
PMI与Hownet结合的中文微博情感分析
2021-06-17 12:08陈临强
电子科技 2021年7期
郝 苗,陈临强
(杭州电子科技大学 计算机学院,浙江 杭州 310018)
近年来,随互联网技术、移动终端技术的迅速发展,我国微博用户数量激增,尤其以新浪微博为主,产生的微博文本数量也迅速增长。Web2.0的提出与兴起使互联网赋予网民更多主动,社交媒体成为用户获取、分享、发表信息的平台。据第43次“中国互联网发展统计报告”,到2018年12月为止,中国网民数量高达8.29亿,渗透率约59.6%,移动互联网用户数达到8.17亿,网民接入互联网比例高达98.6%,移动互联网已渗透到生活的各个方面[1]。2019年3月中旬,相关部门发布“2018年微博用户发展报告”,报告显示,截至2018年4月底,微博中每月活跃人口总数为4.62亿,每日活跃用户则达到2亿,相比较去年同期增长了25%[2]。数量庞大的微博文本,已经能够作为情感分析的重要数据来源。“情感分析”也称意见挖掘,通过处理文本获得情感倾向,从而获得人群网络文本的情感倾向,为舆情监控、预测、引导提供了重要指导意见,也有助于改进产品服务及预测信息走势。情感分析研究所面临的困难源于两个方面:(1)文本情感分析技术涉及领域广,例如数据挖掘、自然语言处理、机器学习等,这些技术理论知识复杂,难以掌握;(2)现有文本情感分析技术准确度不高。因此,有必要提出一个准确、有效的方法来提高文本情感分析准确性。
本文的主要贡献有:利用 Hownet 相似度整合现有词典;利用 PMI(Pointwise Mutual Information) 算法对现有词典扩充,构建符合新浪微博短文本表达特点的微博专用情感词典;收集新浪微博“热点”部分微博,对微博进行清洗、过滤、分词等预处理;结合微博专用情感词典训练Bayes分类器得到情感分析模型。
1 相关工作
情感分析是对公众在社交媒体中发表的评论性文本进行主观意见挖掘,情感分析的结果能够判断研究对象的情感倾向。最早的情绪分析研究始于国外,基于情感词典的分析方法,其结果准确性取决于词典涵盖某领域的完整程度,以及词典标注的准确程度。微博文本中的新词是无穷无尽的,新的在线词汇迅速出现对情绪分析的准确性产生了重要影响。同时中文表达的含义丰富多样,仅依靠情感词典难以得到准确的情感分析结果。基于监督学习的方法能够避免人工带来的误差,其准确性依赖于文本特征的提取,但是需要大量标注训练集才能得到准确的训练结果[3-5]。文本情感分析的关键是找到情感词提取关键字并建立情感分析模型,最后对文本进行情感倾向的分析。
文本情感分析从3个层次出发,分别是词语级、句子级、篇章级。对于词语级别的情感分析,文献[6]提出形容词在句子情感分析中占主导,在句子级的极性倾向计算中有较好的体现。例如句子是由词语组成的,通过提取其中的关键词,进行语义情感分析,从而得到词语的极性倾向值,这个倾向值就是整个句子的语义极性倾向。但实际上对于句子级情感分析,仅通过对单个词语分析来确定句子整体倾向并不是最好的方式。文献[7]提出通过词组进行分析,因为相对于单一词语,用词组表现情感更准确、直观。他们也通过相关的实验,如抽取语料库中的词组,系统根据这些词组进行分析,得出对应的语义倾向,最后计算这些倾向值的平均值,用均值代表整句情感。除此之外,文献[8]提出另外一种基于情感词典的无监督方法。该方法最初应用于句子的情感分析[9],通过计算情感词典中情感强度和情感词汇的关联度获得情感分值,以及文本情感分析。
文献[10]在文本情感分析方面做了大量实验。实验以表情符号为基础,首先采集大量的表情符号构建情感词典,然后将词典应用于社交网络平台,最后经试验得到较准确的分析结果。利用传统的特征提取方法,或者词向量与机器学习算法相的组合,是情感分析领域的热点问题之一。文献[11]针对网上在线招聘广告,建立薪水预测模型帮助求职者选择合适职位,利用文本深度表示模型Doc2vec计算文本的特征向量,更深入地表示文本语义特征。此外,其结合随机森林、支持向量机(Support Vector Machine, SVM),例如使用SVM建立薪资预测模型,将 Doc2vec模型与词频逆向文件频率模型(Term Frequency-Inverse Document Frequency,TF-IDF)、Word2vec 进行比较,发现Doc2vec 可以在薪资预测中取得更令人满意的预测效果。文献[12]使用 Word2vec 模型,并在此基础上将其与TF-IDF 权重计算方法相结合,将微博转换为文本向量的形式,用 K-means 聚类算法对微博数据聚类处理,得到文本的相关主题。文献[13]提出了词向量(Word Embedding 或者 Distributed Representation)的思想。“词向量”是一个向量,是低维稠密的特征表达形式,用于解决维数灾难问题。由于向量本身具有信息量,使用词向量时,可使用向量余弦距离表示词语之间的语义距离[14]。
2 整体框架
本文所提出解决微博文本情感分析问题的整体框架,由两部分组成:第一构建微博专用情感词典;第二结合贝叶斯分类算法训练分类器对微博文本进行情感分析。整体框架如图1所示。
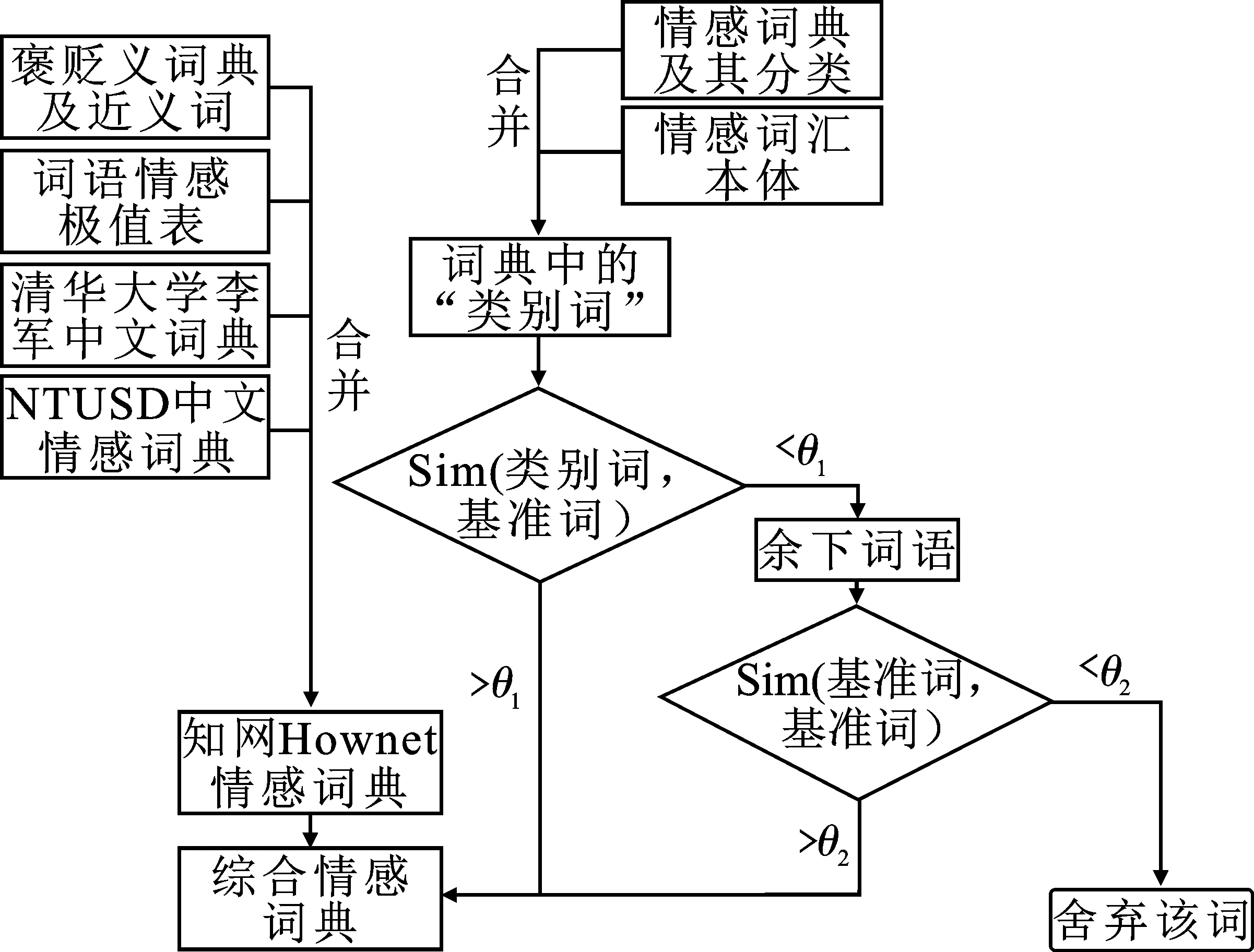
图1 微博情感分析整体框架
2.1 构建专用词典
情感分析研究中常用的词典有:近义词及其褒贬词词典、清华大学褒贬义词典、NTUSD台湾大学中文情感词典、知网Hownet情感词典[15]、情感词典及其分类、汉语极性词极值表、情感词汇本体,各词典特征如表1所示。本文将5个标注极性分类的词典直接合并,没有极性标注的词典利用下述规则合并,并添加网络新词构建完整词典。

表1 情感词典
2.2 算法原理
(1)利用知网(Hownet)相似度合并词典。对于多类别情感词典,使用Hownet相似度进行合并,文献 [16]是对中英文单词所代表的概念的描述。Hownet提供很多有关文本处理的功能,例如词性标注、文本相似度计算等,其中语义相似度计算和语义相关场的计算在本研究中尤为重要,且使用语义相似度计算文本情绪值准确度更高。“语义相似度”反映语义的近似程度,可以理解为两个词语在不同语句中能够相互替换且不改变句子原本意义的程度。词语的情感倾向由它与基准词的语义相似度决定,与积极词典中的基准词相似度大表示倾向积极,反之倾向于消极。
待分析词语计算得到的情感值用so_Hownet(Word)表示,调用Hownet相似度接口计算词语相似度,情感倾向计算式为式(1)。
(1)
用Hownet相似度计算情感值,首先选取褒义词、贬义词两组基准词,调用Hownet API计算相似度,根据相似度对词语进行情感极性判断。其中,sim(Word,posi)和sim(Word,negi)代表Word与褒义词、贬义词的相似度。so_Hownet(Word)的值为“正”表示词语褒义。为“负”表示贬义,设置相似度阈值为θ1,以词语相似度为标准将词语划分进词典;
(2)利用PMI添加网络新词。将PMI用在情感极性计算上,扩充情感词典,PMI是一种基于统计的计算方法。该算法计算语料库中目标词与基准词之间的关联程度,并计算目标词的情感值[17-18]。情绪基准词集合为Pi={P1,P2,P3,…,Pn}(i= 1,2,3,…),n表示基准词个数。目标词集合为C,其中每个目标词cj(j=1,2,3,…)与基准词的PMI值计算式为
(2)
计算词语概率
(3)
(4)
(5)
其中,count(pi,cj)、count(pi)、count(cj)分别表示cj与pi共同出现的次数、pi出现的次数,cj出现的次数、q表示语料库文本总条数。将式(3)~式(5)带入式(2)得式(6)。
(6)
为防止目标词与基准词在同一文本中次数为0没有意义,引入拉普拉斯平滑因子
(7)
引入平滑因子后PMI计算式如下。
(8)
SO_PMI(pi,Bi)=PMI(pi,Bpi)-PMI(pi,Bni)
(9)
计算目标词与两极性基准词Bpi及Bni的PMI,求得的差值结果为正,表示待计算网络词为积极词语,为负表示该网络词为消极词语,差值的绝对值大小表示倾向强度。设倾向性阈值θ2,将阈值划分的词语分别加入pos词典(褒义词典)、neg词典(贬义词典)。专用词典构建流程如图2所示。
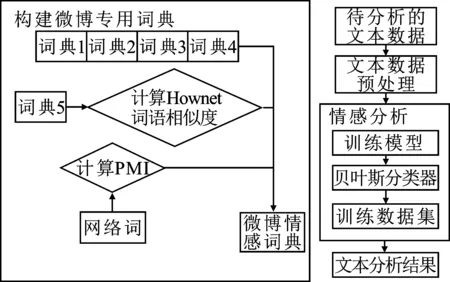
图2 情感词典构建流程
2.3 训练贝叶斯分类器
朴素贝叶斯分类器[18]算法简单,对待分类项目给定输出,将各类别出现概率的大小认定为分类项目所属类别。朴素贝叶斯分类模型参数少,且对缺失值不敏感,适应微博短文本表达特点,适合用于微博情感分析中。贝叶斯算法原理如下
(10)
其中,w表示文本,由文本特征值{F1,F2,F3,…}描述,特征值由TF-IDF统计得到;c表示文本所属类别;P(C)表示某一类别出现的概率;P(W|C)表示某类别情况下文本出现的概率。计算式如下
P(W|Ci)=P(F1|Ci)P(F2|Ci)P(F3|Ci)…
P(Fi|Ci)
(11)
(12)
(13)
式中,Nj表示特征文本在Ci类中出现的次数;N表示属于Ci类的文本出现的总次数;Mj表示某种类别出现的次数;M表示所有类别出现的总次数。另外,由于进行分类时只比较概率大小,不再对分母P(W)进行计算。
贝叶斯算法对文本分类问题的描述为
(14)
式中,Fi表示微博文本特征词语。为避免在计算特征词类别概率为0的情况,概率公式引入Laplace平滑因子
(15)
其中,α表示特征的个数,同理可得式(16)。
(16)
2.4 结合词典与监督学习方法计算情绪值
(1)微博文本进行分词预处理,本文采用Jieba分词技术获取中文分词结果;
(2)逐个查找并匹配词典中分词的结果,在相应词典中找到词语以及标签,直到句子结束;
(3)根据识别到的情绪词计算微博情感值,根据情感值的大小判断微博所属分类。
3 微博数据准备
将情感分析的研究用于解决文本情感识别和分类问题时,需要大量真实微博数据进行试验。本文使用八爪鱼(Octopus)数据采集器设置采集字段进行数据采集,并删除没有情感分析价值的微博。
3.1 数据采集
收集微博文本是情绪分类实验的数据基础,采集新浪微博 “热门”部分的微博,采集字段为 “微博内容” 、“微博发布时间”、 “点赞数”、 “转发数”、“评论数”等,按照设置规则获取“热门”部分的全部微博。
由于获得的微博数量庞大,采集时适当延长数据返回时间,设置自动翻页循环,减少操作次数和时间。如图3所示,微博文本按照指定字段得到采集结果,并导出采集结果。

图3 数据采集过程
3.2 数据预处理
获取到新浪微博“热点”部分的微博不能直接被使用,需要对这些数据进行清洗、分词等预处理。首先,清除含有异常字符的微博;然后清除没有情感分析价值的微博,例如用于营销、活动推广的带有网络链接的博文,出现“领取”“红包”等词语的微博,或者单纯图片转发微博等。经过清洗与筛选之后得到的一部分数据,如表2所示。

表2 微博数据清洗结果
数据清洗部分完成对微博数据的粗略筛选,去掉没有分析价值的微博;然后进行分词处理,本文使用Python版本 Jieba进行分词。
为增加网络词的识别情况,载入网络词典,载入词典的核心代码:jieba.load_userdict(“%vlogdic.txt”)。分词处理得到的结果如表3所示。

表3 分词结果
载入网络词典之后,微博文本网络词识别能力有所提高,应用在情感极性计算上也更加合理。
4 实验结果
本实验用3个真实微博数据集来测试情感分析模型的性能,数据集包括:4月上旬连续半个月的微博数据、4月下旬连续半个月的微博数据及标准集(NLPCC2013会议提供的微博情感测试数据集)。本文从准确率和网络词识别度来评价模型性能。实验环境为Intel(R)Core(TM)i7-2600 ,Windows 7系统, 4 GB内存。
4.1 构建微博专用情感词典
将现有的基础词典融合构建微博专用情感词典,其中二分类词典包括积极、消极两种词典;多分类词典按照其分类标准分成多个类。对词典中词语的信息进行统计,具体内容如表4所示。
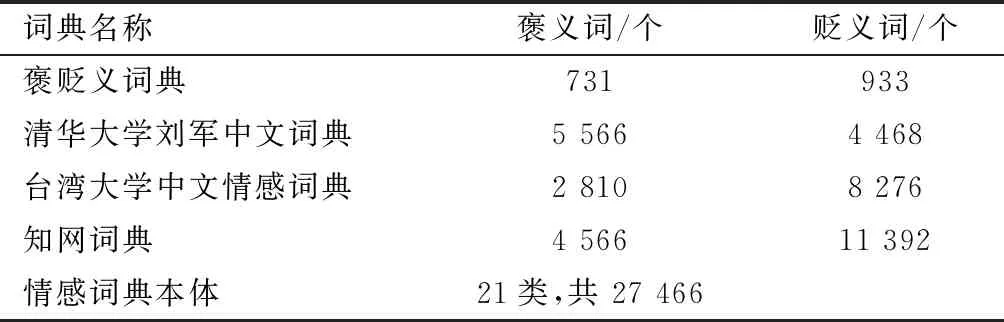
表4 基础词典内容
首先合并二分类词典;然后合并多分类词典,调用Hownet词语相似度接口。先计算“类别词”与基准情绪词的相似度,将相似度大于0.95的直接划分进词典中,若类别词相似度低,则逐个计算分类中词语相似度,直接舍弃相似度低于0.95的词语。然后添加网络词,筛选出有情感倾向的网络新词添加到词典中。从情感词中分别挑选积极、消极情绪值绝对值最大的12对词,并将有情感倾向的网络词作为基准词,在语料库中计算从网词网获取的400个词语情绪倾向(语料库使用的是“网词网”中所有网络词的解析数据)。最后,按照计算结果将网络词添加到词典中。
4.2 数据集
对微博主题情感分析的研究是当前研究的热点问题。微博平台上数据量巨大,然而,在科学研究中用于实验比较的标准数据集很少,因此,本实验自行构造了数据集扩充数据。
使用NLPCC2013会议提供的微博情感测试数据集以及采集得到的4月微博文本(分为上半月、下半月)两类数据进行试验,3个数据集记为First-Three、Mid- Three、Last- Three。
4.3 情绪分类正确率分析
本文采用最直接的准确率作为分析指标,并特别抽出具有网络词的微博文本,使用不同词典以及纯监督学习方法进行情感分析准确率比较。训练模型对文本进行情感分析得到的结果为(0,1)范围的情感值,情感值绝对值越大表明极性越积极,反之消极。根据情绪值大小将情绪细分为“重度积极”、“ 一般积极”、“ 中性”、“一般消极”以及“重度消极”。然后计算分析的准确率。载入不同情感词典,比较准确率,其中“dic1”代表褒贬义及其近义词词典,“dic2”表示清华大学中文词典,“dic3” 表示NTUSD台湾大学中文词典,“dic4”代表知网Hownet词典,“dic5”代表变形极性词汇本体,“dic6”代表本文提出的微博专用词典,实验结果如图4所示。

图4 不同词典准确率比较
使用6个不同词典测试同一数据集情感并分析结果的准确性,实验表明用文本提出方法构建的微博专用情感词典(“dic6”)准确性最好。
针对文本情感分析问题研究标准数据集(NLPCC2013会议提供的情感分析数据集),使用5-折交叉验证的方式,比较结合词典和贝叶斯分类算法与单独使用贝叶斯分类算法训练得到的分类效果,实验结果如图5所示。

图5 监督学习和词典结合方法与监督学习方法准确率比较
图5中词典和贝叶斯结合的分类方法效果优于单独使用贝叶斯分类。使用采集得到的3条极性不同且带有网络词的微博文本,以及情感极性明显的3条微博文本进行试验,载入不同词典得到的试验结果如表5所示。

表5 文本分析样例
其中,“文本1”代表“我很高兴”(重度积极,用“++”表示),“文本2”代表“我很难过”(重度消极,用“--”),“文本3”代表“好嗨呦,离开闵行已经十天了”( 重度积极,用“++”表示),“文本4”代表“蓝瘦,剪头发第一天”(消极,用“-”表示),“文本5”代表“高数考试啊,使出洪荒之力了”( 消极,用“-”表示),“文本6”代表“造飞机导弹尼玛当玩具啊?!”(消极,用“-”表示)。
对比上述6种词典的分析结果,“文本4”显然是消极的,但是由于常用词典对网络词没有识别能力,对情感判断存在误差。仅用本文提出的方法构建专用情感词典对含有网络词的微博具有识别能力,得到了更为准确的分析结果。
4.4 微博文本情绪测试
实验所用的数据采集自新浪微博“热点”部分,用本文提出的微博文本情感分析方法计算博文情感值,并将结果记录下来。实验以天为单位记录整月微博的文本情绪分析情况,如图6所示。

图6 整月热点微博文本情绪走向
通过对微博文本进行情绪分析能够了解网民情绪趋势,可以作为舆情监控的基础,情绪正负的极值点表明当日有特殊事件发生。
5 结束语
本文对数据量庞大的微博“热点”部分真实数据进行情感分析,使用Hownet相似度计算方法整合现有词典,采用PMI算法构建网络词典,识别网络词的情绪倾向,使所构建词典更加适应微博文本短小、新颖、时代性强的特点。本文利用Bayes算法,将词典与Bayes相结合,详细介绍了词典构建的过程,并对多种词典进行文本情感分析的结果进行比较。实验结果表明,采用本文所提方法进行情绪分析可以有效提高准确度。情感分析在舆情分析等方面具有重要的理论和应用价值,其中分类的准确性作为重要基础,有决定性作用。未来有两个方向还需要继续研究:一个是收集网络新词,完善现有词典;另一个是训练细粒度的分类模型,使分析模型细化为多种情绪模型,从而产生更加直观的效果。
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
时代英语·高一(2019年5期)2019-09-03
小学生作文·小学低年级适用(2018年12期)2018-04-11
电测与仪表(2016年11期)2016-04-11
校园英语·下旬(2016年2期)2016-03-18
电源技术(2015年5期)2015-08-22
中关村(2014年5期)2014-05-15
当代修辞学(2013年4期)2013-01-23
