
基于ESTARFM NDVI的察汗淖尔流域灌溉耕地提取方法研究*
2021-06-09 00:15陈晓璐王彦芳张红梅刘峰贵沈彦俊
中国生态农业学报(中英文) 2021年6期
陈晓璐,王彦芳,张红梅,刘峰贵,沈彦俊
(1.青海师范大学地理科学学院 西宁 810008;2.中国科学院遗传与发育生物学研究所农业资源研究中心 石家庄050022;3.河北地质大学土地科学与空间规划学院/自然资源与环境遥感研究中心 石家庄 050031;4.河北省农村供水总站 沧州 062152)
在半干旱地区,耕地灌溉面积的扩大导致区域内湖泊干涸和地下水下降等生态问题日益严重。内蒙古高原边缘地带(坝上高原区)地处农牧交错区,具有自然地理环境简单、抗干扰能力差、生态环境脆弱等特点。据《水资源公报》《内蒙古统计年鉴》和《河北农村统计年鉴》统计,该地区近二十年来灌溉面积增加了1倍,机电井增加约1966眼,且用于灌溉的浅井逐渐干涸、报废,浅层地下水浪费严重[1]。刘淑慧[2]在2008年的研究中提到,1996年以前,坝上高原区并没有采取任何节水灌溉措施,均采用传统的大水漫灌方式。并且自20世纪50年代以来流域内湖泊面积不断缩小,大部分永久性湖泊变为季节性湖泊,即时令湖[3]。所以,灌溉虽然能补充农作物因缺水等因素产量较低的缺陷,但也造成了水资源的浪费[4]。此外,该区域也是京津风沙的主要来源地[5],大规模发展灌溉农业使得该流域地下水资源不断耗散、湖泊大量萎缩甚至干涸,土地荒漠化现象严重[6]。基于以上情况,调查灌溉耕地面积的变化可以为该地区农业耗水管理提供关键数据支持。本研究选取内蒙古边缘地带的察汗淖尔流域为研究对象,利用遥感数据提取灌溉耕地的空间分布,探索复杂多样作物种植情况下的灌溉耕地提取方法。
归一化植被指数(NDVI)时间序列在提取灌溉耕地分布研究中应用较早,主要是利用分辨率为1 km的美国国家海洋大气局高分辨率辐射(NOAAAVHRR)和来自SPOT传感器的全球植被覆盖观测(SPOT-VGT)遥感数据[7-8]。随后,又出现对农作物较为精细观测的MODIS NDVI数据,用于灌溉作物区域时空分布的提取[9]。目前发布的灌溉耕地分布产品范围大多为全球,以GMIA2.0-GMIA5.0为代表,方法主要以统计数据的空间分布为主[10]。Pervez等[11]通过将遥感数据和统计数据进行融合,计算NDVI最大值并且与美国农业部(USDA)统计数据进行循环对比,得到美国灌溉耕地分布图。刘逸竹等[12]使用Pervez等[11]提出的方法,提取了中国灌溉耕地的分布,并验证了该方法的应用效果和制图精度误差的原因。潘学鹏等[13]和王红营等[14]通过MODIS NDVI时序曲线探讨了华北平原主要耗水作物的遥感提取方法,并对该方法进行了应用与验证。以上研究用到的AVHRR和MODIS数据具有长时间序列但低空间分辨率的特点,而Landsat数据分辨率较高却受到云和其他因素的干扰导致时间序列上的不足。针对这一问题,Gao等[15]提出了基于MODIS和Landsat数据进行融合得到高时空分辨率数据的自适应遥感影像融合模型STARFM(spatial and temporal adaptive reflectance fusion model)。但该模型在地表覆盖度复杂的情况下预测结果较弱,为改进这一算法,Zhu等[16]在STARFM的基础上提出了增强型时空遥感自适应模型ESTARFM(enhanced spatial and temporal adaptive reflectance fusion model)。郝贵斌等[17]利用ESTARFM算法提取西藏色林错湖2000—2014年湖泊水体面积信息,为时空融合数据在监测湖泊变化方面的应用提供了参考。郭娇[18]利用ESTARFM模型对西安地区植被覆盖度进行了遥感估算并应用到该地区的土壤侵蚀量计算中。刘咏梅等[19]利用ESTARFM融合模型得到陕北黄土高原ESTARFM NDVI时序数据,分析了陕北黄土高原植被覆盖时空变化以及对气候因子的响应。陈梦露等[20]通过ESTARFM模型在新疆地区开展了NDVI的应用,验证了ESTARFM模型在不同区域状况地区的适用性,并且利用生成的30 m时空分辨率NDVI数据进行作物分类和长势检测。
以上学者对该数据融合模型的研究集中在湖泊和植被覆盖的应用中,对于灌溉耕地的提取仅有个例[21]。而坝上高原灌溉耕地面积迅速扩大,对水资源的消耗引发的生态环境问题日益严重。但是该区域耕地种植类型复杂多样,农作物特征识别容易受异物同谱影响,利用分辨率低的MODIS NDVI数据难以获取灌溉耕地的空间分布,Landsat数据又面临时间分辨率低这一困难。基于这一不足,本研究选取典型内流区的察汗淖尔流域,通过提高数据分辨率的ESTARFM融合方法获得研究区内高时空分辨率的NDVI时间序列,利用支持向量机方法提取察汗淖尔流域灌溉耕地的空间分布并验证,以弥补数据源、特征提取等限制因素对复杂灌溉耕地提取的空缺。
1 研究区域概况与数据来源
1.1 研究区域概况
察汗淖尔流域属于内蒙古高原向冀北山地过渡区,包括内蒙古的商都县、化德县、兴和县、察哈尔右翼前旗、后旗、锡林郭勒盟的镶黄旗以及河北省张家口市的康保县、尚义县和张北县部分地区(图1)。由于受蒙古高压的长期控制,形成了低温、少雨、多风、高蒸发的气候特征。年均气温−0.3~3.7 ℃,年降水量小于400 mm,年均水面蒸发量达1735.7 mm,为降水量的4.75倍[22]。农作物以“一薯两菜”特色产业为主,受旱状况十分严重。除天然降雨外,通过灌溉补充农作物所需要的水分以及提高产量是该流域内普遍的措施。
1.2 数据来源
本研究所用遥感数据主要为美国地质调查局(http://glovis.usgs.gov)空间分辨率为30 m的Landsat OLI数据,选取2017年4月、8月、9月的3幅影像,云量小于10,行列号为125/31。经过辐射定标、大气校正等数据预处理后计算NDVI,并将4月和9月作为ESTARFM模型的输入数据,8月作为结果的验证数据。MODIS数据是MOD09Q1产品,来自美国国家航天局(https://ladsweb.modaps.eosdis.nasa.gov/),分辨率为250 m和8 d。利用MRT(MODIS Reprojection Tool)重新投影为UTM-WGS84后,选择红外波段(b1)和近红外波段(b2)计算NDVI,在ENVI中进行裁剪、重采样后与Landsat分辨率、像元大小与投影方式保持一致作为ESTARFM模型的另一输入数据。融合后的结果利用来自FROM-GLC10 v0.1全球土地覆盖产品(http://data.ess.tsinghua.edu.cn/)提取耕地作为掩膜后进行作物分类,最后利用实地调研数据对提取结果进行验证。
2 研究方法
2.1 ESTARFM模型算法
增强型自适应反射率时空融合模型(enhanced spatial and temporal adaptive reflectance fusion model,ESTARFM)是在STARFM上进行升级,改进地表异质性对数据融合产生误差的缺点[23],以提高目前存在的空间分辨率低的现状。其原理主要是针对混合像元的问题,充分考虑临近像元和目标像元之间的地理距离、光谱距离和时间距离之间的异同[16],计算出目标时期的Landsat影像。将Landsat和MODIS影像传感器之间的偏差最大程度地减小从而进行时空分辨率融合运算[15],融合后的NDVI数据弥补了因空间分辨率低像元识别困难和时间分辨率低作物生育期变化曲线难以完整获取的不足。ESTARFM模型先后输入两组对应日期的高空间、低时间和高时间、低空间影像,以及要预测的目标日期对应的MODIS影像数据,从而模拟出研究所需要的缺失遥感影像。假设两组影像之间的反射率差异仅仅是由不同影像之间地表反射率存在的偏差引起,且在两个时期之间影像并未产生较大差异[13],如公式(1)所示:
式中:L、M分别表示Landsat与MODIS影像,(x,y)为像元位置,B表示影像各波段,to、tp分别为两幅影像相对应的时间,a为转换系数,其值由传感器之间系统偏差所引起。
考虑了复杂的地表覆盖情况,在公式(1)基础上加入能反映具体像元反射率变化的转换系数如公式(2)所示,通过设置移动窗口自动搜索每个相似像元进行加权总和得到能预测不同地表覆盖下2个日期之间的任一时间影像,如公式(3)所示。
式中:v(x,y)是混合像元第i个相似像元的转换系数,N是预测的相似像元总数,(xi,yi)是第i个相似像元的位置,W是第i个相似像元的权重,vi是第i个相似像元的转换系数。
第1个时期m时刻Landsat与tp时刻的MODIS来预测tp时刻Landsat影像的反射率,记为,第2个时期n时刻的两幅影像与tp时刻的Landsat影像的反射率,记为[24-26]。
将以上两个预测结果进行加权计算得到更加精确的tp时刻Landsat影像的反射率。根据tm和tn与预测时刻tp之间MODIS影像反射率的差异计算权重,如公式(4)所示。
由公式(5)预测中心像元反射率。
Landsat和MODIS数据经过预处理后作为ESTARFM模型输入数据,经过计算得到预测日期的MODIS NDVI后与真实Landsat NDVI进行验证。ESTARFM模型有IB(index-then-blend)和BI(blend-then-index)两种方法,IB是利用原始遥感影像计算所需指数,再将计算好的指数输入到模型中;BI是将原始遥感影像输入到模型中,得到融合后的影像再计算所需指数。由于运用ESTARFM模型时IB准确性高且计算时间短[23],所以本研究通过ESTARFM-IB方式进行NDVI预测。
2.2 基于支持向量机的灌溉耕地提取方法
支持向量机(support vector machine,SVM)是监督分类中用于遥感影像分类的机器学习算法[27],在最大程度减小误差的基础上进行最优分类。通过选择训练样本实现遥感影像提取不同地物类型的结果,在区域尺度研究中有重要应用[28]。支持向量机适用广泛,除了对遥感影像进行特征识别、提取外,还可以应用于人脸识别和文本识别[29]。并且在训练样本不足的情况下依然能达到误差较小的分类结果[30]。
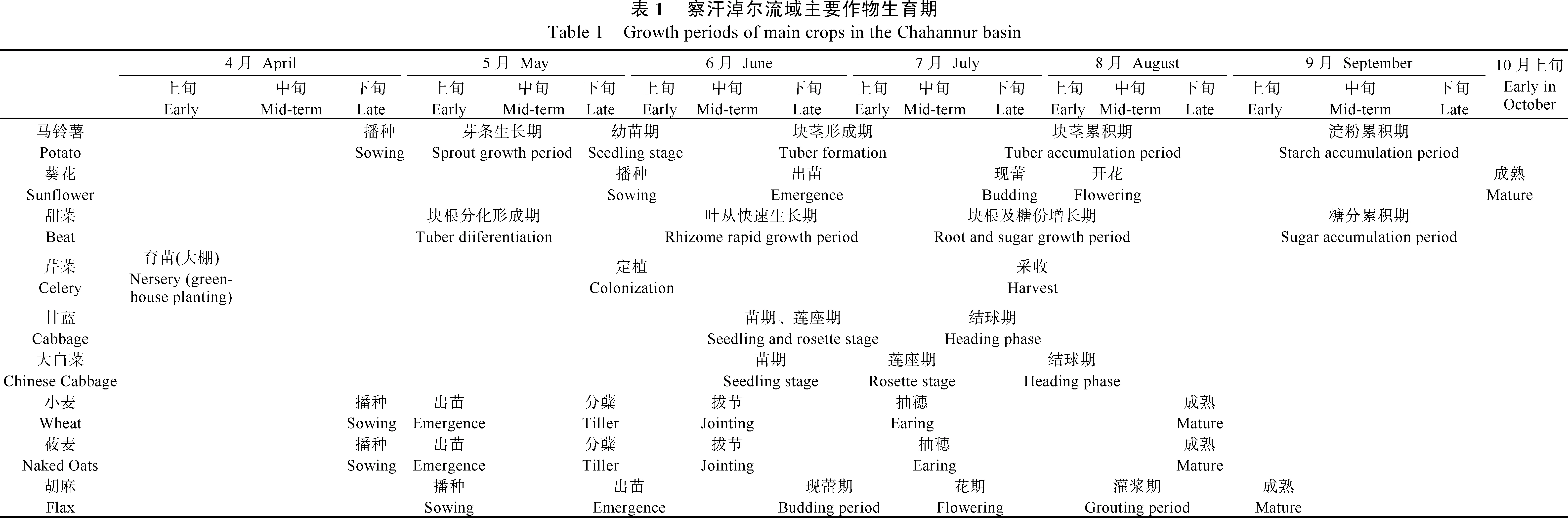
本研究根据数据融合模型ESTRAFM模拟得到的NDVI时间序列数据变化特征,选择灌溉耕地和雨养耕地样本。灌溉耕地主要种植马铃薯(Solanum tuberosum)、甜菜(Beta vulgaris)、葵花(Helianthus annuus)和一些蔬菜[芹菜(Apium graveolens)、萝卜(Raphanus sativus)、甘蓝(Brassica oleracea)和大白菜(Brassicapekinensis)],雨养耕地主要种植莜麦(Avena sativa)、小麦(Triticum aestivum)和胡麻(Sesamum indicum),这些主要作物的生育期见表1,蔬菜的生育期均为5月下旬到8月上旬,各生育阶段接近,NDVI曲线没有明显差别,后面的结果提取没有具体划分。莜麦、小麦和胡麻的生育期均在4月下旬到8月下旬,NDVI变化趋势较为一致难以区分,因此将其作为雨养耕地这一大类进行提取。其中,灌溉耕地作物在生长期进行分阶段灌溉,NDVI曲线上升快,先达到峰值,雨养耕地作物在前期生长较慢,峰值靠后。根据这一变化趋势并结合作物生育期数据,通过ESTARFM数据融合模型得到的NDVI时间序列曲线,选择共353个训练样本点并进行分离度检验,其分离度计算结果达1.9则表明所选的样本分离性较好,可以进行分类。若分离度计算结果小于1.8,则需要重新选择训练样本[31]。将分离度大于1.9的样本输入支持向量机,通过在内部建立的最优函数进行特征识别,选择最合适的核函数求解[32],最后得到分类结果并进行精度验证。
2.3 精度评价方法
混淆矩阵通常用于遥感数据分类结果的精度评价[33],通过建立n行n列的矩阵来清晰表达正确分类样本与错分、漏分误差,并且构建总分类精度(overall accuracy,OA)、Kappa系数、用户精度(user accuracy,UA)和制图精度(producer accuracy,PA)4个指标来评价其分类结果的精度[34],具体公式如下:
?
式中:OA表示每一个样本的分类结果与真实样本一致的概率;xii为i类样本正确分类的像元数量;N为对应像元总量;ix+为验证样本中i类的像元总数;x+i为分类结果中i类的像元总数。K值越大,表明分类结果与实际结果越接近,<0.4则表示结果无效;UA表示某一分类结果相对于实际结果的精确度;PA表示实际结果的任意像元,即分类结果与其一致的概率。
3 结果与分析
3.1 ESTARFM模型融合结果与分析
为验证ESTARFM模型融合结果的精度,选取2017年4月3日、2017年9月10日的Landsat NDVI影像和2017年4月3日、2017年9月10日的MODIS NDVI影像以及预测日期2017年8月25日的MODIS NDVI作为ESTARFM模型输入数据,得到2017年8月25日的ESTARFM NDVI,利用2017年8月25日的真实Landsat NDVI对融合结果进行验证。
图2显示融合的结果与真实影像较为一致,整体上各地物类型识别效果较好。但由于2017年9月10日的Landsat影像受到云量干扰,导致融合结果也出现相应位置的云分布。利用来自FROM-GLC10 v0.1全球土地覆盖产品提取的耕地进行掩膜,掩膜后的结果并不影响分类(图3)。为进一步验证融合的精度,选取细节部分进行观察。从细节图中可以看到,各地物类型的轮廓和纹理基本一致,对应像元NDVI值吻合。
耕地掩膜后的Landsat NDVI和ESTARFM模型融合结果的相关性散点图如图4所示,散点基本分布在1∶1趋势线两侧,较为集中。二者的相关性达0.94,表明融合结果能较好地反映Landsat NDVI光谱信息,可以作为后续灌溉耕地提取的基础数据。此外,还通过ENVI计算Landsat NDVI和ESTARFM NDVI差值直方图,得到像元差值个数的分布基本集中于0,表明实际NDVI和融合得到的NDVI像元大多数无差异,二者相似度极高。
3.2 基于ESTARFM NDVI的耕地植被生长季曲线特征
根据察汗淖尔流域气候和作物生长情况,利用ESTARFM模型融合得到2017年4月3日到10月16日共25景高时空分辨率的ESTARFM NDVI影像(图5)。为了减少与耕地相邻像元(如草地和林地)对灌溉耕地提取的影响,将FROM-GLC10 v0.1全球土地利用覆被数据在ArcGIS中导出耕地,通过IDL进行NDVI时间序列的耕地掩膜,最后得到2017年4月到10月耕地NDVI。由于获得的遥感数据受到云、水汽、气溶胶等因素的干扰,在ESTARFM模型融合时只能减少这些干扰而不能消除,因此得到的NDVI时间序列数据波动强烈。为了在时间维度上对模型融合得到的NDVI时间序列数据进行信息提取和趋势分析,需要进行NDVI平滑重构。本研究选用HANTS(Harmonic Analysis of NDVI Time-Series)滤波和S-G(Savitzky-Golay)滤波对ESTARFM NDVI数据进行平滑重构,发现HANTS滤波效果更好(图6),其处理后的变化趋势与MODIS NDVI基本一致。
察汗淖尔流域作物生长发育集中在4月上旬到10月上旬。大多数作物均为一年1熟,NDVI只有1个峰值。本研究均使用年积日(DOY)表示日期,NDVI值从5月1日(DOY-121)开始上升,葵花、甜菜、马铃薯等生育期长的作物在7月30日(DOY-211)到8月25日(DOY-237)间达到峰值,是作物的生长期。之后开始下降,到10月16日(DOY-289)下降到0.3左右,是作物的成熟收获期;蔬菜生育期较短,在7月下旬(DOY-200以后)达到峰值,之后NDVI值开始下降接近于0;雨养耕地的作物生长期NDVI值上升平缓,且最大值小于0.5,生育期为5月初(DOY-123)—10月初(DOY-289)。以上研究说明ESTARFM模型预测的NDVI能够表示实际作物的NDVI变化趋势。
3.3 基于SVM分类结果精度验证
为使验证点和影像相对应,在影像上选取与大片耕地集中分布相邻近的39个村庄(包括商都县16个村、兴和县6个村、尚义县12个村、康保县5个村)作为问卷调查地,同类作物种植面积大于50 m×50 m的农田作为采样点,将选取的灌溉耕地(包括马铃薯、甜菜、葵花和蔬菜)和雨养耕地(小麦)的实地采样点在ArcGIS中进行矢量化,导入谷歌地图中作为选取验证样本点的参考,最后根据实地样点的纹理、颜色等特征在谷歌地球中选择灌溉耕地和雨养耕地共348个样本点作为SVM分类结果精度验证的样本点(图7)。混淆矩阵结果见表2,灌溉耕地提取的总体分类精度为93.18%,Kappa系数为0.91,说明SVM提取灌溉耕地的结果比较理想。小麦和甜菜的制图精度最高,为96.23%,蔬菜较低,为85.45%,主要原因是蔬菜为错季作物,有少部分出现一年两季的情况,这使得NDVI时间序列曲线不能准确识别其物候变化导致误差较大,加上NDVI到达峰值前后的时间不稳定也使得漏分误差较大,为14.55%;雨养耕地的用户精度较低,为87.93%,主要原因是雨养耕地作物种类复杂,分布不集中,以小麦、莜麦、胡麻和黍子(Panicum mili-aceum)相间种植易出现异物同谱现象,并且这些作物生育期也相近,错分误差较大,为12.07%。但总体来看,由ESTARFM融合后的NDVI能较好地识别不同作物覆被类型下的变化情况,对于复杂农作物种植下的耕地提取有较高适用性。

表2 研究区不同类型作物的支持向量机(SVM)分类结果混淆矩阵Table 2 Confusion matrix of Support Vector Machine(SVM)classification results of different types of crops in the study area %
3.4 基于SVM的灌溉地提取
根据ESTARFM NDVI结果,选取灌溉耕地样本利用SVM对察汗淖尔流域不同灌溉地类型的空间分布进行提取,结果如图7所示。可以看到流域内以种植马铃薯、葵花、甜菜等灌溉作物为主,还有部分单季蔬菜和少量的双季蔬菜。经统计:2017年察汗淖尔流域耕地总面积3348.69 km2,灌溉耕地总面积1958.24 km2,雨养地总面积1390.45 km2,流域内以灌溉耕地为主,分布均匀;商都、兴和、尚义、康保和化德的灌溉耕地占流域总面积的94%,张北、察哈尔右翼前旗、后旗和镶黄旗占6%,其中商都县灌溉耕地面积616.67 km2,雨养耕地356.02 km2,其北部地势较高地下水抽取困难,雨养耕地分布为主;灌溉耕地主要分布在地势低平的东南部,靠近察汗淖尔湖分布密集,其余地方分布稀疏。根据NDVI时间序列变化曲线,商都县主要种植马铃薯、向日葵、甜菜等长生育期农作物。NDVI曲线前期生长快,但生育期长,大约在200 d(DOY-200)左右达到峰值,之后缓慢下降,在280 d(DOY-280)左右收割。兴和县灌溉耕地面积337.36 km2,雨养耕地154.40 km2。农作物种植类型以及NDVI变化趋势和商都县一致,流域内基本以灌溉耕地为主。尚义县灌溉耕地共409.85 km2,雨养耕地191.24 km2。流域内灌溉耕地分布比较均,是蔬菜的主要分布区,主要蔬菜类型有甘蓝、花菜(Brassica oleracea)、娃娃菜(Brassica campestris)、白萝卜(Raphanus sativus)和胡萝卜(Daucus carotavar.sativa),因其生育期基本一致所以将其作为一类提取。从NDVI曲线可以看到,蔬菜生长前期其值直线上升,200 d(DOY-200)左右达到峰值后迅速下降,253 d(DOY-253)后基本收割完毕,生育期相对较短。康保县灌溉耕地290.93 km2,雨养耕地309.86 km2,种植类型与商都县、兴和县一致。化德县灌溉耕地239.38 km2,雨养耕地281.13 km2,化德县地势相对较高,耕地主要集中在东部,灌溉作物以葵花、甜菜、马铃薯等为主。张北县、察哈尔右翼前旗、后旗以及镶黄旗灌溉耕地共64.05 km2,雨养耕地共97.78 km2,在流域内范围较小不予讨论。察汗淖尔流域内雨养耕地作物为莜麦、小麦、胡麻和黍子,NDVI曲线前期增长缓慢,在246 d(DOY-246)左右达到峰值,之后缓慢下降,收割日期和灌溉耕地相差无几。
4 讨论与结论
当前利用遥感提取灌溉耕地空间分布的技术主要受数据时空分辨率的限制,因此本研究利用ESTARFM数据融合模型预测了高分辨率、长时间序列的NDVI提取察汗淖尔流域耕地空间分布。该模型在地表覆盖复杂的情况下能很好地预测不同像元反射率,但受制于输入的已知时期相对应的MODIS和Landsat数据质量以及预测日期的MODIS数据[16]。本研究选取的遥感数据云量均小于10%,避免了大量云污染造成预测NDVI的误差。使用FROM-GLC10 v0.1进行耕地掩膜,减小了异物同谱现象,提高了分类结果的精确度。但由于流域内作物种植地块的破碎化与多样化,选取灌溉耕地错季蔬菜这一作物样本时并没有将每一具体类型区分出来,只能将生育期几乎相同的各类蔬菜作为一大类进行提取,这一结果的不足与误差需要今后进一步研究[35]。而相对于干旱地区,湿润地区由于作物生长茂盛,其NDVI容易达到饱和,对灌溉耕地和雨养地的区分误差较大[10]。有证据表明在英国Louth郡[36]和泰国Suphanburi府[37]NDVI区分灌溉作物和雨养作物时并没有明显差异。也有研究者认为气候干旱年降水量小于400 mm的地区只能依靠灌溉发展农业[38],因此使用NDVI这个单一特征不足以提取农作物空间分布。基于此,其他特征参量如EVI(Enhanced Vegetatin Index)、GI(Green Index)或者WDRVI(Wide Dynamic Rang Vegetation Index)[39]或许能更好地表达灌溉耕地和雨养地的差异。此外,在NDVI基础上加入其他特征参量能够在多条件约束下对灌溉耕地综合提取。董婷婷等[40]和Xie等[41]分别加入WDI(Water Deficit Index)和EVI、GI以及LST(Land Surface Temperature)进行了灌溉耕地的提取并进行了验证。本研究对数据融合后的NDVI曲线进行HANTS滤波后能有效识别出灌溉耕地和雨养耕地,利用像元反射率异同这一性质提取时能表达更加详细的信息。主要结论如下:
1)通过ESTARFM数据融合模型得到2017年8 d为间隔的30 m分辨率NDVI数据,误差主要是由于Landsat数据受云污染的影响较大,时间序列的Landsat难以获取,经过验证预测ESTARFM NDVI与真实Landsat数据的NDVI相关系数为0.94。
2)基于融合的NDVI时间序列数据,选取葵花、甜菜、马铃薯等长生育期作物、蔬菜和雨养耕地作物的训练样本,得到流域内耕地的空间分布结果。流域内耕地总面积为3348.69 km2,主要分布在商都、兴和、化德、尚义和康保县内。其中商都县灌溉耕地面积616.67 km2,主要种植葵花、甜菜、马铃薯和蔬菜;化德县和兴和县灌溉耕地面积分别为239.38 km2和337.36 km2,灌溉耕地多集中分布于地势平坦处,其灌溉作物均与商都县类似;尚义县和康保县灌溉耕地分别为409.85 km2和290.93 km2,灌溉耕地以蔬菜这一短生育期作物为主,马铃薯、甜菜、葵花等长生育期作物较少,其余为雨养耕地;张北县、察哈尔右翼前旗、后旗和镶黄旗灌溉耕地共64.05 km2,占流域灌溉耕地面积比例较小。
3)利用野外调查真实样本对分类结果进行混淆矩阵计算,得到总体分类精度为93.18%,Kappa系数为0.91。灌溉耕地和雨养耕地的平均制图精度分别为91.48%和96.23%,平均用户精度分别为94.67%和87.93%。商都、兴和、尚义、康保和化德5县的灌溉耕地占整个流域面积的94%,而张北、察哈尔右翼前旗、后旗以及镶黄旗占耕地总面积的6%,这4个县因为流域内面积较小选择样本困难,因此是误差的主要来源。
由以上结论可知,本研究通过数据融合模型得到的NDVI通过SVM进行灌溉耕地提取的方法有效,在干旱半干旱地区适用。但此方法只提取了2017年灌溉耕地的空间分布,缺乏长时间序列的空间分布。基于以上研究的不足,未来还需要探究长时间序列灌溉耕地的变化,从而得到灌溉耕地时空分布与水资源利用相关关系,为区域内节水问题提供研究基础。
猜你喜欢
中国化肥信息(2022年8期)2022-12-05
今日农业(2022年13期)2022-11-10
中国农业气象(2022年1期)2022-02-11
作物学报(2022年3期)2022-01-22
今日农业(2021年14期)2021-11-25
大豆科技(2021年4期)2021-11-19
现代园艺(2021年18期)2021-11-09
云南农业(2021年10期)2021-10-22
云南农业(2021年9期)2021-09-24
云南农业(2021年8期)2021-09-06
