
融合知识图谱与深度学习的文物信息资源实体关系抽取方法研究
2021-06-07 06:15彭博
现代情报 2021年5期
彭博
关键词:知识图谱;深度学习;文物信息;关系抽取;BERT;BiLSTM;知识发现
中华文化上下五千年传承,诞生了无数璀璨的文化瑰宝,文物作为其中重要的产物之一,有着巨大的研究价值。同时,文物研究工作中产生的大量信息资源蕴含了无数的文化知识.但是这些信息资源多以非结构化数据为主,知识往往隐含在众多非结构化语料之中。如何全面与精确地挖掘及发现文物信息资源中的知识,成为了传承和推广中华文化所面临的首要问题。
同时,随着人工智能的迅速发展,自然语言处理技术的相关研究也取得了显著进展。在以数字人文为导向进行人文及历史研究的今天,文物信息资源中的结构化数据已无法满足学者们进行文物知识挖掘、关联与利用的研究需要。如何从非结构化的古籍文本、现代研究论文、各類型百科词条中发现、挖掘、关联并进行知识的深度利用,成为了数字人文相关学科亟待解决的重要问题。实体之间的关系作为知识的基本载体,成为进行知识开发与利用的源数据.如何抽取信息资源中的文物实体关系,成为了进行数字人文有关研究的基础。文章以文物信息资源为研究对象.使用知识库数据构建文物知识图谱进行实体及实体关系的自动标注,通过BERT-BiLSTM-ATF模型进行实体关系抽取,在实体关系抽取与发现的实验中取得了较好的效果,为文物信息资源中知识的利用提供了数据基础。
1相关研究
1.1文物信息资源国内外研究现状
目前国内外有关文物信息资源的研究以结构化数据的发布、存储与开发利用为主,主要集中在文物元数据标准的制定、领域本体的构建以及结构化数据中文物知识关联关系的挖掘与利用。文物元数据的有关研究由概括性质的元数据标准细化而来,如针对网络资源的都柏林核心(Dublin Core)元数据标准成为后来众多标准制定及复用的基础。还有如盖蒂研究所发布的艺术品描述类目(CDWA)成为了众多文物元数据标准制定时的参考。国内学者龚花萍等融合以上多种元数据标准,提出了针对文物信息资源元数据的著录标准,构建了针对文物信息资源的元数据模型。艾雪松等则进一步细化,使用标准复用等手段,依据博物馆文物信息资源的特点构建了针对博物馆文物信息资源元数据模型。文物领域本体构建则是针对某一个或者某几种特征较强.难以复用某一类文物元数据标准进行的文物信息共享标准制定。如张华等针对湖北唐崖土司城遗址中的“荆南雄镇”石牌坊结合文物元数据标准与文物特征构建了文物信息本体,实现了文物要素之间的语义关联。Hyvionen使用关联数据有关技术构建与整合了文化遗产领域本体.为进行文物信息资源语义的相关研究提供了数据基础。文物语义相关的研究中,Tsai C M等使用情境感知等方法试图将非结构化文物信息资源转换为文物元数据的著录格式。也有Boer VD等以阿姆斯特丹博物馆为例,将博物馆中文化信息资源通过关联数据有关技术转化为具有语义的结构化数据。曾子明等从数字人文角度针对文化遗产的多媒体资源、视频资源中的潜在语义关联进行了文物知识组织研究。
从以上的国内外研究现状不难发现,目前文物信息资源中结构化数据的有关研究已取得丰硕成果,但受自然语言处理、实体识别、关系抽取等研究发展的限制,针对非结构化数据的研究较少。如何将非结构化数据的研究成果应用到非结构化数据中将会成为文物信息资源研究的发展趋势。
1.2深度学习与关系抽取的国内外研究现状
关系抽取的主要目的是从非结构化数据中提取具有语义关系的实体与实体间关系,目前主流的关系抽取方法分为有监督的学习方法、半监督的学习方法与无监督的学习方法。与其他两种方法相比,有监督的学习方法能够更有效地进行特征抽取,其准确率和召回率更高。深度学习是有监督学习的关系抽取研究中的关键技术,Miller S等采用增强解析树联合训练诃性识别、实体识别、句法分析、语义解析4个步骤抽取句子级别中的实体关系。Mooney R J等基于核方法通过一个实体将一个句子分为前、中、后3部分进行训练,更加精细地得到实体特征,提高了关系抽取的准确率。Mintz M等开创性的将远程监督运用于关系抽取,该方法假设两个实体在知识库中存在关联关系,当这两个实体在同一个句子中时,该句也在表达这种关系,这种方法解决了有监督学习方法中语料标注的问题,但同时也会制造一定噪音。Zeng D等使用卷积神经网络进行关系抽取.采用词向量作为卷积神经网络的输入,通过卷积层、池化层和非线性层得到句子表示,依据实体的位置向量和词汇特征进行关系抽取。Xu Y等使用LSTM进行关系抽取,通过找到两个实体在依存树中的最短路径可以有效提取关键信息.对这两条路径进行特征提取得到关系分类的结果进行实体关系抽取。预训练模型的出现为深度学习与实体关系抽取提供了新的思路.即通过预训练模型使用更少的数据进行学习,通过引入自注意力机制在泛化的应用场景中进行高效的实体关系抽取。
将深度学习用于实体关系抽取可以从文本中识别实体并抽取实体之间的语义关系,所得结果能够将非结构化数据转化为结构化数据,为后续的语义挖掘以知识利用提供数据基础。但同时可以看到,针对文物信息资源中实体关系抽取的研究较少,文物元数据所具有的标准化、唯一性、关联性特征能够为实体标注、关系标引提供良好的数据支撑,文物领域能够成为深度学习及关系抽取的一个较好的研究方向。
2基于深度学习的文物实体关系抽取模型
2.1文物知识图谱的构建
使用深度学习进行文物实体关系抽取的首要问题就是实体与实体关系标注,要标注句中存在的实体及其关系首先需要从事实中获得实体名称及实体间的关联关系。知识图谱的出现为实体及其关系的获取提供了解决方法.“实体1一关系一实体2”的三元组表示形式能够自动标注句中存在的实体,并为关系标注提供额外信息。文章从两方面数据来源构建面向研究对象的文物知识图谱,其一是利用网络知识库如维基数据(Wikidata)、中文通用百科知识图谱(CN-DBpedia)以文物信息资源描述对象为检索人口,通过SPARQL查询得到与研究对象有关的实体的三元组集合转换为RDF中的(S,P,O)三元组。
在得到三元组集合后,使用数据清洗、去重等手段通过图模型将三元组中的实体及属性映射为节点和边,,边E的标签表示为P,构建面向研究对象的文物知识图谱。
2.2信息资源中文物实体及关系标注
实体及关系标注是进行深度学习关系抽取的前提.由于仅依靠实体名称进行实体标注存在的重名等问题会导致标注错误.使用两个或两个以上具有关联关系的实体名称进行联合标注则可以降低错误概率。因此文章以句为单位,若句中存在两个字或词与知识图谱中的实体名称一致,则相应将其对应知识图谱中的节点名称标注为(E1,E2),实体关系标注为V若句中存在两个以上字或词与知识图谱中的实体名称一致时,则依次选取在知识图谱中节点距离为1的节点名称进行标注,标注为(E1,E2)、…、(E,E),实体关系对应标注为、而当知识图谱中部分节点间属性为“别名”“字”“号”等表示两节点指代同一实体时,则在实体及关系标注时认为这些节点距离为0进行标注以增加对同一实体的标注精度。为了避免出现实体与名称不符的情况,文章控制知识库中进行实体再检索的次数.这样一方面能够保留与文物实体关系紧密的实体;另一方面通过控制知识图谱的网络规模降低重名实体出现的概率。
2.3关系抽取模型构建
关系抽取实际上可以被看作是一个分类问题,即给定两个实体及其共同出现的句子,根据给定的属性将实体关系进行分类。进行关系抽取需要经过字、句向量生成提取文本特征和使用神经网络提取语义两个步骤。在文本特征的提取中文章使用预训练模型BERT其利用Transformer Encoder与Self-attention机制,可以更好地描述上下文的语义特征。BERT相较于Word2Vec等仅通过词及窗口范围进行训练获取词向量的方法,加入了NextSentence Prediction与Masked-LM进行联合训练,从而能够获取句子级别的语义特征。该模型是一种基于百科语料预训练的具有泛化应用场景的语言模型.无需进行二次训练便可以直接使用,输入是语料中字或者词,输出的是文本中各个字或词融合句子语义特征后的向量表示,由此形成的预训练向量在许多自然语言处理任务中表现出了良好的性能,尤其针对小样本环境下的自然语言处理任务。
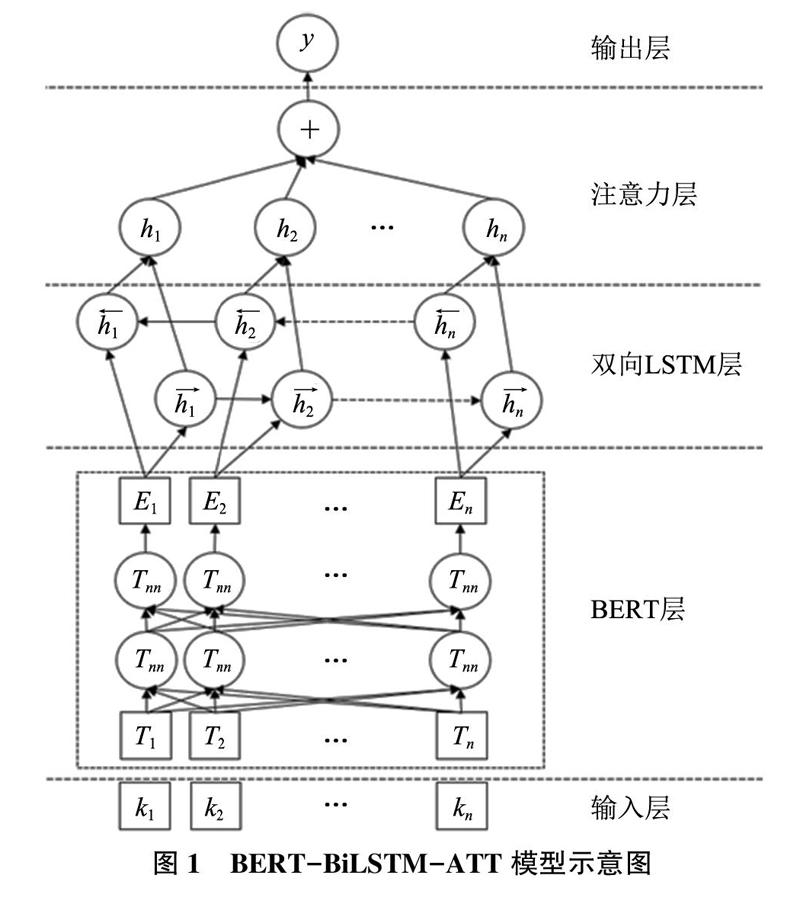
在高层语义特征的提取上文章选择长短记忆神经网络模型(LSTM)进行,该模型既能更好地处理序列数据,又能够处理循环神经网络(RNN)中序列过长引发的梯度消失问题。LSTM每个隐藏层中包含了遗忘门、输入门及输出门。文章加入由单向的、方向相反的两个LSTM的状态组成神经网络.输入经过两个方向相反的LSTM,而输出则由这两个LSTM共同决定双向门控循环单元(BiL.STM)来进行文本深层次特征的提取。而为了减小文物信息资源中长输入序列对神经网络模型学习效果的影响,文章加入注意力机制(ATT)择性地筛选输入中的对应的有关信息,并将输出序列与之关联以提高输出序列的准确性。最终如图1所示,神经网络关系抽取模型分为5层,分别是输入层、用于文本特征提取的BERT层、进行深度学习的双向LSTM层、注意力层及输出层。
3实验
为了验证知识图谱与深度学习融合方法在文物信息資源实体关系抽取中的效果以及进行未标注实体关系发现的能力,文章以中国十大传世名画之一的北宋风俗画《清明上河图》的百科类型文物信息资源为例进行实体关系抽取研究。
3.1数据采集与预处理
文章以文物信息资源文本的来源分类,选定《清明上河图》有关的百科类型文本为数据来源,包括百度百科、维基百科、搜狗百科等关于“清明上河图”的介绍以及网络问答社区“知乎中关于“清明上河图”话题的回答共50篇文本为研究对象。
在文物知识图谱构建方面,文章在Wikidata知识库中以“清明上河图”(编号Q714802)进行检索.随后检索结果中的实体为人口进行了3次再检索共得到RDF三元组380对。随后,在中文知识库CN-Dbpedia中以“Named-Entity Disambigu.ation:清明上河图(北宋张择端风俗画)”同样对检索结果中的实体进行了3次再检索得到RDF三元组108对,经去重得到含有401个节点、409条边的“清明上河图”知识图谱,结果如图2所示。
3.2文物实体与关系标注
不同知识库对实体间关系标注的名称不尽相同,在进行文物实体关系标注前需针对这些关系依照统一的标准进行对齐,否则会造成同一关系因为不同名称的标注而出现歧义。同时依据已有的元数据标准对类似的实体关系进行归并能够减少小样本数据中实体关系种数,增加同类关系在语料中的集中度,提高神经网络的学习效果。
因此,文章根据知识图谱中节点及节点关系以句为单位依照前文中的方法进行标注,参考都柏林核心(DC)、艺术品描述类目(CDWA)、地名本体(GeoNames)元数据标准中的一级元数据元素对知识库中提取的实体关系进行归类合并,将知识库提供的25种实体关系归并为6大类,归并结果如表1所示。以句为单位,依照“实体1”“实体2”“关系”及关系所在句子的格式,共自动标注实体关系508条.其中时间关系141条,作者关系121条,位置关系81条,属性关系58条,内容关系57条,收藏关系50条。
为了研究文章模型在百科类型信息资源中文物实体关系抽取的效果,文章通过人工标注的方式对实验语料的50篇文本中的实体关系进行标注以加入测试集,经过对比在原有508条自动标注的实体关系,人工标注增加了77条经知识库中未收录的实体关联关系.其中时间关系14条,作者关系11条,位置关系11条,收藏关系11条,内容关系5条,属性关系25条。
3.3实验结果及分析
文章实验平台为CPU:17-9750H,内存:16GB,显卡:GTX-1660Ti,显存:6G,实验环境为Python3.6、TensorFlowl.13.1、Keras2.4,BERT预训练模型选取BERT-base-Chinese,共110M个参数,768个维度。训练时,最大序列长度采用样本中句子的最大长度278.train_batch_size为16,droup_out_rate为0.2,learning_rate为0.02,BiL-STM隐藏层维数为128,Epochs设置为30,但由于实验为小样本,为了防止过拟合,文章加入Ear-ly Stopping机制,连续5个Epoch未达到最佳精度则停止。
为检验模型在实体关系抽取中的效果,文章采用精确度(Precision,P)、召回率(Recall,R)和F1(F1-score)值作为度量指标。精确度代表被预测为正样本的正确率.召回率代表实际为正样本被正确预测的比例,F1值为两种指标的调和平均值,模型的综合抽取效果与其值正相关。
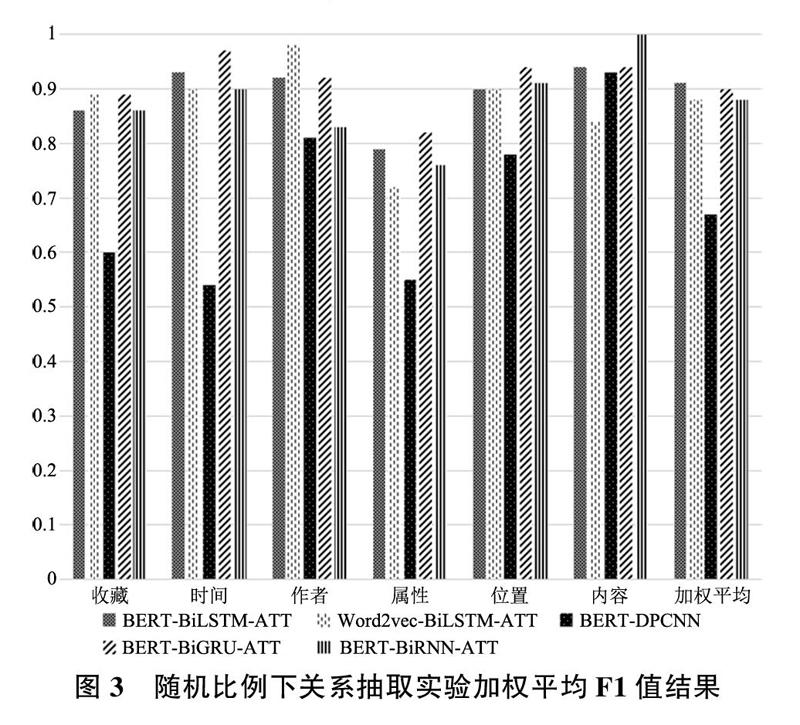
文章首先将自动标注的实体关系按8:2的比例随机划分为训练集与测试集,再将人工标注中知识库未收录的实体关系随机选取20%加入测试集中,最终训练集中实体关系为406,测试集中实体关系为118.将文章方法与另外4种实体关系抽取方法进行对比,探究模型对于文物实体关系的抽取能力,其结果如图3所示,“时间”关系与“位置”关系F1值相对较高,这一方面是由于时间与位置信息的名称相对标准,关系特征明显;另一方面也说明文物信息资源中有关“时间”与“位置”关系所描述的内容较为一致,使用深度学习的方法能够较为准确地识别和抽取该类型关系。同时“内容”关系是与《清明上河图》有关内容的描述,其承载信息有限,使得“内容”关系的抽取也取得了较好的效果。为了对比实验结果,文章加入双向循环神经网络(BiRNN)、双向门控循环单元(BiG.RU)、深度金字塔卷积神经网络(DPCNN)进行对比。BiRNN使用Keras中的SimpleRNN函数进行实现,BiRNN和BiGRU参数与BiLSTM一致。同时为了研究BERT预训练模型在提取字符级别特征中的效果,文章选择整合了百科及新闻语料的中文词向量进行对比,采用Skip-gram进行训练,词向量维度为300,窗口长度为5。从结果上看,BERT-BiLSTM-ATT方法抽取效果最好,但其与使用循环神经网络有关方法抽取结果间差距不大.BiLSTM、BiGRU、BiRNN 3种方法获得的加权平均F1值分别为0.91、0.9、0.88。BERT预训练语言模型相较于Word2vec词向量在字符特征的提取上具有一定的优势.使用BERT预训练模型与Word2vec词向量搭配BiLSTM-ATF深度学习取得的加权平均F1值分别为0.91和0.88。相较于循环神经网络,卷积神经网络在同样的预训练语言模型下取得的加权平均F1值为0.67,结果相对较低。
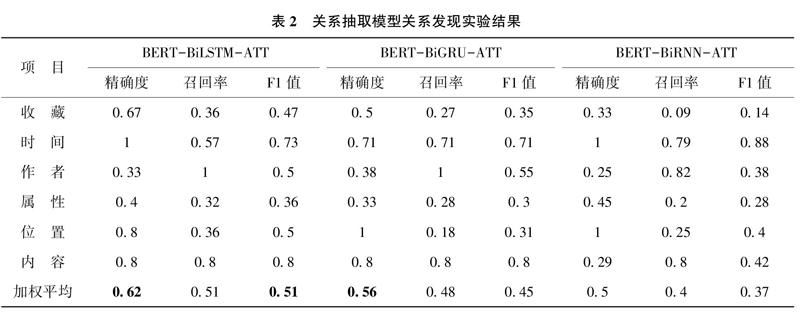
为了更进一步研究文章使用的实体关系抽取方法在文物信息资源实体关系挖掘中的效果,文章将自动标注的508条实体关系作为训练集.人工标注中知识库未收录的77条实体关系作为测试集,与另外两种实体关系抽取方法进行对比,探究模型对于未根据知识库数据规则进行标注的文物实体关系的发现能力,实验结果如表2所示。
从表2的结果可以发现,精确度要明显高于召回率,这说明经过自动标注后的关系抽取模型在发现实体关系的准确率上要高于发现关系的能力。在分类关系的抽取上,对比前文中“时间”关系的抽取,关系抽取模型对于自动标准之外的“时间”关系抽取效果有所降低.通过结合自动标注与人工标注在“时间”关系上的差异发现,《清明上河图》创作于北宋时期,从知识库中提取的时间有关信息大多描述该画在北宋以及北宋后一定跨度时间内的流转情况,而随着时间的推移,后续信息逐渐减少.人工标注中新增部分多以该画在清朝以及近现代流转情况为主,深度学习方法无法获取到近现代时间描述的有关特征,导致“时间”关系提取效果下降。“位置”和“作者”实体关系的提取在发现实验中降低比例较为一致,这说明知识库存有的实体关联關系在经过神经网络提取特征后对上述两种关系具有一定的预测能力。“内容”实体关系由于文物信息资源中对于内容有关信息的描述较少且难以通过标准化数据手段收集,致使与内容有关的实体关联关系抽取效率变化不明显。“属性”与“收藏”两种实体关系抽取效果较差.说明如要提升这两种关系的抽取效率需要在知识库关联关系以后通过其他方法添加外部信息,扩充这两种实体关系的相关特征。
而在模型对比上BERT-BiLSTM-ATT效果最好.这说明BiGRU相对简单的结构一定程度上忽略了文物实体关系具有的特征,导致实体关系发现效率下降。BiRNN相较于BiLSTM忽略掉了部分长序列中存在的实体关联关系,导致抽取效率降低。
综合图3与表2的关系抽取与关系发现结果可以得到如下结论:①关系抽取模型经过自动标注以及训练后能够在随机环境中抽取到文物信息资源中大部分的实体关系,精确度与召回率较好,说明百科类型文物信息资源实体关系较为集中与重复,适合使用预训练语言模型提取字符特征后利用深度学习方法进行关系抽取。②相对于其他深度学习方法.循环神经网络及其改进方法能够在实体抽取中取得较好的效果,长短记忆神经网络模型实体关系抽取效率稍高于现有的其他循环神经网络方法.这一特征在实体关系的发现实验中更为明显。这说明长短记忆神经网络对于未标记实体关系的预测能力更为优秀。③在小样本数据中,BERT预训练语言模型由于在字符语义特征之外还能够提取句子级别语义特征,使得其得到的序列数据特征相较于Word2vec能够更好的被深度学习模型提取,提高实体关系抽取效率。④在随机环境下的6种不同类别文物实体关系的抽取中,“时间”与“位置”关系抽取效果最好,这与文物信息资源中“时间”与“位置”信息具有较为标准化的描述以及明确的表达规范有关,使其具有强烈与一致的语义特征.利用深度学习有关方法对文物信息资源中的时间与位置信息进行分析有着较高的效率。⑤在知识库未收录文物实体关系的发现实验中.方法在“时间”关系的发现中效果最好,但由于时间具有演进特征.新的时间称为与表述方法不断出现,“时间”关系受知识库更新延迟的影响较大。受制于知识库实体关系存储数量.其他几类文物信息资源实体关系则需要通过补充外部信息来提高实体关系抽取效率。
4总结
为解决文物信息资源中实体关系的抽取问题,文章提出了融合知识图谱与深度学习的文物信息资源实体关系抽取方法.构建了基于深度学习的文物实体关系抽取模型.进行了实体关系抽取与发现的有关实验。结果显示,该方法对于小样本语料的关系抽取与发现有着较好的应用前景。BERT-BiL.STM-ATT在与另外两种方法以及循环神经网络有关衍生方法的两次对比实验中精确度与召回率均最高,取得了不错的效果。
文章的主要贡献与创新之处有以下几点:首先,依据文物信息资源中研究对象实体的特点,利用知识库检索提取关联实体及关联关系集合并构建知识图谱,通过规则进行针对百科类文物信息资源文本中文物实体关系的自动标注。其次,文章通过BERT-BiLSTM-ATT模型进行实体关系抽取,利用预训练模型提取字符语义特征,为小样本数据进行实体关系发现提供了一种切实可行的方法。此外,文章方法对于文物信息资源中的时间以及空间特征具有较好的提取与发现效果,为文物信息资源的时空数据研究提供新的视野。
未来的研究中,文章将模型与其他的神经网络进行性能比较.扩大数据集规模,进行更广泛领域的文物信息资源实体关系抽取研究。
猜你喜欢
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
中国教育信息化·基础教育(2016年9期)2016-10-18
