
基于小句复合体的句子边界自动识别研究
2021-06-10 07:18何晓文罗智勇胡紫娟王瑞琦
中文信息学报 2021年5期
何晓文,罗智勇,胡紫娟,王瑞琦
(北京语言大学 信息科学学院,北京100083)
0 引言
篇章处理的基本单位是句子。一般来说,从语义上看,小句相当于命题,小句对应的命题由逻辑关系组合起来,语义上相当于命题组的,就是句子,或更准确地称作小句复合体[1](clause complex)。因此,凡涉及文本意义的自然语言处理应用,切分小句和句子,是一件基础性的工作。不切分出小句,命题的核心谓词和相关论元就不完整,不切分出句子,命题之间的关系就不清楚,如此状态下,涉及文本意义的各种自然语言处理应用就不可能实现高性能。
汉语文本通常被逗号、分号、句号、叹号、问号等标点符号分割成标点句序列,而汉语的小句则以标点句为基本组件,依据字面的上下文扩充话头和话体而得。若干小句依靠话头和话体的成分共享关系(简称话头共享关系),以及小句间的逻辑语义关系,组合成小句复合体,相当于通常所说的句子。句子边界识别任务即,对于给定的标点句序列,确定其中的每一个标点句是否作为某个句子的起始、中间还是结束位置,甚至能否独立形成句子。
汉语句子切分具有现实的困难,主要来自两个方面,一是汉语句子的语言学界定问题,二是实际应用中简单利用标点符号确定句子边界所带来的问题。
① 句子的语言学定义。在英语中,从句法上看,小句是一个主谓结构,其中谓语是限定动词短语,主语同谓语具有句法上的一致性。句子是小句借助连词按照逻辑语义关系复合的结果。而汉语少有形态标志,没有限定动词或非限定动词的区别,更无法进行两个成分句法一致性的判别,表示小句间逻辑关系的连词也常常不出现。如此,汉语的主谓结构、小句和小句复合体无法按英语的方法定义。汉语语法界通常定义句子为“句子是前后都有停顿并且带着一定的句调表示相对完整的意义的语言形式。”[2]这种定义虽然可以被人大致地感悟,但“相对完整的意义”缺少可操作性,难以机械化地应用。
② 特定标点符号不能作为汉语句子切分的唯一依据。英语的句子在书面文本中通常以句号、叹号、问号结束。仿照英语的做法,目前多数汉语处理应用系统都以句号、叹号、问号为句子的切分标记,但这一做法对于汉语来说没有理论依据,在应用中也存在诸多问题(以句号为例): 一是缺少语言学规范的约束。真实文本中句号的使用常常带有一定的随意性,因此以句号切分的句号句不一定具备当作基本语法单位的资格。文献[3]也明确指出了这一点。二是结构和意义不完整。一般人的印象中句号句是结构和意义完整的,但事实并非如此。
例1安军在长安杀安禄山仇视的政敌及其家属;对投降的官僚则迁到洛阳,授以官爵。又大肆搜括民财,弄得民间骚然不安。(百科全书)
例1中的百科全书语料包含5个标点句,分别为c1、c2、c3、c4、c5。以句号切分例1中的语料,得到c1-3、c4c5两部分内容,从例1的小句复合体的换行缩进图示(图1)中我们观察到: c1-3标点句序列的内容表达的意思完整,但c4c5标点句序列的内容表达的意思并不完整,标点句c4、c5都缺少主体“安军”,它位于被句号所分隔的标点句c1中。因此,此例中,c1-5应处理为一个句子,c3末尾的句号不能作为句子分割的标记。

图1 小句复合体的换行缩进图示
例2对于公民的申诉、控告或者检举,有关国家机关必须查清事实,负责处理。任何人不得压制和打击报复。(中华人民共和国宪法第四十一条)
例2中的句子由两个汉语句号句组成,它的英语参考译文(引自全国人大网)也是两个句号句:
The State organ concerned must, in a responsible manner and by ascertaining the facts, deal with the complaints, charges or exposures made by citizens. No one may suppresssuch complaints, charges and exposuresor retaliateagainst the citizens making them.
例2中,“任何人不得压制和打击报复。”的受事是“公民的申诉、控告或者检举”。但它前面的句号隔断了这种关系,使“压制”和“打击报复”无法找到被施用者。如果机器翻译系统以句号句为单位进行翻译,则很难译出参考译文中加下划线的内容。由于句号句不一定能表示完整的意义,因此以句号句为单位进行语言信息处理的工作会受到本质性的影响。
我们统计了包括本文语料库(4.1节中有详细介绍)中百科全书、政府工作报告、小说等领域语料中句号句的分布情况: 百科全书领域的语料共5 123个句号句,其中1 706个共享前面句号句中的成分,占33.3%,比例很高。同样规模的政府工作报告和小说领域的语料中这类情况分别占16.3%和24.4%,比例也很高。
本文的主要贡献在于: 重新审视了语言学中句子的定义和自然语言处理中句子的切分问题,把汉语的句子定义为话头—话体关系自足的、最小的标点句序列;本文以标点句序列作为输入,将句子边界识别问题转化成有指导的分类问题,并构建了基于预训练语言模型BERT[4]的句子边界识别模型;实验结果表明,本文提出的方法对句子的边界识别正确率、F1值分别达到了88.37%、83.73%,识别效果明显好于按照不同形式的标点符号机械分割的方法。本研究对解决句法语义分析、机器翻译等中文信息处理应用中的输入单元问题具有一定的借鉴意义。
本文第1节介绍相关研究;第2节介绍相关概念并对句子的边界识别进行建模;第3节介绍基于BERT的句子边界识别模型;第4节介绍相关实验结果对比分析,第5节为总结与展望。
1 相关研究
虽然已有大量研究者关注汉语篇章分析[5-6],但实际上着重于汉语句子分析的研究工作并不多,而对于怎样界定汉语的句子,至今还缺少深入的研究。
赵元任[7]指出: “句子是最大的语法分析上重要的语言单位。”一个句子是两头被停顿限定的一截话语。这种停顿应理解为说话的人有意作出的。其中“最大”则缺少可操作的检验标准。朱德熙[2]指出: “句子是前后都有停顿并且带有一定的句调表示相对完整的意义的语言形式。”其中“停顿”和“句调”是语音标志,在文本中部分内容是可检验的。“相对完整的意义”则缺少可操作性。宋柔等[1]把汉语的句子大致地界定为自足话题结构。之所以说“大致地”,是因为有时一个自足话题结构因带有某些连词而逻辑上不能独立,需要与和它相邻的作为逻辑关联方的自足话题结构合在一起,才能构成汉语的句子。
目前自然语言处理领域边界识别常用的方法有基于统计的方法、基于规则的方法、最大熵模型[8],以及最大熵和规则相结合的方法[9]、决策树和规则相结合的方法等,涉及的语言有藏语、维吾尔语、英语等,对汉语来说句子边界识别的研究工作并不多。本文提出的基于小句复合体的句子边界自动识别,不仅有小句复合体规则的约束,而且句子的结构和意义完整,具有一定的操作性。
句子的定义涉及小句复合体的话头共享关系,目前话头识别任务主要通过机器学习方法来实现。文献[10]等根据小句复合体理论中话头结构的堆栈模型,开展单个标点句的话头识别任务。开放测试的准确率为73.36%。在此基础上,文献[11]等将单个标点句的话头识别任务扩展到标点句序列。在开放测试集的标点句序列的话头识别任务正确率为64.99%。文献[12]等利用标点句在篇章中的位置特征、话头的语法特征、话头串和说明的邻接性等粒度特征等提高系统效率,使单个标点句话头识别任务的正确率提高了0.96%,标点句序列话头识别任务的正确率提高了1.31%。在机器学习方法中,文献[13]基于Attention-LSTM构建深度神经网络模型,进行单个标点句话头识别任务的研究,正确率可达81.74%。
2 基于小句复合体的句子边界识别建模
2.1 标点句
我们把逗号、分号、句号、问号、叹号、直接引语的引号以及这种引号前面的冒号所分隔出的词语串称为标点句[14]。
2.2 小句复合体
小句复合体是话头共享关系、逻辑语义关系和指代关系都不可分割的最小的标点句序列。其中,话头是字面上出现的词语,是话语的出发点;话体是对话头进行说明的成分。小句复合体的认定涉及各小句之间的话头话体共享关系、逻辑语义关系,还有指代关系,但话头话体共享关系是小句复合体内部最重要的衔接手段。因此,本文目前的工作只涉及小句复合体的话头共享关系。
2.3 句子
句子是话头—话体关系自足的、最小的标点句序列。某个标点句如果不是语境中其他标点句中话头的说明,且没有成分做话头被语境中其他标点句说明,这种标点句称为话头结构独立句,简称独立句,独立句也是句子。
例31875年(光绪元年),清政府采纳左宗棠的建议,派军进入新疆。左宗棠采取≮先北后南,缓进速战≯的进军方针,于1876年收复天山北路,1877年进入南疆。阿古柏在节节失败、众叛亲离情况下于库尔勒服毒自杀,其汗国亦随之覆灭。(百科全书)

图2 含有8个标点句的小句复合体结构
例3中包含8个标点句,分别为c1、c2、c3、c4、c5、c6、c7、c8,组成3个小句复合体①、②、③,小句复合体间以空行分隔。①中包含一个句子,为c1-3; ②中包含一个句子,为c4-6; ③中包含2个句子,分别为c7、c8。标点句c1缺少话体“清政府采纳左宗棠的建议”,标点句c2缺少话头“1875年(光绪元年)”,标点句c3缺少话头“1875年(光绪元年)”和“清政府”。标点句c1、c2、c3组成的整体是话头—话体关系自足的、最小的标点句序列,故标点句c1、c2、c3组成的整体是一个完整的句子。标点句c4成分完整,但是被标点句c5共享“左宗棠”,标点句c6缺少话头“左宗棠”和“于”,标点句c4、c5、c6是一个句子。标点句c7、c8都为独立句,故标点句c7、c8都是句子。
2.4 句子边界识别的形式化表示
本文将基于小句复合体的句子边界识别问题转换为标点句序列的二分类问题。该二分类模型可以定义为: 给定一个标点句对X=
汉语的句子涉及多个标点句,我们对例4中的语料进行标注。分别给出X标点句序列个数为2、3的两种标注形式。
语料的换行缩进形式如图3所示,标点句序列个数为2的语料的标注信息如图4所示。标点句序列个数为3的语料的标注信息如图5所示。

图3 含有7个标点句的小句复合体结构

图4 标点句个数为2的语料的标注形式

图5 标点句个数为3的语料的标注形式
例41995年末居民储蓄存款余额接近3万亿元,比≮七五≯末增加两万多亿元。城乡劳动就业不断增加。脱贫工作取得很大成绩,贫困人口由≮七五≯末的8 500万减少到6 500万。(政府工作报告)
3 基于BERT的句子边界识别模型
句子边界识别模型包括五个部分: BERT编码层、pooler层、全连接层、非线性激活层、softmax层。整体架构如图6所示。其中BERT编码层的向量由三种向量求和而成,这三种向量分别为词向量(Token Embedding)、位置向量(Position Embedding)、句向量(Segment Embedding)。其中位置向量表示该词的位置信息,自然语言处理中单词顺序是特别重要的特征,需要对位置信息进行编码。句向量用于表示输入的标点句对信息。将标点句对经过BERT编码层得到最后一层的输出,经过pooler层取[CLS]位置的词向量,然后经过全连接层和非线性激活层,此时的输出向量既包括词的信息,又包括上下文语义的信息。最后通过softmax层对小句复合体标点句序列进行分类。

图6 汉语句子边界识别模型
我们给出了标点句序列个数为2、3的两种标注形式。这两种标注形式对应的BERT边界识别模型的输入分别为:
(1) [CLS]必须加强国防现代化建设,[SEP]增强国防实力。[SEP]
(2) [CLS]比≮七五≯末增加两万多亿元。城乡劳动就业不断增加。[SEP]脱贫工作取得很大成绩。[SEP]
句子边界识别模型中前向计算如式(1)所示。
(1)
本文采用交叉熵函数作为模型的损失函数,给定两个概率分布p和q,通过p来表示q的交叉熵,如式(2)所示。

(2)
为了避免过拟合问题,我们在优化目标函数中加入了刻画模型复杂程度的L2正则化。L2正则化的计算如式(3)所示。
(3)
4 实验设计
4.1 数据集
本文采用北京语言大学中文小句复合体语料库[15],包括百科全书、政府工作报告、新闻、小说四个领域的语料,共有12 675个句子。语料中句子的分布情况如表1所示。
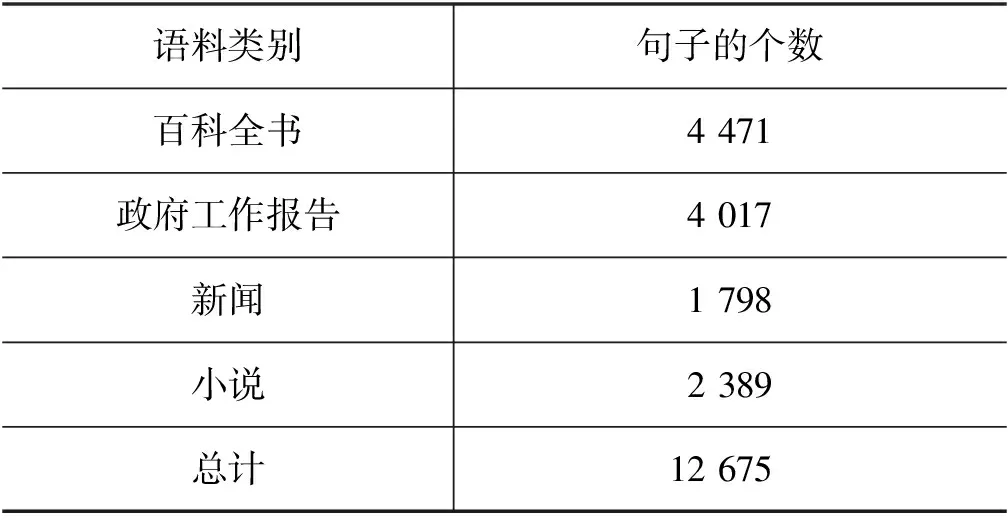
表1 句子的分布情况
我们依据小句复合体理论对百科全书、政府工作报告、新闻、小说的语料进行标注。语料中共标出了37 090个标点句对,我们按照7∶2∶1的比例随机划分训练集、验证集、测试集。
4.2 评估指标
本文采用的评估指标为正确率、F1值。实际类别与预测类别关系如表2所示:

表2 实际类别与预测类别关系的表示
其中,TP为正确预测句子边界的数量;TN为将非句子边界预测为非句子边界的数量;FP为将非句子边界预测为句子边界的数量;FN为将句子边界预测为非句子边界的数量。据此,正确率(Accuracy)定义如式(4)所示。
(4)
精确率(Precision)为正确预测为句子边界的占全部预测为句子边界的比例。精确率定义如式(5)所示。
(5)
召回率(Recall)为正确预测为句子边界的占全部实际为句子边界的比例。召回率定义如式(6)所示。
(6)
F1值为精确率和召回率的调和均值。精确率和召回率都高时,F1值也会高。F1值定义如式(7)所示。
(7)
4.3 依据特定标点符号机械分割识别结果
在标注好的语料的基础上,我们分别按照句号、句号分号、句号叹号、句号问号4种形式的标点符号对百科全书、政府工作报告、小说、新闻文本中的语料进行机械分割,正确率分别为: 80.77%、79.41%、80.98%、80.93%。结果如表3~表6所示。
表3是按句号分割语料的结果。全部语料按句号分割的正确率为80.77%,其中政府工作报告、百科全书、新闻、小说语料按句号分割的正确率分别为82.53%、78.90%、81.66%、81.18%。

表3 按句号分割语料的结果
表4是按句号分号分割语料的结果。全部语料按句号分号分割的正确率为79.41%,其中政府工作报告、百科全书、新闻、小说语料按句号分割的正确率分别为81.62%、76.25%、81.16%、80.91%。
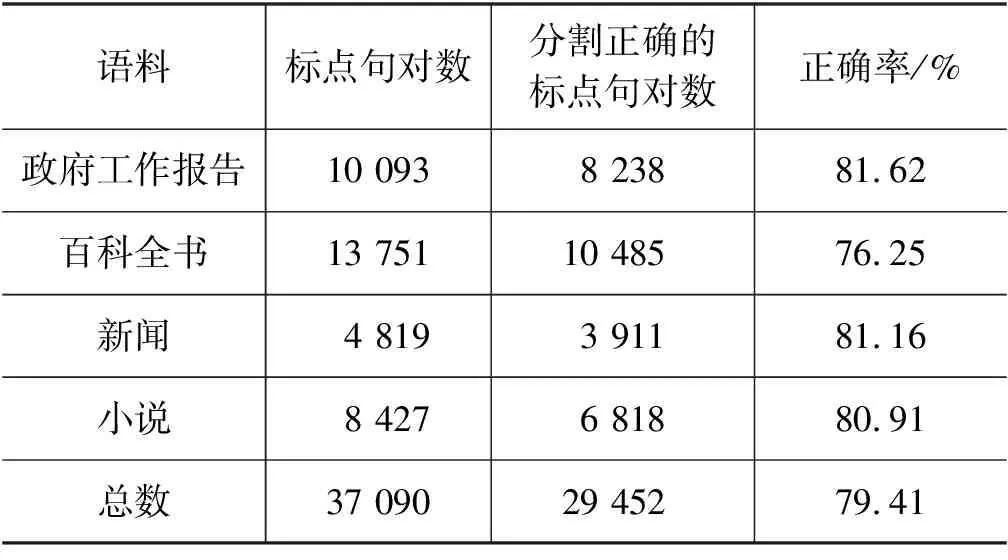
表4 按句号分号分割语料的结果
表5是按句号叹号分割语料的结果。全部语料按句号叹号分割的正确率为80.98%,其中政府工作报告、百科全书、新闻、小说语料按句号叹号分割的正确率分别为83.01%、78.88%、81.93%、81.42%。
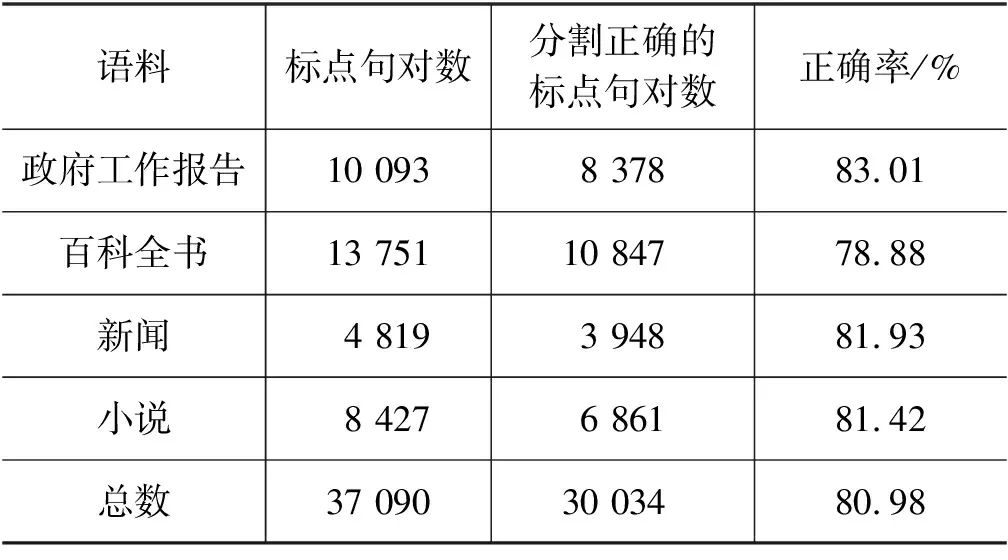
表5 按句号叹号分割语料的结果
表6是按句号问号分割语料的分布情况。全部语料按句号问号分割的正确率为80.93%,其中政府工作报告、百科全书、新闻、小说语料按句号问号分割的正确率分别为82.53%、78.89%、82.63%、81.36%。

表6 按句号问号分割语料的结果
4.4 实验设置
实验中所有模型使用深度学习开源框架Tensorflow搭建。训练集的Batch Size设置为32。选用的优化器为Adam Optimizer,优化器的学习率为0.000 05。迭代次数为2 000。BERT模型未进行参数更新。
4.5 实验结果
该实验对句子的边界进行识别,标点句序列个数为2的实验在测试集上的正确率、F1值分别为85.90%、79.75%,如表7所示。由上文我们得到按句号、句号分号、句号叹号、句号问号机械分割的正确率分别为: 80.77%、79.41%、80.98%、80.93%,正确率分别提高了5.13%、6.49%、4.92%、4.97%。
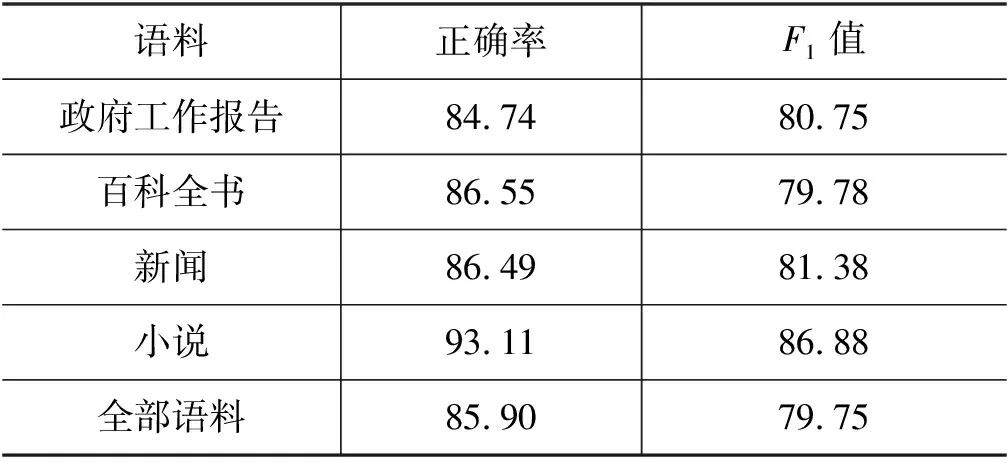
表7 标点句序列个数为2的句子边界自动识别结果 (单位: %)
标点句序列个数为3的实验在测试集上的正确率、F1值分别为88.37%、83.73%,如表8所示。由上文我们得到按句号、句号分号、句号叹号、句号问号机械分割的正确率分别为: 80.77%、79.41%、80.98%、80.93%,正确率分别提高了7.60%、8.96%、7.39%、7.44%。
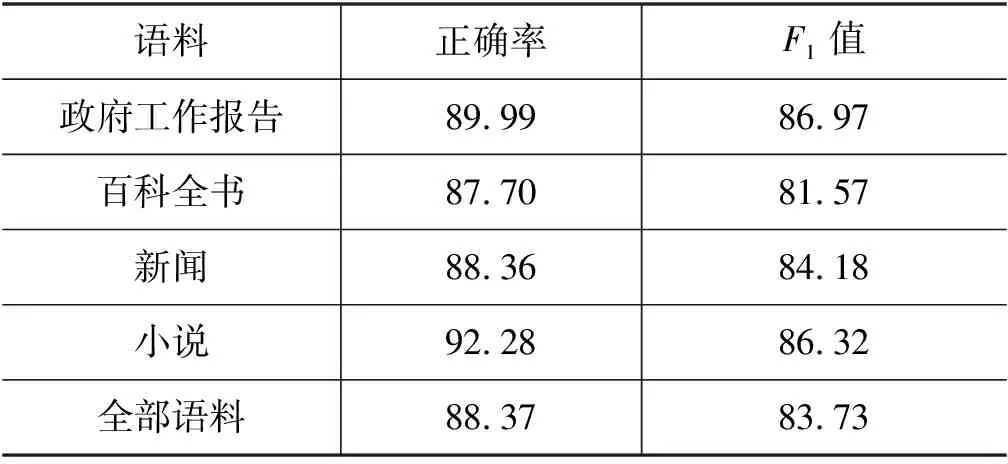
表8 标点句序列个数为3的句子边界自动识别结果 (单位: %)
我们对政府工作报告、百科全书、新闻、小说领域的语料进行研究,对比不同领域句子的边界识别效果。表9为不同领域语料实验对比结果。

表9 不同领域语料实验对比结果 (单位: %)
4.6 实验结果分析
我们对政府工作报告、百科全书、新闻、小说等不同领域语料、不同实验配置条件下的句子边界识别效果进行对比分析,得到如下结论:
(1) 基于BERT边界识别模型的自动识别效果明显好于按照不同形式的标点符号机械切分的效果。
(2) 预测点上下文窗口大小,对于句子边界识别正确率具有较大影响。在满足BERT模型所能容纳的序列长度限制条件下,上下文标点句序列长度越长,识别性能越高。实验中,预测点上下文标点句序列长度为3时达到最佳性能。
(3) 模型在不同领域文本中的识别效果有较大差异。小说文本的识别效果最好,其次为政府工作报告,最差为百科全书文本。
我们对语料中未能正确识别出句子边界的标点句序列进行分析,涉及的原因主要包括:
(1) 除话头话体关系外,句子内部涉及转折、对比、假设等逻辑语义关系,如例5所示。
例5我们要为经济振兴打好基础,必须使基本建设保持必要的规模,但这个规模一定要同国力相适应,不能超过财力负担和物资供应的可能。如果违反这一客观经济规律,就会受到现实生活的惩罚。(政府工作报告)

图7 依据话头话体关系和逻辑语义关系构成的小句复合体
例5中包含6个标点句或2个句号句(c1-4和c5c6),实际组成一个小句复合体(句子)。模型未能识别句号句c1-4和c5c6之间的假设和转折关系,因而错误地将上述标点句序列切分为c1-4和c5c6两个独立的句子。
(2) 句子中含有的直接或间接宾语等嵌套成分,如例6所示。
例6他还认为,就汽车营销而言,中国现在还几乎是一张白纸,这意味着难得的发展机遇。中国汽车工业的进步将强有力地推动中国经济的发展。

图8 具有嵌套结构的小句复合体
其中,“就汽车营销而言……发展机遇。中国汽车……的发展”整体作为动词“认为”的间接宾语,而间接宾语中又包含有两个小句复合体(句子),存在多层嵌套关系。系统未能识别间接宾语所覆盖的范围,误将间接宾语中的第一个句号(连同外部的引导语)和第二个句号句识别为两个独立的句子。
5 总结与展望
句子是语篇的基本语义单位,其句内、外的功能组织在语篇的发展过程中扮演了重要的角色,句子边界识别是整个篇章分析过程的前提和基础。本文依据小句复合体理论提出了汉语句子切分的任务,并设计和实现了基于BERT的句子边界识别模型。实验结果表明,该方法相比于传统基于标点符号进行句子机械分割的方法,具有更高的准确率。
目前,我们的研究只涉及分析标点两侧相邻的多个标点句序列之间的关系,以识别句子的边界。未来的工作将尝试通过序列标注的方式对标点句之间的逻辑语义关系进行建模、引入嵌套结构层次分析等方法,进一步提升句子边界识别的性能。
猜你喜欢
红蜻蜓·低年级(2022年9期)2022-10-14
小学生学习指导(低年级)(2021年12期)2021-12-31
辽宁省博物馆馆刊(2021年0期)2021-07-23
作文周刊·小学一年级版(2021年32期)2021-01-04
小天使·一年级语数英综合(2020年11期)2020-12-16
小学生学习指导(低年级)(2020年9期)2020-11-09
小学生作文(低年级适用)(2017年3期)2017-07-06
作文大王·低年级(2016年1期)2016-02-29
原子与分子物理学报(2015年1期)2015-11-24
食品科学(2013年15期)2013-03-11
