
向量分组聚集计算技术研究
2021-06-11 10:16张延松
计算机工程与应用 2021年11期
张 宇,张延松
1.国家卫星气象中心,北京100081 2.中国人民大学 信息学院,北京100872
数据库的OLAP查询主要由选择、投影、连接、分组、聚集等基本关系操作组成,其中分组聚集操作需要对海量的事实数据按指定的属性进行分组并执行聚集计算,是一个典型的数据密集型负载,也是一个对查询性能有较大影响的操作符,但OLAP查询性能并不是简单的关系操作符性能的叠加。通过实验测试发现,GPU数据库MapD在连接、分组聚集等主要操作符的性能上较其CPU版本具有显著的优势,但对于查询操作整体而言,即使在查询的数据量低于GPU本地内存的情况下,GPU版本的查询性能也要低于CPU版本。单纯提高关系操作符在GPU上的执行性能并不能最大化GPU数据库整体性能,需要以异构计算平台作为数据库新的硬件假设,优化设计面向异构计算平台的查询处理模型。通过定制面向异构计算平台特征的操作符优化查询算法以提高查询算法与硬件特性的适应性来提升查询性能。
本文以OLAP中重要的分组聚集操作为研究对象,将传统查询处理模型中位于查询树末端的分组聚集操作拆分为分组和聚集计算两个操作,分组操作采用“早分组(early grouping)”策略下推到表扫描阶段并与维表绑定,聚集计算操作采用“晚聚集(late aggregation)”策略保留在查询树末端并与事实表绑定。分组操作融合到连接操作中,通过向量索引实现分组与聚集计算之间的映射。向量索引聚集技术将数据密集型的聚集计算从计算密集型的连接操作中分离出来,将传统流水线查询处理模型中的计算密集型操作与数据密集型操作分离,同时建立了聚集计算性能测试基准,以便更加准确地评估聚集计算性能并匹配最佳的计算平台,实现在异构计算平台上负载的优化分配。
本文的贡献主要体现在以下几个方面:
(1)提出了基于私有向量的向量分组聚集算法和基于共享向量的向量分组聚集算法,设计了cache-conscious vector grouping benchmark,分析了算法性能与硬件参数之间的关联性,提出了算法优化选择策略。
(2)提出了将分组聚集操作从传统的流水线中分离的策略,通过向量聚集技术实现数据密集型负载与计算密集型负载的分离,为准确评估聚集计算代价和优化配置硬件资源提供必要的条件。
(3)对比了向量分组聚集算法与当前最优的内存数据库Hyper、GPU数据库MapD在不同分组势集参数下的向量分组聚集操作性能,揭示了算法的性能特征,通过量化的向量分组聚集基准性能测试提供硬件平台最优匹配策略。
1 相关工作
当前高性能数据库以内存数据库和基于硬件加速器的数据库(如GPU数据库)为代表,其性能的关键影响因素包括:关键算法性能、查询处理模型性能、异构平台协同计算性能等。
在传统的关系操作中,连接是查询性能重要的影响因素,近年研究热点问题之一是如何通过面向硬件特性的优化技术提高连接操作性能。NPO(No-partitioning hash join)[1]、PRO(Radix-partitioning hash join)[2]和sortmerge[3]等代表了当前最优的内存连接技术,其中以hardware-conscious的PRO算法性能最优。哈希连接是数据库中通用的算法,算法优化涉及较多的影响因素,加大了优化的难度[4]。Array Join[5]和AIR[6]是面向外键特性的定制化连接技术,针对OLAP特性的定制将哈希表简化为数组,将哈希探测操作优化为数组地址访问,通过面向负载与数据特征的定制优化进一步提高连接性能。
进一步地,连接优化技术从通用的多核CPU平台扩展到硬件加速器平台,利用专用硬件的高性能来加速连接操作。近年来一系列面向专用硬件加速器,如GPU[7-9]、Phi[10]、FPGA[11-12]以及多异构加速器的连接优化技术研究深入探索了如何基于硬件加速器的物理特性加速连接性能的优化技术。已有的研究主要聚焦于如何挖掘特定硬件加速器的计算特性,但对硬件加速器存储空间利用率在算法中的影响未赋予足够的权重。当前研究中性能最优的PRO分区哈希连接算法需要付出额外的数据分区存储和计算代价来换取较高的性能,这在CPU平台的内存模式下以内存足够大的默认假设为前提,但在硬件加速器平台,较小的内存容量破坏了这一基础假设,使其理想性能可支持的数据量大幅削减。在文献[13]中通过实验测试发现基于分区技术的PRO算法在Phi加速器上所支持的数据量是不分区技术的NPO算法的一半,而且性能低于面向OLAP定制的AIR算法。从硬件的发展趋势来看,硬件加速器内存与连接通道带宽性能始终存在较大差距,提高硬件加速器内存利用率、提高关键算法的数据局部性是两个重要的优化维度。连接技术的深入研究证明了在多核CPU和GPU等硬件加速器平台上的性能优化方法的效果,但这些研究通常面向独立的连接操作,对于OLAP场景下的多表星形连接以及整个查询执行计划中计算密集型的连接操作与数据密集型的分组聚集操作之间的优化匹配涉及较少,而连接技术的选择受分组聚集操作技术的影响较大,需要综合考虑性能、数据效率、数据局部性等影响因素。
当前的GPU连接优化技术研究关注于连接操作性能问题,而在关系数据库的Volcano查询处理模型中连接操作处于查询流水线中间,其性能受其他操作符影响较大。文献[14]指出在实际的TPC-H查询中单独连接操作执行时间占比仅为10%~15%,通过GPU仅加速连接操作对于提升整体查询处理性能的作用受到一定限制。
分组聚集是OLAP查询中另一个重要的操作符,主要的分组聚集方法包括排序分组聚集和哈希分组聚集两大类。排序分组聚集适合于非常大的分组势集并且需要将查询树前端的连接结果物化下来才能执行,不适合流水查询处理模型。哈希分组聚集适合OLAP查询中分组势集较小的场景,而且适应流水线查询模式,在数据库中应用较广。哈希聚集又分为基于共享哈希表、独立哈希表和分区哈希表三种方法[15],其优化技术原理也与哈希连接算法类似,不同之处在于分组聚集操作中的哈希分组表远小于哈希连接操作中的哈希表,而且分组聚集操作涉及的数据集远大于连接操作。除通用的哈希分组聚集算法之外,文献[6]中使用了面向OLAP负载定制化的多维数组聚集计算方法,通过将各维表上的分组属性映射为一个多维数组实现通过简单的多维数组代替哈希表的聚集计算。在Oracle内存数据库中使用的内存聚集IMA算法[16]也使用了类似的方法,通过Key Vector映射连接键值和分组编码,通过多维聚集器进行分组聚集计算。从算法实现技术来看,哈希分组聚集方法通用性较强,多维数组和IMA算法面向OLAP负载特征定制化设计,在性能、代码执行效率等方面具有显著的优势。
分组聚集计算也是GPU数据库的重要操作,在GPU平台上的分组聚集计算方法因GPU存储层次的多样性而产生不同的优化技术[17],分组聚集计算是典型的数据密集型负载,其综合性能评估还需要增加PCIe通道数据传输代价。从处理模型来看,CPU平台完成了从一次一列处理模型[18]向一次一向量[19]、实时编译[20]查询处理模型升级,但GPU数据库通常采用一次一操作(一次一列)的处理模式,产生较高的中间结果物化代价,降低了GPU内存的利用率。同时,传统的流水处理模式中,分组聚集操作位于连接操作之后,难以从查询计划中有效地分离计算密集型与数据密集型负载。文献[21]提出一种整合MOLAP多维计算与ROLAP关系存储的OLAP实现技术,并将传统的OLAP查询计划分解合为维映射、多维计算与聚集计算三个处理阶段,实现以负载为粒度的异构查询处理。本文在此基础上进一步研究基于向量分组聚集计算实现技术,探索硬件参数对向量分组聚集算法性能的影响因素,以及分组聚集计算在CPU与GPU平台的执行策略。
2 异构平台OLAP计算框架
在CPU-GPU异构平台上,GPU并行计算能力强大,显存带宽更高,但容量相对较小,CPU与GPU之间的PCIe通道带宽性能远低于内存带宽和GPU显存带宽。对于异构平台上的计算负载来说,数据有多大,算得有多快,数据是否具有共享性等因素都是决定计算负载执行场地的影响因素。
本章首先讨论以分组聚集计算为中心的查询处理策略,然后介绍面向异构计算平台的OLAP计算框架,实现基于负载特征和异构计算平台特征的定制化OLAP查询处理模型。
2.1 以分组聚集计算为中心的查询处理策略
在OLAP应用中,分组聚集计算是在庞大的事实表上按GROUP BY属性分组后进行聚集计算,其依赖的数据集较大,而且分组操作依赖于前面连接操作的结果集,在CPU-GPU混合平台上执行时其执行场地的选择既受数据量的影响又受连接操作场地的影响。关系数据库采用流水迭代查询处理模型,在查询优化中主要采用将选择、投影等操作下推到底层表扫描节点的优化策略,分组操作涉及不同的表而通常采用后物化方式在连接操作之后实时执行哈希分组并与聚集计算合并。OLAP查询中分组数量远低于记录数量的特征决定了后物化分组方法增加了重复的哈希分组探测计算代价并且与连接操作形成强依赖关系,连接操作的执行场地通常就是分组聚集操作的执行场地。在CPU-GPU异构计算平台上若连接操作与分组聚集操作分布于不同的处理器平台时,在异构计算平台上连接结果物化后再执行分组聚集操作方法产生较高的连接结果物化代价。
基于异构计算平台的存储与计算资源不均衡的特性,本文采用以数据局部性优化为中心、以计算独立性为基础的异步OLAP查询优化策略,通过反向查询树优化方法优化异构计算平台上的关系操作实现技术。分组聚集操作应用于事实表大数据集,在CPU-GPU混合平台数据移动代价最高,从数据局部性的角度来看最优的计算平台是CPU;从性能的角度来看,关键问题是CPU分组聚集计算最优性能在什么负载区间能超过GPU计算以及分组聚集计算选择CPU或GPU作为计算平台的优化选择策略。本节介绍了分组聚集计算的优化方法,以及受优化的分组聚集计算反向传播而影响的相关关系操作实现技术,提出了以分组聚集计算为核心的OLAP查询优化方法,并在实验部分给出了分组聚集计算对CPU和GPU平台的优化选择策略。
(1)分组聚集优化
从OLAP逻辑数据模型的角度来看,OLAP操作可以抽象为在事实数据上按给定的选择策略和分组策略进行聚集计算。从关系角度看,OLAP操作最理想的方法是直接执行事实表上的索引分组聚集计算,即每一条事实记录根据一种特定的索引结构确定自己是否参与查询的聚集计算,并且可以直接访问用于聚集计算的累加器地址。从索引实现技术的角度看,实现理想的分组聚集计算需要将分组属性向量化并且将分组向量映射到事实表位图索引中实现直接的分组聚集计算。
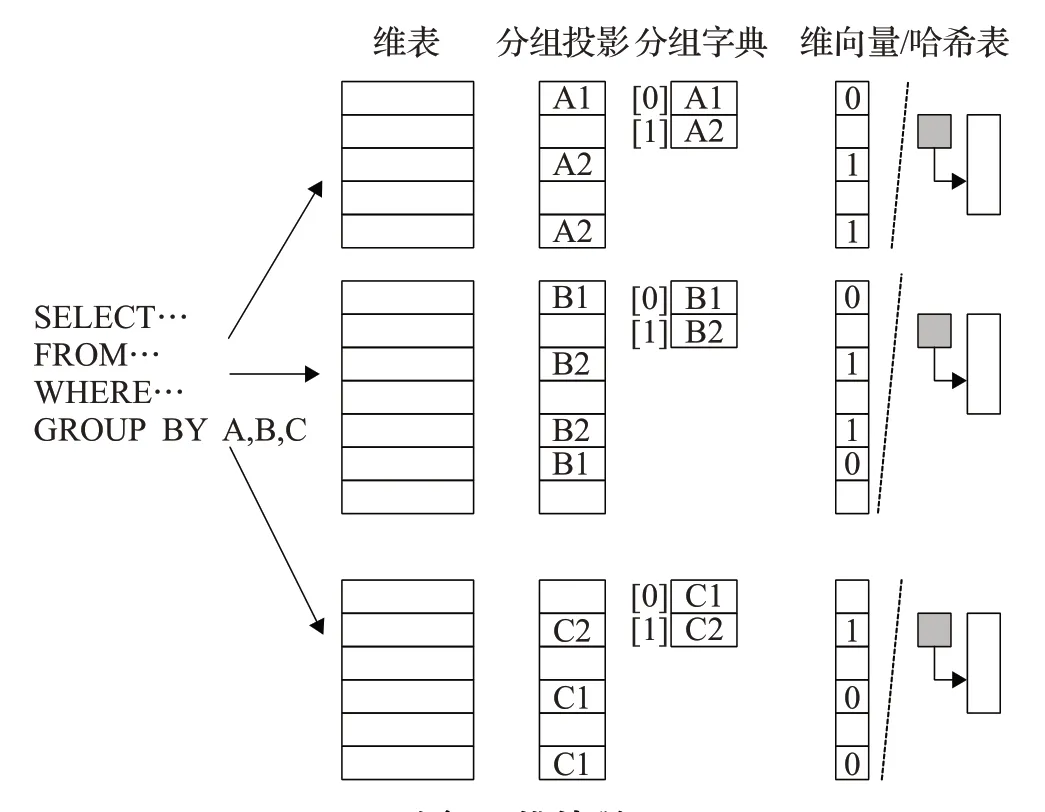
图1为向量分组聚集计算操作示意图,右侧分组向量为基于SQL命令中GROUP BY语句构造的分组向量,每个分组值对应向量中的一个单元,分组ID为向量单元地址(数组下标)。相应地,事实记录上的向量分组聚集操作基于向量索引实现。左侧为向量索引结构示意图,向量索引是一种多位位图结构,非空值代表相应位置的事实记录参与查询最终的分组聚集计算,向量索引值为最终分组向量单元ID,通过向量索引实现对事实记录按位置访问并按向量索引值直接映射到分组向量单元聚集计算。向量索引的基本结构为与事实记录等长的定长向量,向量宽度最小为向量索引中非空值数量(分组向量势集)对应的最小二进制位,即lb|分组向量|,向量索引的单元地址与事实记录地址为一一映射关系。当向量索引中非空值数量较少,即查询选择率较低时,向量索引可以采用压缩的二元组key/value结构,key值为非空向量索引单元的记录位置,value为该向量索引单元存储的分组ID。在应用中,定长向量索引可以选择一个适合的公共宽度,如int_16(对应最大216个分组),不同的OLAP查询可以共享该向量索引结构,减少多查询处理时的动态内存分配代价。压缩向量索引在低选择率查询执行时降低了向量索引扫描代价,不同查询需要生成不同长度的压缩向量索引,需要为压缩向量索引动态分配内存。

图1 向量分组聚集操作
从算法设计的角度来看,本文提出的向量分组聚集操作在分组向量存储结构上达到了最小化存储空间,直接映射到分组向量单元的聚集计算达到了分组计算的最小化CPU计算时间,在聚集数据扫描操作上通过压缩向量索引达到最高访问效率,在独立的分组聚集操作实现技术上达到了局部最优。从数据库查询处理模型的角度来看,关键问题是如何优化数据库查询处理模型以创建最优的分组聚集计算所需的分组向量和压缩向量索引数据结构,来最大化分组聚集操作性能,从而为分组聚集操作的执行场地选择提供支持。
向量分组聚集操作基于向量索引顺序扫描和事实数据按位置访问操作,是一种线性的处理方式,适合于多核CPU并行处理。图2显示多核并行向量聚集操作的基本实现方法:若向量索引为定长向量,按线程数量逻辑划分向量索引分区,并按相同的位置逻辑划分事实数据分区,每个线程并行扫描向量索引分区并执行在对应事实数据分区上的向量聚集操作;若向量索引为压缩格式,采用与定长向量索引相同的逻辑分区一方面需要扫描压缩向量索引的key值确定分区位置,另一方面当向量索引中非空值分布不均衡时定长逻辑分区导致不同线程中实际执行的聚集计算代价不同,负载难以均衡,采用在压缩向量索引上均衡逻辑分区策略,简化逻辑分区的位置计算并使各线程对应逻辑分区上的聚集计算代价较为均衡。

图2 多核并行向量分组聚集操作
在本文提出的在并行向量分组聚集操作执行时实现技术中,可以采用三种聚集计算方法:多线程共享统一的分组向量,执行基于并发控制机制的全局分组聚集计算;每个线程使用私有分组向量完成本线程逻辑事实数据分片上的分组聚集计算操作,各线程处理完毕后执行线程间分组向量的归并计算,生成最终的分组向量;当分组向量势值非常大时,采用基于分组向量ID的Radix分区方法对分组向量和相应的事实数据进行分区,使每个分区的分组向量小于私有cache,然后在每个分区上执行基于私有分组向量的向量分组聚集计算或哈希分组聚集计算。当分组向量比CPU线程私有cache(L1 cache、L2 cache、L3 cache slice)小时,分组聚集计算具有较高的数据局部性,私有分组向量提高了并行计算效率。当分组向量超过CPU线程私有cache时,私有分组向量产生较高的cache miss,共享分组向量具有较好的效率。基于Radix分区的分组聚集方法加倍了内存开销,在GPU使用较小内存执行大数据分组聚集计算时进一步降低了GPU内存利用率,因此本文中暂未对Radix分区分组聚集计算进行深入的研究,在对比实验中主要选择代表性的GPU数据库MapD的分组聚集实现技术作为GPU上分组聚集操作的代表性实现技术。在实验部分测试前两种多核并行向量分组聚集计算的性能,通过实验确定两种方法的适用范围。在性能指标的选择上,创造性地设计了数据处理带宽指标,即用分组聚集计算操作涉及的数据量除以查询处理时间以获得数据处理的带宽性能,将PCIe带宽作为一个阈值来决定分组聚集计算的执行场地选择策略:
①当数据处理带宽>PCIe带宽时,分组聚集操作的执行场地为CPU。
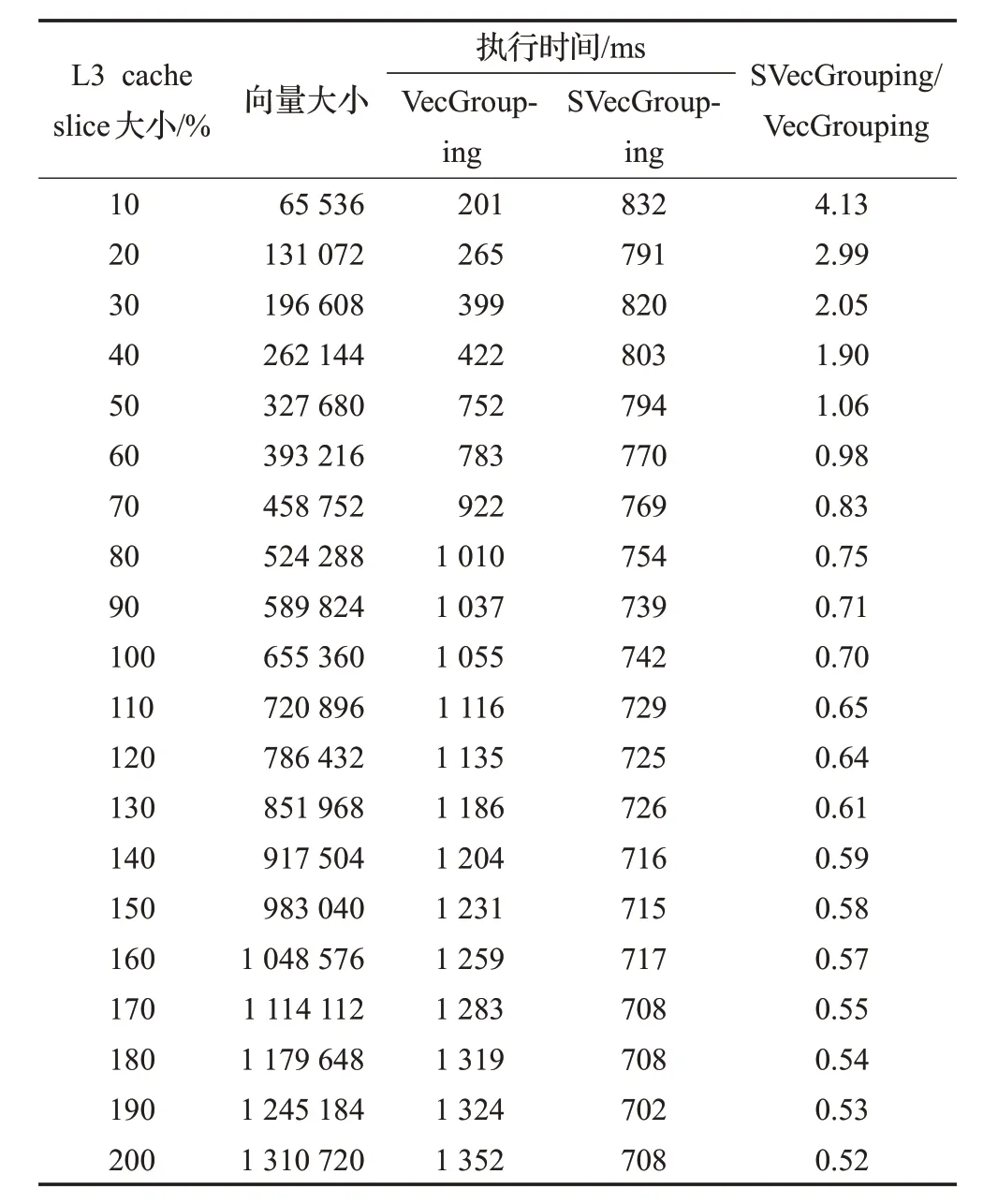
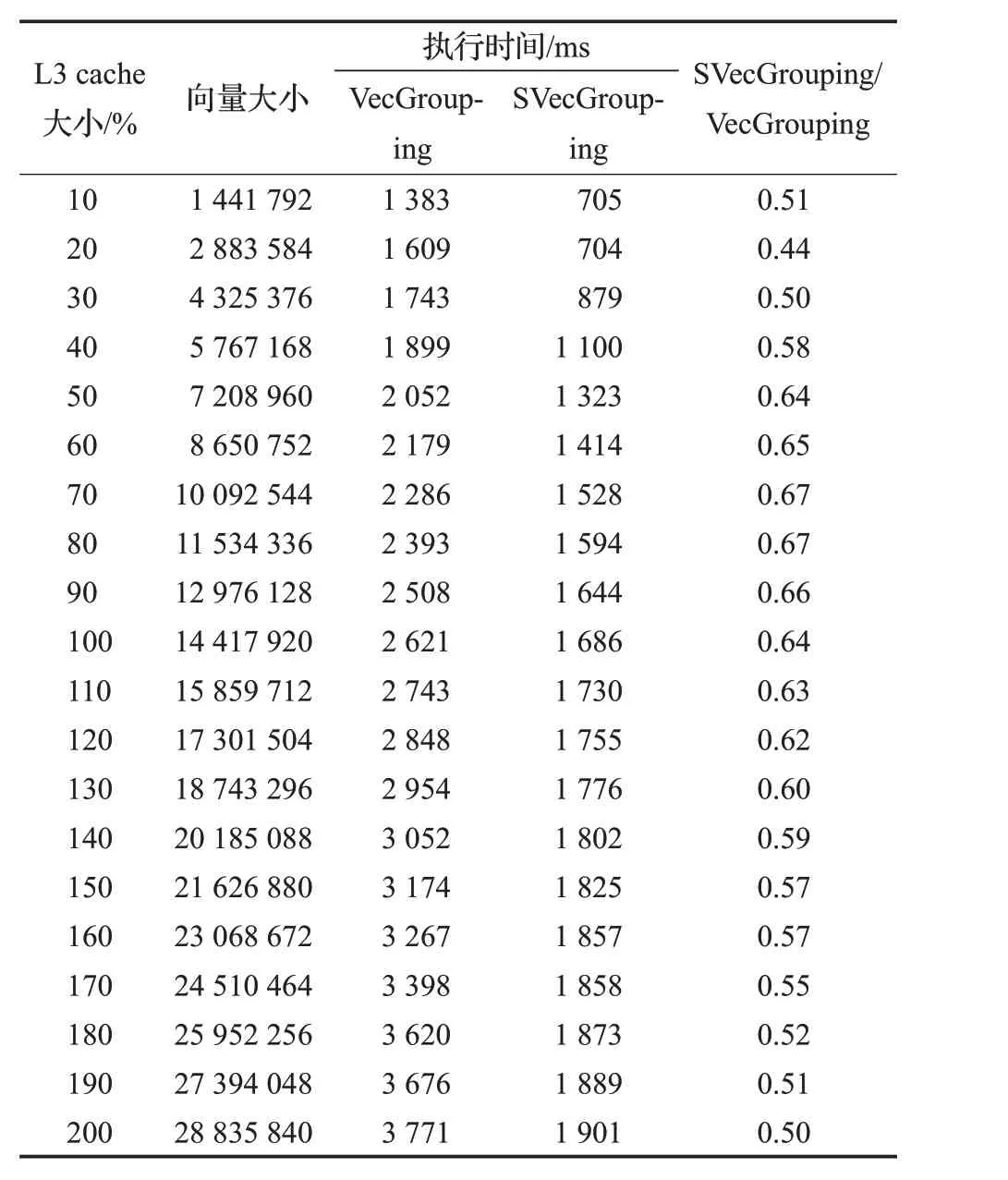
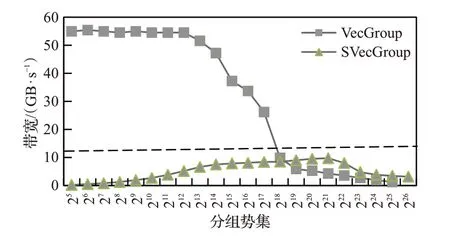
②当数据处理带宽 执行场地选择策略确定了在向量分组聚集操作下选择CPU作为执行场地的规则,但对于是否在GPU端执行还需要额外的选择策略,如GPU端分组聚集操作的性能、基于数据移动的GPU分组聚集操作是否优于CPU端分组聚集操作性能、GPU端数据存储策略、GPU分组计算方法等因素的影响,将在未来的工作中继续深入探索完整的执行场地选择优化策略。本文采用的执行场地优化选择策略在实验部分SSB基准数据集上的测试结果表明,在典型的OLAP负载中该规则已准确选择分组聚集操作执行的最优场地。 (2)星形连接操作优化 在查询处理模型的优化设计中采用反向贪心算法,即从查询树末端操作开始设计最优的实现方法,然后反向传播,确定前一操作相对应的最优实现技术,以保证以分组聚集计算为中心的查询处理达到最优。 确定OLAP查询处理末端分组聚集操作的最优模式后,需要反向优化前端的星形连接操作,要求星形连接操作输出向量索引。 图3给出星形连接操作的几种实现方法。本文的星形连接操作只涉及较小的维表输出数据结构(向量或哈希表)、中等大小的事实表外键和向量索引,不涉及庞大的事实数据,在连接操作中消除传统事实表和事实数据之间的关联性,从而使连接操作可以在较小的事实表外键列上独立执行,也使连接操作可以与分组聚集操作分离,成为两个独立执行的操作,在执行场地的选择上消除强关联。当维表采用代理键(surrogate key,连续的自然数列)时,可以使用优化的AIR[13](vector referencing[21])算法执行连接及星形连接操作,外键值直接映射到维向量的数组地址。当维表主键不能直接映射为地址时,可以采用传统的哈希连接方法,为维表(主键,维分组ID)创建哈希表。本文采用cube映射方式将GROUP-BY属性映射为分组向量,即将各维表上的GROUP-BY属性映射为一个多维cube的各维ID,当一个维表上存在多个维属性时则通过降维方法将多个属性的distinct值映射为该维的复合ID。使用该多维cube分组时称为cube分组,将该多维cube映射为一个一维向量分组称为向量分组,执行星形连接时需要迭代地通过各维表的分组ID计算出在多维cube上一维地址,作为后一阶段向量分组聚集操作中的分组向量ID。cube分组对应了GROUP-BY属性映射出的多维空间,在连接操作执行时可能部分单元在事实表上没有实际对应的数据,可以通过向量紧缩方式进一步压缩向量大小,生成与最终查询结果GROUP-BY属性对等的向量分组。具体方法是通过一个全局递增序列在执行星形连接时为每个实际向量分组单元分配唯一的ID,并将此ID作为最终向量索引中的分组ID值,原始向量分组作为最终向量与GROUP-BY属性cube分组的映射表。 图3 星形连接操作 当维表不满足主键-地址映射或者使用代理键主键但维向量很稀疏时使用哈希连接方法,图3中哈希分组中的键值为各维表分组ID,执行星形连接时基于全局递增序列为相同分组ID的哈希记录分配全局分组ID,并作为星形连接的结果记录在向量索引对应的单元中,哈希分组中的哈希表作为原始多维cube与分组向量的映射表。 内存数据库较高的性能支持用户细粒度的交互式OLAP查询,查询结果的分组数量通常较低,采用cube分组可以简化星形连接算法实现并满足大部分OLAP查询需求。 星形连接操作是一个独立的计算阶段,可以独立选择适合的优化实现技术及执行场地。文献[22]给出了一个星形连接操作实现方法,通过将连接所需的外键列驻留存储于GPU显存,通过动态传入较小的维向量调用高效的GPU星形连接计算并输出较小的向量索引的方法提供了自治的星形连接计算服务。该方法可以作为本文所提出的查询处理模型优化的星形连接阶段的一个定制化的实现方法,可以通过扩展本文所提的哈希表星形连接方法使其进一步通用化。 星形连接阶段需要输出向量索引,向量索引中分组向量的构建需要在星形连接之前的维表处理阶段实现GROUP-BY属性与多维分组cube的映射。 (3)维处理优化 在维表处理阶段,如图4所示,SQL命令改写为分解到各维表的选择、投影操作,过滤后投影出的GROUP BY属性通过字典表压缩将该维表上的分组值映射到数组字典表并使用数组下标作为分组ID,分组字典表数组在逻辑上映射为查询最终分组多维cube的一个维度。维表过滤、投影后的压缩分组ID构成一个维向量,用于后一阶段事实表与该维表的连接过滤操作。当维向量大小低于CPU的LLC大小或维向量超过LLC大小且选择率较低时,维向量连接过滤性能较高[13],当维向量上选择率很低时,可以将维向量中非空单元通过key/value二元组存储为哈希表,通过哈希连接完成连接过滤。 图4 维处理 从OLAP查询特点来看,分组聚集计算是逻辑多维数据集上的核心操作,而其他关系操作则为保障分组聚集计算的辅助及预处理操作。以分组聚集计算为中心的优化技术通过向量索引保证最优的按位置事实数据检索及基于最小向量的分组聚集计算,而向量索引则反向优化星形连接操作,通过迭代多维cube地址计算最小化星形连接操作中间结果集为单一的向量索引列,优化了operator(column)-at-a-time查询处理模型的中间结果物化代价,星形连接操作中的多维cube机制反向优化了维表处理阶段输出数据结构,以优化的维向量和分组向量优化维表输出数据结构大小,也进一步优化了后一阶段的连接性能。 传统的关系数据库中使用基于查询树的迭代查询处理模型,查询树中的节点为表或中间结果,表上关系操作的结果在查询树之间流水处理,这种查询处理模型构成了一种强耦合的处理模式,不同节点之间的操作具有较强的关联性。 本文通过对关系操作的优化设计,将查询树转换为扁平的结构,以负载为粒度将查询树划分为线性的计算模块,各模块之间执行以负载为粒度的异步流水处理模式,将结构紧密的查询树分解为松耦合的负载计算模块。从查询处理过程来看,本文提出的OLAP处理框架将传统的查询处理过程分解为三个独立的计算阶段,将同构计算平台上以消除物化代价为目标的流水线处理模型转换为适合异构CPU-GPU计算平台的、基于物化的向量索引的串行计算负载处理过程,通过数据的优化分布策略最大化计算的数据局部性,减少CPU与GPU之间PCIe数据传输代价。通过查询处理过程的分解,计算密集型的星形连接操作和数据密集型的分组聚集操作独立选择最适合的处理器平台,简化了异构CPUGPU平台上的优化策略。 图5显示了面向异构计算平台的OLAP计算框架。OLAP典型的逻辑模型是星形模型,由多个维表和事实表组成,OLAP查询是在维表与事实表多维连接的基础上执行的分组聚集分析处理。传统的数据库将OLAP查询转换为查询树,每个表上的记录通过查询树流水迭代处理。本文将查询树转换为扁平的三个查询阶段:维处理、星形连接和向量聚集,形成三个独立的计算阶段,分别对应OLAP数据库中的维表、外键和事实数据三个独立的数据集,各计算阶段可以根据计算特征分配不同的处理器平台,如本例中使用CPU平台执行维处理和向量聚集计算,GPU执行星形连接计算。 图5 OLAP处理框架 以Star Schema Benchmark(SSB)基准数据集为例,在SF=100时维表、外键和事实数据大小分别为1%、19%和80%,而三个数据集上的计算时间占比约为7%、85%和8%[6]。在OLAP查询中分组聚集计算是一种典型的数据密集型负载,在异构OLAP计算平台上不仅需要分析分组聚集计算的性能,还要将分组聚集计算的数据量作为一个参数,评估在PCIe通道的传输代价,作为分组聚集计算平台选择的考虑因素。本文在实验部分通过分组聚集操作带宽性能与PCIe带宽性能的阈值比较给出了分组聚集操作优化执行场地的选择。 本文将SQL命令中的分组聚集计算从传统的查询树中分离为独立的计算阶段,采用基于共享向量索引的物化机制降低了operator-at-a-time查询处理模型的物化代价,最大限度降低了分组聚集操作与其他操作和数据的依赖度。同时,向量分组聚集算法只使用简单的数组数据结构和数组地址访问操作,易于绑定到特定硬件平台,实现分组聚集计算向硬件平台的下压,使计算更加靠近存储平台,提高计算效率。 本文聚焦于OLAP中计算代价较大的分组聚集操作,重点比较本文提出的向量分组聚集算法与主流数据库的分组聚集实现技术在性能上的差异,包括CPU与GPU平台数据库中的分组聚集计算性能,通过对向量分组聚集算法性能的综合测试分析分组聚集计算在CPU和GPU平台执行的不同策略。 实验平台为一台Supermicro Super Workstation 7047GR-TPRF服务器,配置一块Intel Xeon E5-2699 v4@2.2 GHz多核处理器,CPU核心数量为22,支持44个物理线程,内存为256 GB DDR4。服务器操作系统为CentOS 7,Linux内核版本3.10.0-514.16.1.el7.x86_64,gcc编译器版本为4.8.5。服务器配置一块NVIDIA K80 GPU,cuda核心数量为4 992,显存容量为24 GB,显存带宽为480 GB/s。 实验中使用文献[3]提供的开源哈希连接代码为实验床,使用相同的多线程并行处理和对共享向量的latch并发访问控制机制。在开源代码中增加了向量聚集算法,生成两个列作为度量列M1、M2,模拟两个度量列上的聚集计算;算法中设置线程数量、选择率和分组数量参数,用于模拟不同查询选择率和分组势集下的聚集计算性能,算法执行命令示例脚本如下: 当前实现了2.1节中介绍的两种向量分组聚集算法:多线程共享分组向量聚集算法和线程私有分组向量聚集算法。当前分组聚集算法的研究中还没有较权威的开源代码,难以进行不同研究之间的横向比较。Hyper和MapD是内存数据库和GPU数据库的代表性系统,其性能代表了CPU和GPU上关系操作的最高水平,在实验中使用Hyper和MapD的CPU与GPU版本作为性能参照,通过SQL命令模拟分组聚集操作,相对于Hyper和MapD的性能也可以作为其他相关研究的量化参考。实验中使用OLAP测试基准SSB(Star Schema Benchmark,SF=100,事实表记录行数为6亿条),通过SQL命令模拟基于不同分组势集列的聚集计算操作。 如在Hyper数据库中使用lo_ordertotalprice%512作为分组属性,分组势集为512,使用top 1命令只输出每一行分组聚集计算结果,最小化记录输出时间的影响。Hyper数据库模拟测试SQL命令如下: 在MapD数据库中使用mod(lo_ordertotalprice,512)函数对lo_ordertotalprice列按512生成分组ID.MapD支持CPU-only的纯内存计算模式和使用GPU的GPU计算模式,在实验中通过SQL命令分别测试CPU和GPU模式下的模拟向量分组聚集计算性能。MapD数据库模拟测试SQL命令如下: 测试时每个查询连续执行三遍,取最短时间作为内存分组聚集计算时间,MapD GPU模式在第一次查询执行时间较长,主要原因是查询产生的从CPU内存到GPU内存的PCIe数据传输代价,通过连续执行消除查询执行时的数据传输代价,以准确反映MapD在GPU上的分组聚集计算性能。 实验首先测试不同分组势集下的基准分组聚集计算性能,分组势集从32(25)起依次加倍,直到67 108 864(226),分组数量覆盖OLAP查询的应用范围。 表1 基准分组聚集操作性能 分组聚集基准计算性能如表1所示,表中下划线代表当前分组数量下的最短执行时间。从整体上看,向量分组聚集算法优于Hyper和MapD数据库中的分组聚集操作性能,主要原因是数据库使用哈希分组聚集算法,相对于向量分组聚集算法使用了更大的哈希表和CPU代价更高的哈希探测方法,因此总体性能低于向量分组聚集算法。Hyper采用JIT实时编译技术和面向寄存器的优化技术,相对于采用向量处理技术的MapD CPU版本具有更优的性能。MapD GPU版本的分组聚集操作性能显著优于CPU版本,体现在了相同的MapD算法框架下GPU对分组聚集操作的加速能力,MapD GPU版本的分组聚集操作性能在分组数量界于256(28)和4 194 304(222)之间时优于Hyper,最大性能提升达到61%。当分组势集高于8 388 608(223)时,MapD GPU版本的分组聚集操作性能低于Hyper,在本文最大分组测试用例67 108 864(226)时分组聚集操作执行时间是Hyper的2.17倍,表明分组聚集计算在极大分组势集时MapD GPU算法性能低于CPU。 向量分组聚集算法的性能主要取决于向量大小与CPU cache大小之间的关系。向量长度低于524 288(219)时,对应的线程私有向量大小低于2 MB(低于CPU每核心2.5 MB的L3 cache slice),基于线程私有向量的向量分组聚集算法性能优于基于共享向量的向量分组聚集算法。当向量大小超过线程私有cache大小时,基于线程私有向量的向量分组聚集算法性能开始低于基于共享向量的向量分组聚集算法,而且较大向量也导致私有向量存储空间开销指数增长,如分组数为67 108 864(226)时44线程所需创建的私有向量产生内存空间不足错误。 总体而言,向量分组聚集算法性能优于代表性内存数据库Hyper、GPU数据库MapD的相应性能,最大性能提升分别达到695%和481%,相对于最优数据库分组聚集操作性能的最大性能提升达到481%。 向量分组聚集算法通过对OLAP查询处理模型的优化将分组聚集操作从查询树中独立出来,基于向量的分组聚集计算最小化分组聚集器的内存空间,最大化分组聚集计算时的cache局部性,基于向量地址直接访问的分组定位机制最小化分组操作的CPU代价。向量分组聚集计算在算法上的简化将性能影响因素简化为单一的向量大小,与各级cache大小的相对关系决定了其性能特征。 实验中设计了cache-conscious vector grouping benchmark(cache敏感的向量分组基准测试),测试当向量长度为各级cache大小不同百分比时的向量分组聚集计算性能。实验中向量设置为int_32类型,以各级cache容量的10%为步长设置向量长度,向量大小设置为各级cache大小的10%~200%,量化分析向量的cache局部性对向量分组聚集计算性能的影响。 表2显示了当向量大小为L1 cache大小(32 KB)的10%~200%时向量分组聚集与共享向量分组聚集算法性能。当向量小于L1 cache大小时,线程私有向量分组聚集算法性能高于共享向量分组聚集算法并且执行时间较为稳定;当向量较小时,共享向量分组聚集算法各线程并发访问共享向量产生较高的向量单元更新的latch并发访问控制代价,随向量长度的增长latch并发访问控制代价逐渐降低。共享向量分组聚集算法与向量分组聚集算法执行时间比最大为22.37倍,随向量长度的增长逐渐降低为6.17倍。 表2 L1 cache大小相关的向量分组性能 表3显示向量大小为L2 cache大小(256 KB)的10%~200%时向量分组聚集与共享向量分组聚集算法性能。10%L2 cache时向量实际大小小于L1 cache,向量分组聚集执行时间较短,随向量长度的增长,私有向量分组聚集算法时间逐渐增长,而共享向量分组聚集算法执行时间逐渐减少,二者执行时间倍数从9.04倍逐渐下降到2.9倍。 表3 L2 cache大小相关的向量分组性能 多核处理器每个核心直接连接2.5 MB的L3 cache slice,处理核心访问私有cache slice延迟低于访问共享L3 cache中其他核心的L3 cache slice,因此L3 cache slice可以看作处理核心的最后一级私有cache。表4显示了向量大小为L3 cache slice的10%~200%时两种向量分组聚集算法的性能。当私有向量大小超过L3 cache slice的50%时,私有向量分组聚集算法执行时间开始高于共享向量分组聚集算法,此时每核心2个线程私有向量总和达到L3 cache slice,私有向量访问cache局部性达到临界值,当向量继续增大时,向量访问的cache miss增加,查询延迟增长。共享分组向量仍然有较高的cache局部性,较大的向量也减少了每个向量单元并发访问冲突,查询性能逐渐提升。 表4 L3 cache slice大小相关的向量分组性能 当向量大小在L3 cache的10%~200%之间时,如表5所示,共享向量分组聚集算法具有一定的cache局部性,两种算法随向量长度的增长执行时间均增长,算法执行时间比缓慢降低。 综上所述,私有向量分组聚集算法在向量具有较高的cache局部性时有较高的性能,即每线程私有向量长度小于50%×L3 cache slice时基于线程私有分组向量的向量分组聚集算法性能较优,当向量长度继续增长时,基于共享向量的向量分组聚集算法性能逐渐优于私有向量分组聚集算法。 如图1所示,当查询选择率较低时向量索引中非空值单元较为稀疏,压缩向量索引不仅减少了向量索引非空单元的存储空间开销而且将向量索引的顺序扫描转换成更为高效的压缩向量索引扫描。 表5 L3 cache大小相关的向量分组性能 表6 基于压缩向量索引的向量分组性能 表6显示了不同选择率下的向量分组聚集算法和基于压缩向量索引的向量分组聚集算法性能,分组数固定设置为65 536,采用私有向量分组聚集算法,压缩向量索引存储为key/value序列,key值为非空向量索引单元下标,value为非空向量索引单元存储的分组ID。当选择率为100%时,压缩向量索引实际存储空间大于非压缩向量索引,其执行时间稍长;随着选择率的降低,基于压缩向量索引的向量分组聚集算法执行时间开始低于原始向量分组聚集算法但两种算法之间的执行时间差异并不显著,在选择率为10%时非压缩与压缩向量索引向量分组聚集算法执行时间比为1.63,当选择率为1%时二者执行时间比为3.62;当选择率继续以10倍的速度递减时,两种算法执行时间比逐渐增大,但执行时间比增长速度远低于选择率增长速度。由实验结果可以得到这样的策略:当OLAP查询选择率较高时(大于1%)可以采用定向向量索引策略,定长向量索引可以被不同的查询共享以简化内存管理;当OLAP查询选择率低于较低时(低于1‰)使用压缩向量索引以提高向量分组聚集计算性能。 分组聚集计算是OLAP查询中重要的操作,也是OLAP查询性能的主要决定因素之一。分组聚集操作需要在较大的事实数据上执行分组与聚集计算,本文通过将分组操作下推到维表处理阶段实现基于向量的分组聚集计算,最小化了分组计算代价,使分组聚集计算成为一种数据密集型任务,即在大数据上的低CPU代价计算。基于向量的分组操作具有较好的cache局部性,在CPU平台也具有较高的性能。 将查询中不同的操作优化分配给CPU或GPU平台以获得最高的整体性能是GPU查询优化的核心任务,需要设计将什么样的查询操作及以该查询操作在什么情况下分配给CPU或GPU的优化策略。 GPU上的计算包括本地静态数据计算和动态数据计算两种类型:本地静态数据计算指通过数据库的数据分布策略将一部分数据预先分配在GPU内存,执行GPU内存上的本地化计算;动态数据计算指数据存储在CPU端,在计算时实时通过PCIe通道传输到GPU内存后执行GPU数据复本上的计算,GPU内存缓存CPU端数据但不持久存储CPU端数据集。 由于GPU内存容量相对CPU内存较小且OLAP数据集的事实数据极为庞大,因此在事实数据上的分组计算操作主要考虑动态数据计算模式。GPU端优化执行分组聚集计算时需要满足TGPUAgg+TTrans 图6 模拟GPU聚集计算性能 随着GPU上算法优化技术的深入和GPU扩展性的提升(通过配置多块GPU卡),GPU数据库在GPU端的分组聚集计算性能可能进一步提升,从而使GPU分组聚集计算代价模型难以直接应用,从PCIe带宽性能出发提出GPU分组聚集计算的选择策略。图7给出了私有和共享向量分组聚集算法的数据带宽性能(分组聚集计算数据量/执行时间),虚线为PCIe 3.0的带宽(16 GB/s),若CPU端的向量分组聚集算法带宽性能超过PCIe带宽性能时,则CPU端执行分组聚集计算性能肯定优于GPU端,否则GPU端执行分组聚集计算性能可能优于CPU端。 图7 向量分组聚集计算带宽性能 从图7中可以看到,当分组数量低于131 072(217)时,在CPU端执行向量分组聚集计算带宽性能超过26 GB/s,远高于数据从PCIe通道传输到GPU的时间,因此适合CPU端执行。从SSB、TPC-H、TPC-DS等典型OLAP负载的查询命令来看,GROUP-BY属性通常为低势集属性,适合于向量分组聚集算法的应用场景,也适合在CPU执行。 综上所述,OLAP是适合使用GPU加速的计算密集型负载,但使用GPU加速通用的关系操作和查询处理模型难以获得最优的性能。通对OLAP查询中关键的分组聚集计算的优化设计,查询优化器可以根据分组聚集计算优化规则精确地根据查询输入参数(如分组数量等)确定分组聚集操作在CPU端还是GPU端执行,生成最优的异构计算平台OLAP查询执行计划。 实验部分通过cache-conscious vector grouping benchmark实验设计量化地给出了2.1节两种向量分组聚集方法的性能变化区间和性能变化的阈值,可以根据分组向量大小以及各级cache容量参数确定根据负载选择优化向量分组聚集操作方法的策略。进一步地,通过带宽性能指标可以进一步明确分组聚集操作选择CPU作为执行场地的分组阈值,实现了基于硬件参数确定分组聚集操作执行场地优化选择策略。 本文提出了面向异构计算平台的OLAP分组聚集计算实现技术,通过向量分组技术实现了将数据密集型的分组聚集计算从传统的查询处理模型中分离出来,独立地根据算法和硬件参数特性优化选择适合其执行的计算平台。基于向量分组的聚集计算方法通过“早分组、晚聚集”策略获得了最优的分组聚集计算性能,与当前最优的内存数据库Hyper、GPU数据库MapD相比有显著的性能提升,基于cache-conscious的向量分组聚集计算基准测试精确地描述了算法的性能特征,使查询优化器可以根据查询与硬件参数准确地估算其性能及执行异构计算平台选择策略。实验结果表明,向量分组聚集算法相对于当前主流数据库的实现技术有显著的性能优势,而且易于在异构计算平台上的实时OLAP分析处理应用中实现。
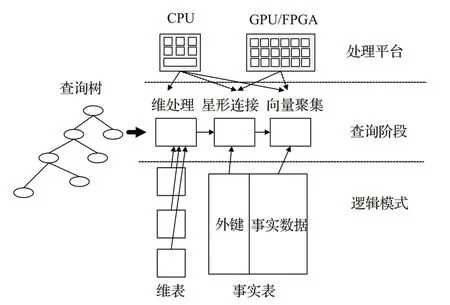
2.2 面向异构计算平台的OLAP计算框架
3 实验与结果
3.1 实验平台和实验设计


3.2 分组聚集计算性能对比

3.3 分组聚集计算性能分析
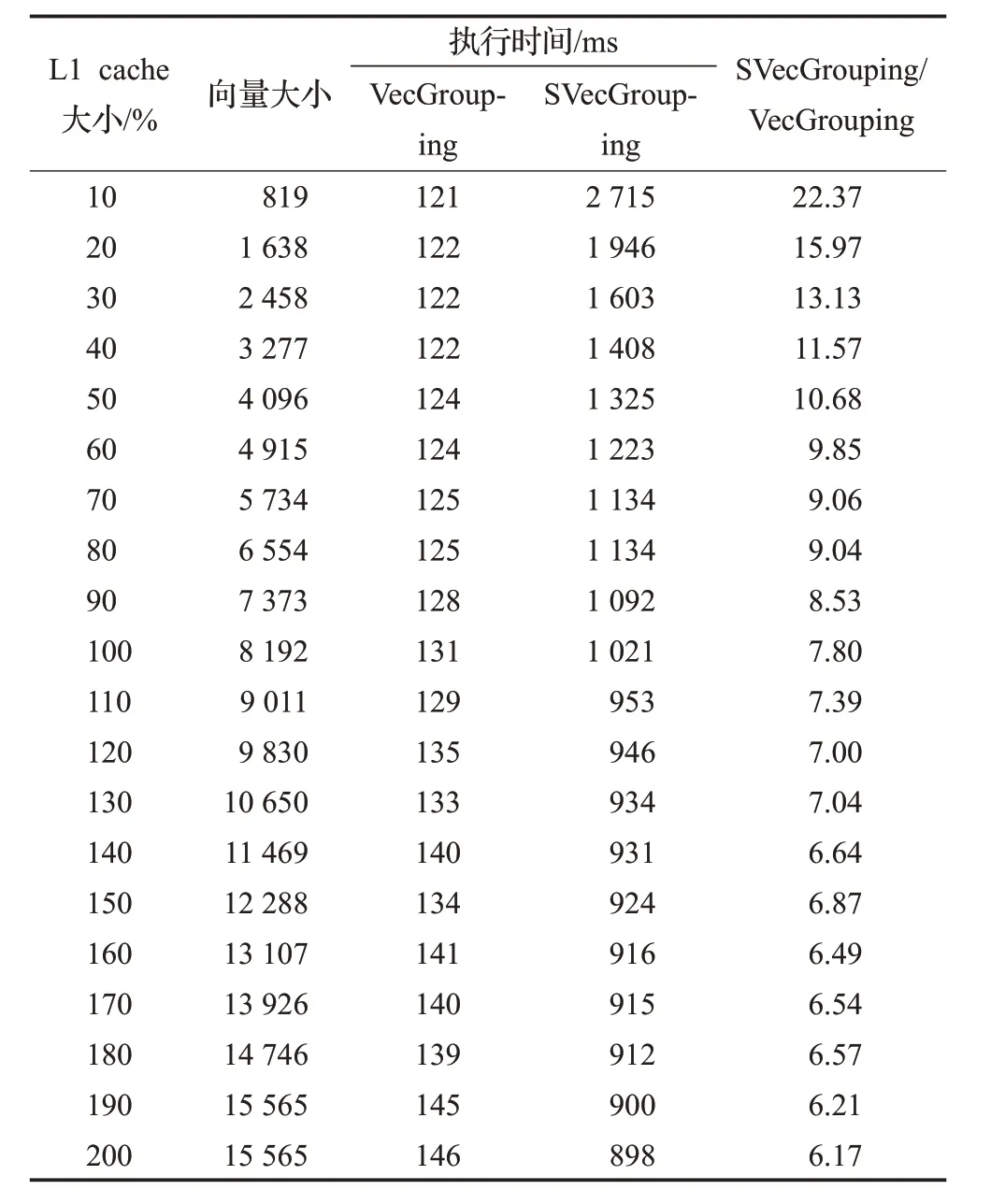

3.4 基于压缩向量索引的向量分组聚集算法性能

3.5 分组聚集计算的平台选择策略

4 结束语
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28中学生数理化(高中版.高考数学)(2021年1期)2021-03-19电脑爱好者(2020年20期)2020-10-22小学生学习指导(低年级)(2019年3期)2019-04-22小学生学习指导(低年级)(2018年9期)2018-09-26小学生导刊(低年级)(2017年1期)2017-06-12高中生学习·高三版(2016年9期)2016-05-14工业设计(2016年8期)2016-04-16新高考·高二数学(2015年11期)2015-12-23电脑爱好者(2015年13期)2015-09-10
