
面向云网融合的细粒度多接入边缘计算架构
2021-06-17 14:06张健浩伍楷舜
计算机研究与发展 2021年6期
王 璐 张健浩 王 廷 伍楷舜
1(深圳大学计算机与软件学院 广东深圳 518060)
2(上海市高可信计算重点实验室(华东师范大学) 上海 200062)
(wanglu@szu.edu.cn)
近年来,平板电脑、智能手机、大规模传感器以及各式各样的异构物联网设备变得越来越流行,已经成为我们日常生活中的主要计算资源[1].据保守估计,到2022年,将有500亿台终端设备进行互联[2].随着终端设备的爆炸式增长,为终端设备设计的应用程序也大量涌现,如交互式游戏、自然语言处理、面部识别、增强现实等.这种类型的应用程序往往需要大量的资源,包括密集的计算资源和高速的传输资源.随着新颖的交互式移动应用程序的日益丰富和终端设备功能的日益强大,我们正处在移动计算的重大变革之中.
近期的研究进展见证了移动计算的模式转变.在终端设备不断产生的海量数据驱动下,集中式的移动云计算正在向移动边缘计算进行迁移.计算、存储和网络资源均在基站(base station,BS)端集成[3-4].网络边缘大量空闲的计算资源和存储空间可以被充分利用,以完成计算密集型和延迟关键型的计算任务[5-6].随着各种计算和存储资源越来越贴近终端用户,移动边缘计算有望为资源消耗庞大的应用程序提供超低延迟和超低网络拥塞的服务.
终端设备的爆发式增长使得无线连接成为发掘移动边缘计算潜力的关键技术之一[7].因此,移动边缘计算的适用范围已经扩展到无线接入网络(radio access network,RAN)内,以提供边缘计算的能力.这也称为多接入边缘计算(multi-access edge computing,MEC).在多接入计算架构中,边缘计算的资源可以部署在LTE基站(eNodeB)、3G无线电网络控制器(radio network controller,RNC)或多天线聚合基站中.多接入边缘计算将移动计算和无线通信2个学科的理论和技术进行了深度融合,是云网融合的典型技术之一,因此受到学术界和工业界研究人员的一致倡导.可以预见,将新型的无线网络技术与面向服务的边缘-云体系结构进行结合,可以显著降低网络拥塞和用户延时,提高用户的服务质量(quality of service,QoS)和服务体验(quality of experience,QoE)[8-9],为终端应用程序、内容提供商和第三方运营商提供更好的服务.
尽管研究人员在多接入边缘计算方向进行了不断的尝试和大量的努力,然而,由于终端设备的物理硬件限制以及无线信道的连接能力限制,多接入边缘计算依然面临着诸多挑战[10].目前的已有工作大多考虑粗粒度的资源分配策略,包括传输、计算和存储资源,这些分配策略缺乏对所有可能资源的细粒度控制,这成为实现延迟敏感服务的主要障碍.目前亟需新的多接入边缘计算架构,可以对所有的资源进行细粒度的灵活分配.具体来说,对于新的多接入边缘计算架构,我们考虑3个问题:
1)是否存在一种细粒度的多接入边缘计算架构,可以对网络资源和计算资源进行细粒度的协同优化,从而更好地支持终端多样化的云网融合?
2)如果存在这样的架构,那么,应该如何设计接入网的信道接入策略,从而使终端用户可以并发地使用细粒度的网络资源?
3)基于细粒度的网络接入策略,如何灵活地进行计算任务卸载,并对边缘计算资源进行分配,从而更好地支持多服务、多租户生态系统?
针对这3个问题,本文将系统地研究一种面向云网融合的细粒度多接入边缘计算架构.本文从网络底层入手,通过研究媒体接入控制层(media access control layer,MAC)和物理层(physical layer,PHY)的特性,讨论细粒度接入策略简单高效的解决方案、优化策略及系统结构,并结合边缘计算的计算资源分配需求,对计算卸载服务进行协同优化,从而较大程度地减轻网络传输负担,提高计算卸载效率.具体来说,本文提出了一种基于软件定义的细粒度多接入边缘计算架构,通过对网络资源和计算资源的灵活控制,可以更好地满足异构物联网服务的服务质量.具体来说,首先,由于无线接入网建立在多接入策略之上为异构物联网提供服务,因此本文解决了如何利用物理层/MAC层的切片来支持多用户简单高效的并发传输.进一步地,本文设计了一种基于深度强化学习的资源分配策略,可以对资源分配进行自适应的学习,同时,通过设计一种基于软件定义的多接入边缘计算架构,将控制平面与数据平面解耦,可以对所有可能的资源,包括网络资源和计算资源,进行统一的细粒度管理.最后,本文通过大规模的仿真实验,验证了该架构的有效性和可靠性.总的来说,本文的主要贡献有3个方面:
1)提出了一种基于软件定义的多接入边缘计算架构,通过对物理层/MAC进行简单高效的切片设计,可以对通信资源和计算资源进行细粒度的控制,从而更好地支持复杂的底层环境,满足多样的用户需求.
2)基于所提出的多接入边缘计算架构,我们设计了一种基于深度强化学习的资源分配策略,通过对网络资源和计算资源的自适应训练和学习,实现了低延时的计算卸载服务.
3)利用网络仿真软件NS3进行了大规模的仿真实验,并通过实验验证了所提架构的有效性.实验证明,相比于传统的MEC架构,该架构性能提高30%以上.
1 相关工作
由于物联网中计算密集型应用程序的大量涌现,以及工业物联网、车联网等新型业务的爆发式增长,网络业务需求日益复杂.大量的研究人员将精力投入到云计算与网络架构的融合设计中去,从而协同应对计算与传输的双重挑战.
Cloudlet是首个将云计算放在网络边缘的计算模式[11],其主要目的是为了支持资源匮乏的移动用户运行资源密集型和交互式应用程序.事实上,Cloudlet将计算资源接近移动用户的这种思想和WiFi的概念很相似,WiFi的设计目的就是为了让移动用户可以便捷地访问互联网资源[12].随后,Cisco提出了雾计算,将云计算从网络核心扩展到网络边缘,减少了需要向中央云系统所传输的数据量[13].因此,大部分的密集计算,以及终端用户收集到的数据,都可以由雾计算中网络边缘的雾节点进行处理和分析,从而大大减少了计算延迟和网络拥塞.然而,Cloudlet和雾计算并没有将计算资源整合到移动网络的体系结构中去.因此,Cloudlet和雾计算的节点常常由私有企业进行部署,很难为移动用户提供有QoS和QoE保证的计算服务[14-15].
云无线接入网络(cloud radio access network,C-RAN)首次将云计算的概念引入无线接入网中.在C-RAN架构中,传统BS被分布式远程无线电头(remote radio heads,RRH)和集中式基带单元(baseband units,BBU)所取代.而传统由BS负责的基带信号迁移到中央BBU中进行[16-17].通过这种去耦的方式,RRH只需要负责基本的射频功能,因此可以高容量地网络接入,而中央BBU则提供大规模的信号处理,例如集中编码和解码,以及联合波束成形和资源分配.
2014年末,欧洲电信标准研究所(European Telecommunications Standards Institute,ETSI)制定了移动边缘计算的行业规范,并首次提出了MEC的概念.作为C-RAN架构的补充,MEC旨在对接入网和云服务进行融合,将传统的云计算功能融入无线接入网中,从而更接近移动用户端[17].因此,MEC可以支持多种终端用户应用,例如无人驾驶、虚拟现实(virtual reality,VR)/增强现实(augmented reality,AR)、沉浸式媒体等.为了通过异构接入网,如5G,WiFi,LoRa来发掘更多MEC的潜力,ETSI在2017年将移动边缘计算正式更名为多接入边缘计算[18].经过这次修订,MEC服务器可以由网络运营商在接入网的任何位置进行部署,如BS(4G中的eNodeB、5G中的g NodeB)、光纤网络单元、WiFi接入点等.这次转型将计算智能迁移到网络边缘,可以更好地对网络资源和计算资源进行融合.
在MEC中,网络和计算的资源分配一直是关系到MEC性能的关键问题.文献[19]提出了一种集中式的多用户资源分配策略[19].通过对计算、存储和通信资源的协同优化,实现了较高性能的计算卸载策略.集中式的分配策略可以对资源进行协同优化,却具有较高的计算复杂度和传输代价,因此并不适用于分布式的多接入边缘计算架构.文献[20]提出了一种分布式的多用户MEC资源分配和计算卸载策略[20].通过交替方向乘子法(alternating direction method of multipliers,ADMM),文献[20]实现了较为高效的分布式资源分配策略.
近几年,人工智能与网络的结合取得了巨大的进步.由于MEC资源优化问题的复杂性,很多学者将深度强化学习(deep reinforcement learning,DRL)引入MEC之中.通过和网络环境不断地进行交互,从而自动学习不同情况下的最优分配策略.文献[21]将MEC的计算卸载问题描述成一个Markov决策过程(Markov decision process,MDP),并将用户和Cloudlet节点间的信道质量引入状态决策之中[21].文献[22]将Q-Learning和深度学习(deep learning)进行结合,从而自适应地学习最优卸载决策和卸载速率[22].
网络切片技术是5G新无线电(new radio,NR)的关键技术之一.切片技术允许运营商共享相同的网络基础架构资源,如频谱、基站等[23].通过切片技术,运营商可以基于单一物理设施为用户提供多虚拟网络运行服务,满足个性化的业务需求.第三代合作伙伴计划(3rd generation partnership project,3GPP)将网络切片定义为一项使运营商能够创建不同的网络来满足和优化不同市场需求的技术[24].而ITU-T将网络切片定义为逻辑隔离网络分区(logical isolated network partitions,LINP).隔离分区由多种虚拟资源组成,这些资源相互隔离并配有可编程控制和数据平面[25].大量的现有研究已解决了网络中不同级别的切片问题[26-30].在文献[26]中,作者提出了一种基于部分频域复用的资源共享协议政策,通过比较数据间的相关性来减少丢包.在文献[27]中,作者设计了一种切片资源的分配方案.通过调节切片资源的利用率来提高网络的整体性能.在文献[28]中,作者通过减少片间干扰来解决相邻基站之间的干扰问题.然而,目前很少有工作从接入网的物理层切片技术入手,讨论无线网络的资源优化问题.文献[29]第1次着重阐述了物理层切片对于无线网络优化的重要性,并提出了自适应的物理层切片分配算法.在文献[30]中,作者进一步提出,物理层网络切片要和边缘计算进行联合,并设计了相应的优化方案SI-EDGE,对MEC资源进行统一优化.
然而,当前的MEC架构没有将网络特性和计算特性进行很好地融合.而且,由于资源的分配过于粗粒度,并不能很好地适应底层网络复杂多变的情况和上层用户动态多样的资源需求.如图1所示,本文旨在提出一种细粒度的多接入边缘计算架构,将接入网的信道传输特性和基于软件定义的计算资源进行深度融合,通过深度强化学习,对所有可能的资源进行协同优化,以满足资源的高效利用.
为了实现以上目标,我们要从网络底层入手,重新思考整个网络的架构.因此,当前的设计面临着3个挑战:
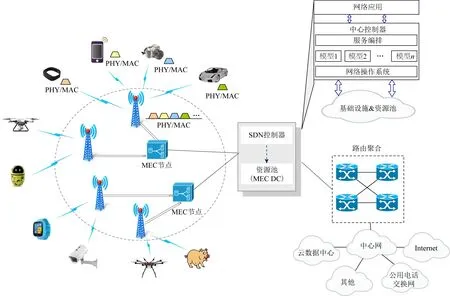
Fig.1 Fine-grained multi-access edge computing architecture for cloud-network Integration图1 面向云网融合的细粒度多接入边缘计算架构
1)为了保证接入网的信道资源可以细粒度地访问,接入网的物理层要实现切片,并对传输信号进行有效分离.这样,终端用户才可以在传统的接入网信道中细粒度地使用信道资源,实现按需的混合MAC并发传输.然而,如何在不改变原有调制编码的情况下,有效地将不同用户的数据区分开,进行MAC协议协同合作,是一个严峻的挑战.
2)传统的MEC架构基于固定的网络部署,这往往会增加资源调用的代价.基于软件定义的网络控制器应该如何部署,才能结合接入网的网络特性,尽可能减少控制信息传输代价,进行有效的资源卸载,也是一个继续思考的问题.
3)在保证细粒度的网络资源接入和灵活的计算资源部署之后,如何利用深度强化学习相关技术,更好地结合云网各自的优势来实现资源的有效利用,是本文需要解决的重要问题.
2 面向云网融合的细粒度物理层/MAC层切片
本节我们主要介绍面向云网融合的细粒度物理层/MAC层切片.该架构从网络底层入手,通过物理层/MAC层切片,可以实现接入网细粒度的混合MAC并发传输.
2.1 物理层/MAC层切片概述
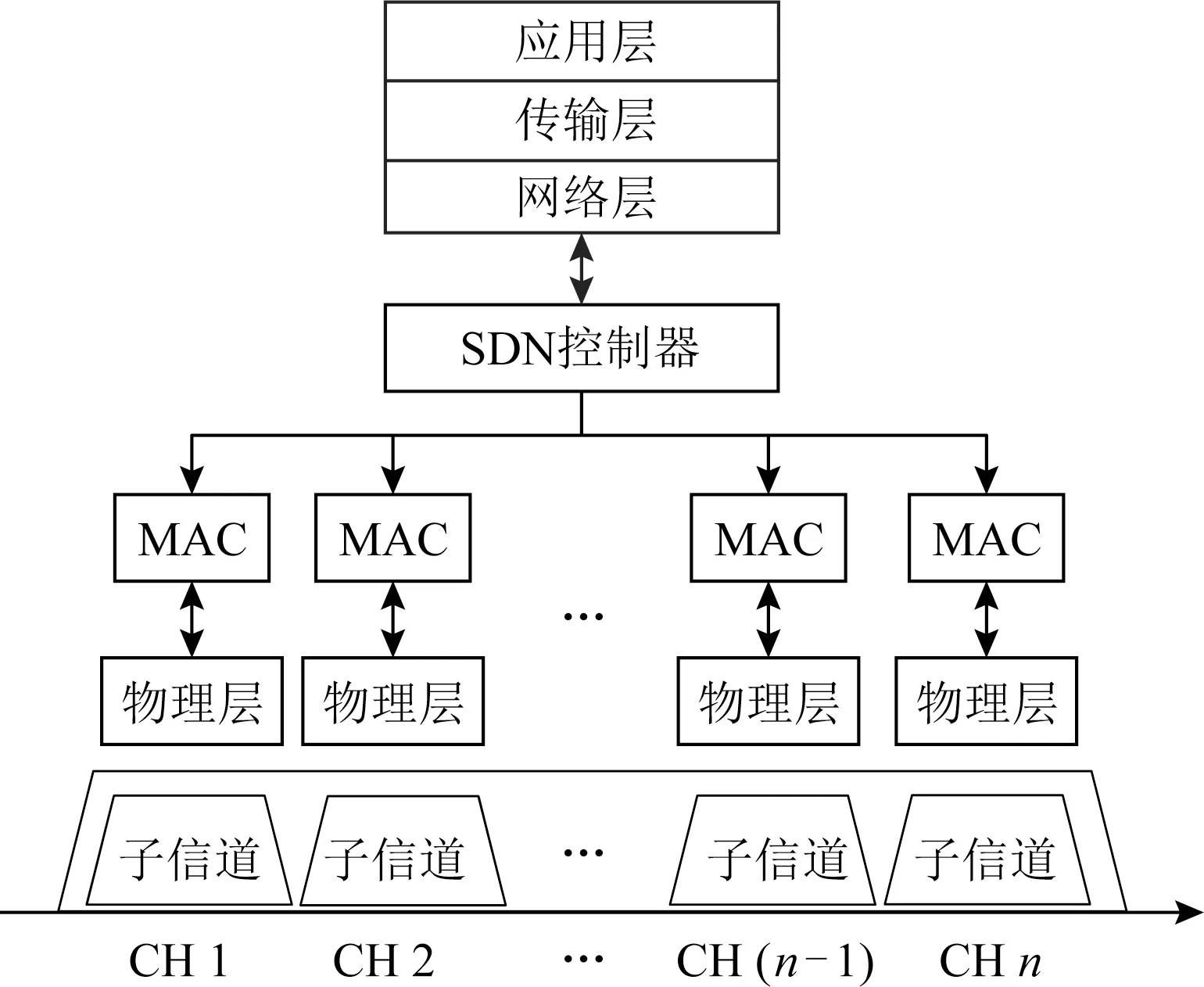
Fig.2 Design of edge computing protocol stack for cloud-network integration图2 面向云网融合的边缘计算协议栈设计
由于智能终端用户的传输需求动态多样,加之无线接入网底层的环境复杂多变,传统单一且粗粒度的MAC接入方式已经不能应对如此巨大的挑战.目前急需细粒度且灵活的MAC接入方式,来满足不同用户的传输需求.因此,本文从接入网的底层入手,首先提出了一种基于物理层和MAC层的切片设计.图2描述了基于物理层/MAC层切片设计的协议栈.原始的物理信道被切分成若干个细粒度的单元(例如,由若干子载波组成的子信道),每个子信道可以支持一种MAC接入方式.这样,不同的终端设备就可以根据自己的信道质量和传输需求,在同一个信道通过不同的MAC协议进行接入,从而最大化地对信道资源进行利用.具体来说,物理层/MAC层切片建立在正交频分复用技术(orthogonal frequency-division multiplexing,OFDM)之 上.通过对物理层子载波之间进行解耦和,从而实现细粒度的MAC访问.物理层/MAC层切片为终端用户接入网络提供了灵活、自适应的传输承诺.多种MAC访问在频域上的并发传输,可以更好地迎合终端用户动态多样的传输需求.在这种背景下,协议栈配有一个软件定义网络(software defined network,SDN)控制器,运行在物理层/MAC层切片之上,负责物理层子信道和MAC层协议的分配.通过及时调整物理层的子信道资源和MAC层的接入协议,SDN控制器旨在利用底层信道的多样性,对物理层和MAC层资源进行协同优化,最大化地提高资源利用率.
2.2 物理层/MAC层切片设计
为了使各式各样的智能终端设备可以利用物理层/MAC层切片设计进行细粒度的信道接入,本文设计中使用的基本访问粒度是元信道(meta channel).每个元信道由一组OFDM子载波组成.以无线局域网(wireless local area network,WLAN)为例,对于一个具有64个快速傅里叶变换(fast Fourier transform,FFT)点的20 MHz信道,通常每16个子载波(带宽为1.33 MHz)组成一个元信道,而若干元信道组成一个子信道.子信道可以是连续的,也可以在频域上相对分离.子信道的大小由SDN控制器统一进行安排,一般遵循2个标准:1)每个子信道的分配应足够宽,以确保满足终端用户的传输需求;2)子信道的分配也应该足够窄,从而充分利用频率选择效应进行适合的MAC传输.当一种MAC协议在一组子信道上进行接入时,剩余的子信道资源由SDN控制器进行分配,分配主要依据2个原则:终端用户的信道质量和传输计算需求.其中,子信道的质量由终端用户进行评估,并反馈给SDN控制器;而传输计算需求则在竞争轮询时将请求报告给SDN控制器.由于传统的时间竞争策略大大增加了传输代价,因此,本文设计了一种频域竞争策略.与传统的时域竞争相比,频域竞争策略可以充分利用频域资源.在频域竞争策略中,终端用户可以利用不同的频域同时进行资源需求的请求,因此可以避免时域竞争的传输冲突,大大降低了竞争的开销.
频域竞争策略的想法虽然听上去简单直接,然而,为了可以应用到细粒度的边缘计算架构中,需要设计两级F-RTS/F-CTS结构.图3给出了一个频域竞争策略的示例,整个信道分为5个子信道.当网络初始化之后,终端用户先等待DCF帧间间隔(DCF interframe space,DIFS),以完成同步.随后,在轮询时段,终端用户通过频域竞争策略进行传输/计算需求的请求.当SDN控制器获得所有用户的需求之后,将运行资源分配策略,根据终端用户的信道质量和传输/计算需求,对所有可能的资源(如传输资源、计算资源和存储资源)进行分配,并在F-CTS中反馈分配结果.在等待PCF帧间间隔(PCF interframe space,PIFS)之后,终端用户可以根据通知结果,去接入自己分配的信道资源.
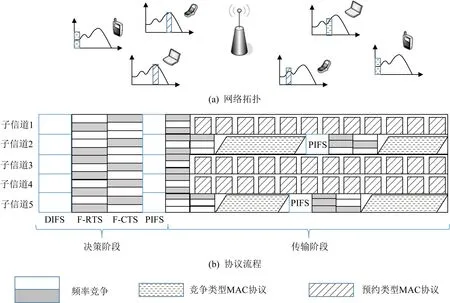
Fig.3 Physical layer/MAC layer slice example图3 物理层/MAC层切片示例
具体来说,两级F-RTS/F-CTS结构实现了两级的竞争轮询,分别是竞争/通知轮询阶段和传输轮询阶段.第1级的竞争/轮询阶段由F-RTS/F-CTS负责,用于信道和计算资源的分配.在第2级的传输轮询阶段,F-RTS/F-CTS有另外的用途.如果终端用户被分配的是竞争类型的MAC协议,如载波监听多址接入(carrier sense multiple access,CSMA),即如图3中的子信道2和子信道5,那么这2个子信道的F-RTS/F-CTS用于组织终端用户进行的接入网的访问.如果终端用户被分配的是预约类型的MAC协议,如图3中的子信道1,3,4,那么这3个子信道的F-RTS/F-CTS用于安排传输时间表.因此,F-RTS/F-CTS在这2层中具有不同的帧格式.举例说明,在第1级,F-RTS/F-CTS用于资源的竞争,因此在频域中,F-RTS/CTS包括2个部分:1)作为标识;2)作为竞争/通知频段.标识部分用来说明当前的帧是F-RTS还是F-CTS.这部分标识放置在帧的开头.以64点的FFT为例,通常来说,为了保证BAM的抗干扰能力,16个子载波比较合适.然后,在竞争/通知频段,为了保证抗干扰性能,以每4个子载波为一个基本单元进行传输需求的请求,而每12个子载波为一个基本单元进行计算资源的请求.相应地,在通知阶段,子载波也分成2个部分:1)用来确认MAC协议的分配;2)用来确认子信道的分配.在第2级中,F-RTS/F-CTS用于细粒度的接入网资源访问,由于终端设备的传输需求动态多样,第2级的传输可以用于不同类型的MAC协议进行并发传输.这部分的具体分配也由SDN控制器进行规划.例如,预约类型的MAC协议,如时分复用的多址接入(time division multiple access,TDMA)可以通过F-CTS进行传输调度安排.而竞争类型的MAC协议,如CSMA可以利用F-RTS/F-CTS进行细粒度子信道访问竞争.在第2级的CSMA竞争中,用户可以随机选择一个子载波作为其标识,并使用该子载波在F-RTS期间发送BAM符号.如果该终端用户的访问被授予,SDN控制器将在F-CTS期间在对应的子载波进行通知.通过这种方式,可以实现细粒度的接入网资源分配,最大化地提高接入网的频谱利用率和系统效能.我们进一步设计了基于Q-Learning的两级自适应资源分配学习策略,将在第3节中详细介绍.
3 基于软件定义的细粒度多接入边缘计算架构
本节我们将详细介绍基于软件的细粒度多接入边缘计算架构.传统的边缘计算架构无法充分地利用接入网和边缘-云节点的资源.在本文中,基于细粒度的物理层/MAC层切片,边缘计算可以更好地利用接入网特性和MEC节点的资源进行协同优化.
3.1 基于软件定义的多接入边缘计算架构设计
如图1所描述,具有存储和计算资源的MEC节点(例如服务器)部署在接入网之中,从而为终端用户提供具有弹性的网络服务,如计算卸载和服务缓存.这些MEC节点可以部署在eNodeB、BS、宏站甚至是小型基站之中.此外,MEC节点也可以部署在住宅区域,并通过边缘交换机或集成交换机进行接入访问.除了接入网络中的MEC节点之外,我们也在接入网和汇聚网之间根据需要部署具有适当规模的MEC数据中心(data center,DC),通常,汇聚网的聚合节点,例如公用电话交换网(public switched telephone network,PSTN)、中央或移动电话交换局(mobile telephone switching office,MTSO),是部署MEC数据中心的理想场所,因为所有流量在接入到Internet之前,都会经过这些节点.并且,MEC DC也是基于软件定义的数据中心,其中MEC节点(即包含计算、存储能力的资源池)根据需要由一个或多个SDN控制器进行控制.
图4给出了基于软件定义的多接入边缘计算分布式节点架构设计.这些MEC节点有几种不同的功能和角色,包括公共节点(common node,CNode)、区域代理节点(regional node,RANode)、超级节点(super node,SNode)和证书授权节点(certificate authority,CA).这些MEC节点的角色描述为:
1)CNode.CNode是最常见的MEC节点,分布在整个接入网中.CNode用于为终端用户提供计算卸载服务,并为远程Internet/云服务的服务缓存提供存储资源.CNode是高度虚拟化的,并且虚拟机(virtual machine,VM)可以在SNode的控制下远程安装/迁移到CNodes上.
2)RANode.RANode代表位于接入网中的区域代理MEC节点.RANode由SNode进行选择.SNode从接入网范围内的CNode中确定合适的RANode.RANode负责资源发现、管理/监视其区域内所有CNode的状态.尽管具有区域代理的作用,但RANode本身还是CNode,可以执行计算卸载.
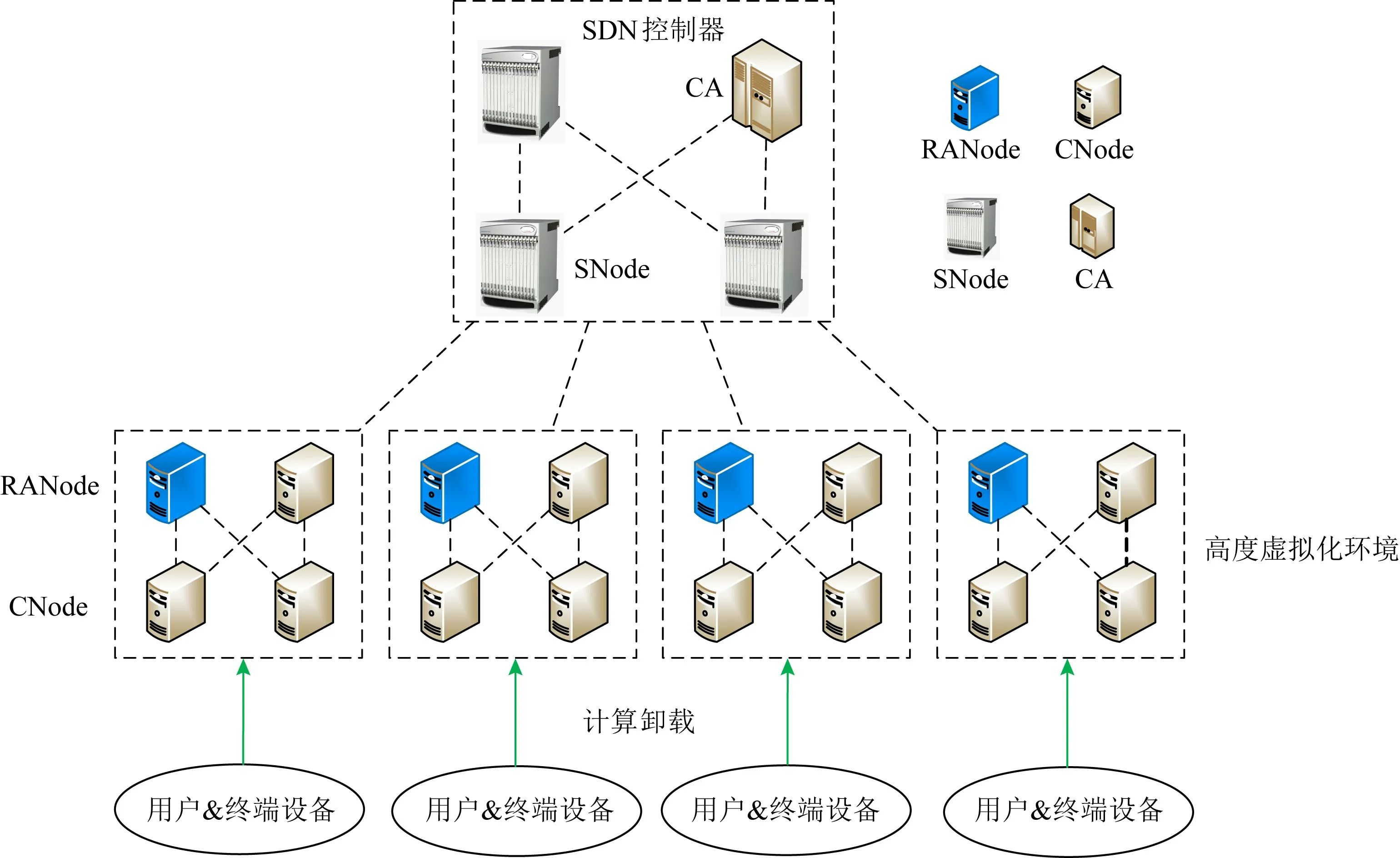
Fig.4 Software-defined based multi-access edge computing architecture design图4 基于软件定义的多接入边缘计算架构设计
3)SNode.SNode代表位于接入网和汇聚网之间MEC数据中心中的超级智能节点.每个SNode负责管理SDN控制器分配给它的一定数量的CNode和RANode.SNode的任务包括管理CNodes/RANode上的VM远程安装、节点的加入/离开(无缝扩展)、节点配置、用户管理等.SNode由SDN控制器控制,并且可以与其他SNode通信.SNode还可以缓存从远程数据中心卸载的Internet服务和云服务.进一步地,SNode可以将部分缓存服务卸载到更接近终端用户的CNode或RANode中,从而极大地提高计算卸载效率.
4)CA.证书授权节点CA是位于MEC数据中心内的节点,负责用户的证书生成和管理,提供签名、授权和证书的功能,并保留证书存储库内所有授权用户的信息.
3.2 云网资源分配问题建模
我们将面向云网融合的细粒度边缘架构抽象成图5所示的系统模型.该模型设定为由m个用户client i,i∈{1,2,…,m},n个边缘计算节点CNode j,j∈{1,2,…,n},SDN控制器SNode和中心云所组成的多层次网络.基于该系统模型,我们将资源分配算法进行建模,具体为:
1)用户任务.Client Task i(i∈{1,2,…,m}),表示用户i所提交的任务请求.Client Task i又可细分为Client Task i={Mem i,f i}.其中,Mem i表示任务所需内存大小,代表该任务所需的存储能力;f i则表示处理1 b数据所需的时钟周期,代表该任务所需的计算能力.
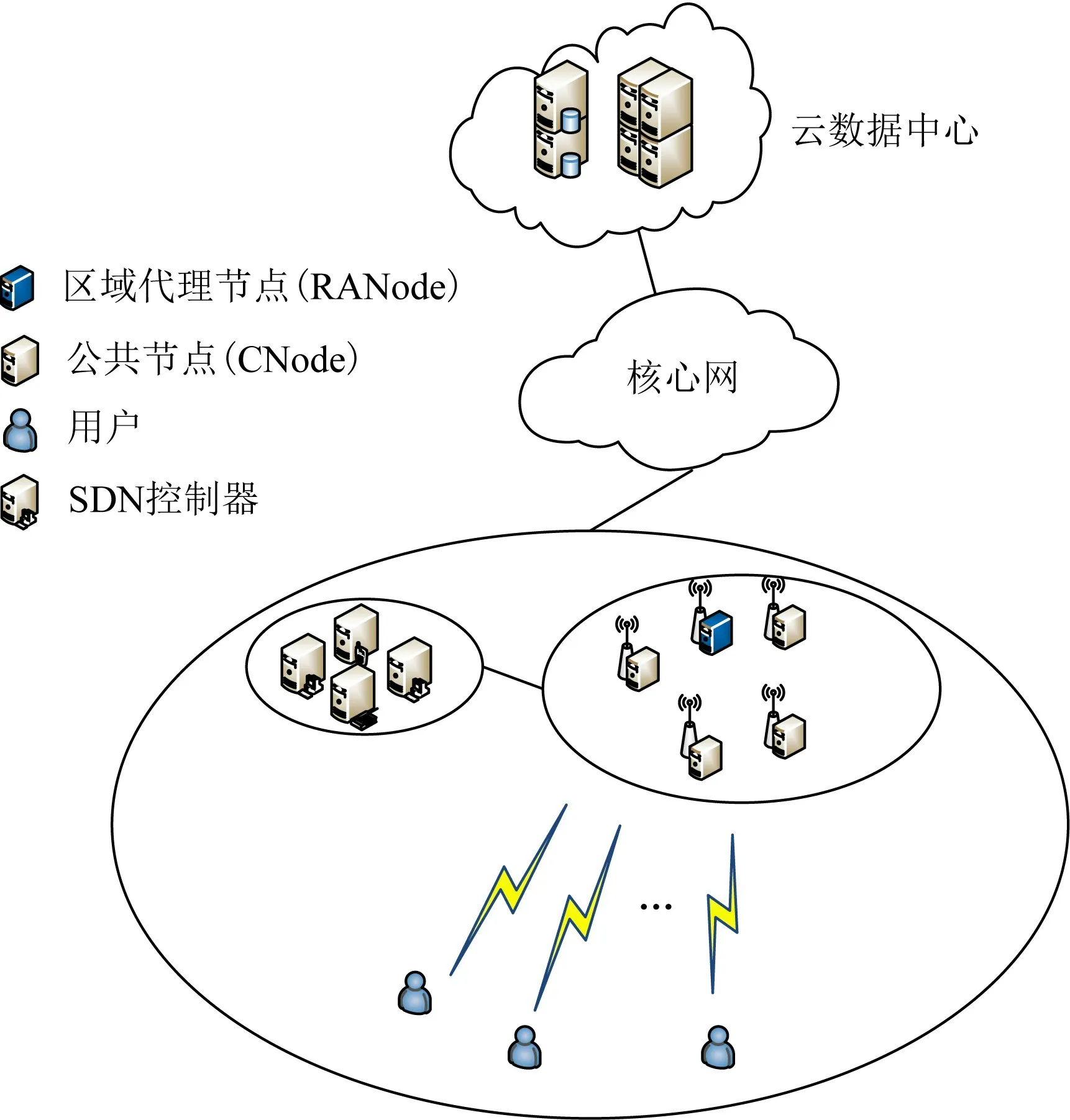
Fig.5 Resource allocation model for cloud-network integration图5 面向云网融合的资源分配模型
2)服务节点资源.ServerSource j(j∈{1,2,…,n}),表示服务节点j拥有的资源量.ServerSource j同样可细分为ServerSource j={Mem j,f j}.
3)MAC协议.MACProtocol={TDMA,CSMA}.
4)信道质量CSI.CSI={CSI c1,CSI c2,…,CSI cm}.
该模型应符合约束条件,即用户任务应小于服务节点资源Client Task i={Mem i,f i}≤∀Server-Source j={Mem i,f j},i∈{1,2,…,m},j∈{1,2,…,n}.而用户所选择的MAC协议与信道质量CSI之间也存在关系:MACProtocol=λ×CSI,其中,λ是选择某一种MAC协议的概率.
给定了用户任务ClientTask i和信道质量CSI i,我们的目标是优化整个系统的网络效用和计算效用,即

优化问题复杂度:这个优化问题可以转化成算法布林可满足性问题(Boolean satisfiability problem,SAT)[31].由于给定变量,包括Server,Task,CSI,MACProtocol,都对应着SAT问题中的一个析取范式C i,而SAT问题求解的实质是要确保每一个Ci中都能够存在1,从而保证子句C=1.对应于我们提出的问题,其实质就是对应给定的一个Task,能够正确地选择出合适的MACProtocol,CSI以及Server作为一组结果,也即SAT问题的解.因此,我们将SAT问题规约到我们的算法中继续解决,从而证明本算法属于NP-Complete问题.
3.3 基于Q-Learning的细粒度自适应资源分配算法
由于该问题是NP-Complete问题,本节提出了一种基于深度强化学习Deep Q-Learning(DQN)[32]的细粒度自适应资源分配方法.深度强化学习可以通过感知周围环境,不断进行学习,并根据环境的反馈进行策略调整,最终学习到最优的策略.在本文中,我们设计了一种融合网络和云端特性的协同学习优化策略.系统首先通过终端用户的接入网网络特性对传输资源的分配进行细粒度的学习,根据传输资源的学习结果,再结合边缘计算节点的计算性能进行计算卸载的策略学习,从而最大化地利用网络和计算资源.
具体来说,SNode首先根据终端用户的信道质量CSI i,i∈{1,2,…,m},对于每一个用户的物理层/MAC层策略进行自适应学习.假设当前一共有S个子信道channel j,j∈{1,2,…,s},用户client i所需要卸载的计算任务可表示为Task i={s i,g i},i∈{1,2,…,Q},其中Q表示用户i卸载的任务总量,s i表示任务数据输入大小,g i则表示请求的服务器计算资源大小.则SNode需要为用户client i确定使用的MAC策略MACProtocol i.
1)状态(State).control拥有所有的终端用户信道质量,因此control表示的系统整体状态为
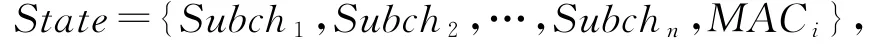
其中,Subch表示信道资源,MACProtocol i表示第i个用户分配的子信道MAC协议.
2)动作(Action).动作表示为control为用户选择的MAC协议,即Action集合为
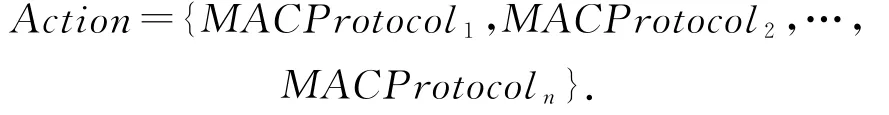
3)奖励(reward).奖励部分由执行动作前后的环境信息状态进行确定.如基于时延指标的环境信息,若State t=100 s以及State t+1=120 s,则易知存在-0.2的增长.因此,得到指标增长比:
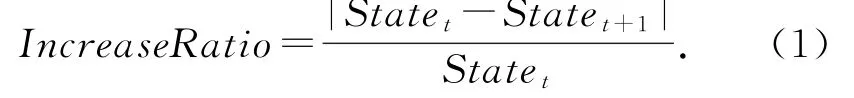
式(1)等号右侧分子部分采用绝对值形式,是因为基于不同的指标形式,指标增长比所带来的效果是不一致的.对于时延指标来说,指标值增加带来负收益,而对于吞吐量等指标来说,指标值增长则是正收益.因此,需要依照具体指标形式,设定指标增长比计算公式.
依照上述分析,可获取指标值的增长比,但是为了防止出现过拟合现象以及Q表更新合理性分析,设定为
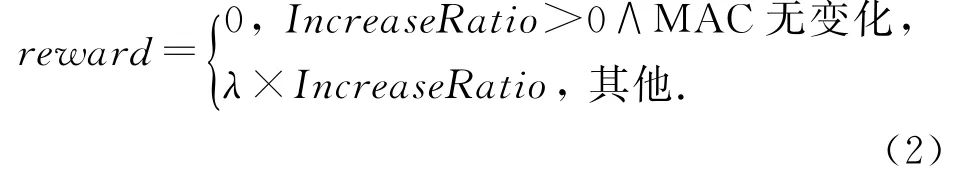
式(2)中,在已经获取优势MAC协议后,设定reward=0,以防止Q表值过大,Q-Learning收敛过快;λ则为衰减因子,防止IncreaseRatio过大,从而导致reward过大、过快收敛.算法1描述了基于Q-Learning的自适应MAC分配协议.
算法
1.基于Q-Learning的MAC协议选择算法.
输入:网络指标类型;
输出:网络性能指标.
①初始化Q表、初始状态;
重复:
②由当前状态以及网络指标类型确定当前网络状况;
③利用Q表或者ε_贪婪策略,基于当前网络状况选择MAC协议;
④用户改变MAC协议,并报告新状态;
⑤由新状态以及网络指标类型确定新网络状况;
⑥通过前后网络状况对比,计算动作奖励;
⑦依照获取的奖励更新Q表,并更新当前状态;
⑧记录本次网络性能指标;
结束条件:达到终止状态或者达到训练次数;
Return:网络性能指标.
当确定终端用户的物理层/MAC层策略之后,SNode进一步对终端用户进行计算卸载的策略学习.假设服务器Server j资源可表示为source j={f j},j∈{1,2,…,n},其中f j表示对服务器资源的综合评价.而通信方面分配的资源用MAC协议进行描述,即c k={TDMA,CSMA},k∈{1,2,…,n}.
1)状态(State).control拥有所有的边缘服务器信息以及用户所提交的任务信息,因此control表示的系统整体状态为

其中,EdgeServerSource n表示第n个边缘服务器所拥有的资源,Task u表示第u个用户的任务请求信息.
2)动作(Action).动作表示为control为用户选择卸载服务器,即Action集合为

其中,EdgeServer n表示第n个边缘服务器,cloud表示云服务器.
3)奖励(reward).由计算卸载的目标准则可知,针对用户任务卸载请求,完成任务所需要消耗的时延越短越好.因此易知,当用户任务卸载至本区域内的边缘服务器时,其所消耗时延将小于卸载至其他区域内的边缘服务器,远小于卸载至云服务器的时延.同理,卸载至其他区域边缘服务器所消耗的代价略大于本区域的边缘服务器,小于云服务器的代价.因此,设定不同的优先级标识不同层次的服务器级别.

依照不同的优先级,将获得不同收益;我们期望高优先级能够获取更好的收益,而中优先级所获取收益相对来说较少,而对于云服务器来说,由于其长距离导致的高时延问题,因此将获得负收益.其reward计算为
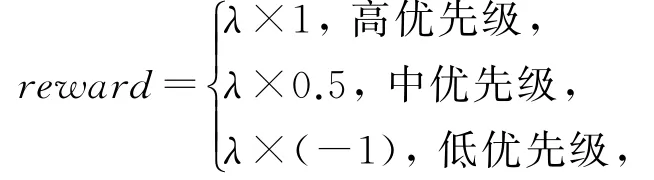
其中,λ表示衰减因子,防止网络收敛过快.算法2描述了基于DQN的计算卸载自适应学习过程.
算法2.基于DQN的计算卸载算法.
输入:预测神经网络、目标神经网络、经验池;
输出:网络性能指标.
①初始化 经验池、神经网络参数;重复:
②由边缘服务器信息以及任务请求确定当前状态;
③利用预测神经网络或者ε_贪婪策略,基于当前状态选择动作(卸载节点)Action;
④用户卸载至边缘服务器[Action]或者云服务器;
⑤获取新状态,并计算动作奖励;
⑥将四元组(当前状态,动作,奖励,新状态)存储到经验池;
⑦由经验池随机抽样作为预测神经网络的训练数据;
⑧基于预测神经网络、目标神经网络,计算损失函数;
⑨利用损失函数更新,预测神经网络参数;
⑩经过一定次数训练探索后将预测神经网络参数替换目标神经网络参数;
○
1记录本次网络性能指标;
结束条件:达到终止状态或者达到训练次数;
Return:网络性能指标.
算法复杂度:
我们定义函数regret来衡量采用的epsilon_greedy策略对探索和利用的平衡效果.具体而言,regret表示每一步平均的可能机会损失,其复杂度为Ω(min{T,A H/2}),其中T表示Q-Learning总训练步数,H表示每个episode的训练步数,A表示动作数量.因此,时间复杂度为一次Q-Learning算法训练时间,主要在于读取Q表,而Q表读取时间为S×A.因此总时间为:总训练次数×读取Q表时间,即O(T×A×S),T=KH,其中T表示Q-Learning总训练步数,K表示总的episode,H表示每个episode的训练步数,S表示服务器数量,A表示动作数量.而空间复杂度包含信道以及服务器资源存储空间和Q表存储空间,即O((C+S×|R|)×A×H),其中C表示信道资源量,S表示服务器数量,由多元组表示服务器资源,A表示动作数量,H表示每个episode的训练步数.
具体来说,SDN在本文设计的多接入边缘计算架构中的工作机制为:
首先,Internet服务提供商主动将与他们自己相关联的服务卸载到MEC节点.以图6为例,假设移动用户正在通过常规数据路径访问基于Internet的游戏前端服务器.该游戏服务提供商通过注册来使用MEC节点,从而主动卸载其服务并进行缓存,并将其存储在适当的SNode中.进一步地,SNode通过将服务复制到CNode来将服务推向最终用户.同时,CNode在固定时间间隔内搜集覆盖范围内的移动用户的信道信息CSI,并上报给SNode.
在计算服务被分流之后,当一个移动用户想要访问游戏服务器时,该用户向SNode提出自己的请求.SNode首先根据用户的信道质量,运行物理层/MAC层分配算法.下一步,根据终端用户分配的MAC协议及访问需求,SNode为该用户选择最佳的CNode进行卸载,若不存在合适的CNode,则将用户任务卸载至中心云.这样,相关的流量从网络核心和Internet上成功进行了卸载,从而大大减轻了流量负担.
4 实验与结果
本节我们使用网络模拟器NS3对本文提出的多接入边缘计算架构进行了仿真.我们首先验证了物理层/MAC层切片的可行性.进一步地,我们验证了基于Q-Learning的自适应资源分配算法的有效性.最后,我们对比了MEC架构中的随机卸载算法,以及目前最好的工作SI-EDGE卸载算法[30].通过大量的仿真实验证明,我们设计的细粒度资源分配算法相比经典的卸载算法,延时降低了30%,而对比SI-EDGE卸载算法,延时降低了10%.
4.1 实验设置
实验拓扑图设置如图5所示,我们考虑一个典型的MEC计算卸载场景.终端用户的信道模拟为频率选择性衰落信道(frequency selective fading channel),因此不同子信道之间的质量差异较大.信道基本带宽为10 MHz.终端用户随机分布在边缘计算节点CNode周围,MEC服务器的计算能力为fMEC=5 GHz/s,每个终端用户的计算能力为fUE=1 GHz/s.具体的实验参数设置如表1所示:

Fig.6 Example of SDN-based resource allocation and task offloading process图6 基于SDN的资源分配及任务卸载流程示例
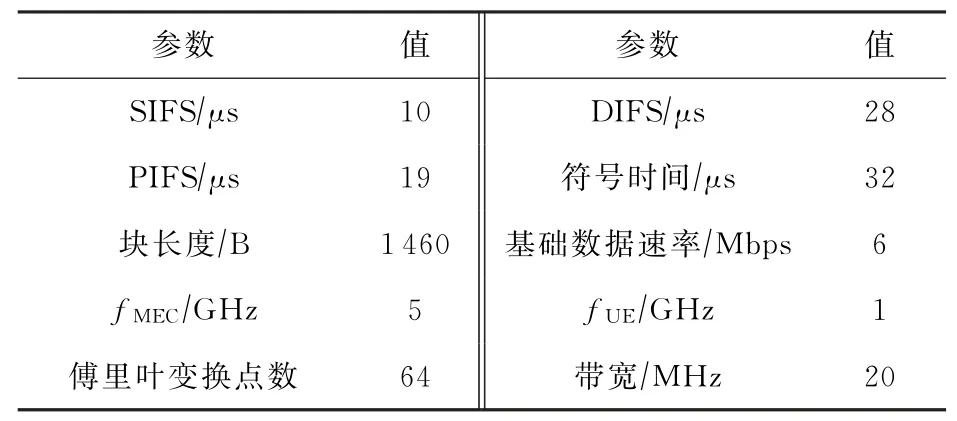
Table 1 Experimental Setup表1 实验设置
4.2 物理层/MAC层切片性能
在物理层/MAC切片中,频域竞争对于确保有效的无线资源访问至关重要.为了验证其有效性,我们通过单个冲突域拓扑进行模拟频域竞争策略.其中,SDN控制器作为集中控制部分,负责自适应策略的学习和最终分配解决方案的决定.因此在传输分配时不会产生冲突.然而,在传输竞争中,很可能几个终端用户随机选择到同一段子载波作为它们的竞争子载波.竞争子载波上的这种冲突将大大降低子信道的访问效率,冲突的终端用户无法将发送任何东西.在这里,我们评估2个或多个客户端选择相同的竞争子载波的可能性,从而评估频域竞争策略的可行性.
图7描述了频域竞争策略下不同数量的竞争用户碰撞的概率P.其中横坐标是用户的个数,纵坐标是选择同一段竞争子载波的概率.从图7中我们可以看出,碰撞概率P随着终端用户数量的增加而增加.因此随着用户数量的增加,用户选择同样的子载波的概率变得更高.为了应对这个问题,我们增加了子信道带宽来减少多用户之间的碰撞概率.当子信道中子载波数量n=8时,终端用户之间的竞争空间是28-1=255.此时,这个竞争空间产生的最大碰撞概率为30%.如果我们继续对子信道进行扩充,例如,当n=10时,随着竞争空间提升至210-1=1 023,则碰撞概率会迅速下降至10%.足够大的竞争空间,可以为用户提供更多的选择机会,去选择不同的竞争子载波,从而提供更好的接入网频域选择性能.

Fig.7 The conflict probability of the frequency domain competition strategy under different numbers of users图7 频域竞争策略在不同用户数量下的冲突概率
4.3 基于Q-Learning的自适应资源分配方法
本节我们对基于Q-Learning的自适应资源分配法进行仿真验证.首先,我们验证基于Q-Learning的MAC协议选择算法.我们设定一个动态网络环境,节点可任意接入,造成信道质量的波动.节点根据信道质量进行学习,从而选择CSMA协议或者TDMA协议.网络状况设置为:网络初始20 s保持较为空闲状态,在20~40s网络转换为繁忙状态,在40 s后网络又切换为空闲状态.在这种网络动态变化的情况下,我们验证根据不同信道学习对MAC协议进行学习的性能.
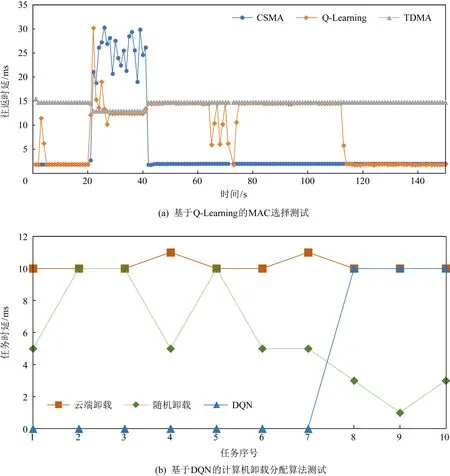
Fig.8 Adaptive learning algorithm test图8 自适应学习算法测试
图8(a)显示了用户对MAC协议的学习和切换过程.在网络初始的0~20 s之内,除了几次基于随机探索外,基于Q-Learning的MAC选择算法都能够正确地选择时延较低的CSMA协议.在20~40 s,由于信道质量突变,导致学习过程中产生巨大的负向reward,因此算法能够及时地切换MAC协议.可以发现,在该时间段,算法能够正确地选择时延较低的TDMA协议.然而在40~60 s时,我们可以发现网络状态已经切换为空闲状态了,但是算法不能及时反应时延较低的CSMA协议.这是由于从TDMA切换到CSMA协议所获得正向reward相对于前面突发网络所造成的负向reward较小,需要进行多次随机探索才能够很好地消除巨大负向reward造成的影响.在113 s时,算法经过多次随机探索后,正确地切换为时延较短的CSMA协议.
下一步,我们验证基于DQN的计算卸载算法.在训练初始阶段,根据一定概率,随机为用户选择节点卸载.因此,在训练初始阶段,部分的卸载选择了其他区域或者云服务器进行卸载.而当经过一段实验训练后,DQN做出的卸载决策主要集中于卸载至本地边缘服务器上.图8(b)描述了基于DQN的训练卸载结果.其中,当任务超过一定数量之后,如7个,超过了本地服务器的计算能力.由于任务量过大,DQN会选择卸载至云端,因此时延会有所增加.
4.4 基于软件定义的细粒度边缘计算架构的性能
本节我们对基于软件定义的细粒度边缘计算架构的性能进行了评估.对于传统物理层/MAC层未切片的边缘计算架构,我们设计的边缘计算架构可以使终端用户细粒度的接入无线网络进行计算卸载.我们选择了云端卸载、随机卸载以及SI-EDGE三种方法作为对比.为了保证对比实验的公平性,我们为这3种的计算架构添加了频域竞争策略,从而降低了竞争的传输代价.与本文设计的频域竞争策略一致,这3种边缘计算架构中终端用户利用FRTS宣布其计算需求,并且通过SDN控制器,利用F-CTS进行分配决定的通知.在云端卸载架构和随机卸载架构中,并没有使用切片化的物理层/MAC层资源,用户每次分别选择云端进行计算卸载(云端),根据一定的概率选择卸载的节点(随机).而在SI-EDGE中,网络使用切片化资源,并利用Edge Slicing Optimization Problem(ESP)算法进行网络和计算资源的联合优化.
图9描述了在不同任务数量的对比下4种计算架构的服务时间.首先,云端卸载和随机卸载,由于并没有利用切片化的资源,因此和本文提出的MEC架构表现出很大的性能差异.在云端卸载和随机架构中,服务时间随着用户数量的增加而迅速增加设备用户.由于传统的架构每次只能服务一类的MAC协议,并不能同时满足多种多样的计算要求.相比而言,本文设计的细粒度MEC架构在频率上可以对多种MAC进行并发传输.由于多个MAC协议可以同时运行,并且每个子信道可以根据终端用户的信道质量,最大化地进行计算卸载的协同优化,因此,能够适应动态多变的终端用户的需求.
相比而言,由于SI-EDGE的架构也采用了切片技术,因此SI-EDGE相较于云端卸载和随机卸载也表现出良好的性能,然而由于SI-EDGE并没有采取MAC的学习策略,因此其性能相比本文提出的细粒度卸载策略还是有所差距.可以发现,在前面任务数量较少时,SI-EDGE策略和本文设计的策略之间差异较小,而随着任务数量的增多,两者之间的差异也越来越大.原因主要是因为任务数量增大,从而使得本文涉及的策略增加更多的训练学习机会,因此能够更好地决定卸载决策.

Fig.9 Performance comparison of MEC图9 MEC的性能比较
最后,我们测试了本文设计架构的可靠性.我们分别测试了在链路故障和节点故障下,计算卸载的性能分析.我们随机选择一条链路使其故障,此时,SNode会直接从路由表中删除当前链路,并启用备用的链路进行传输.图10(a)描述了链路故障下计算卸载时延的变化.其中,加粗线条表示的是节点切换路由表项的时间,其所需时间较短.由于训练后,节点选择的链路会比备用链路更好,因此链路故障之后,最初数据包的往返时延会随着更换链路而增大.但是仍然可以继续进行计算卸载并在线学习.随后,我们进行了节点故障的测试.我们在计算节点中随机选择一个节点使其故障.此时,用户会向RNode提出切换节点请求,而RNode会返回相应新节点并将业务迁移到新的节点上.因此,节点故障后,并不能够很快发送和接收数据包,而需要等待一段迁移时间才能够获取到达新节点的往返时延.图10(b)描述了节点故障下计算卸载的实验变化.其中,结果中所示的节点进行业务的迁移时间,由于要进行业务迁移,时延增加较多,然而,在该架构下计算卸载仍可以顺利进行,并可以继续在线学习.
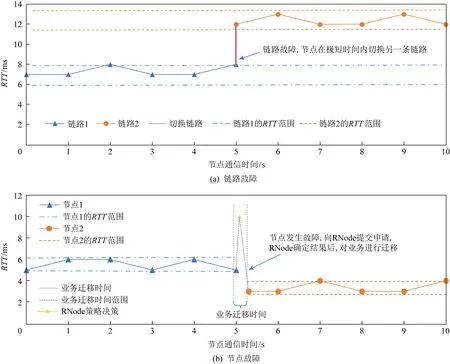
Fig.10 Reliability analysis of fine-grained multi-access edge computing architecture图10 细粒度多接入边缘计算架构的可靠性分析
5 总 结
针对目前多边缘计算架构中资源优化粒度粗、掌控不充分等诸多问题,本文设计了一种基于SDN的细粒度多接入边缘计算架构,可以对网络资源和计算资源进行细粒度的控制并进行协同管理,从而提高多接入边缘计算的服务质量.本文提出了接入网简单高效的物理层/MAC切片方法,可以根据设备的计算要求来支持混合的按需并发传输.本文进一步设计了一种基于深度强化学习Q-Learning的两级资源分配策略,对网络资源和计算资源进行自适应的细粒度学习,并通过软件定义的体系结构将控制平面与数据平面分离,增加了边缘计算架构的灵活性和可靠性.与传统固定的边缘计算架构相比,本文提出的细粒度架构可以对所有的资源进行逻辑集中控制,因此控制平台能够提供更有效的计算分流和服务扩展.我们讨论了所提架构的可行性,并通过仿真证明了其有效性.
为了能够充分发挥多接入边缘计算的软件定义计算卸载的潜力,仍需解决多项研究问题.由于能耗始终是物联网设备的主要问题,因此应在计算分流和能耗之间取得平衡.此外,安全性和隐私问题在物联网计算卸载中也至关重要.在下一阶段,我们建议在实时测试平台(例如软件定义的无线电和软件定义的网络平台)上验证本文提出的多接入边缘计算框架,并将更多功能集成到该框架中,以使更多物联网应用受益.
猜你喜欢
科学与财富(2019年11期)2019-08-06
中国新技术新产品(2017年9期)2017-04-13
中国新通信(2016年21期)2017-01-06
中兴通讯技术(2016年3期)2016-06-22
中国新通信(2016年2期)2016-03-11
新媒体研究(2014年11期)2014-09-01
新媒体研究(2014年7期)2014-05-21
中国信息化·学术版(2013年5期)2013-10-09
现代电子技术(2009年9期)2009-06-25
