
基于空洞卷积与多尺度特征融合的室内场景单图像分段平面三维重建∗
2021-06-16 10:36:08孙克强缪君江瑞祥黄仕中张桂梅
传感技术学报 2021年3期
孙克强缪 君江瑞祥黄仕中张桂梅
(南昌航空大学计算机视觉研究所,江西 南昌330063)
基于图像的室内场景三维重建是计算机视觉领域的一个重要研究内容,它在视觉SLAM(Simultaneous Localization And Mapping)、虚拟现实(Virtual Reality)、增强现实(Augmented Reality)等领域具有广泛的应用。
基于图像的三维重建一般需要获得场景深度信息及相机参数,然后利用二者逐像素计算得到的三维点云建立模型。室内场景通常包含大量的平面结构,例如墙壁、天花板等。基于图像的分段平面重建是常用的方法之一。这类方法除了计算深度信息及相机参数外,还估计场景包含的平面,因此重建精度更高。目前常用方法有布局估计法[1]、曼哈顿假设法[2]及各种体素重建法[3],但单张图像对应着无数真实物理世界场景,重建的逆推过程存在很多歧义,而且除受光照变化影响外,室内场景还存在纹理缺乏的挑战。近年来,深度学习算法被快速应用到计算机视觉的各个领域,基于深度卷积神经网络可以从图像中学习场景丰富的特征表示,故利用深度神经网络的单幅图像室内场景三维重建已有研究[4-5]。这些算法将平面分割和深度估计统一在共同的深度学习框架内,但都存在以下问题:①没有充分考虑到平面内待重建目标物体的细节,易丢失平面内小物体的信息;②预测的分割图及深度图的边缘效果不佳,影响重建精度。
为了解决上述问题,本文针对室内场景重建提出了一种端到端分段平面重建算法(如图1)。该算法将平面分割和深度图预测任务整合到一个深度卷积神经网络中,对室内场景中的整体结构进行快速高效的推断和分析,本文的主要技术贡献包括以下两个方面:①提出了一种基于深度卷积神经网络端到端的方式实现室内场景的三维重建算法;②改善了平面内待重建目标物体的细节信息及预测的分割图及深度图边缘效果不佳的问题。

图1 单图像室内场景分段平面重建
1 相关工作
在室内机器人导航及社交媒体等新兴产业有着广泛应用的场景三维重建是计算机视觉和计算机图形学重点问题。其中,三维场景中的平面区域为一些类似于场景理解[6]和场景重建[3]等三维感知任务提供了极为重要的几何线索。
大多数传统室内场景平面预测和重建方法[7-8]都需要借助多幅图像的输入或深度信息。Deng等人[9]近来提出了一种基于学习的方法用来恢复室内场景中的平面结构,但它需要已知深度信息。随着如基于模板的形状组合[10-11]、包围盒[12]或线框[13]形式的目标检测框架结构在三维理解任务中的广泛应用,对室内场景中的目标对象进行形状预测,但只能得到粗糙的目标对象,对具有遮挡和复杂特性的室内场景重建能力具有一定的局限性。
除了利用检测的框架结构外,联合优化的分割掩模对于一些需要更精确的平面参数或边界的三维重建应用来说很有帮助。通过近年来在语义分割方面的研究,发现全连接条件随机场(Conditional Random Field)在边界分割及定位方面表现十分奏效[14]。CRF通常只利用低级语义信息,需利用图形化模型[15]或设计新的神经网络[16-17]从而进一步利用全局上下文信息。
在规则的人造环境室内场景中存在很多平面结构,利用这些平面区域的空间信息使得三维场景的恢复变得便利。此外,针对室内场景,基于分段平面的重建算法通常可以恢复完整的室内场景结构,这是传统的像素或空间点级的算法难以企及的。
基于分段平面深度图的重建曾经是多视图三维重建领域的一个热点话题[18]。其主要任务是通过二维图像推断出一组平面参数,同时再为各像素标定平面序号。目前,现有的大多数的方法都是先重建出精确的三维点,再通过拟合后的平面生成平面假设,然后再通过求解一个全局推理问题将分段平面的深度图重建出来。基于多视图的三维重建须从不同角度采集场景多幅图像,但现实生活中拍摄的照片单幅居多。本文提出的端到端的三维重建方法以单幅RGB图像为输入,直接推断平面参数、分割图及深度图,进而重建出室内三维场景。
在2006年,Saxena等人[19]通过提出的基于学习的方法,直接从单幅RGB图像中推断出深度图。随着深度神经网络的研究和发展,许多基于卷积神经网络(Convolutional Neural Network,CNN)的方法被一一提了出来[20-21]。但大多数的技术方法只是通过单幅RGB图像生成了深度图(仅有一组深度值)并没有进行平面分割掩膜处理或平面检测;在2016年,Wang等人[22]利用提出的方法通过推测出处于平面上的像素来进一步进行深度和表面法线预测。但该方法仅能判断出像素是处于平面还是非平面上,未能对平面进行分割处理和平面参数估计,这导致该方法的重建缺乏时效性和高可靠性。最近,Zhou等人提出的PlaneRecover[4]和Liu等人提出的PlaneNet[5]均是将单图像三维重建看作是平面分割任务,这与我们的工作很接近。但本文进一步考虑了平面内待重建目标物体的细节和易丢失平面内小物体的情况,并对边缘像素进行了监督,使得重建精度更高。
2 本文的算法
2.1 算法概述
本文算法的目标是通过CNN预测直接从单幅RGB图像中得到室内场景的深度图、分割图及平面参数,然后将平面深度图与相机标定获取的相机参数相结合,得到逐像素的三维点云深度信息(3D点坐标),并通过平面拟合恢复各平面结构。这就使得本文算法必须要满足两个条件:①能够准确地检测出场景中的平面;②在获得室内场景各平面深度图的同时,还要能够对室内场景中的平面进行平面参数的估计及分割掩膜处理。本文使用包含语义标签和深度信息的数据集训练一个深度神经网络,以此得到平面参数、分割图及深度图。
如图2所示,本文设计的深度神经网络整体上包含两个分支。一个分支整合了分割图和深度图的预测任务,另一分支进行平面参数的预测任务。首先,输入单幅RGB图像,经过RESNet-101处理后得到输入图像的特征图(Feature Map);接着经过全局平均池化(Global Average Pooling)和双线性插值(Bilinear Iterpolation)对特征图分别进行下采样和上采样操作;最后,再经过条件随机场对分割图进行优化。前一分支输出分割图及深度图,后一分支输出平面参数。其中,平面参数包括平面法向信息和偏移量。通过本文预测得到的平面参数、深度图及分割图,即可确定室内场景中的各平面结构及三维空间范围。最终,利用逐像素的三维点云深度信息,并通过拟合平面恢复各平面结构,实现分段平面的三维重建。
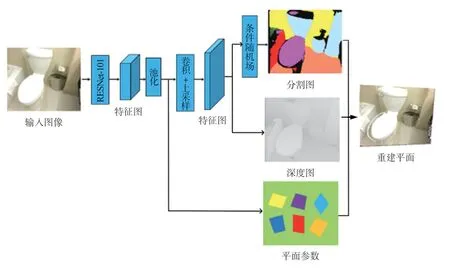
图2 算法流程
2.2 算法网络结构
本文提出的神经网络结构建立在深度残差网络(Deep Residual Networks,DRN)[23](如图4)上,包含三个主要部分:特征提取网络,分割细化网络以及平面参数网络。
为了预测空间点的数值,我们采用小卷积核进行卷积。但固定的感受野不利于检测复杂场景中大小不同的物体。相比于核尺寸相同的卷积,空洞卷积可以在不增加计算量和参数量的情况下增加卷积核的感受野。感受野RF、卷积核尺寸C及空洞率V之间的关系为:
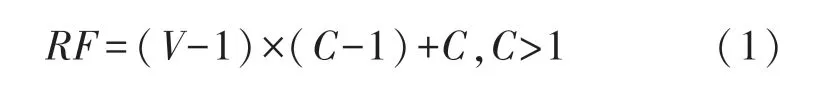
当V=1时,即为普通卷积。空洞率V越大,可使卷积核获取更大感受野、采样更大范围。

图3 部分特征图结果示例
特征提取网络:特征提取网络利用加入空洞卷积的ResNet-101网络,提取全局特征(如颜色、纹理特征等)与局部特征(如边缘、角点等),输出高分辨率的特征图。以如图3(a)所示的输入图像为例,本文将DRN作为基础网络提取全局特征,将网络对输入图像采用卷积等操作进行特征提取,得到不同分辨率的特征图。这些特征图分别为输入图像的1/2,1/4,1/8,即128×96,64×48,32×24。部分特征图结果如图3(b)所示。局部特征提取将PSPNet[17]作为基础网络,并利用改进后的PSPNET(Refine PSPNet,如图5所示)对DRN网络产生的不同分辨率的特征图进行处理。为了保留特征图中大量的有效信息及减少计算量等因素,本文利用全局平均池化对特征图进行处理,结果如图3(c)所示。首先将网络产生的分辨率为32×24的特征图经过金字塔池化及1×1卷积操作后,将产生的分辨率均为32×24的四层特征图进行双线性插值操作,并且与DRN网络产生的相同分辨率的特征图进行拼接;接着,将通过3×3卷积和双线性插值上采样产生的分辨率为64×48的特征图与DRN网络产生的相同分辨率的特征图进行拼接;然后,再通过3×3卷积和双线性插值将产生的分辨率为128×96的特征图与DRN网络产生的相同分辨率的特征图进行拼接;最后,为了将特征图恢复到输入图像大小,本文通过双线性插值[24]对特征图进行处理,图3(d)显示了部分实验结果。
分割细化网络:分割细化网络包括分割图分支和深度图分支。该网络利用Refine PSPNet,首先将DRN输出的不同分辨率的特征图进行平均池化、卷积、拼接等操作;接着将拼接后的特征图进行双线性插值,生成分辨率为256×192的分割图;最后,在分割图预测分支加入用于图像像素分类的概率图模型-条件随机场对分割图进行分割优化。
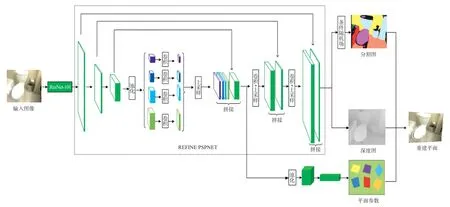
图4 网络结构图
为了控制深层网络结构的参数量和计算量,本文将深度图预测分支与分割图分支整合在同一个金字塔池化模块下。由于在人工环境中,平面与非平面类分布不均衡,故本文通过交叉熵损失函数用于监督分割图的训练过程。
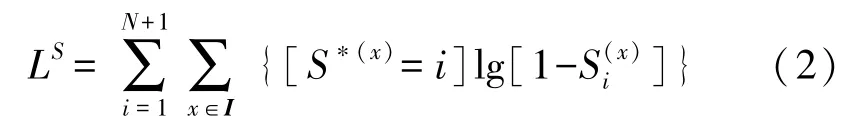
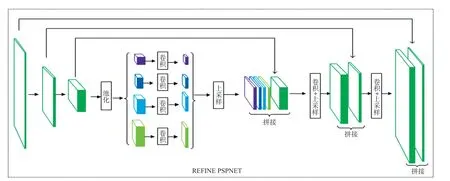
图5 改进后的PSPNet(Refine PSPNet)
对于深度图预测分支,首先通过Refine PSPNet将生成的多尺度特征图经过双线性插值及与本文设计的网络产生的各分辨率特征图进行拼接等操作,最终生成分辨率为256×192的深度图。本文利用真实的深度图与预测的深度图间的差值平方和作为深度图的监督训练损失:
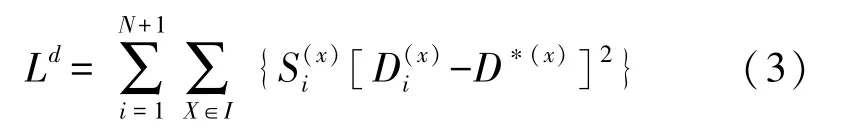
平面参数网络:平面参数网络将利用Refine PSPNet,将拼接后的分辨率为32×24的特征图经过平均池化得到1×1的特征图,再经过全连接层,得到平面参数。本文首先将设计的网络产生分辨率为32×24的特征图经过金字塔池化处理,再经过1×1卷积操作将产生的分辨率均为32×24的四层特征图进行上采样操作,并且与DRN网络产生的分辨率同样为32×24的特征图进行拼接;然后将通过平均池化操作产生的特征图通过1024个通道的全连接层处理,产生平面参数。
由于在预测平面参数任务过程中,平面的回归顺序不可知,故本文利用倒角距离作为平面参数回归的度量指标,定义了无序损失函数对平面参数进行监督训练。
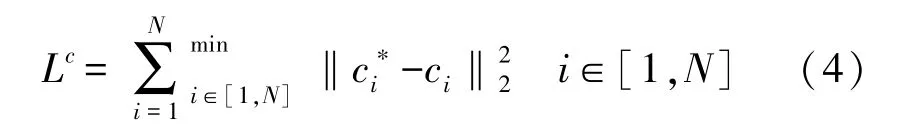
通过利用上述各分支损失函数监督训练得到输入图像场景中的分割掩模图、深度图及平面参数,通过训练总损失:

完成本文提出的深度神经网络各分支监督训练。其中,Ls为分割掩模损失;Ld为深度损失;Lc为平面参数损失。
为了防止在训练时出现过拟合问题,在网络中使用Dropout方法,使全连接层的神经元以一定的概率失活并不再参与前向和反向传播,随机忽略部分学习参数。
3 数据集及评价指标
3.1 数据集
本文使用目前具有代表性的大规模室内场景数据集—ScanNet[25],这是一个大型室内RGB-D视频数据集,包含了1513个场景的250万个视图,并标注了3D相机的姿态、表面重建和语义分割。ScanNet包含各种室内场景,例如办公室,公寓和浴室等。数据集既包含了一些如浴室、杂物间等小的空间集合又涵盖了一些如教室、图书馆等大的空间集合。由于计算机内存和显存等因素的限制,我们只从数据集中选取共51000张图片用于实验研究。其中,训练集有50000张图片,测试集有1000张图片。另外,选用NYU Depth Dataset V2[8](NYUV2)数据集对本文预测的深度结果做定量分析。部分数据集示例如图6所示。

图6 数据集示例
3.2 评价指标
对于单目图像深度图的预测,我们采用以下几种定量的评价指标进行计算:①相对误差(Relative Error,Rel);②平方相对误差(Square Relative Error,Rel(sqr));③均方根误差(Root Mean Squared Error,RMSE);④对数均方根误差(Logarithmic Root Mean Square Error,RMSE(log));⑤对数平均误差(Logarithmi Mean Error,log10);⑥阈值误差(Correct,δ(%))。通常,误差值越小且精度值越高,预测的深度图质量越好。
其评价指标计算公式如下:
①相对误差(Relative Error,Rel),其公式为:
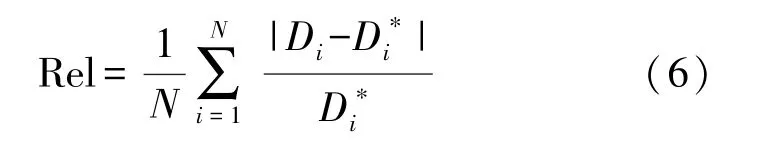
②平方相对误差(Square Relative Error,Rel(sqr)),其公式为:
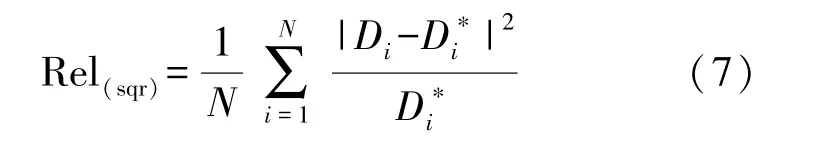
③均方根误差(Root Mean Square Error,RMSE),其公式为:
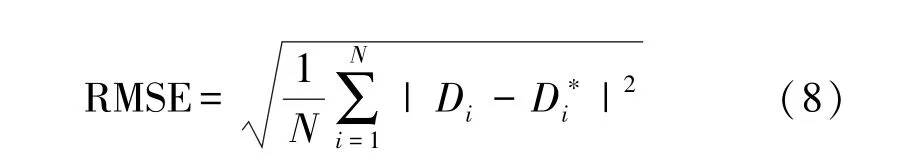
④对数均方根误差(Logarithmic Root Mean Square Error,RMSE(log)),其公式为:
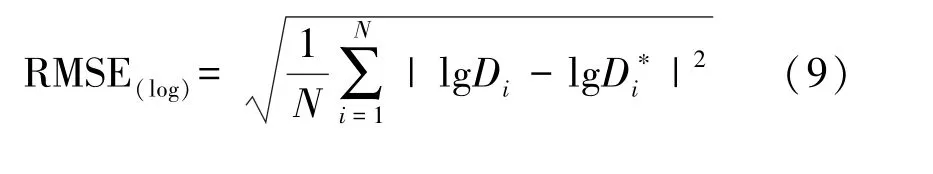
⑤对数平均误差(Logarithmi Mean Error,log10),其公式为:
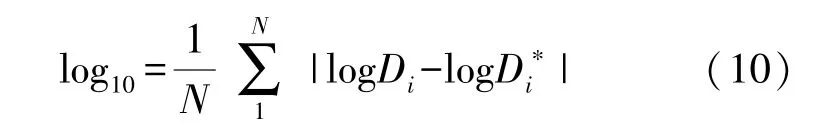
⑥阈值误差(%,Correct)δ,其公式为:
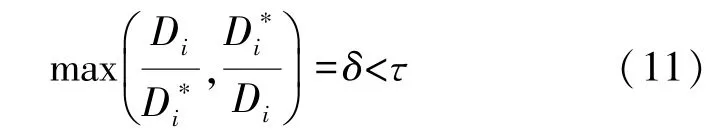
式中:N为像素总个数,Di为第i个像素的预测深度值,为第i个像素所对应的真实深度值,τ为设置的阈值,通常所设定的阈值为:1.25、1.252、1.253。
4 实验结果
我们基于ResNet-101网络结构,通过使用TensorFlow[26]的框架实现了本文的算法。本文利用ScanNet训练集进行训练,共迭代500000次,使用Adam优化器[27]进行参数优化,初始的学习率(Learning Rate)定为0.0003。我们在平面分割结果、深度预测精度和重建结果方面将本文算法和其他方法进行了比较。
4.1 平面分割结果
为了评估本文的平面分割算法,NYU-Toolbox[8],曼哈顿世界立体视觉[2](MWS),分段平面立体视觉[28](PPS)以及PlaneNet[5]被用来进行比较。NYU-Toolbox是一种使用随机采样提取平面的算法,并通过马尔可夫模型对分割掩模进行优化;MWS在提取平面过程中使用了曼哈顿世界假设,并采用成对的消失线来改善平面提取结果;PPS使用消失线产生了较好的平面候选区域;PlaneNet使用深度卷积神经网络提取平面特征。
图7展示了各种算法在ScanNet数据集上的部分平面分割结果。从图中可以看出来:其他方法在进行室内场景的分割时,不能够准确的分割出室内场景的平面(如图7中框中所示)且无法捕捉到精确的边界。本文利用空洞卷积增加卷积核的感受野,捕获更多空间语义信息,并融合多尺度特征,故可以对室内场景平面进行准确分割,并且通过将全连接条件随机场优化的定位精度与深度卷积神经网络的识别能力耦合,从而可以更好地处理边界定位。
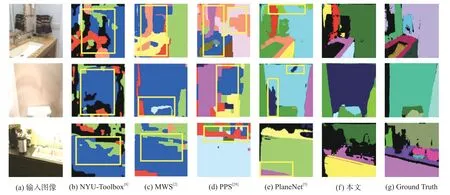
图7 平面分割比较
在图8中展示了本文算法和其他方法关于平面分割精度的定量比较。其中,像素召回率指的是正确预测的平面重叠区域中像素所占的百分比;平面召回率指的是正确预测真实平面的百分比。如果所预测的平面与真实平面的交并比(IOU)大于0.5,并且重叠区域的平均深度差值小于设定的深度阈值(从0到0.6 m,增量为0.05 m),那么我们就认为该平面被成功的预测出来了。从曲线图8可以看出来:当使用预测的深度图作为输入时(计算预测的像素点到预测深度图间的距离),本文算法的平面召回率和像素召回率都是最优的;即使使用真实深度图作为输入时(计算预测的像素点到真实深度图间的距离),本文算法的平面召回率和像素召回率也比PPS和PlaneNet好。
4.2 深度预测精度
在本节中,本文算法和其他方法进行了深度图的定量分析比较。为了得到深度图,除了使用全局预测任务外,同时为了避免其他分支的影响,我们还单独使用深度预测分支(深度)进行深度图的估计,同时使用Eigen[29]等人的方法改变训练损失。深度预测精度在NYUV2数据集上的测试结果如表1所示。Eigen-VGG是一个用于法线和深度预测的卷积神经网络;SURGE[22]是一个可进行平面优化的深度预测网络;FCRN[30]是目前最好的单图像深度预测网络之一。由于NYUV2深度图极具噪声且真实平面的提取极具有挑战性且质量不佳,故本文仅使用深度预测分支及深度损失来微调网络。
表1展示了4.2节提到的各种指标的定量结果。表格第2至第6列是各种深度误差指标值(差值越小表明深度预测结果越好);表格第7至第9列的三个指标为深度精度指标(数值越大表明深度预测结果越好),它们表示预测深度值与真实深度值的差值小于设置阈值情况下的像素所占比例。从表中可看出来,当使用全局预测任务预测深度图时,和文献[5]相比各种深度误差指标和深度精度指标相当甚至不及;当仅使用深度预测分支(深度)进行深度估计时,各种深度误差指标和深度精度指标略有提高。
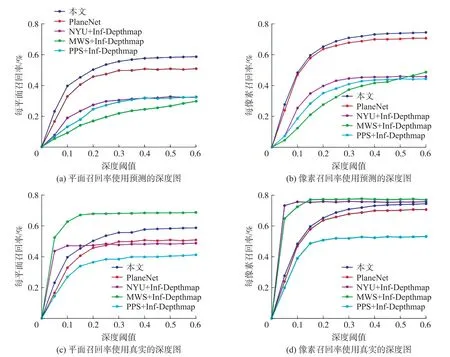
图8 平面分割精度比较
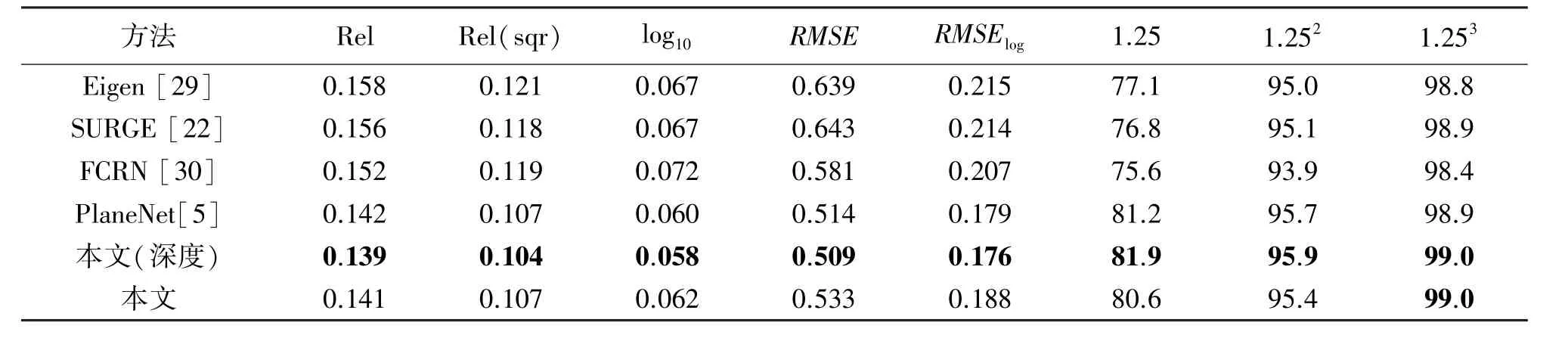
表1 NYUv2数据集深度精度比较
4.3 重建结果
图9展示了本文算法与使用深度残差网络的PlaneNet[5]各室内场景重建对比结果。PlaneNet使用固定的感受野,无法使用卷积核进行更大范围的采样、捕获丰富的空间语义信息,并且没有使用浅层高分辨率的特征;本文利用空洞卷积并设置不同空洞率增加卷积核的感受野,捕获更多空间语义信息,并融合多尺度特征。从图9中矩形框可以看出,本文的算法在边缘位置的重建效果(如框所示)要好于PlaneNet。

图9 重建结果对比
5 总结
本文提出了一种基于空洞卷积残差连接的和多尺度特征融合网络的分段平面三维重建算法。本文提出的算法可直接从单幅图像中预测出平面参数、深度图及分割掩模。由于本文是在静态室内场景下进行的三维重建,未来的一个重要方向是能够在室内和室外均进行动态场景的实时三维重建。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
软件(2020年3期)2020-04-20 00:56:34
计算机应用(2019年3期)2019-07-31 12:14:01
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
软件导刊(2016年9期)2016-11-07 22:22:57
光学精密工程(2016年6期)2016-11-07 09:07:56
腹腔镜外科杂志(2016年12期)2016-06-01 12:10:09
科技视界(2016年2期)2016-03-30 11:17:03
中国医疗美容(2015年1期)2015-07-12 10:05:59
