
融合多元评论信息的用户情感分类方法
2021-06-15 01:08徐红艳黄法欣
辽宁大学学报(自然科学版) 2021年2期
徐红艳,黄法欣,冯 勇
(辽宁大学 信息学院,辽宁 沈阳 110036)
0 引言
互联网3.0时代的来临,越来越多的公众参与到网络交互中,极大地推动了网络商业化进程.2019年阿里巴巴双十一消费数据调查显示[1],订单峰值为54.4万笔/秒、当天成交额为2 684亿元,比去年同期增长了42%.由此可见,电子商务已为公众所接受,电商平台已经成为人们消费的主要途径.电子商务中商品和服务的评论对人们消费决策的影响已经引起学界和业界的关注,但现有研究成果由于很少考虑评论中存在虚假评论、默认好评、随意打分等因素,难以准确获得用户的真实情感分类,导致研究成果在实际环境下的应用效果欠佳.
通过对用户评论信息进行分析可知,用户评论中包含原始评论、原始上传图片、追加评论以及追加上传图片,在对用户评论进行情感分类时综合考虑这四类多元评论信息可增强情感分类的准确性.为了减少虚假评论等因素对用户情感分类准确性的干扰,需要对用户多元评论中的隐含信息进行分析和挖掘.通常,发布虚假评论的用户往往不会进行追加评论,因此发布追加评论的用户评论内容可信度较高.同时,引入体现评论延续性的追加评论可以反应出用户在不同时刻对商品的情感特征;另外,发布虚假评论的用户在电商平台下单购买商品后不会收到所购买的商品,因此评论中上传的图片通常为店铺主页的商品推广图片或其他商品图片.本文通过融合多元评论信息减少虚假评论等因素对用户的情感分类结果的影响,为交叉销售、个性化推荐等应用的开展提供支撑.
综上,本文提出了一种融合多元评论信息的用户情感分类方法(user emotion classification method integrating multiple comment information,UECMIMCI),该方法首先对爬取数据进行预处理,使用图片分类技术对用户评论中上传的图片进行分类,选出上传图片为拍摄商品图片的用户,利用这些用户的多元评论信息来重构图文数据集;其次,采用文本分割技术将原始评论、追加评论按照评论内容进行分割重构;最终,将经过预处理后的图文数据集分多通道输入到卷积神经网络中,得到融合多元评论信息的用户情感分类结果.实验证明,所提方法能够对评论中的用户情感进行准确分类,具有良好的应用前景.
1 相关工作
1.1 虚假评论的识别
商品评论是获取用户情感分类的一个重要依据,但是虚假评论严重影响着用户情感分类结果的真实性.虽然研究人员研究并提出了很多检测虚假评论方法及评论检测技术,但这些方法大多通过分析语言结构和提取虚假特征的方式识别虚假评论.如房有丽等[2]提出融合评分-评价一致性和多维时间序列的虚假评论识别方法,构建虚假评论识别分类器.提高虚假评论的识别效果.郝玫等[3]提出基于特征观点对的语义匹配算法,实现特征观点对的语义匹配及提取,对产品可信评论进行筛选和分析.目前,主流的虚假评论识别方法只针对用户上传多元评论信息中的评论文本在特征提取和语义分析等方面分析与优化,未考虑利用用户评论中其他的多元评论信息,尤其是未充分利用用户上传的图片的类型去识别和过滤疑似虚假评论.
因此,本文提出利用多元评论信息中的上传图片进行虚假评论的识别.将评论上传图片分为两类,第一类是用户收到商品后拍摄的商品图片,上传该类图片时用户发布的评论文本在本文定义为真实评论;第二类为上传店铺主页商品的推广图片以及其它商品图片,上传该类图片时用户所发布的评论为虚假评论.通过图片二分类的方法过滤第二类图片,确保输入到情感分类器中的图文评论数据集有较高的真实性.
图片分类方法在医学、商品销售等多领域得到广泛应用,常使用机器学习和深度学习的方法对图像特征进行提取并完成分类.Yu等[4]提出基于新型深度双流网络进行图像分类方法,先通过多实例网络和全局优先级网络分别获取输入图像的局部和全局特征流,后将双流特征融合,利用该特征完成图像的分类.Li等[5]提出一种基于注意力机制的多标签图像分类方法,利用LSTM网络生成图像的多个标签,再使用注意力机制提取图片特征,从而取得良好的图片分类性能.Su等[6]提出结合生成对抗网络的半监督学习方案,提高图像分类的准确性.本文通过卷积神经网络对用户上传图片进行分类,根据分类结果在评论图文数据集中保留上传拍摄商品图片的用户多元评论信息,进而提高用户情感分类性能.
1.2 文本分割
文本分割在信息检索、摘要生成、问答系统、信息抽取等领域发挥着重要作用,通过文本分割算法将长文本分割成细粒度的短文本更易于挖掘文本的内容信息.王忠义等[7]提出基于知识元的中文文本分割方法,该方法先对知识元的类型及其描述规则进行分析,然后将所有的知识元和知识元之间的衔接句视为一个类,最后使用分割算法对该类进行文本层级分割.王鹏等[8]提出了文本的分层分割方法,该方法通过计算文本内容的间隔相似度,实现文本的分割.本文为了解决情感分类过程中存在的缺乏评论延续性的问题引入了追加评论,使用文本分割技术对用户在不同时期的评论内容按照“商品-客服-物流”的评论顺序进行分割重构,确保提取的原始评论和追加评论的情感特征按照上述三方面进行精准的融合,来获取用户更多的情感特征信息,提高用户情感分类的准确性.
1.3 用户情感分类
用户评论的情感分类研究是近几年来学术和业界以及应用开发领域的研究热点与前沿领域之一.情感分类的应用可以将意见分类为不同的情感,并总体上评估公众的情绪,其分类结果对于研究商品口碑、进行商品推荐都具有重要的价值[9-11].随着深度学习的兴起,在进行用户情感分类时使用深度学习方法可以融合多元评论信息,提高用户情感分类的准确性.在众多深度学习方法中,双通道卷积神经网络方法得到较为广泛的应用,如周锦峰等[12]提出基于fcmpCNN模型的网络文本情感多分类标注方法,该方法在池化的过程中使用全卷积—多池化单元的堆叠,充分提取文本语义;李平等[13]提出的基于双通道卷积神经网络的文本情感分析方法,融合字向量进行细粒度情感分析,充分挖掘出评论文本的情感信息;Liu等[14]提出基于MCCNN模型进行评论情感分类,融合文本的拼音、字符以及单词使用三通道CNN进行情感分类.赵乐等[15]提出一种结合词性特征、语法特征等,提取名词、动词、形容词、副词等特征,然后运用软投票机制,结合随机梯度下降算法、随机森林、神经网络等算法,对已获取评论文本进行极性二分类.Zhang等[16]提出的双通道卷积记忆神经网络模型,将评论文本的词向量和特征向量输入双通道卷积神经网络中,进行情感分类.综上分析,多通道CNN模型通过不同通道分析用户不同方面的情感表述,进而得到较为准确的用户情感特征向量用于情感分类.
2 融合多元评论信息的用户情感分类
考虑到评论中存在的虚假评论、默认好评等因素影响对用户真实情感的分类,本文提出融合多元评论信息的用户情感分类方法.首先,使用图片分类和文本分割技术对图文数据集进行预处理,过滤掉虚假评论重构图文数据集;其次,将处理后的数据集划分为训练集和测试集,使用训练集对UECMIMCI用户情感分类模型进行训练;最终通过测试集对模型进行验证,得到正确的分类结果.融合多元评论信息的用户情感分类方法的框架如图1所示.
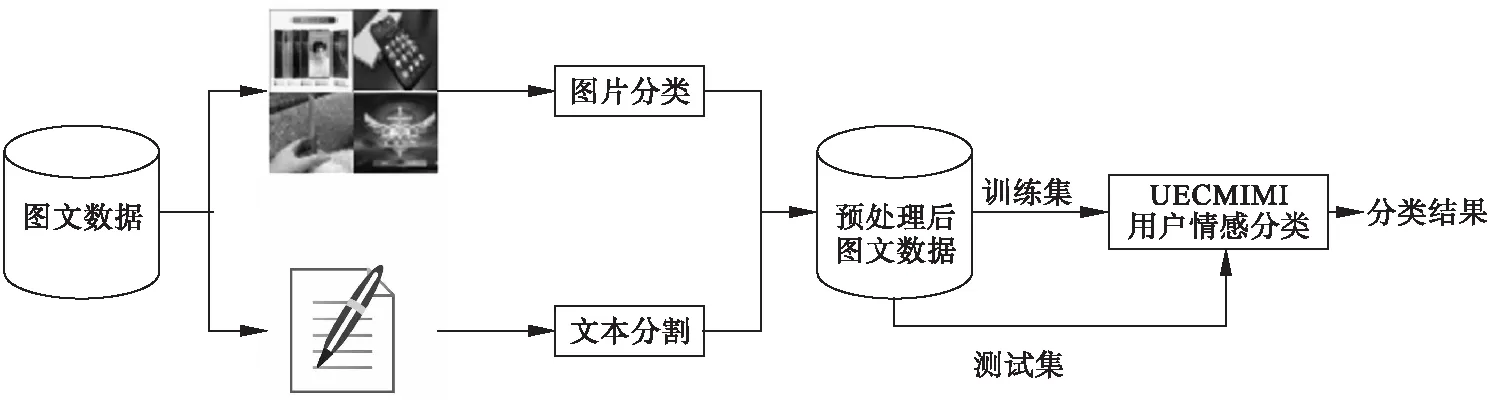
图1 融合多元评论信息的用户情感分类方法框架
下面对所提方法的核心环节:图片分类、文本分割、UECMIMCI用户情感分类模型的构建加以详述.
2.1 图片分类
如今的电商评论中主要存在两个突出的问题:一是由“刷单”引起的虚假评论现象十分常见;二是用户随意打分、随意评价评价造成评论数据的不准确,严重影响用户情感的准确分类.这两个问题的共同特点为:用户上传的图片或者是店铺主页商品的推广图片,或者是其他商品图片.根据这一特点本文提出结合用户上传图片识别虚假评论的方法,对评论信息中的图片使用卷积神经网络进行二分类:第一类是用户收到购买商品后拍摄的真实图片;第二类是虚假图片,包括店铺主页商品的推广图片及其他商品图片.按照分类结果保留上传第一类图片的用户多元评论信息,以此来降低虚假评论、随意评论现象对用户情感分类结果的影响,提高用户情感分类的准确性.
本文采用卷积神经网络(CNN)对上传图片进行二分类,其中卷积核尺寸设置为3×3、4×4、5×5,利用不同规格的卷积核对上一层图片进行卷积操作,分别提取用户收到商品后拍摄上传的商品图片、店铺主页商品的推广图片和其他商品图片的多方面特征,实现图片分类器的训练;从未过滤虚假评论的图文数据集中抽取图片数据输入到图片分类器中,按照提取到的图片特征信息进行图片的分类,识别出真实图片和虚假图片;筛选出上传虚假图片的用户,将该用户的多元评论信息从的图文数据集中删除,使用余下真实评论用户的多元评论信息重构图文数据集,为用户情感分类做准备.图片分类模型如图2所示.

图2 图片分类模型
输入层:将爬取到的评论上传图片、店铺主页商品的推广图片以及与其他商品图片作为训练集输入到CNN图片分类模型中.
卷积层:按照不同尺寸的卷积核对图片进行特征的提取,如公式(1)所示.
(1)
其中,l代表所在层次;k代表卷积核;Mj为输入的感受野;B为偏置项;f为激活函数.
采样层:采样层可降低网络的空间分辨率,消除偏移和图像扭曲,实现位移不变性[17],如公式(2)所示.
(2)
其中,p代表采样层;B代表权值系数.
输出层:将上一层的特征向量进行全连接,如公式(3)所示.
(3)
分类器:采用softmax分类器对输出层得到的图像特征进行二分类,如公式(4)所示.
(4)
其中,W为卷积核;b为偏置项.
根据图片分类结果对抓取到的11 762个用户的评论数据集进行预处理,通过过滤上传无关图片以及主页图片的用户评论进行图文数据集的重构,降低评论中虚假评论和随意评论对用户情感分类结果的影响,最终得到10 819个用户上传的有效评论.过滤无关图片对用户情感分类结果的影响如表1所示.

表1 图片分类对UECMIMCI模型情感分类准确性的影响
通过调整UECMIMCI模型中图片和文本特征提取时卷积核的尺寸从多角度、多维度证明,使用过滤后的图文评论数据集可提高UECMIMCI模型在用户情感分类的准确率,可提升2%以上.
2.2 文本分割
在一条评论中往往包含了用户对商品的不同方面的评价,主要有对商品的体验、店家服务的态度、运输物流的评价.对用户评论文本进行分割时,首先,将评论文本内容按照标点进行分割,且从中选出对上述三方面的中性评价;其次,对分割的评论文本进行增删操作.若评论文本中不完全包含这三方面的评价,用第一步选出的中性评价将每条评论按照这三方面补充完整.若评论内容中存在对其他方面的评价信息,删去与这三方面无关的评论内容;最后,将处理后的评论文本按照“商品-客服-物流”的评论顺序对评论文本重新组合,重构评论文本示例如表2所示.

表2 重构评论文本示例
2.3 UECMIMCI用户情感分类模型构建
构建UECMIMCI用户情感分类模型,将经过预处理的用户图文评论数据集,利用Word2vec工具[18]训练评论文本,获取词向量,作为训练集输入到模型中.其中卷积层的大小是3、4、5,池化层采用最大池化突出最明显的情感特征,同时在模型中添加dropout层,作用是在训练过程中随机关闭一些神经元,避免出现过拟合现象.为了将原始评论与追加评论、原始上传图片与追加上传图片的情感特征信息进行合并,本文提出了特征融合层,在该层中按各部分对情感分类的贡献度将特征向量进行合并.最后,将情感向量传递给Softmax分类器进行分类,得到评论对应的情感类别.
本文提出的情感分类模型最终将多元评论信息分为好、中、差三类情感极性,UECMIMCI用户情感分类模型如图3所示.
输入层:将经过预处理的原始评论、原始上传图片、追加评论、追加上传图片输入到UECMIMCI用户情感分类模型的四个通道中.
卷积层:将输入这四个通道的向量矩阵分别使用三个卷积核进行局部特征提取,每个卷积核的卷积操作,如公式(5)所示.
ci=relu(W*xi:i+h-1+b)
(5)
其中,W为卷积核;b为偏置项,x为与卷积核大小相同的评论文本部分.
池化层(采样层):目的是提取经卷积核得到的特征矩阵中情感表达最强烈的向量,在实验中采用max-pool的方法,如公式(6)所示.
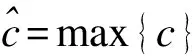
(6)
全连接层:将上一层的结果进行拼接,得到最终的特征向量,如公式(7)所示.
(7)
特征融合层:按照评论对情感分类贡献程度,将特征向量进行合并,如公式(8)所示.
x=αx1+βx2
(8)
其中,α、β之和为1,x1代表与原始评论相关的信息,x2代表与追加评论相关的信息.α、β取不同值对UECMIMCI用户情感分类模型准确率的影响如表3所示.

图3 用户情感分类模型
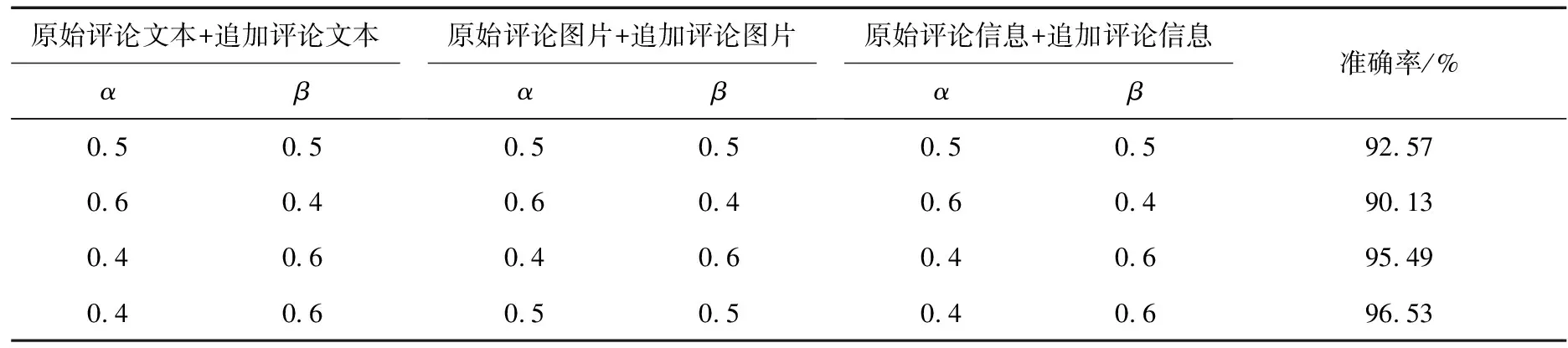
表3 参数与UECMIMCI用户情感分类准确率的关系
大量实验验证,原始评论文本与追加评论文本特征融合时,α、β值分别为0.4、0.6;原始上传图片与追加上传图片进行特征融合时,α、β值分别为0.5、0.5;原始评论信息和追加评论信息进行特征融合时,α、β分别为0.4、0.6,实验效果最佳.
情感分类层:在图片分类完成后得到训练情感分类器的图文数据集,通过最小负对数似然函数调整参数.通过模型去计算融合用户原始评论、原始上传图片、追加评论、追加上传图片的情感特征向量,利用参数集合为θ的模型去计算该情感特征向量到每一个情感倾向的得分Si.通过Softmax分类器来进行最终的情感极性的划分,后对划分结果取对数用随机梯度下降使似然函数最大化优化分类器,计算过程如公式(9)~(10)所示.
(9)
J(θ)=∑logp(yi|pi;θ)
(10)
其中,pi为UECMIMCI情感分类模型的预测类别,yi为实际类别.
3 融合多元评论信息的用户情感分类
3.1 实验数据集和实验环境
实验中采用Python爬虫程序从京东网站爬取发表有关华为手机评论的用户并将其上传的所有评论信息作为数据集.共抓取11 762个用户评论信息经预处理和手工标注后得到的手机评论数据集,如表4所示.
本文利用基于Python语言的Tensorflow深度学习框架完成实验.Tensorflow支持多种主流神经网络模型,包括 CNN、LSTM 等,本文具体实验环境为:操作系统为Windows 10,CPU为Inter(R)Core(TM)i5-4460 CPU @ 3.20 GHz.
3.2 词向量训练和模型参数设定
本文利用Python然语言处理库提供的结巴分词技术进行句子分词处理.使用Google提供的开源词向量训练工具Word2vec中的skip-gram进行词向量的训练,其训练参数[18]设置如表5所示.
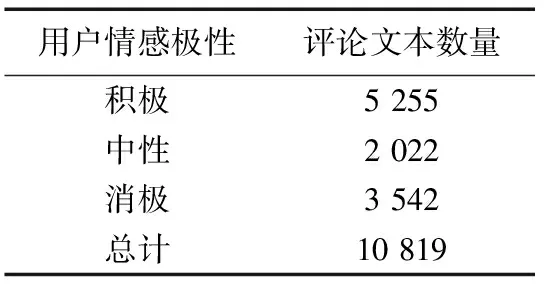
表4 实验数据集

表5 word2vec训练模型
在数据集预处理中使用CNN对上传图片进行分类以识别虚假评论,为了获得最佳的分类效果,实验中选取不同尺寸的卷积核进行实验对比,卷积核尺寸对图片分类的准确率及分类器训练耗时的影响如表6所示.
从表6中可见,卷积核尺寸越小图片分类准确率越高,但分类器训练耗时也越长.综合考虑训练耗时及分类准确率两个因素,本文选择3*3,4*4,5*5的卷积核尺寸进行图片分类器的训练及UECMIMCI情感分类模型中图片特征的提取.本文在提取评论文本情感特征时使用多通道卷积核对输入向量进行卷积操作,文本卷积核维数参照陈珂等[19]提出的模型参数.而对于文本卷积核尺寸与迭代次数的选择是通过实验分析得出最佳卷积核尺寸和迭代次数.实验结果如表7、图4所示.

表6 图片卷积核尺寸与图片分类准确性及分类器训练耗时的关系

表7 文本卷积核尺寸与UECMIMCI模型确性及训练耗时的关系
实验表明,综合模型运行的时间和准确率考虑卷积核尺寸选为3,4,5时,可使用户情感分类效果最佳.
为了使UECMIMCI模型在用户情感分类时达到最好的分类效果,在实验过程中设置UECMIMCI模型的最大迭代次数为300次.如图4所示,在UECMIMCI模型迭代到250次时,该模型对用户情感分类的准确率值最佳为96.53%,在250次之后,模型的分类准确率略有下降,基本稳定在96.41%.因此本文选择250次作为UECMIMCI模型迭代次数.

图4 UECMIMCI模型迭代次数和准确率的关系

图5 UECMIMCI分类方法多次实验误差范围情况
综合考虑上述所有因素进行多组实验,比较实验的误差范围,结果如图5所示.图5中实验1-4对表7中选择的文本卷积核尺寸做对比试验,结果显示在文本卷积核维度是3、4、5时,实验效果最佳.实验5-6,按照图片卷积核尺寸为3×3、4×4、5×5和文本卷积核尺寸为3、4、5以及迭代次数为250次条件下,重复实验,准确率基本一致,UECMIMCI模型稳定可行有实际应用价值.
综上分析,基于多元信息的多通道卷积神经网络模型超参数设置,如表8所示.

表8 模型参数
3.3 实验结果分析
将本文提出的情感分类方法UECMIMCI与fcmpCNN方法[12]、DCCNN方法[13]、MCCNN方法[14]、LSCNN方法[16]以及双通道卷积记忆神经网络模型[20]在同一数据集上进行对比实验,其中,对比实验采用原始评论作为数据集进行实验,下面给出对比方法简要描述:fcmpCNN模型采用全卷积—多池化单元的堆叠提取文本的语义,对网络文本进行情感多分类;DCCNN模型通过融合字向量的双通道卷积神经网络对文本进行情感分类;MCCNN模型结合文本的拼音、字符及单词使用三通道CNN融合多种表征,进行文本情感分类;LSCNN模型将文本情感矩阵以及词向量输入到双通道CNN中进行分类;双通道CNN-LSTM模型将词向量和情感词典输入双通道卷积神经网络中,通过长短期记忆网络结合上下文进行文本情感的分类.
对比实验采用准确率、精确率、召回率和F值作为评价指标.计算公式如公式(11)-(14)所示.
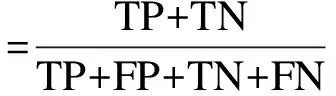
(11)

(12)

(13)
其中,TP为预测正确的好评数、FP为预测错误的好评数、P表示预测为好评的评论数、FP将除好评外的其他类别分为其他类别、TN表示将好评误分为其他类别.

(14)
UECMIMCI模型及对比模型的准确率如表9所示.

表9 对比试验结果
从上述图表可以看出,UECMIMCI用户情感分类方法的准确率为96.53%,高于其他对比方法.其中,DCCNN和MCCNN取得较低的准确率,其原因是仅对文本按照不同的方式进行分词和输入,忽略了虚假评论的存在对分类结果的影响.fcmpCNN模型通过修改神经网络的结构来增强文本的语义进行情感分类,没有充分利用评论中其他信息达到提高用户情感分类准确率的目的.LSCNN和双通道CNN-LSTM模型准确率达到91%和92%,由于二者均利用情感词典来增强评论的情感特征表示,没有考虑到追加评论的内容有更强的情感色彩、更能反映出用户的真实情感.而本文提出的UECMIMCI用户情感分类方法中先过滤掉虚假评论,后融合原始评论、原始追加评论、追加评论和追加上传图片的特征,使得UECMIMCI方法对用户情感分类性能明显高于对比方法.
4 实验分析
为了解决评论中存在虚假评论、随意评论等评论乱象对用户情感分类的影响、提高用户情感分类的准确率,本文提出了一种融合多元评论信息的用户情感分类方法.该方法为了保证评论分类的准确性、减少虚假评论的干扰,分别对评论图片分类、评论文本分割进行预处理操作,构建过滤掉虚假评论的图文数据集;之后将预处理后的图文数据集分别输入到原始评论、原始上传图片、追加评论和追加上传图片这四条通道中进行卷积、池化提取图文特征,最终将四条通道特征进行融合来得到最优质的特征信息进行情感分类.经实验验证UECMIMCI用户情感分类方法的准确率高于其他对比方法,取得了较好的分类效果.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
云南教育·小学教师(2022年4期)2022-05-17
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
艺术评论(2020年3期)2020-02-06
福建基础教育研究(2019年3期)2019-05-28
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
