
大数据环境下基于深度学习的移动视觉搜索机制研究*
2021-06-09 09:16朱维乔
图书馆学刊 2021年5期
朱维乔
(广州航海学院图书馆,广东 广州510725)
1 国内外相关研究现状评述
大数据环境下,随着智能移动终端设备的普及和计算机技术的迅猛发展,智慧图书馆传递的信息除了传统的文本形式之外,更多地扩展为以图片、3D模型、多媒体音视频以及Web页面等作为载体的视觉数据,其日益成为图书馆大数据资源必不可少的组成部分[1],视觉资源与用户交互传感信息的有机融合使搜索引擎面临严峻挑战。一方面,基于关键词标注的传统信息检索模式效率低下且成本较高,不再适用于移动视觉大数据搜索;另一方面,深度学习技术驱动的计算机视觉的飞速发展,为挖掘更为高效的视觉资源搜索方式提供了技术保障。移动视觉搜索是以移动智能设备作为采集终端,以实物图片、音视频等视觉数据作为搜索对象,提取关联信息的资源获取模式,使用户从图书馆视觉资源库中迅速获取其需要的关联内容[2]成为现实。移动视觉搜索(Mobile Visual Search,MVS)相关技术及应用研究对推动图书馆智慧服务发展将产生卓有成效的深远影响,基于深度学习的移动视觉搜索在这一背景下应运而生。大数据环境下的移动视觉搜索包括图像特征提取、区域分割等计算机视觉处理过程,鉴于深度学习技术在计算机视觉方向取得的突破性成效,国内外研究人员对其展开了以下研究。
国外研究人员对移动视觉搜索的研究始于斯坦福大学举办的移动视觉搜索研讨会,主要是从计算机领域涉及到的技术,如特征提取与表示、高维索引与匹配等内容进行研究,如Bernd Girod提出移动视觉搜索的混合型架构,通过对视觉对象局部特征在移动终端的提取和编码,将其传输至服务器,匹配局部特征数据后再将搜索结果反馈至移动终端[3]。在视觉搜索领域应用深度学习技术的研究也取得了一定的进展,如Razavian论证了运用深度神经网络卷积层提取图像特征用于图像搜索的可行性,提出了多尺度图像局部特征提取方法[4]。由此可见,视觉搜索领域的深度学习技术应用已经得到了开拓性进展并具备广阔的开发前景。各大搜索引擎所提供的图像检索功能早已开始应用深度学习技术,甚至在内部成立了研究深度学习的专门机构。实践表明,通过深度学习提取的视觉特征在图像识别、语音识别以及智能监控等领域都获得了较为成功的应用。
国内学者对移动视觉搜索的研究始于2010年,段凌宇等人围绕移动视觉搜索的资源组织方法、资源标准化以及关键技术等问题展开了讨论。随后,数字图书馆领域围绕相关理论与应用模式展开了一系列研究,如张兴旺对数字图书馆移动视觉搜索模型的内涵与架构等问题进行了梳理[5];曾子明结合移动视觉搜索的用户需求,搭建了智慧图书馆的移动视觉搜索服务模型,在论述中提到了深度学习对模型搭建提供的技术支持[2]。
综上所述,将深度学习技术应用于移动视觉搜索领域的研究尚处于起步阶段,相关研究有待进一步深入。将二者相结合作为大数据环境下数字图书馆全新的信息检索模式,有利于解决如何高效处理多模态视觉大数据的问题,显著提升了数据检索与整合效率,将颠覆现有的信息检索工具,成为大数据时代智慧图书馆提升用户服务水平的利器。
2 大数据环境下基于深度学习的移动视觉搜索框架构建的必要性
深度学习技术是机器学习研究领域的前沿热点,对视觉大数据具有强大的非线性表达能力,以及更抽象本质的理解能力,其通过对文本、图像及音频等数据进行建模分析,以人脑的信号处理机制为模拟对象,以繁杂的层次结构对数据实行逐层提取,从而使计算机视觉得以实现[7],即从大量数据中自动提取多层特征,以数据驱动的方式促进了图像识别、信息检索等领域的变革。在多媒体融合的大数据环境下,智慧图书馆的移动视觉数据显现出分散异构、跨模态语义关联的特征,需要移动视觉搜索功能实现对视觉对象的语义感知分析与跨模态融合。深度学习技术对于视觉资源的语义理解具有较为显著的优势,因为多个卷积层与隐层包含在深度卷积神经网络结构中,其可以通过逐层迭代的方式学习图像特征,即从边缘像素等低层特征、物体结构轮廓等中层特征到情感场景等高层语义特征,形成从低层特征至高层特征的映射模型[2],对图像语义特征和语义内容进行提取分析,即通过多层神经网络对视觉资源特征进行训练学习,获取到特征提取更为合理、具有更强区分度的视觉特征语义理解与描述。
移动视觉搜索与深度学习技术的有效融合不仅需要在大数据环境下构建相应的搜索服务模型框架,还需提出可行的技术方案。因此,首先对数字图书馆移动视觉搜索中的深度学习技术需求进行全面分析,构建基于深度学习的移动视觉搜索机制框架,并对其中的技术方法进行研究,为实现大数据环境下的移动视觉搜索服务提供可实施的技术框架。
3 大数据环境下基于深度学习的移动视觉搜索机制框架
如何在不同模态类型的视觉大数据之间建立语义关联,对跨媒体数据进行动态分析和高效处理,实现更为有效的移动视觉搜索模式,是智慧图书馆建设过程中的研究热点之一。笔者构建大数据环境下基于深度学习的移动视觉搜索模型,将深度学习技术框架嵌入移动视觉搜索服务体系,使其服务过程得以高效实现(见图1)。模型架构包含以下主要部分。
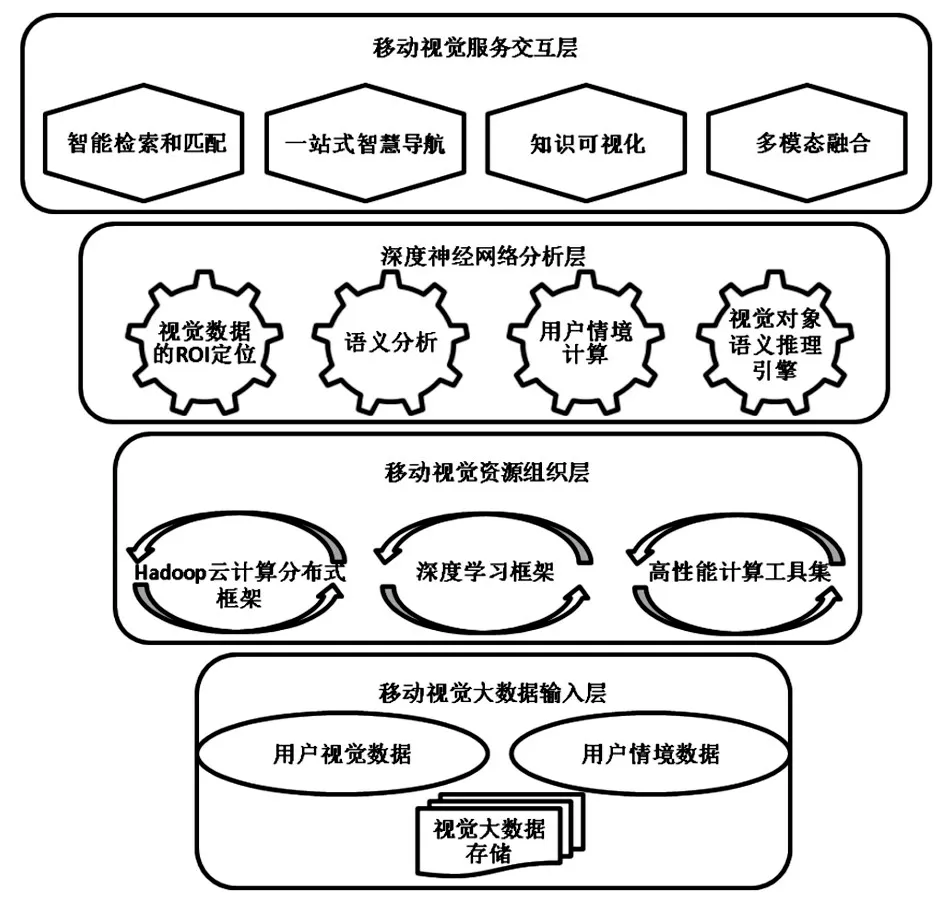
图1 大数据环境下基于深度学习的移动视觉搜索机制框架
3.1 移动视觉大数据输入层
获取移动用户的视觉数据和情境数据,对视觉对象进行分类后根据结果决定视觉大数据资源的存储方案,为视觉搜索服务提供基础数据源。视觉大数据输入层是面向用户移动视觉搜索模型的核心层,其主要任务包括视觉大数据的特征表示,建立不同类型资源之间的语义关联,以及对情境大数据的存储和处理。由于资源类型的差异,输入层首先需要对异构大数据进行整合统一,并通过视觉资源的语义关联功能实现文本数据的特征表示与图像索引之间的关联,在检索获取图像资源后,将相关的文本资源返回,即利用多模态资源对检索内容进行协同表达[8]。情境数据包括用户的网络环境、地理位置、移动终端、检索时间等相关数据,为基于深度学习的移动视觉搜索模型提供数据支持,并将移动终端、物联网等硬件设备与用户视觉大数据相结合,获取用户的情境信息并分析其行为特征,将底层情境数据嵌入到移动视觉索引模块[8],并结合用户需求返回视觉检索结果。
3.2 移动视觉资源组织层
移动视觉资源组织层包含了深度学习框架和高性能计算工具集等,是基于深度学习的移动视觉搜索服务系统的根基。云计算分布式框架以Hadoop文件系统和MapReduce分布式模型为核心,为大数据环境下的移动视觉搜索提供了高效的计算平台。深度学习框架为移动视觉搜索服务的图像特征提取与处理提供有力保障,是开发深度学习算法和训练模型的综合平台。由于深度学习在特征学习与特征表达方面具备突出能力,其通过逐层学习提取多媒体视觉数据的本质特征,可对数据中蕴含的深层语义信息进行揭示。当前主要的深度学习框架有TensorFlow、Caffe和Torch等[9]。传统的数字图书馆云计算平台具有将海量数据分布在大规模集群上并进行处理的能力,然而集群节点的运算能力却无法满足深度神经网络训练测试以及移动视觉搜索服务实时响应的应用需求,可以弥补这一不足之处的高性能计算应运而生,其利用GPU通用计算有效增强集群的并行计算能力,包括可视化、多媒体等多种集成工具,进而提升深度学习框架的运行效率[2]。
3.3 深度神经网络分析层
视觉数据应进行逻辑分析和处理才能为移动视觉搜索功能提供资源支撑,因此,将深度神经网络分析层分为视觉数据的ROI定位、语义分析、用户情境计算以及视觉对象语义推理引擎等功能模块,将视觉图像特征运用深度卷积神经网络进行有效提取,通过特征编码生成视觉图像的描述,再结合用户情境信息与卷积特征对图像进行ROI定位、物体识别分类以及图像的语义分析[2]。在大数据环境下,用户搜索的目的是获取视觉图像的关联信息,其提交图像包含的实体对象所在区域称为兴趣区域(Region of Interests,ROI),通过对搜索图像的ROI定位能够减少目标特征提取的搜索范围和计算量,并有效提高目标物体识别的准确度;语义分析是对移动视觉资源进行语义抽取与分割,描述数据信息与语义信息间的对应关系;用户情境计算主要是分析采集的情境信息,将用户需求与搜索目标通过构建用户情境模型推测出来,并将情境分析结果嵌入到移动视觉搜索服务过程中。视觉对象的语义推理引擎是指在移动视觉搜索的过程中,使用视觉对象知识库的表示方法进行语义关联分析和特征提取的支持,进而实现视觉对象在语义层面的知识推理和服务需求的求解建模[10]以及服务资源和服务能力的最优配置。该功能模块的任务是根据搜索图像的语义标签、特征向量等计算搜索图像与其他数据的相关性,结合用户情境信息与行为偏好对相关资源进行排序并返回筛选结果。在此过程中突显的语义鸿沟问题是限制语义推理准确性的最大障碍。大数据环境下,在数字图书馆移动视觉搜索过程中,语义推理条件、过程以及结果均为动态变化,存在多方面的不确定性因素,为此需要引入逻辑推理算法供用户MVS语义推理引擎调用,通过深度学习技术对用户的视觉搜索需求进行动态模拟与计算推理,以便于得到符合搜索需求的语义分析结果[10],进而为用户需求提供精准的科学算法支持。
3.4 移动视觉服务交互层
服务交互层的主要作用包括用户视觉搜索访问与查询、语义推理等应用和外部软硬件环境的接口与交互,实现智能检索和匹配服务、一站式智慧导航、知识可视化服务以及多模态融合[11]等功能。系统对各种视觉资源的灵活调度和配置,只有通过调用上述应用接口才能得以实现。智能检索和匹配服务能够对多种媒体资源类型进行基于语义的查找和匹配;一站式智慧导航通过分析用户信息需求和兴趣偏好,以及其与平台的交互行为,为用户进行知识推荐与导航服务;知识可视化服务通过视觉表现形式描述和构建知识形态、学科领域、资源主题及其之间的联系,使知识呈现更加生动形象,有助于加强用户理解[12];移动视觉搜索返回的结果可能包含了多种模态的信息资源,多模态融合技术将这些搜索结果进行相关性整合并采用融合的形式向用户呈现。
4 结语
大数据环境下,深度学习以逐层学习的方式寻找高度异构信息的语义关系,通过语义映射与相似度计算,提取移动视觉跨媒体数据的特征,探寻异构模态资源之间的语义关联,使移动视觉搜索程序得以简化,提升了视觉大数据的检索精确度与用户的服务体验,为完善图书馆智慧服务体系提供有力支撑,使用户的个性化检索需求得以满足,进而彰显了图书馆的自身价值并增强了自身的竞争力。因此,在大数据环境下对基于深度学习的移动视觉搜索服务模型及其技术实现方法进行系统研究,具有重要的实际应用价值和学术研究意义。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
北京航空航天大学学报(2022年8期)2022-08-31
快乐学习报·教育周刊(2022年16期)2022-05-01
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
当代陕西(2019年10期)2019-06-03
福建基础教育研究(2019年6期)2019-05-28
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
