
深度学习和协同过滤的高校图书混合推荐算法研究
2021-06-16 16:43黄沁芳
电子技术与软件工程 2021年4期
黄沁芳
(集美大学诚毅学院 福建省厦门市 361021)
1 引言
当前随着互联网信息技术的快速发展,各大高校纷纷建立智慧图书馆来实现图书的信息化管理。为了满足高校学生对于图书馆服务的个性化需求,图书推荐算法也在日益改进和创新。推荐系统被认为是一种非常有效的信息过滤工具,通过分析用户的历史行为数据,为用户推荐个性化的内容[1]。协同过滤是推荐系统中应用最广泛的算法之一[2],但它存在数据稀疏性和冷启动问题。深度学习基于数据来进行特征学习,而卷积神经网络是其中的一种学习方法,它能从大量的输入输出数据中找出相应的映射关系。本文将卷积神经网络的内容推荐应用到推荐系统的协同过滤算法中,从而缓解数据稀疏性和冷启动的问题,提高推荐结果准确率。
2 深度学习
深度学习是神经网络发展的产物,神经网络是对人脑或一些生物神经网络特征的抽象和建模,能够从外界进行学习,并以生物类似的交互方式来适应外界环境[3]。深度学习分为监督学习和无监督学习。监督学习包含了多层感知机、卷积神经网络等学习模型;而无监督学习包含了自动编码器、稀疏编码器和深度置信网等学习模型。
卷积神经网络是由多层的神经元构成,其网络结构主要包括输入层、卷积层、池化层、全连接层和输出层。实际上,卷积神经网络就是将大量输入的数据进行训练,从而学习到数据中的特征,找出输入数据和输出数据之间的映射关系。
3 协同过滤算法

图1:基于卷积神经和协同过滤的混合推荐算法

图2:卷积神经网络结构图
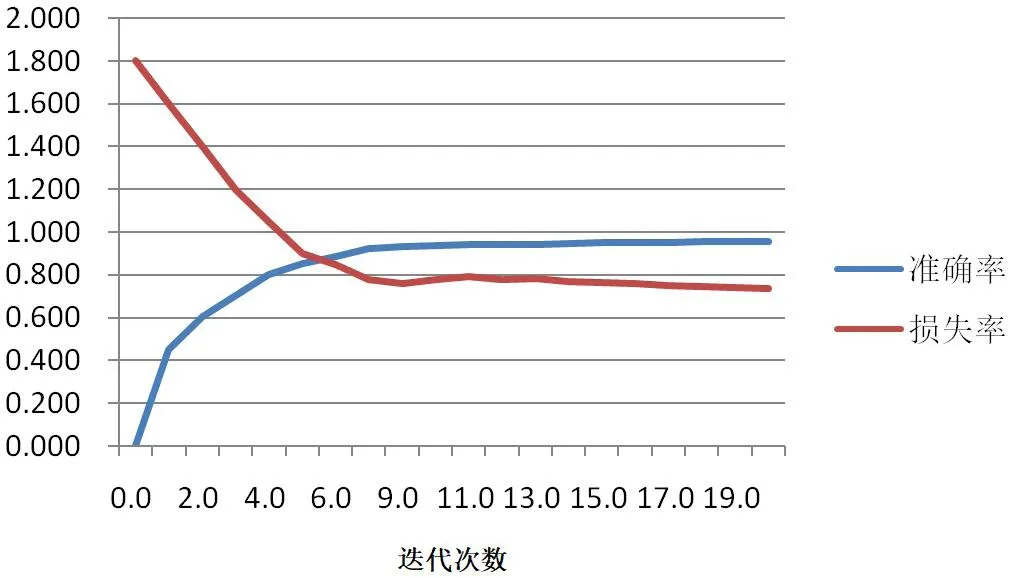
图3:卷积神经网络模型准确率和损失率

图4:推荐结果准确性对比图
推荐系统主要分为协同过滤推荐、基于内容推荐和混合推荐,其中协同过滤是目前使用最广泛的推荐算法之一。协同过滤算法是通过收集用户的历史记录来发现用户和物品之间的关联性,借此向用户提供可能感兴趣的推荐。它分为基于邻居的协同过滤和基于模型的协同过滤,基于邻居的协同过滤又分为基于用户协同过滤和基于项目协同过滤[4]。基于用户的协同过滤是通过收集用户历史行为或偏好数据生成用户-物品矩阵,利用相似度算法找到与当前用户有相似兴趣爱好的用户,将此用户喜好的物品推荐给当前用户。基于项目的协同过滤是通过收集偏好物品的相似性生成物品-用户矩阵,利用相似度算法找到用户喜欢的相似物品推荐给用户。在协同过滤算法中如果出现新用户或物品时,或者数据少比较稀疏时,很难收集到偏好信息找到相似用户或物品,导致无法生成推荐,这就存在冷启动和数据稀疏问题。
4 基于卷积神经和协同过滤的混合推荐算法
本文针对的是高校图书馆,用户以学生教师为主,采用基于用户的协同过滤算法。通过收集学生教师对图书的评分和评价行为构建读者-图书矩阵,寻找相似读者形成推荐结果。再将卷积神经网络训练模型所产生的推荐结果与协同过滤的推荐结果进行线性组合,形成更为准确的推荐列表,也从而解决了图书信息少,用户评价少的冷启动和数据稀疏问题。具体步骤如图1 所示。
(1)收集相关信息包括用户图书搜索记录和图书信息例如书名、作者、出版社、简介等,作为输入数据进行模型训练,得出用户最可能感兴趣的三类图书,生成推荐列表1。
(2)提取用户的图书评分信息以及评论信息,形成用户-图书矩阵,通过计算相似度寻找相似用户,根据相似用户的喜爱产生推荐列表2。
(3)将推荐列表1 和推荐列表2 进行内容线性组合,生成最后的推荐列表。
5 算法实现
5.1 卷积神经网络的构建
通过访问图书信息数据库和读者搜索记录数据库,提取所需要数据,经过数据清洗和过滤,利用jieba 分词工具进行分词,生成词向量训练所需要的图书语料库。使用Word2Vec 中Skip-Gram 模型对图书语料库进行训练生成词向量。Word2Vec 是基于中文语料库的,可以处理自然语言。生成的词向量作为卷积神经网络的输入数据,进行下一步的训练。
本文的卷积神经网络模型主要由输入层、卷积层、池化层、全连接层和输出层构成,如图2 所示。
输入层:此层中输入的数据是中文词语的词向量,图中的k 表示300 维,n 为100。一行词向量为一个词语,将n 个词语则构成一个句子,可表示为:x1:n=x1⊕x2⊕x3⊕…⊕xn,其中xi∈Tk表示第i个词语的K 维的词向量。
卷积层:此层作用是提取词向量的特征,输入数据大小为100×300。卷积结果为di,即di=f(v·xi:i+h-1+a),其中f 为非线性函数,本文采用的是ReLU 函数;v∈Thk为卷积核,v 表示宽度为k维高度维h 个单词的向量;a 表示函数的截距。在本文的模型中卷积核有三种,大小分别是3×300、4×300,5×300,其中n-h+1 的值为96,所以最后输出大小为96*128。
池化层:此层是实现降维和过滤噪声。它将卷积层的输出结果集合D 的最大值取出来,组成输出结果。池化窗口大小也分为三种3、4 和5;输入数据大小是96×128,对应的输出数据大小分别为32×128、24×128 和19×128。池化层输出结果将会进入下一个卷积层进行特征提前。

表1:读者-图书评分矩阵R(m,n)
融合层:本文模型中卷积核和池化窗口都有三种,融合层将组合这三种结果,进行线性连接。输入数据分别是三个128 维向量,则输出数据则变为一个384 维向量。
全连接层:来自融合层的384 维向量,在全连接层最终输出结果维度为53。此层使用了Dropout 函数,取值为0.2,用来来实现80%神经元的局部连接,忽略掉20%的神经元数据,这样在某种程度上避免了过拟合。同时还使用Softmax函数,来实现多分类功能。
本文以Tensorflow 和Keras 作为框架搭建卷积神经网络进行模型训练,采用交叉熵损失函数。模型的准确率和损失率如图3 所示。从图中可以看出在刚开始训练时损失值很大,当迭代次数达到一定数量时逐渐趋向平稳;而准确率在开始时不断上升然后随着迭代次数趋向平稳。在词向量维度300,迭代次数为20 时准确率可以到达95.2%。因此可以将此卷积神经网络模型应用到推荐系统中。
5.2 协同过滤算法的实现
从学校图书馆的读者借阅信息数据库获取读者对图书的评分和评价信息,并对数据进行清洗,将活跃程度低的用户以及无效的数据过滤掉,最后构建成读者-图书矩阵。假设有m 个读者,读者集合为U={U1,U2,U3,…,Um};n 种图书,图书集合为B={B1,B2,B3,…, Bn};m 个读者n 种图书构成的m×n 阶的读者-图书评分矩阵R(m,n),如表1 所示。
要寻找相似读者,需要计算相似度,常用的方法有皮尔逊相关系数、欧几里得距离法和余弦值法。本文采用的是皮尔逊相关系数。假设读者u 与读者v 的相似度sim(u,v),Iuv表示读者u 与读者v 对图书评分的交集。相似度结果区间在[0,1],结果值越大,表示越相似。
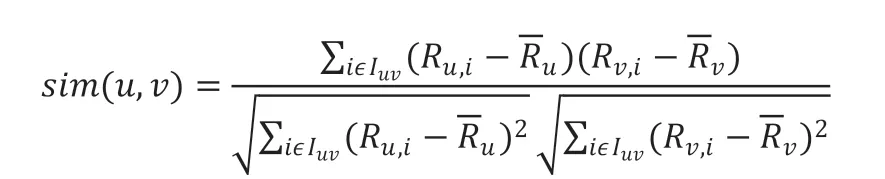
通过读者的相似度,计算出读者u 对图书i 的偏好预测值Pu,i,KNNp表示与读者u 最相似的k 个读者的集合,分别表示读者u 和v 对所有图书的平均评分。

将预测值Pu,i由大到小排列,生成Top-N 推荐列表,将其中的N 本图书推荐给读者。评估推荐系统的准确性指标最常用的是准确率(Precision)、召回率(Recall)和F1 值,假设R(u)是训练集中得出的推荐列表,T(u)是测试集中得出的推荐列表,相应公式如下:

本文在实验中将评分矩阵数据分两部分,作为训练集数据占80%,测试集数据占20%。实验结果验证推荐的准确率为3.54%,召回率为2.83%,F1 值为3.04%。
5.3 卷积神经网络与协同过滤组合
以用户图书搜索记录和图书信息作为输入数据,通过卷积神经网络进行模型训练,得出用户最可能感兴趣的三类图书,生成最热门评分最高的推荐列表,与协同过滤算法生成的Top-N 推荐列表,进行内容线性组合生成最后的推荐列表。计算最终的推荐结果准确率为5.10%,召回率为4.65%,F1 值为4.93%,相对于协同过滤而言,推荐结果准确性明显提高了如图4 所示。
通过实验对比,相对于单一的协同过滤推荐系统,卷积神经网络和协同过滤相结合的混合推荐系统推荐效果更好。
4 结语
为了实现从大量图书资源中向高校学生推荐他们感兴趣的图书,本文提出了将卷积神经网络的推荐结果和协同过滤算法的推荐结果向结合,组成一种混合推荐系统,从而提高了推荐的准确率,并缓解了冷启动和数据稀疏问题。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(中年级)(2021年4期)2021-04-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中学生数理化·中考版(2015年10期)2015-09-10
华东师范大学学报(自然科学版)(2014年3期)2014-03-11
