河(下半月)(2014年3期)2014-02-28
杂草学报(2012年1期)2012-11-06
质量与标准化(2010年5期)2010-05-03
