
基于BERT-CRF模型的中文事件检测方法研究
2021-06-11 10:16田梓函
计算机工程与应用 2021年11期
田梓函,李 欣
中国人民公安大学 信息网络安全学院,北京100038
近年来,随着网络的持续普及,技术的不断发展,使用网络的用户越来越多,网络中的信息量随着用户频繁的交互行为的增加而增加,互联网成为传播大量信息的新媒介,由于信息多数是非结构化的,且一个领域的信息散布在浩瀚的信息海洋中,致使网络中的信息很难处理,因此快速从大量信息中提取有价值的信息显得越来越重要。许多信息一般是以事件的形式存在,事件指的是由特定关键词触发的、包含一个或多个参与者参与的、特定类型的事情,事件抽取技术是从纯文本中提取人们关心的事件信息,并以结构化的形式展现出来[1],是构建特定领域的事件库以及建立知识图谱的基础。事件抽取分为两个步骤,事件检测和元素抽取,事件检测指从一段文本中提取可以标志事件发生的触发词,包括事件触发词识别与事件触发词分类两部分。元素抽取主要针对一句话中与触发词相关的元素进行抽取和角色匹配。本文的重点是针对事件检测部分。
事件检测中的触发词是指直接引起事件发生的词语,一般触发词的词性为动词,也可能是表示动作或状态的名词。事件检测任务面临着许多挑战,一是一句话中不仅只有一个事件,有多个事件就会有多个事件触发词。例如,在句子1中有两个事件触发词,分别是“离”和“暗杀”,并且是两种不同的子事件类型“Transport”和“Attack”。
句子1:根据警方消息来源,法官与其子在上午交通高峰时间离家时,遭到暗杀。
二是由于中文没有自然分隔符,词语的边界不明确,存在触发词可能是词语的特定部分,也可能包含多个词语,造成触发词不匹配的问题。例如,在句子2中,“砍伤”是一个词语,但“砍”和“伤”分别是不同的触发词类型,“砍”属于“Attack”事件类型,“伤”属于“Injure”事件类型;在句子3中,“生命”和“危险”虽然是两个词组,但他们合并属于“Injure”事件类型。在ACE中文数据集中,触发词不匹配占据了所有触发词的14.61%。
句子2:其中一人因为滑到被歹徒砍伤背部。
句子3:目前3个人仍有生命危险。
本文的工作主要体现在三个方面,提出一种将预训练模型BERT(Bidirectional Encoder Representation from Transformers)[2]与条件随机场(Conditional Random Field,CRF)[3]相结合的中文事件触发词检测模型;引入基于词的BIO标注机制来解决中文事件检测中触发词的识别与分类问题;通过实验结果的比较体现本文提出方法的优越性。
1 相关工作
事件抽取任务与实体抽取、关系抽取一样,是信息抽取的关键子任务之一,也是当前自然语言处理的研究发展方向之一,本文将事件检测的方法分成三个部分:基于模式匹配的事件检测、基于机器学习的事件检测和基于神经网络的事件检测。
基于模式匹配的方法是利用恰当的匹配算法,在一段文本中找寻符合预定义模式的事件。Kim等[4]利用WordNet语义数据库与模式获取相结合的方法进行事件抽取。Grishman等[5]提出基于模式匹配和分类器的事件抽取系统AceJet。姜吉发[6]提出一种针对飞行事故领域的IEPAM系统。但是,基于模式匹配的方法需要针对不同的特定需求制定相应的规则和模板,可移植性差,所以该方法更适合于特定领域。
基于机器学习的方法一般被看成多分类问题,利用最大熵、隐马尔科夫、支持向量机等分类器提取特征。Hai等[7]在事件检测任务中使用最大熵分类器。Ahn[1]在事件检测任务使用了MegaM分类器和TiMBL分类器。Saha等[8]在生物事件检测中使用支持向量机分类器。虽然传统机器学习避免了预先制定许多的规则,并将事件检测问题看作序列标注问题,但其不可以自主学习新的特征,使得模型的泛化能力较差。
近年来,深度学习已成为最新研究趋势之一,在各个领域都有应用。Nguyen等[9]和Chen等[10]提出将卷积神经网络(CNN)应用到事件检测任务中,前者使用CNN自动地从预先训练好的词嵌入、位置嵌入和实体类型嵌入中学习多种特征表示,从而减少错误传播。后者提出动态多池卷积神经网络模型(DMCNN),该模型可自动地提取词语级特征和句子级特征。Nguyen等[11]提出一种基于离散短语的卷积神经网络模型对事件识别与分类。Nguyen等[12]新颖地引入句子结构信息,在事件检测任务中利用图卷积神经网络提取结构特征。而对于中文的事件检测,Zeng等[13]利用双向长短期记忆(Long Short Term Memory,LSTM)网络与CRF相结合提取句子级特征,利用卷积神经网络提取上下文特征,将两种特征结合对中文事件检测。Lin等[14]提出NPNs模型,将字与词混合表示模型,包含触发词识别与触发词分类两个功能模块,将每个词看作是一个触发词块,并结合了Chen等[10]提出的DMCNN网络结构。Ding等[15]提出TLNN模型,模型中引用了外部知识库HowNet获取字与词的所有语义信息,并使用了lattice LSTM框架将所有信息动态合并。Xu等[16]提出将语义、句法依存等特征信息结合到词向量中,再将词向量输入到BiLSTM中捕获句子级信息。
随着对自然语言处理领域的研究更加深入,Word2Vec词向量训练工具已不能满足学者们的需求。Peters等[17]提出了ELMo模型,ELMo基本结构是一个双层的Bi-LSTM,采用正向编码器和反向编码器的双向拼接方式提取特征信息,使上下文无关的静态向量变为上下文相关的动态向量。Radford等[18]提出了GPT模型,与ELMo模型的不同点是GPT采用Transformer而不是RNN作为特征提取器,但GPT只利用了单向编码。BERT[2]相对于GPT的创新在于使用了Transformer的Self-attention机制实现双向编码,并且构造了更加通用的输入层和输出层,只需修改模型下游任务,就可以应用在多种任务中,丰富了GPT原有的任务种类,包括句子间关系判断、句子分类任务、阅读理解任务和序列标注任务。
2 基于BERT-CRF的事件检测模型
2.1 BERT预训练模型
BERT的输入表示是三种Embedding的直接相加,其中,Token Embeddings表示为词向量,对中文语句处理时,可以是针对字的向量,也可以是针对词的向量,本文使用的是字向量,Position Embeddings表示位置信息,由于基于自注意力机制的模型不能感知每个字之间的位置关系,因此需要使用Position Embeddings给每个字标记序列顺序信息,Segment Embeddings是用于针对多个句子间的分割向量,本文的实验中只在每个句子的开头和结尾加上[CLS]与[SEP]。
BERT是采用基于微调的多层双向Transformer作为编码器,在Encoder和Decoder部分都使用了Transformer,可以让一句话中的每个字无论方向前后或距离远近,直接和句子中的任何一个字进行编码,每个字都能融合字左右两边的信息。Encoder的每个模块包括多头自注意力机制(multi-head self-attention)和全连接前馈网络,multi-head attention意味着对多个attention计算,每一个attention关注句子中的不同信息,再将所有的attention信息拼接在一起,如下式所示:

而self-attention是对Q、K、V三个向量计算,将Encoder中输入的每个字向量在整个输入序列中进行点积与加权求和得到在此位置的输出结果,如下式所示:

Decoder的每个模块都比Encoder多了一个Encoder-Decoder attention,虽然也是利用multi-head attention机制,但它与self-attention的不同是它的输入分别是Decoder的输入和Encoder的输出。
由于self-attention的注意力只放在每个词的自身,为了训练双向Transformer模型,需要随机掩盖一定比例的词语,让模型用正确的词预测被掩盖的词,在训练的过程中,与CBOW将每一个词都预测一遍不同,而是随机选择数据集中15%的原始词语,这样就可以融合到上下文相关的信息。在掩盖的词中有80%会直接用MASK代替,10%用另外一个词代替,剩下10%不变还使用原词。
2.2 CRF模型
对于本文的序列标注问题,在预测阶段通常采用softmax分类器对标签进行预测,但softmax分类器在序列标注任务中没有考虑标签与标签间存在的依赖关系,而条件随机场CRF可以使用对数线性模型来表示整个特征序列的联合概率,能更好地预测序列标注中的标签。
假定句子长度为n,句子序列为X=(x1,x2,…,xn),对应的预测标签序列为Y=(y1,y2,…,yn),预测序列最终的总分数为:
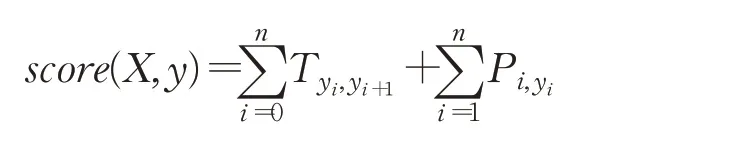
其中,T表示标签间的转移分数,Pi,yi表示每个字到对应yi标签的分数。
由于预测序列有多种可能性,其中只有一种是最正确的,应对所有可能序列做全局归一化,产生原始序列到预测序列的概率:

2.3 BERT-CRF模型
传统的神经网络模型需要用NLP工具对语料进行预处理,例如分词,并以分割后的词语作为输入向量,会造成误差的累积与传递,预测的标签不准确。为了避免这种误差传递,本实验将触发词抽取与检测看作字级别的标注任务,采用BIO序列标注规则,其中,“B”表示为事件触发词的起始,“I”表示为事件触发词的中间,“O”表示为非事件触发词。模型的输入包括字向量、位置向量和分割向量,但由于输入中只有一个句子,所以分割向量为0。输出为每个字的标注结果。BERTCRF模型是在BERT模型后添加一层CRF线性层,模型如图1所示。

图1 基于BERT与CRF相结合的事件检测模型
本文实验中使用的是Google发布的针对中文语料训练好的BERT Base版本,该模型采用12层的Transformer,隐藏大小为768,自注意力的multi-head为12,模型的所有参数为1.1×108。
3 实验
3.1 数据集
本文的实验数据是采用ACE2005中的中文数据集,ACE2005定义了8种事件类型,每种事件类型还包含不同的子事件类型,共有33种子事件类型,如表1所示。为了与前人的实验方法相比较,本文选择了64篇文章作为验证集,64篇文章作为测试集,余下的569篇作为训练集。
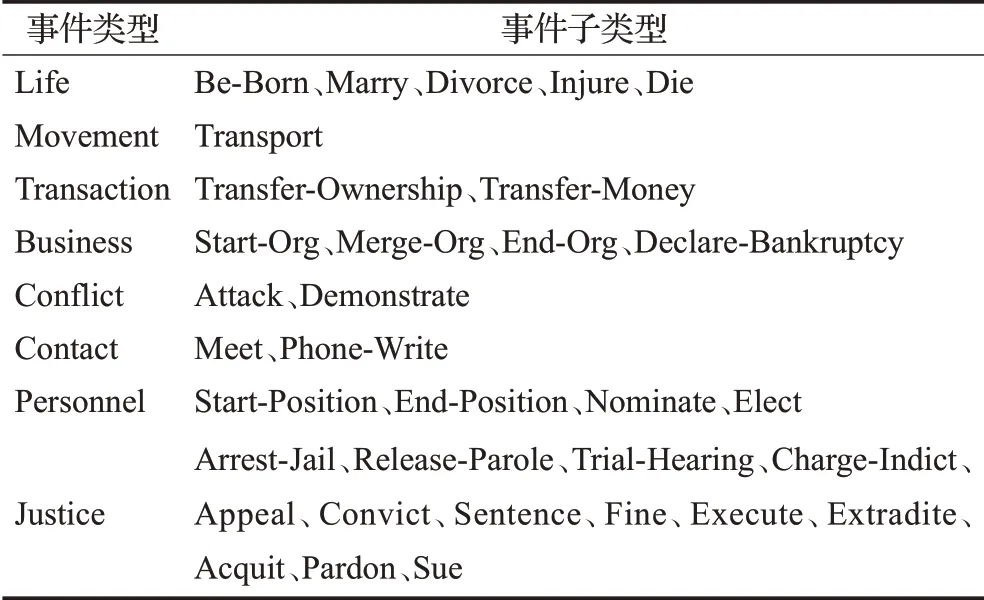
表1 ACE2005中的事件类型与事件子类型
3.2 实验环境与参数设置
实验环境是采用Tensorflow对模型进行搭建。实验中的参数设置为:输入序列长度seq_length为256,训练集的batch_size为8,训练学习率learning rate为2×10−5。
3.3 实验结果与分析
本文使用事件检测的精确度(P)、召回率(R)和F值(F-score)来评估模型的性能:

将本文提出的BERT-CRF模型与BiLSTM-CRF、NPNs、TLNN等多种模型进行比较,实验结果如表2所示。
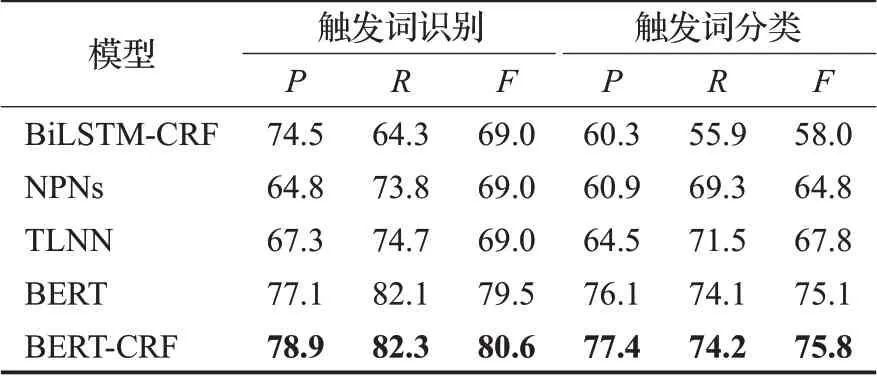
表2 不同事件检测模型性能比较%
从表2中可以看出,本文提出的模型在ACE2005数据集上得到了相对不错的结果,通过BERT动态提取字的词向量特征,并直接利用BIO机制进行标注,避免了使用NLP工具造成错误传播的可能,使得在触发词识别和触发词分类任务中都有很好的效果。
NPN模型虽然新颖地提出以字为中心的触发词块,但将候选触发词的范围规定在一个固定的大小,不灵活且不能将所有的可能性包含,并且会有触发词重叠的问题,TLNN模型只是将信息从前往后单方向地整合。BiLSTM-CRF模型是经典的处理序列标注问题的神经网络模型,模型中使用的是静态的词向量,相较于本文提出的预训练模型中的动态词向量,不能获得每个字所有的有效信息。本文提出的模型可以将一句话中的触发词尽可能提取出来,并且模型是双向的编码,可以很好地利用从前往后和从后至前的信息,使模型在触发词识别和分类的任务中检测更准确。
针对触发词不匹配问题,用BERT连接softmax与本文提出的模型进行比较,从表2可以看到本文提出的模型在各项指标比较中略有优势,表3用例子比较触发词问题的解决效果。例1中针对一句话中多个触发词,仅使用BERT的没有识别出“育”字为“Be-born”事件类别,例2中针对触发词匹配问题,“杀死”在中文中虽然是一个词组,但“杀”和“死”指代两个不同的事件,应分别对应“Attack”和“Die”这两种事件类型。

表3 不同模型的触发词分类结果
4 结束语
本文提出了一种基于预训练模型的中文事件检测模型,针对中文语言的特定问题,将句中的每个字作为输入向量,不需要可能造成错误传递的NLP工具,利用BERT预训练模型抽取特征,条件随机场CRF进行多标签分类。实验结果显示,与现有的中文事件检测方法进行比较,本文提出的模型在ACE2005中文数据集上实验效果较好。在接下来的工作中,将模型与现实需求相结合,针对社会安全领域事件触发词的特定问题,优化事件检测模型,为建立社会安全相关的知识图谱提供技术支撑。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
海峡科技与产业(2016年3期)2016-05-17
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
