
基于双向注意力机制的多模态情感分类方法
2021-06-11 10:16黄宏展蒙祖强
计算机工程与应用 2021年11期
黄宏展,蒙祖强
广西大学 计算机与电子信息学院,南宁530004
在日常生活里,人们所接触的信息通常有以下几种形式:视频、声音、图片、文字等。在许多场合,从信息的感知到认知的理解过程可能需要综合多种形式的信息才能完成。多种形式信息所构成的数据,也叫做多模态数据。使用多模态数据可以从给定学习任务所考虑的每种模态中提取互补信息,与仅使用单个模态相比,可以产生更丰富的表示[1]。
情感分析领域里,目前较为常见的是针对文本数据进行自然语言处理[2-3],挖掘文字背后蕴藏的感情色彩。也有部分学者将图像处理技术运用于情感分析[4-5]。但是,目前综合文本和图像进行多模态情感分析的研究相对比较少。在有的场合下,仅通过单一模态挖掘数据背后的情感特征往往容易产生歧义,需要借助其他模态信息的辅助才能够更好地表达情绪倾向。例如,从图1中(a)和(b)容易观察出积极和消极的情感倾向,然而在(c)中只观察图片会误以为描绘美丽的森林,结合文本中的“abandoned”“fallen”“shattered”等情感词汇才可以得到原创者表达的消极倾向。图片与文本数据的融合解释,不但可以加强情感的传达,也能避免单模态下情感分析的片面性。

图1 社交媒体上的图文数据
在实际生活中,部分人工智能应用场景需要涉及到多种模态输入。学习更好的特征是多模态学习中的核心内容之一,已有工作[6]表明通过深度学习提取到的特征往往能够取得较好的效果。Jônatas等[7]使用基于帧的时序卷积(convolution-through-time)深度模型学习预告片中图像和音频信息并融合网络结果,以执行多标签类型分类,准确识别出多种电影类型。该方法基于视频帧的图像和音频数据均具有时序结构,然而有些情况下需要考虑异构的多模态数据。例如Oramas等[8]通过深度学习架构提取音轨、文本评论以及封面图片特征,进行音乐流派分类,实验结果表明,组合不同模态特征分类性能优于单模态特征。Bae等[9]在面对花卉数据分类任务时,提出改进的多模态卷积(m-CNN),利用多种CNN分别学习图像信息和文本信息并集成表示有效识别花卉的类别,证明了语言描述信息可以作为图像特征的有效补充。对学习到不同模态特征,如何进一步利用它们之间的关联信息,发挥其互补特性则需要合适的模态融合方式。
进行不同模态特征的融合同时也是多模态任务的关键内容。模态表征融合阶段可以分为早期特征级别和后期决策级别融合两个阶段。深度学习中较为常见的是提取模型中层输出作为特征进行特征级融合,基本融合方法主要有拼接[10-11]、矩阵加法[12-13]、哈达玛积[14]等方法。
迄今为止在多模态情感分析领域仍然存在诸多难点。首先不同模态数据对同一信息的表达形式不同,数据的结构和属性各异使得机器可能无法识别具有相关含义的表征。其次,不同模态数据之间的互补特质难以充分利用。数据的底层特征往往具有不同的维度和分布,模态间的特征融合无法有效结合数据的关联信息。此外,即使网络上存在大量的多模态数据,关于多模态情感分类的公开数据集依然较少。针对目前多模态情感分类任务的难点,本文进行图像和文本模态的自注意力深层语义特征提取,并构建了双向注意力机制的多模态情感分类模型,引入不同模态特征相互交互,加强关键性特征判别,充分发挥模态间的互补信息。此外结合了特征融合和决策融合策略,进一步提升情感分类任务的表现。实验结果基于两个不同性质的真实社交媒体数据集,在不同实验指标下验证了所提方法的有效性和鲁棒性。
1 相关工作
1.1 多模态情感分类介绍
随着社交媒体呈现信息的多模态化,多模态情感分类吸引了研究人员的注意,许多研究工作开始尝试在一种模态数据的基础上引入其他模态数据进行情感识别。情感分类任务通常包括数据预处理、特征提取、特征学习和分类四个模块。多模态的分类任务是在特征学习模块中进行共享表征的学习,主要有联合表示和协同表示两种方式[15]。其通用框架如图2所示。联合表示方式是将不同模态特征映射到同一向量空间。例如Zadeh等[16]提出一种端到端融合模型,通过张量积的形式将不同模态特征映射于同一向量空间表示,在单模态、双模态以及三模态上的情感分类均得到了较好的效果,证明了该方法可以有效地捕获模态内和模态间相关关系。但是张量积的方式在面对较大维度特征时融合得到的特征维度将呈平方级甚至立方级增长。协同表示是将不同模态特征映射到各自向量子空间,映射后的表征之间存在相互联系。He等[17]提出视觉文本双流模型学习各自的潜在语义表示,合并预测结果得到较好的分类精度。然而这种合并未能充分挖掘图像文本中的重要元素的相关性。本文通过双向注意力机制学习在本模态空间下关于另一模态的表征,在不增加特征维度的情况下发挥模态之间的互补特征以加强情感分类性能。

图2 多模态分类任务的通用框架
决策级别融合方法通过组合多个分类器的结果,生成最终决策。Cao等[18]利用后期融合策略将单模态情感预测结果通过线性插值的方法组合,增强了情感分析结果。然而仅仅通过决策的融合会导致特征层面上关联性的忽视[19]。本文结合特征融合和决策融合方法,进一步提升了情感识别的准确率。
1.2 注意力机制概述
注意力机制(Attention)参考了人类视觉注意力的特点,对有效区域分配更多关注,获取更多任务相关细节,并抑制其他无关区域。在图像视觉、文本处理等领域中,注意力对关键特征的作用主要体现在权重的分配上。
假设注意力层接受一个输入Source,Source可以看成由键Key与值Value组成,给定一个任务相关的元素Query,通过计算Query与Key之间的相似性,归一化得到Value关于Key的权重系数,通过对Value加权求和得到最终注意力的数值。其计算公式如下:

自注意力机制是注意力机制的特殊情况,其中Key=Value=Query,即使得输入的某一部分均与输入自身每一部分进行注意力计算,学习内部关联,增强有效区域。
2 基于注意力机制的多模态深度融合模型
针对多模态情感分类提出的注意力混合模型,本章首先分别介绍文本和图像模态的自注意力网络模型,然后提出聚焦于通道级别图像特征和单词级别文本特征的双向注意力模型。最后介绍分类器与计算最终情感结果的后期融合方法。多模态注意力混合模型总体结构如图3所示。
2.1 文本自注意力模型(T-SA)
在自然语言处理任务中,对一段文字的处理也可以看成对一段文字序列的处理。一串文字的输入在时间上具有前后关联的特质,模型接受新词的输入后产生新的状态,循环神经网络(Recurrent Neural Network,RNN)通过前后状态的传输,能够很好地处理序列数据的问题。本文选择RNN的变种LSTM网络作为学习文本特征的模型。相较于普通RNN,LSTM具有长时记忆功能,适合更长的序列相关问题。由于情感分类任务常常与特定情感词汇具有更强的相关度,增强相关词汇在分类任务的作用,有助于提升最终结果[20]。因此,文本将LSTM的每一步输出联结为文本的表示特征,通过自注意力机制,使模型更关注于关键步,也就是关注关键词汇的输出,以此学习到情感色彩更富的文本表征。
令DEC=[B1,B2,…,Bn],表示由n条文本记录构成的数据集。为了学习文本记录的词向量特征,本文使用Google发布的预训练BERT模型[21]对文本数据进行词嵌入,得到文本Bi的词向量,表示为:,其中l是固定的一段文本词嵌入的向量数量。
为了进一步学习文本的上下文特征,词向量作为LSTM的输入,并输出每一步的结果。假定t时刻LSMT的输入为,上一时刻输出为ht-1,状态为Ct-1。计算过程如下:
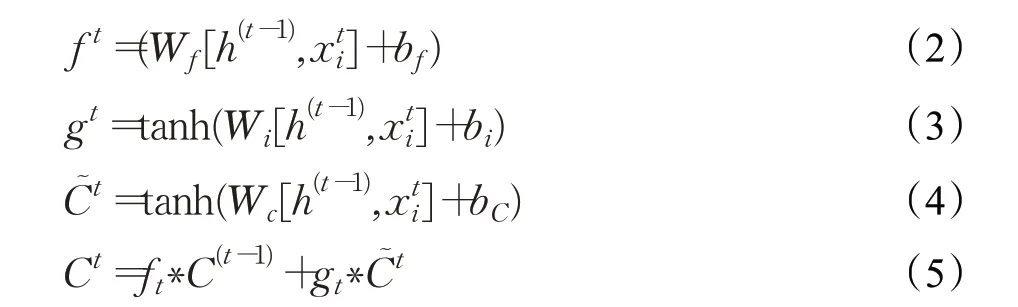
此时的输出为:

其中,Wf、Wi、Wc、Wo是待训练的参数。最终得到的文本Bi上下文表示为。显然,Si∈Rl×d,也是LSTM在t时刻的输出。σ是sigmoid激活函数,tanh是双曲正切激活函数。在t时刻下LSTM模型内部计算过程如图4所示。
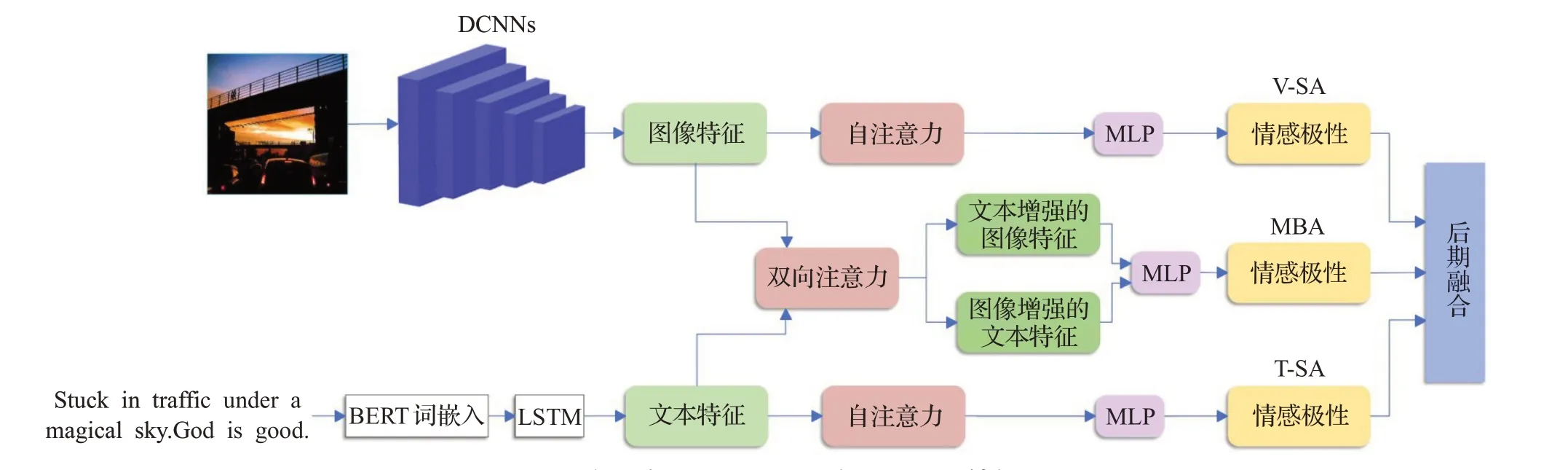
图3 多模态双向注意力融合模型总体结构
LSTM模型可以输出关于上下文表示的文本特征Si,但是并未体现每个输入的词对结果的不同的影响。为了使模型更聚焦于判别性特征,本文使用自注意力机制(Self-Attention),将文本表示Si设为注意力机制的Key,Value,Query,即特征中的每个状态输出通过线性变换与该特征的所有输出在式(1)的基础上进行注意力计算,学习句子内部依赖关系。其中相似性计算过程如下:
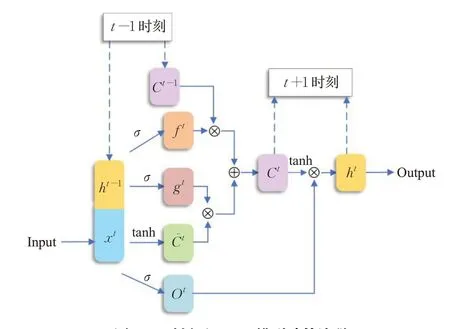
图4 t时刻下LSTM模型计算流程
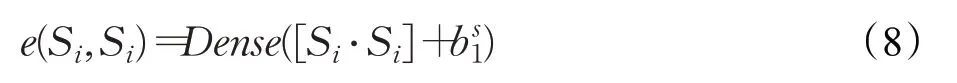
其中bs1是偏置。此处借鉴了Luong等[22]设计的注意力对齐函数向量点积∙的思想,使得Si中每个向量也就是每个状态的输出均与Si中所有向量即所有状态输出进行特征匹配。通过Dense层线性变换以及softmax函数的归一化,得到Si本身在不同状态下也就是的注意力权重αi,最终的加权求和即是自注意力下LSTM模型的输出结果。计算公式如下:

其中,d是每个状态输出的长度,输出的结果∈Rl。
2.2 图像自注意力模型(V-SA)
与文本模态数据具有时序性不同,图像特征在空间上的分布更加离散。在类激活映射中,有效特征的分布相对位置并不一定具有规律性,甚至不一定在相同子空间中。在颜色、纹理、形状等不同的特征子空间中皆可能存在有效的局部特征。关键性特征的选择对情感分类的结果具有较大影响。利用卷积核和窗口滑动,卷积神经网络可以实现权值参数共享,能够有效捕捉图像的局部特性,经常被用于图像处理任务[23]。VGG16是深度卷积神经网络的经典模型,它的预训练模型已经被广泛应用在图像处理的表征学习过程中[10,24],并取得良好的效果。在本文中,利用VGG16模型的泛化能力结合迁移学习的微调方法,冻结模型的原有卷积层参数并外接一层卷积层,用于实现图像特征提取。原有卷积层在Imagenet数据集上经过充足的训练可以有效识别图像主体,而外接卷积层的微调使其提取的特征更符合文本任务目标。再利用自注意力机制,使模型更多聚焦于关键通道上的情感特征,提升模型对图像情感类别的判断能力。
数据集中的图像数据可以记为IMG=[I1,I2,…,In],其中n表示图像的数量。VGG16模型的结构由5个卷积块和3个全连接层组成共有16层[10]。本文提取图像数据Ii在VGG16的第5个卷积模块的结果,输入外接卷积层,如图5所示。在不同通道中学习情感的语义特征。通过增加卷积层在预训练VGG16模型的基础上学习情感相关特征,Vi∈Rc×r,其中c是图像特征的通道数,r是子特征长度。
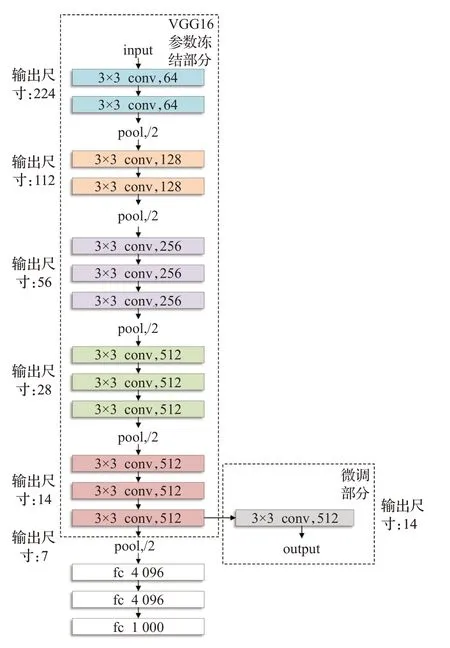
图5 调整后的VGG16模型
每个通道使用各自的卷积核学习特定视角下的子特征,本文使用自注意力机制,将Key=Value=Query均设置为图像表示Vi,将每个通道的子特征与所有通道子特征在式(1)的基础上进行注意力计算,增大情感相关通道特征的辨别性,得到关于Vi通道间的注意力权重βi。与式(8)相同,利用点积方法计算当前通道与其他通道的相似性。
最终对通道特征加权增加判别性子特征对结果的作用。计算公式如下:
其中,r是每个通道子特征长度,输出特征。
2.3 图文双向注意力模型(BAM)
自注意力机制通过特征自身的注意力权重分配,可以使得模型聚焦于判别性特征,然而这种聚焦会使得模型更关注于特定事物而忽视了总体的情感表达。此外针对同一事物,其不同模态特征表示之间一般存在某种内在关联。显然,有效利用这种关联可以提高多模态数据分类的效果。在多模态情感分类方面,目前已有了一些工作[25-26],但这些工作几乎未涉及到挖掘模态之间的互补性、相似性等关联特征。通常来说,图像能够提供更丰富的视觉元素而缺乏对元素主观联系上的体现,而文本能够描述事物之间逻辑联系,但是无法考虑事物的细节。
基于此,本文提出针对跨模态情感分类的双向注意力网络,利用一种模态的高层语义特征,参与另一种模态下注意力特征的生成,此外由于高层语义特征被赋予了较多的情感特性,因此另一种模态的注意力权重将增强情感特征在分类中的作用。与上述相同,本文将LSTM模型学习到的特征作为文本特征,调整后的VGG16学习到的特征作为图像特征。
在文本的图像注意力特征计算过程中,由于图像高层语义特征在实验中与文本特征首先进行注意力计算,将其初始化为,Qi∈Rk,Qi是一组一维张量,k是Qi的长度。此处,注意力机制中Query、Value均为Si,Key为Qi。由于图像高层语义特征与文本特征Si维数不同,首先需要复制d次Qi,组成新的矩阵,然后跟文本表示Si在每个状态输出的级别上拼接,为文本信息扩增图像内容。借助线性变换计算每个状态LSTM输出关于图像高层语义的注意力权重,通过softmax函数进行归一化。计算过程如下:

其中:
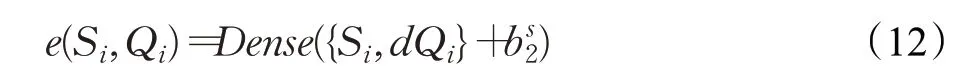
其中,Dense层激活函数为tanh函数,是偏置。{Si,dQi}表示Si与复制d次Qi拼接后的张量。
据产品负责人介绍,该平台包含设备管理、项目管理、分析统计、健康管理、配件销售、服务管理、还款管理等多个功能模块,适用于各类工程机械设备。该平台突破性地解决了多个工程机械行业管理痛点的同时帮助中联重科解决了“最后一公里”管理难题,并凭借其技术创新和模式创新跑在了行业前列,成为我国装备制造业有效集合大数据、物联网等前沿技术进行智能管理的第一梯队成员。
此时文本关于图像注意力特征的加权结果为:



其中:

其中,Dense层激活函数为tanh函数,是偏置,{Vi,cUi}表示Vi与复制c次Ui拼接后的张量。此时图像关于文本注意力特征的加权结果为:


其中,WQ、bQ分别是文本高层语义线性变换的参数与偏置,语义特征Qi∈Rk,这里σ是sigmoid函数作为线性变换激活函数。最终得到了文本增强的图像特征Qi,和图像增强的文本特征Ui。双向注意力网络与单向(单模态)自注意力网络对比如图6所示。

图6 双向注意力模型与单向自注意力模型的结构
2.4 情感分类器
本文为图文双向注意力特征{Qi,Ui},这里的{Qi,Ui}表示图像与文本高层特征拼接后的共享表征,以及单模态图像自注意力特征和文本自注意力特征搭建了相同的分类器结构,由两个隐藏层与z个节点的输出层构成的多层感知器(MLP),z是类别数。输入是对应模态下得到的注意力特征Fi。分类过程如下:

两个隐藏层均使用线性整流relu激活函数,W1和W2分别是两个隐藏层的参数,输出结果由softmax作为激活函数的输出层得到模型的预测结果Yi。
不同模态以及跨模态决策过程是相对独立的,因此本文通过后期融合,为三个决策结果赋予不同的决策分值,形成最终情感决策D。

其中,ω、μ是衡量决策重要程度的决策分值,分别是文本自注意力模型、图像自注意力模型、图文双向注意力模型(BAM)的预测结果。假定算法达到指定迭代次数停止训练,多模态注意力混合模型计算过程如算法1所示。
算法1多模态注意力混合模型情感分类方法
输入:训练集(B,I,Y),其中Y是情感倾向标签、文本自注意力模型预测结果YT、图像自注意力模型预测结果YV。
输出:图文双向注意力神经网络权重WM和偏置bM。以及图文神经网络各自的决策分值ω、μ。
①随机初始化所有网络权重和偏置。
②定义图像高层语义特征向量Q并进行0初始化。
③以词嵌入特征B作为文本部分输入,经过LSTM模块学习文本特征S。
④以VGG16模型提取图像数据I作为图像部分输入,经过卷积层模块学习图像表示V。
⑤将文本特征S与图像高层语义特征Q进行注意力计算(如式(11)),得到加权后的特征。
⑥经由全连接层进一步更新文本高层语义特征U(如式(14))。
⑦将图像特征V与文本高层语义特征U进行注意力计算(如式(15)),得到加权后的特征。
⑧经由全连接层,更新图像高层语义特征向量Q(如式(18))。
⑨拼接融合Q、U,共享表征输入分类器,得到分类输出Y͂M。
⑩根据输出Y͂M与标签Y计算分类结果交叉熵损失值。
⑪如果未达停止条件,则使用梯度更新算法学习神经网络权重WM和偏置bM,并转③,否则转⑫。
⑫根据文本与图像分类模型预测结果YT、YV以及多模态模型预测结果Y͂M,使用网格搜索寻找最优的决策分值ω、μ(见如式(20))。
3 实验
为了证明所提出方法的有效性,本文在单模态分析、多模态融合方法以及不平衡类别的数据集等方面,做了一系列实验。本章详细说明了实验的相关设置,介绍了针对多模态情感分类使用的数据集,并展示了所提出方法在数据集上的实验结果。此外通过可视化的方式进一步分析模态之间的关联性。
3.1 实验设置
本文中的文本最大长度设为200,经过隐含层节点数为768的预训练BERT模型进行词嵌入后得到的文本特征为200×768。LSTM的隐含层节点数设置为512,并且保留每个状态的输出作为文本特征。图像在输入前全部缩放为224×224的尺寸,并保留三通道。黑白单通道图片则将该通道复制三次再组合成三通道特征。外接卷积层使用2×2卷积核,个数为512,卷积步长为1,并使用零填充补足长度使与输入相同。输出的图像特征为14×14×512双向注意力计算中,由于具体实现中图像语义特征晚于文本注意力计算,因此本文初始化了值为0的一个初始向量作为图像高层信息输入文本关于图像的注意力计算。
分类器中前后两个隐藏层的节点数分别是1 024和512。Flickr-M数据集下模型输出层有两个节点,Memotion数据集下的实验设置输出层有三个节点。本文针对二类分类问题选择二元交叉熵(binary crossentropy),三类分类问题选择分类交叉熵(categorical cross-entropy)作为损失函数,并使用Adam优化器进行训练解目标函数,初始学习率为0.000 1。后期融合策略的三个决策分值参数ω、μ,是在0到1区间以0.1为步长使用网格搜索技术进行确定。本文中的模型均在NVIDIA RTX 2080TI显卡上训练。
3.2 数据集介绍
(1)Flickr-M数据集。Flickr是雅虎旗下的一个图片托管与分享网站,在Flickr上可以通过检索文本寻找相关的图片。Borth等[27]介绍了一个包含了1 200个名词对(ANPs)以及其对应的情感值的视觉概念检测库。,本文通过Flickr提供的API接口在检索所用的1 200个名词对,每个名词对检索60张图片。同时获取每张图片对应的介绍,并去除单词数小于5或者大于100的文本和类似链接的无关文本,保留下与图片相关的文本介绍信息。本文将情感值为正数的检索词检索到的数据归属于积极类别,具有负数情感值的检索词检索到的数据归属于消极类别,最终保留了10 000张积极情感和10 000张消极情感的图片及其介绍。
(2)Memotion数据集。Memotion数据集[28]是SemEval-2020竞赛中的一个公开数据集。Memes样本数据是近几年流行的表情包文化,包含图像与对应文本。本数据集是主办方从社交平台中收集,包含6 992条图像-文本数据,并具有多方面的标注标签:幽默检测、嘲讽检测等。本文使用“总体情感”标签进行情感分类实验。由于部分标记数量过少,所以本文将“积极”与“非常积极”标签统称为积极,“消极”与“非常消极”统称为消极,“中立”标签保持不变。最终得到了4 160条积极情感样本,631条消极情感样本以及2 201条中性情感样本。
数据集Flickr-M有两类情感类别,分别为消极类和积极类,这两类的样本数量相同,属于平衡分类问题;数据集Memotion有三类情感类别,这三类的样本数分别为4 160、631和2 201,属于不平衡分类问题。也就是说,在实验中本文既使用了类别平衡的数据集,也使用了类别不平衡的数据集,以更好地验证所提出方法对不平衡分类问题的鲁棒性。表1展示了两个数据集的分布情况。

表1 实验所用数据集的分布情况
3.3 评价标准
本文中针对积极(P)与消极(N)情感二类分类实验结果的评价标准为准确率(Accuracy)、精确率(Precision)、召回率Recall、F1值(F1-score)[13]。其计算公式如下:

其中,T和F分别表示预测值等于标签值和预测值不等于标签值的情况。例如TP表示预测值和标签值均为积极的情况数量,FP表示预测值为积极而标签值为消极的情况数量。
针对积极(P)、消极(N)还有中性(M)情感三类分类,由于Memotion样本类别不平衡,本文使用权重平均(weight-averaging)的思想计算精确率(Precision)、召回率Recall和F1值(F1-score)三个指标。准确率(Accuracy)指标计算方式与上述相似。具体计算公式如下:
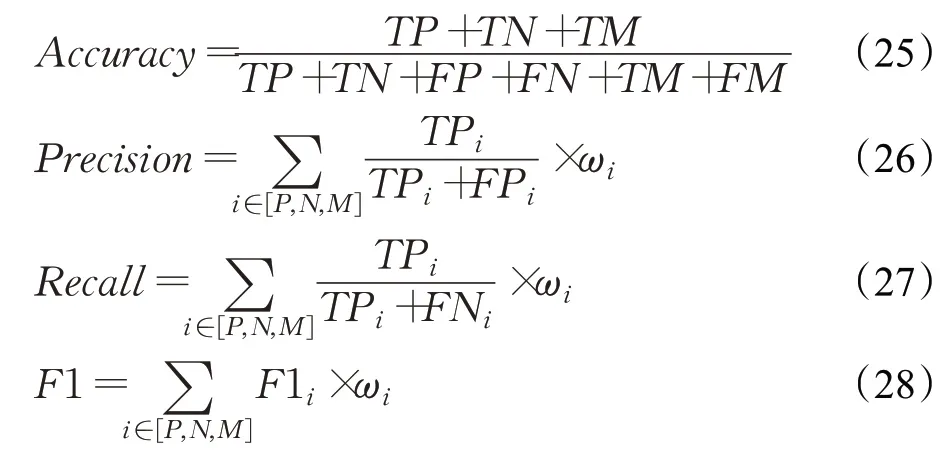
其中,精确率(Precision)、召回率Recall和F1值(F1-score)的计算结合了One-vs-all策略,假设将积极类别(P)视为正类,即i=P,则消极(N)和中性(M)类别的结果均被视为负类。ωP为积极类别样本占比。此时TPP表示为预测值和标签值均为积极情感的情况数量,FPP表示预测值为积极情况数量,而标签值为非积极情况的数量。F1P表示积极类别(P)视为正类时的F1值。
3.4 方法对比
本文结合单模态与多模态,注意力机制,不同特点的数据集和融合方法等多方面对所提出方法进行比较,还实现了最新的算法进行对比,以验证方法的有效性。这里将LSTM模型输出特征视为文本特征,VGG16模型外接卷积层的输出特征视为图像特征,设置了以下对比实验组:
(1)T:将文本特征进行情感分类。
(2)V:将图像特征进行情感分类。
(3)TV-Concat:将图像特征与文本特征拼接进行情感分类。
(4)T-SA:文本特征结合自注意力机制产生的判别性特征进行情感分类。
(5)V-SA:图像特征结合自注意力机制产生的判别性特征进行情感分类。
(6)DMAF:对两种单模态注意力加权特征拼接,结合后期融合进行情感分类[23]。
(7)MBAH:该模型是本文提出的总模型。
3.5 实验结果分析
表2和表3列出所提出模型与对比方法的实验结果。

表2 在数据集Flickr-M上的结果%

表3 在数据集Memotion上的结果%
从表2的结果,可以看出二类情感分类任务中,文本数据的分类效果相比图像数据更好,这是由于在结构上文本数据比图像数据更容易挖掘情感特征。并且,多模态融合方法结合两种模态关联信息使得情感分类结果表现优于单模态下的分类结果。注意力机制的引入也在一定程度上改善情感分类结果。通过表中标记的最优数据可以看出,本文所提出的MBAH模型总体上优于其他方法,相较单模态文本T和图像V模型的情感分类准确率分别提升了4.4个百分点和18.5个百分点。与最近的方法DMAF相比,准确率提升了1.2个百分点。这说明了本文的MBAH模型可以更好地进行情感分类任务。
从表3可以看出,多模态拼接融合方法对单模态下情感分类结果并没有显著提升,这是由于在更多类别下不同模态带有的情感信息随之更为复杂,对互补特征,关联特征的学习难度更大。注意力机制的引入在该数据中未能改善单模态分类结果。这是由于类别不平衡,使得情感特征的学习不充分,而本文所提出的MBAH模型总体在多数指标中均具有优势,证明了MBAH方法的鲁棒性。综上,结合二类与三类分类的性能对比,MBAH对单模态情感分类模型提升较为明显,并且超过了最近的DMAF方法,说明了MBAH模型在情感分类任务中的有效性。
3.6 双向注意力机制的类激活可视化(CAM)
为了进一步分析双向注意力机制对图文数据融合分类的影响,研究图像和文本模态在分类过程的相关属性,本文选取Flickr-M数据集中积极和消极情感图文数据各两条,分别对其在图像模态模型、文本模态模型,以及图文双向注意力模型上的类激活权重分布进行可视化对比。
其中对视觉图像的可视化,根据grad-CAM方法[29],利用模型的最后一层卷积结果反向传播求权重特征图,并与原图加权,得到视觉类激活热力图。具体表示为该区域颜色越接近红色,则该区域类激活权重越高。而对文本的可视化,本文通过单词的掩膜(mask),得到缺失该单词的一段文本,利用模型对该文本在当前类的输出值大小,判断该词的对分类结果的重要程度。具体表示为,重要程度越大,单词背景红色越深。可视化结果如图7所示。
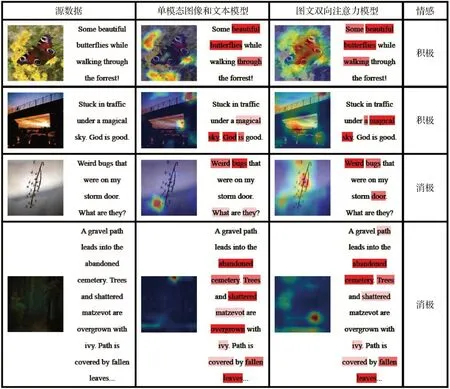
图7 图文双向注意力模型与单模态模型类激活图对比
可以观察出,图像注意力中对文本信息的引入使得图像模型的关注能力相对较强,也能更好地识别出文本所描述的事物。在文本注意力模块对图像信息的引入,使得模型摒弃了部分冗余无关信息,对图像主体的语义识别更为精确。据此可以证明图像与文本特征之间存在互补关系,可以有效地提升情感分类任务的表现。
4 结束语
本文提出了多模态双向注意力融合模型(MBAH),利用双向注意力机制学习图像与文本表征的关联信息,发挥多模态数据的互补特性,并混合早期融合和后期融合策略进一步提升了情感分类任务的结果。实验结果表明,本文所提出模型在类别平衡与类别不平衡数据集下均得到了更好的结果,证明了该模型的有效性与鲁棒性。在未来的工作中,本团队将计划更多地发掘社交网络上的其他可用信息,例如结合地理位置、社交关系等信息开展社交媒体数据的情感分析研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西科技大学学报(2016年1期)2016-06-22
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
