
生成对抗网络介绍及应用
2021-06-10 12:23:36奚祥品朱向冰
无线电通信技术 2021年3期
奚祥品,陈 筱,朱向冰
(安徽师范大学 物理与电子信息学院,安徽 芜湖241002)
0 引言
近年来,随着计算机技术的发展,数据量的积累和对动物神经网络的研究及成果,使得人工智能发展迅速,在机器学习方面尤为突出。依据输入数据集是否有标签(label),机器学习任务被分为有监督学习[1]、无监督学习[2]和半监督学习[3]。目前机器学习[4]方法,特别是深度学习[5]方法在无监督学习任务中取得优秀的成绩,如图像修复、图像生成及风格迁移等。生成对抗网络(Generative Adversarial Networks,GAN)是一种无需大量标注训练数据的深度学习模型,在许多方面都有应用,包括图像生成[6]、图像语义编辑[7]、图像风格转换[8]以及图像超分辨率等[9]。
2014年,Goodfellow等人[10]最早提出了生成器和判别器的概念和结构,介绍了GAN。2014年9月,Mehdi Mirza等人[11]在原始GAN的基础上提出了条件GAN,证明了该模型可以生成以类别标签为条件的手写数字集。Xi Chen等人[12]提出了GAN的理论扩展InfoGAN,从3D渲染图像的光照中构成模型,从SVHN数据集上的中心数字中获得背景数字。Yu L等人[13]提出了一个序列生成框架,称为SeqGAN,以解决原始GAN不易生成离散标记序列的问题。GAN广泛应用在图像领域,将从GAN模型的结构和原理进行介绍。
1 GAN模型
GAN是一组相互竞争的网络。GAN由生成器(Generator)和判别器(Discriminator)组成。例如对于一组图像数据集,常见的类比是把一个网络看作伪造专家,而另一个网络看作鉴别专家。伪造专家被称为“生成器G”,生成器的目的是为了生成逼真的图像。鉴别专家被称为“判别器D”,它接收伪造(fake)图像和真实 (real)图像,并将它们区分开,如图1所示。在GAN的结构中,生成器接受随机噪声生成合成数据样本。将合成数据样本或真实样本数据集输入到判别器进行判断,如果是合成数据样本,则输出“伪造”,同时输出分数(接近0)。如果判别器判断输入是真实数据集样本,则输出“真实”,并进行打分。生成器和判别器接受训练,相互竞争。
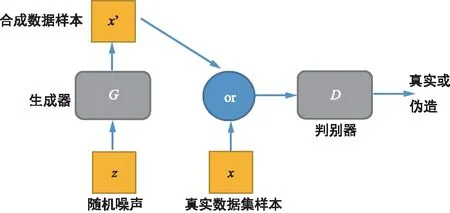
图1 GAN结构Fig.1 Structure of GAN
生成器无法直接生成真实图像,它学习的方式是通过与判别器进行交互。判别器可以获得真实样本(来自真实图像数据集)以及伪造样本。如果判别器识别到样本来自生成器,判别器反馈结果为伪造;如果识别到样本来自真实数据集,反馈结果为真实。这个结果(fake)可以用来训练生成器,使其能够产生质量更好的伪造品。判别器网络D可以理解为一个函数,计算输入图像样本数据来自真实数据分布的概率,对输入的图像样本进行评价。判断的数据若来自真实数据集,则输出接近于1;若是有生成器生成,则输出接近0。当判别器分类效果比较优秀时停止训练,对生成器G继续进行训练,同时降低判别器的准确度。如果生成器产生的图像数据与真实的图像数据及其相近,判别器就会最大程度地混淆,对所有输入预测结果为0.5。
GAN网络有很多优点,但也存在训练不稳定、梯度消失、模式崩溃的问题。为解决这些问题,提出了很多的GAN改进模型,下文对部分模型进行介绍。
2 GAN改进模型
2.1 深度卷积生成对抗神经网络
Radford等人[14]提出了一种名为深度卷积生成对抗神经网络 (Deep Convolutional Generative Adversarial Networks,DCGAN)的网络架构,生成器模型和判别器模型都运用了深度卷积神经网络(Convolutional Neural Networks,CNN)。如图2所示,它将原始GAN网络和CNN网络结合起来,生成多种多样的图像。生成器和判别器使用ReLU激活函数降低梯度消失风险。将池化层用卷积层替代,判别器用步幅卷积替代,生成器用部分步幅卷积替代。DCGAN对CNN的结构做了一些改变,以提高样本的质量和收敛的速度。
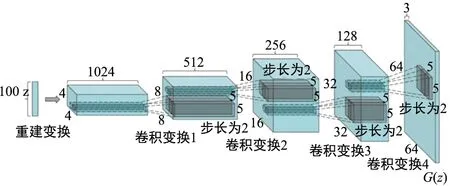
图2 DCGAN生成器结构Fig.2 Generator structure of DCGAN
2.2 条件生成对抗网络
原始GAN生成的图像随机,生成图像不可控制。针对原始GAN不能生成特定属性图像的问题,Mehdi Mirza等人提出了条件生成对抗网络(Conditional Generative Adversarial Networks,CGAN)。如图3所示,CGAN生成器和判别器的输入多了一个约束项y,用来生成指定的图像。约束项y可以是一个图像的类别标签,也可以是图像的部分属性数据。如果条件变量y是类别标签,那么CGAN便将无监督的学习转化为有监督的学习。CGAN生成的图像虽有很多缺陷,譬如图像边缘模糊,生成的图像分辨率太低等,但是它为后面的Cycle-GAN开拓了道路,模型转换图像风格时对属性特征的处理方法受CGAN启发。
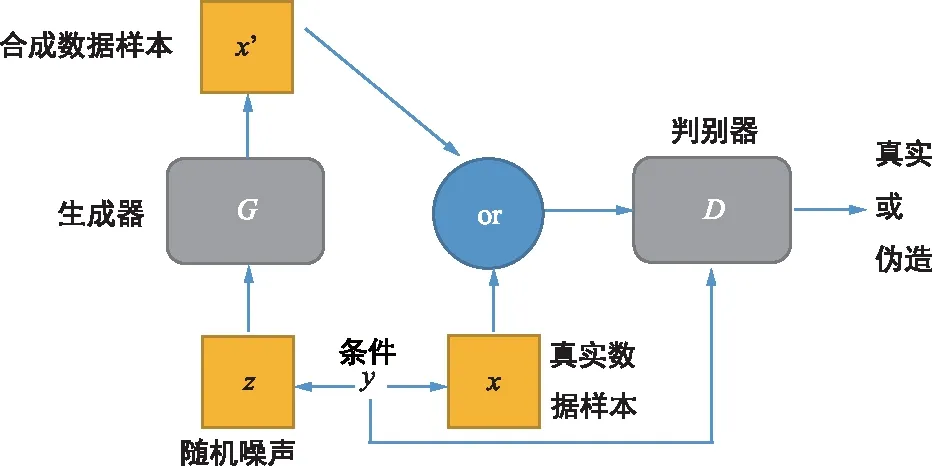
图3 CGAN结构Fig.3 Structure of CGAN
2.3 无监督式生成对抗网络
相对于原始GAN网络,无监督式生成对抗网络(Information Maximizing Generative Adversarial Networks,InfoGAN)[12]将随机噪声z分成固定分布噪声z1(见图4)和有隐含意义的信号(例如图像风格)c,损失函数里面用到互信息,使得隐变量c与生成的变量G(z,c)拥有尽可能多的共同信息。对随机噪声 z 施加可解释的隐含变量,控制图像生成。以MINST数据集为例,了解隐含变量可以控制生成图像的亮度、倾斜程度、笔划粗细等。

图4 CGAN结构Fig.4 Structure of InfoGAN
2.4 基于能量式生成对抗网络
基于能量式生成对抗网络(Energy-based Generative Adversarial Networks,EBGAN)[15]与原始GAN的区别在于,EBGAN更改了判别器的架构,如图5所示。在输入图像(x)后添加一个自编码器(Auto-encoder),把自编码器当作判别器,输出的E是编码器(Encoder)和解码器(Decoder)的均方差(MSE)。根据提供的真实图像样本重构误差值来判断图像质量的好坏,图像重构的误差越小,说明图像的质量越高;相反,如果图像重构的误差值越大,说明图像的质量越差。EBGAN的优点是不需要生成器提供伪造图像样本,仅使用真实图像样本就可以重复训练判别器。在训练EBGAN最初的几个迭代(epoch)就可以得到比较清晰的图像。

图5 EBGAN结构Fig.5 Structure of EBGAN
2.5 改进自编码器式生成对抗网络
改进自编码器式生成对抗网络 (Variational Autoencoder Generative Adversarial Networks,VAE-GAN)[16]可以理解为用变分自编码器(Variational Autoencoder)来强化GAN。VAE可以理解为auto-encoder的改进。如图6,图像x进入编码器(Encoder)后转化为向量(代码)q,q再进入解码器(decoder)后再输出图像x。图像x前后要求越相近越好。VAE会约束q,使其满足正态分布。VAE-GAN在原来的编码器和解码器之后再加一个判别器,来判断解码器(生成器)输出图像x的真伪性。生成器在训练的时候要考虑判别器的反馈,同时需要降低图像重构差异值,所以训练的结果比较稳定。

图6 VAE-GAN结构Fig.6 Structure of VAE-GAN
2.6 双向生成对抗网络
双向生成对抗网络(Bidirectional Generative Adversarial Networks,BiGAN)[17]由一组自编码器(autodecoder)和判别器(discriminator)组成。编码器和解码器相互无关联。如图7所示,输入真实图像x进入编码器获得代码(code)p,输入代码(code)p进入解码器(decoder)生成图像x。

图7 BiGAN结构Fig.7 Structure of BiGAN
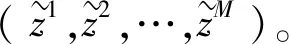
2.7 超分辨率生成对抗网络
为了提高图像在更高分辨率下的保真度,C.Ledig等[18]提出了超分辨率生成对抗网络 (Super-Resolution Using a Generative Adversarial Network,SRGAN),使一幅低分辨率的图像生成一幅相同更高分辨率的图像。为了使生成的高分辨率图像和真实高分辨率图像相近,SRGAN在loss上增加了feature map部分的均分误差。生成器和判别器的结构如图8所示。生成器由B残差块(B residual block)和多个卷积层组成,目的是生成高分辨率的图像。B residual block包括卷积(Conv)、归一化(BN)、参数化修正线性单元(PReLU)、元素求和(Element Wise Sum)。图8中的k,n,s分别表示每个卷积层相应的卷积核大小、特征映射数量和步幅。判别器同样由大量卷积层组成,目的是判别输入图像的真伪性,判别器的卷积层包括Conv、BN以及带泄露的修正线性单元(Leaky ReLU)。

图8 SRGAN部分结构Fig.8 Structure of SRGAN
3 GAN的应用
3.1 图像生成
由GAN的结构就可以了解到,GAN的一个作用就是生成数据。目前限制深度学习发展的一个原因是训练数据的缺乏,而GAN生成数据刚好可以弥补这一缺陷。最近的GAN研究主要集中在提高图像生成能力的质量和实用性上。LAPGAN模型[19]在Laplacian金字塔框架中引入了层叠的卷积网络,以粗糙到精细的方式生成图像。Huang等人[20]使用了类似的方法,GAN对中间表示操作,而不是低分辨率图像。CGAN的想法后来被扩展到自然语言。Reed等人[21]使用GAN架构从文本描述中合成图像,可以理解为自然语言处理(NLP)。例如,给定一只鸟的文字说明,比如它的头部和翅膀上有一些黑色的白色,以及长长的橙色的喙,经过训练的GAN可以生成一些与描述相符的图像,如图9所示。

图9 文字描述生成图像Fig.9 Text description generated image
条件GAN不仅可以用来生成具有特定属性的新样本,还可以用来开发编辑图像的工具。例如,改变图像中一个人的表情,让她微笑,或者修改皮肤颜色让她看起来更年轻,如图10所示。GAN在图像编辑方面的其他应用包括Brock[22]等人的工作。

图10 更改面部表情Fig.10 Facial expression changes
3.2 图像超分辨率
图像超分辨率技术能够使低分辨率图像生成高分辨率图像,训练模型在上采样时模拟出逼真的细节。SRGAN模型[18]通过添加一个损失组件(loss)改进GAN的损失函数,将基于均方误差的内容损失替换为基于VGG网络的特征映射计算的损失。损失函数包括对抗损失、图像平滑项和特征图差异三个损失项,对抗式损失是损失函数的组成部分。图像超分辨应用介绍如图11所示,从左到右分别为:双三次插值法对应图像、超分辨率深度残差网络对应图像、超分辨率生成对抗网络图像以及原始高分辨率图像。

图11 SRGAN生成高分辨率图像Fig.11 Generates high-resolution images by SRGAN
3.3 图像风格迁移
图像风格迁移如图12所示,使用内容图像和风格图像组合,生成一张风格迁移之后的图像。pix2pix模型为图像风格迁移提供了通用的解决方案。pix2pix模型学习输入图像到输出图像的图像特征变化,同时构建了一个loss函数来训练这种特征变化。如图13所示,从模型图生成街景,航拍照片生成地图,黑白图像上色到手绘图像转变现实图像,体现了pix2pix模型在图像风格迁移上的作用。

图12 图像风格迁移Fig.12 Image style transfer

图13 pix2pix生成图像Fig.13 Generate image use pix2pix
4 结束语
本文对GAN的原理结构、改进模型以及应用进行了介绍与总结,在深度学习这个广泛的背景下使用GAN进行图像分类,对在非监督学习中提取特征进行有效定量评估。GAN应用主要是图像生成,在预先设定的条件下生成图像时很有效。以图像超分辨率为例,解释了现有的方法如何优化生成对抗网络(如SRGAN),以获得更高质量的图像结果。最后,pix2pix演示了GAN如何解决自动将输入图像转换为输出图像等一系列任务。借由GAN的强大能力,基于GAN的应用在未来也将会有更广阔的前景。
猜你喜欢
雷达学报(2020年3期)2020-07-13 02:27:16
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
太空探索(2015年8期)2015-07-18 11:04:44
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:19
