
CPLM-CSC: 基于单字级别预训练语言模型的中文错别字纠正方法
2021-06-10 07:18谢海华李奥林李亚博陈志优吕肖庆
中文信息学报 2021年5期
谢海华,李奥林,李亚博,陈志优,程 静,吕肖庆,2,汤 帜,2
(1. 北大方正集团有限公司 数字出版技术国家重点实验室,北京 100871;2. 北京大学 王选计算机研究所,北京 100871)
0 引言
中文错别字检测和纠正(Chinese spelling checking and correction, CSC)的目标是检测并纠正中文语句里的字词误用情况。与英文等拼音文字的拼写检查类似,CSC可以分为两个类别: 词错误(word error)纠正和非词错误(non-word error)纠正。词错误指的是两个正常词之间的误用,例如英文中的quantity和quality互相误用,中文里的“权力”和“权利”互相误用。非词错误指的是把一个正常词误写为一个非词(不在词典中的词),例如: 把quantity误写为quatity,把“进入”写成“进人”。
错别字通常发生在音近字(读音相近或相同的字)之间或者形近字(形状相似的字)之间。一般地,错别字纠正的方法分成两步。第一步是错别字的检测,即发现句子中的错别字并确定它们的位置。通常基于语言模型的原理来设计错别字检测算法。第二步是错别字纠正,通常基于一个大规模的混淆集(confusion set)来给出正确字的候选集,并评估每个候选正确字的概率,概率最高且大于一定阈值的候选字被认为是纠正的结果。评估候选正确字的概率的方法也主要基于语言模型的原理来设计[1]。
汉语的某些特征使得中文错别字纠正具有很大的难度。首先,汉语中有错误的词,但是没有错误的字,而很多错别字发生在单字词之间(例如: “在”和“再”)。单字词的用法种类很多,需要结合上下文语义才能判断它们是否误用。其次,由于中文的词之间没有分隔符,非词出现在句子中不一定是错误的,例如: “进人”在句子“化合物被注射进人体”中就没有错误。另外,发生错别字的词,在语句分词时不能被正确地切分。因此,不适宜以词为单位进行错别字的纠正。
在当前的错别字纠正模型中,非词错误纠正是主要的研究内容,但是目前的准确率也只有70%左右[2]。而词错误纠正的准确率更低,因为词错误主要发生在易混淆词之间,例如: “无需”和“无须”,不仅读音相同而且意思相近,需要基于语义分析才能准确地检测和纠正[3]。除了词错误和非词错误的纠错困难,错别字纠正工作还存在一个问题,即很多非错别字被误报。误报情况主要发生在训练数据或者词典中很少出现的词语当中,例如,专业名词、人名地名、网络用语等。
针对上述问题,我们提出一种基于单字级别预训练语言模型(CPLM-CSC)的方法来进行错别字纠正。由于错别字变化多端而且层出不究,错词典的构建非常困难,因此CPLM-CSC的错别字检测模块和纠正模块都基于预训练语言模型来设计,以避免词典构建,并减少训练数据规模。而且由于词级别纠错模型的固有缺点,即: 发生错别字的词无法被准确地切分,而且错别字纠正的目标是找出错字而非错词,CPLM-CSC采用单字级别的模型来进行纠错,即: 模型的输入和输出都是字序列,以避免分词的错误。在错别字纠正阶段,CPLM-CSC采用掩字模型的方式,即: 将检测出来的错别字掩盖,然后基于语言模型给出候选正确字的列表,并计算每个候选字的概率以选择其中最优一个作为输出。CPLM-CSC还采取了语言模型微调、数据增强、排名阈值和概率阈值等方法,来提升错别字纠正的性能。在SIGHAN 2015的数据集上进行测试,CPLM-CSC取得了68.95%的准确率和62.19%的召回率,F1值为0.654,性能优于其他模型。
1 相关工作
在现有的中文错别字纠正(CSC)算法和系统当中,语言模型理论、词切分、混淆集、错词典等是常用的技术和工具。CSC的流程主要包括两个步骤: 错别字检测和错别字纠正。错别字检测的目标是判断语句中哪个位置出现了错别字,而错别字纠正的目标是纠正识别出来的错别字。
错别字检测是CSC的重点和难点。Chang[4]提出了一个简单的做法,假设语句中所有字都可能是错误的,然后对每个字进行纠正。为了减少计算量,Lin等[5]提出了一个优化的方案,假设语句分词之后所有的单字都可能是错误的。除此之外,Hsieh等[6]使用基于未知词检测和语言模型校验的方法,以及基于由混淆集生成的词典来识别错别字。最后,将各种方法产生的结果结合起来形成最终的识别结果。其中,混淆集里面包含所有汉字以及每个字对应的音近字和形近字。由混淆集生成的词典,即错词典,包含正确词与它对应的可能错词,而一个正确词对应的错词是基于音近字和形近字生成的。Yang等[7]提出了一个高性能的模式识别器来增强分词后候选词识别的效果。Zhao等[8]为每个句子构建了一个有向无环图,并运用单源最短路径算法识别一般的错别字情况。
在错别字纠正方面,Chang[4]基于混淆集,用音近字或形近字替换掉语句中的可能错字,然后使用二元语言模型来计算原始句子的概率和所有更改的句子的概率。尽管该方法能够有效地识别错别字,但是它的计算时间长,而且有非常多的漏报。Chiu等[9]运用了统计机器翻译模型来将含有错别字的句子翻译成正确的句子,并选择拥有最高的翻译概率的句子为最终正确的句子。Yang等[10]使用ePMI矩阵统计字词之间的共现情况,并基于ePMI矩阵,选择与前后文经常共现的字词作为错别字的纠正候选。Fu等[11]将含有错别字的语句“翻译”成语法正确的语句,并从翻译后的句子中找出错别字纠正的结果。
上述方法大多需要构建大规模的混淆集和错词典,并基于大规模语料训练语言模型和分类器,总体上效率低下,而且性能不佳。另外,词切分是一项基础工作。然而,词切分本身带来的错误,会对错别字的检测和纠正带来非常大的影响。
2 算法基本流程
图1是CPLM-CSC错别字检测和纠正的基本流程。

图1 CPLM-CSC错别字检测和纠正的基本流程
模型的输入是待检查的中文段落(可包含多个语句),而输出是经过错别字纠正之后的段落。流程中间的三个步骤简单介绍如下。
2.1 单字级别词性标注和语句长度一致化调整
在训练和预测阶段,对输入模型的原始中文语句,需要进行如下的词性标注和长度一致化调整。
(1) 单字级别词性标注。词性特征对有些错别字的检测非常有用,例如: “的”字之后的词一般是名词,如果其后是动词的话,则“的”字用错了。由于输入CPLM-CSC的是字序列,即输入序列中每个单元是一个字,因此这里需要进行字级别的词性标注。对字序列进行词性标注的流程如下:
① 对语句进行分词并标注词性。
② 基于每个词的词性,按照BIES方式给语句中的每个字标注词性。BIES的含义如下:
a) B: 词的起始字;
b) I: 词的中间字;
c) E: 词的结尾字;
d) S: 单字词。
例如,“哈尔滨”的词性为地名(ns),其中每个字的词性为: 哈(ns-B),尔(ns-I),滨(ns-E)。
(2) 长度一致化调整。过短的语句很可能没有包含完整的文本信息,而过长的语句在模型中容易发生信息丢失。我们设计了基于规则的文本切割方法,并通过实验设置了语句长度范围,效果明显优于按照终结符进行语句切分的方法。例如,设置语句的长度范围为15~30字。对于长度大于30字的语句,则截取30字以内的分句。对于长度小于15字的句子,则根据情况拼到前后句子中。具体的算法如下。

2.2 基于预训练语言模型的错别字检测
CPLM-CSC的错别字检测模块是基于单字级别预训练语言模型设计的(详细描述见3.1节)。单字级别预训练语言模型(例如: BERT[12],ERNIE[13])接受字序列作为输入。由于预训练语言模型是运用大规模语料训练的,因此CPLM-CSC的错别字检测模块不需要大量语料来训练,只需要少量数据进行模型微调。
2.3 基于掩字语言模型的错别字纠正
CPLM-CSC的错别字纠正模块依然基于预训练语言模型设计以减少训练语料(详细描述见3.2节)。在输入的语句中,由错别字检测模块识别出来的错别字被掩盖,并在输出端产生错别字的候选纠正结果。针对现有方法误报较多的问题,为了提升错别字纠正性能,CPLM-CSC采取概率阈值、排名阈值、音近、形近判断等方式,以筛除不合适的纠正结果,并选择最优的结果输出。
3 算法的具体步骤
3.1 基于单字级别预训练语言模型的错别字检测
图2显示的是CPLM-CSC错别字检测模块的基本框架。输入模型的是中文语句字序列,以及单字级别词性序列。以x表示语句中的一个汉字,pos(x)表示它的词性标注,CPLM表示单字级别预训练语言模型,POSM表示词性编码矩阵。

图2 CPLM-CSC错别字检测模块的基本框架
x经过CPLM编码,输出的结果如式(1)所示。
v′(x)=CPLM(x)
(1)
输出结果v′(x)是结合深度上下文信息的字表征,维度为1×768。
pos(x)是以one_hot模式表示的x的词性,维度为1×144(36种词性标签,以及B/I/E/S这四种单字级别标签)。pos(x)经过词性编码矩阵的输出如式(2)所示。
pos′(x)=POSM(pos(x))
(2)
POSM是一个144×72的矩阵,在训练之前随机初始化,并在训练后确定矩阵元素值。pos′(x)是维度为1×72的向量。字编码和词性编码在链接之后[见公式(3)]作为语言模型编码层的输出,并输入到Bi-LSTM层。
v(x)=catenation(v′(x),pos′(x))
(3)
v(x)是维度为1×840的向量。经过Bi-LSTM层,输出如式(4)所示。
w(x)=BLSTM(v(x))
(4)

(5)

基于错别字检测模块的输出,标注为“E”的汉字被认为是可能的错字,需要在下一步进行纠正。而标注为“O”的字,不需要进行处理。
3.2 基于掩字语言模型的错别字纠错模块
CPLM-CSC采用掩字语言模型进行错别字的纠正。错别字纠正模块的框架见图3。
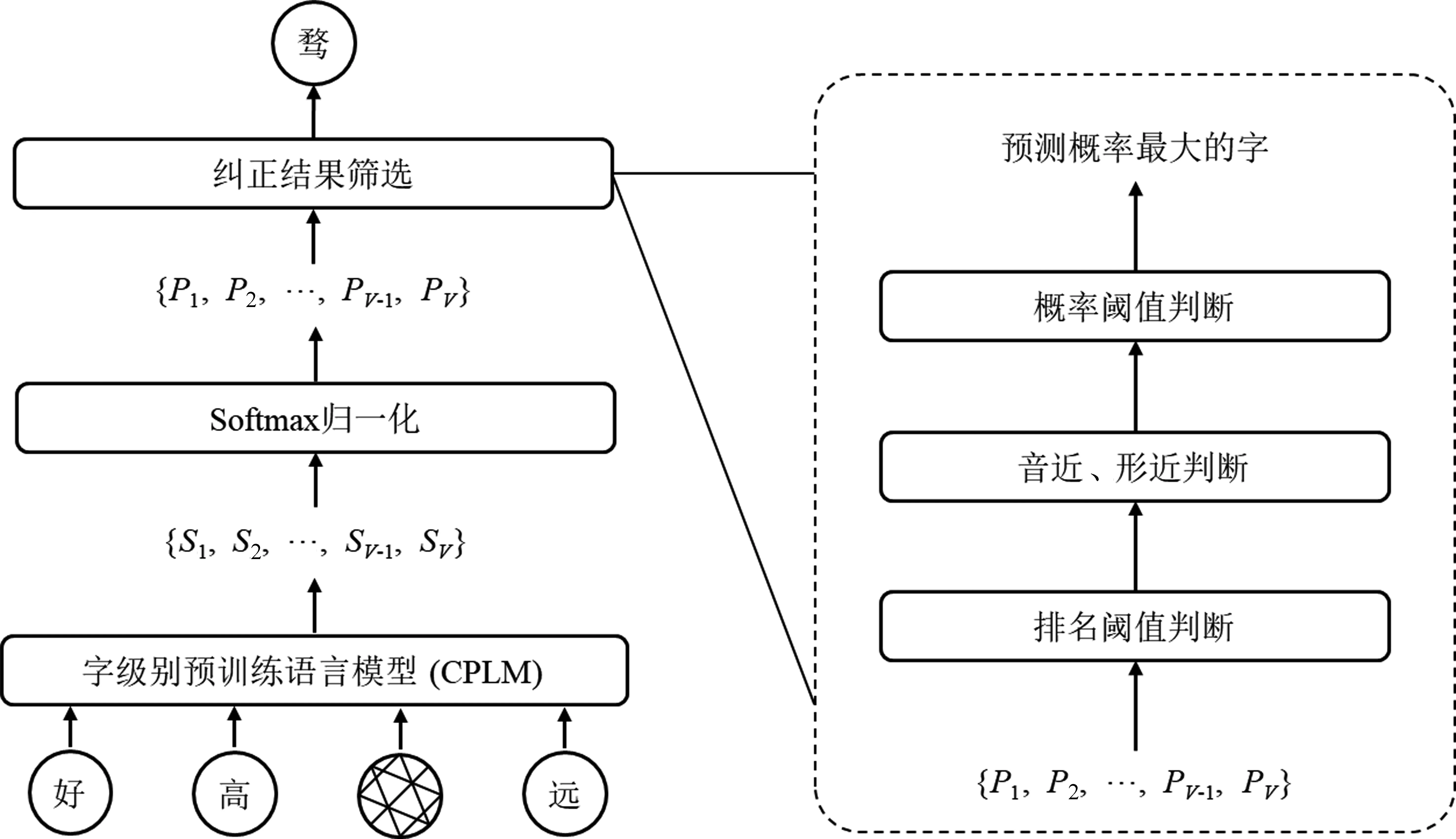
图3 CPLM-CSC错别字纠正模块的基本框架
模型的输入是一个中文语句,在错别字检测阶段中被识别出来的错别字被掩盖。经过CPLM计算之后,输出为一个维度为1×V的向量{P1,P2,…,PV-1,PV}(V是字符集的基数),向量中的元素值表示相应字符是正确字的概率(称为正确字置信度),可以将置信度最高的字作为模型输出,但是效果并不理想。为了提升最终输出结果的准确率,本文采用了以下三种方法来处理正确字置信度向量,以筛选最优的输出结果。
(1) 排名阈值判断。如果被掩盖的可能错字(例如图3中的“婺”)的正确字置信度在所有字符的正确字置信度的排名大于一定阈值(例如:100),说明它很有可能是正确的用法。这样,它被选为最终输出,即该字不做纠正。
(2) 音近、形近判断。由于绝大多数错别字出现在音近/字或形近字之间,因此首先排除音不近及形不近的候选字。基于公开的音近、形近字混淆集(Confusion Set),按照正确字置信度从大到小的顺序,筛掉与疑似错字(即被掩盖的字)音不近且形不近的字,直到出现一个音相近或者形相近的字。
(3) 概率阈值判断。在音近、形近判断之后,如果剩余的字符里面正确字置信度最大者(即置信度最大的音近字或形近字)的置信度大于一定阈值,则将该字输出;否则,由于该字的置信度不高,纠正的把握不大,因此不做纠正,输出(被掩盖的)疑似错字。
基于以上处理,最终的输出结果可能是原来的字,即不做修改,或者是满足排名阈值和概率阈值,与识别结果读音相近或者字形相近,而且正确字置信度最大的字。
错别字纠错模块的参数不需要经过训练来确定。掩字语言模型直接采用公开的、已经训练过的预训练语言模型,而概率阈值和排名阈值则由人工来确定和更新。
4 实验与分析
4.1 评测数据集
实验采用的数据是SIGHAN 2015数据集[3],其中的数据采集自初学汉语的外国人写的作文,并由汉语母语者进行标注。SIGHAN 2015数据集包含词错误和非词错误两种类型,分成以下两个部分。
(1)训练集: 包含970篇中文作文,3 143个错别字错误。
(2)测试集: 包含1 100个中文段落,其中一半至少有一个错别字错误,而另一半没有错误。
SIGHAN评测规定,参赛者可以使用任意的语言和计算资源。大多数参赛者使用了往年的SIGHAN 评测的数据集来训练模型。为使得对比公平,我们的实验使用了SIGHAN 2013[2]和SIGHAN 2014[14]的训练集。SIGHAN 2013的数据从中学生的作文中收集,错误类型较为单一,只有非词错误,共有2 000个语句,1 621个错别字错误。SIGHAN 2014的数据也是从外国人的作文中收集的,包含非词错误、单字词错误和双字词错误,共有1 363篇作文,6 076个错别字。
结果的评测分成以下两个方面。
(1) 错别字检测: 语句中的错别字被正确地识别出来。
(2) 错别字纠正: 语句中的错别字被正确地识别并且纠正。
错别字纠正结果采用准确率(Acc.)、精确率(Pre.)、误报率(FPR)和召回率(Rec.)进行评价。按照SIGHAN规定,TP表示错别字被正确纠正的次数;FP表示非错别字被误报为错别字的次数;TN表示不含错别字而且没有被误报的语句数量;FN表示错别字未能被正确检测的次数。性能评测指标的计算如式(6)所示。
(6)
针对一些特殊的错误类型,实验采用了数据增强的方法来扩充训练数据集。例如,把数据集里“的”“地”和“得”进行随机替换、将“在”和“再”进行随机替换等。
4.2 性能分析
CPLM-CSC以及其他模型的错别字检测和纠正性能见表1。实验中,CPLM-CSC采用的预训练语言模型是BERT[12],排名阈值是150,正确字置信度是0.5。表1中,CAS-Run1和CAS-Run2是SIGHAN 2015评测中结果最好的两个模型。同时,为了更加全面地分析模型,我们对CPLM-CSC模型进行了多种修改,分别进行实验,并将结果列举在表1当中。

表1 各种模型的错别字检测和纠正性能
我们对结果进行了深入分析,并统计了各种类型错误的纠正效果。对于某一种类型的错误,例如“非词错误”,我们首先计算含有“非词错误”的语句数量,然后用上文所述的各项指标的计算方法来计算纠正性能。需要注意的是,有些语句包含多种类型的错误,它们会在不同类型错误的纠正效果的统计当中被重复计算。统计结果见表2。

表2 CPLM-CSC针对不同错误类型纠正的性能分析
从表2可以看出,非词错误的纠正效果明显好于词错误纠正,而采用了数据增强的“的地得”误用的纠正效果比单字词错误的平均纠正效果要好。从这些结果中可以看出: ①词错误依然是错别字纠正的难点; ②训练数据对纠正效果有较大的影响。
5 总结
本文针对中文错别字的检测和纠正问题,提出了一种基于预训练语言模型的错别字纠正方法,以利用从大规模语料学习到的语法和语义知识,节省训练语料规模,并提高纠错的性能。本文提出的方法采用单字级别语言模型,可以消除中文分词错误对错别字识别的影响。另外,在错别字纠正阶段,本方法采用基于掩字方式构建的语言模型,并利用上下文信息计算出错别字的纠正候选字。在SIGHAN 2015评测数据集上进行测试,本文提出的方法取得了0.654的F1值,性能明显优于其他模型。
基于测试结果的分析,本方法在非词错误、单字词错误(特别是“的地得”误用,“再在”误用等)等错误上表现较好,但是在词错误上表现不好。由于词错误经常发生在一些易混淆词之间,需要结合上下文语义分析进行判断,因此其一直是错别字检测的难点。另外,本方法的误报和漏报情况依然很多,如果借助一些特殊的数据和手段,例如错别字集和专业词汇集,可以降低误报率和提高召回率。
针对上述问题,以下列举了一些可以改进模型性能的方法。
(1) 针对易混淆词之间的误用情况,依靠语言模型无法得到很好的解决。可以设计出更长距离依赖的模型,以解决这种需要进行深度上下文语义分析才能识别的错误。
(2) 借助混淆集来查找音近字和形近字,存在效率低和准确率低的缺点,毕竟混淆集包含的情况有限。设计算法来评估两个字的音近和形近程度,并给出相应得分,可以更加有效地辅助错别字纠正。
(3) 由于错别字的类型较多,针对每个类型的错误,采用单独的训练数据,设计独特的数据增强方法,甚至设计单独的纠正模型,可以显著地提高纠错性能。不过这里需要大量细致的工作。
(4) 有些字词的用法有固定的语法规则,需要应用语言学知识才能更好地判断它们的用法是否正确。因此,结合语言学知识进行错别字纠正,也是一个可行的方向。
猜你喜欢
邯郸学院学报(2020年2期)2020-08-11
新世纪智能(语文备考)(2020年4期)2020-07-25
学生天地(2020年34期)2020-06-09
作文小学中年级(2020年2期)2020-04-26
课堂内外·创新作文高中版(2016年7期)2016-08-19
中华诗词(2016年11期)2016-07-21
现代语文(2016年21期)2016-05-25
学生天地(2016年12期)2016-04-16
语文知识(2014年4期)2014-02-28
西南学林(2013年1期)2013-11-22
