
基于随机森林的用户流失预警研究
2021-06-06 09:23余建波李艳冰
精密制造与自动化 2021年2期
陈 静 余建波 李艳冰
(1.同济大学 机械与能源工程学院 上海201804;2.上海质量管理科学研究院 上海200052)
近年来用户流失预测问题在学术界引起了广泛关注, 范围涉及 MOOC 平台、社交平台、电信等多个领域。它是结合用户的历史数据,对其进行建模,从而训练出能判别用户是否流失的分类器,是一个常见的二分类问题[1]。 流失用户在传统意义是指曾经某时间段内使用过某产品或服务,后期由于种种原因退订该产品或服务。对于流失用户的定义依行业不同而不同,APP领域以用户一定时期内不再登录、卸载软件且不再二次安装以及选择其他同类APP为标准界定流失用户[2],而商业银行用户流失是指终结与商业银行所有业务往来的情形,包括交易锐减、停止交易或者清户[3]。
1 数据预处理与特征工程
1.1 数据预处理
1.1.1 数据清洗
对数据集进行分析发现,无重复值,而对于缺失值和异常值,考虑银行数据的敏感性本文未进行处理,对无关字段用户ID进行了删除。
1.1.2 数据转换
通过数据观察可以了解到,性别、家庭住址和电话信息为字符型变量,本文采用LabelEncoder编码,将文本数据转换成连续的数值型变量,即对不连续的数字或者文本进行编号。如表1所示。

表1 字符型变量编码
1.2 数据不平衡问题处理
数据不平衡,又称样本比例失衡,以二分类问题为例,假设正类的样本数量远大于负类的样本数量,即称为不平衡数据集。正类的样本数量如图 1所示。
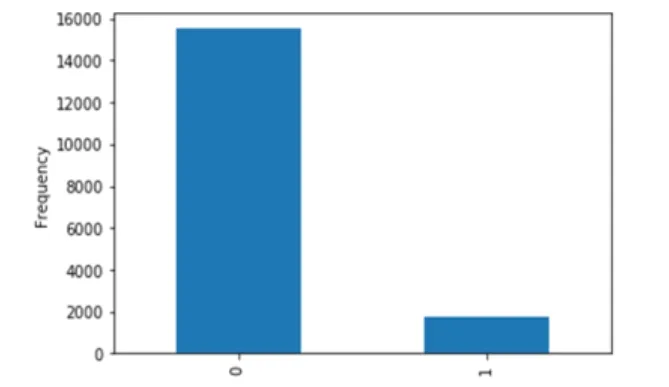
图1 正负样本数量
由图1可知,本文数据集的正负样本比例接近10:1,采用SMOTE合成少数类过采样技术,其基本原理是利用自助法和K近邻法,基于特征空间生成与少数类相似的新数据,来降低分类器的误差。由于该算法产生了新的少数类数据,与采用对少数类数据简单复制的随机上采样的方式有很大不同,尽量避免了模型过拟合现象,有效解决了数据不平衡所带来的分类器性能下降问题[4-5]。
1.3 特征工程
特征工程是将原始数据转换成能被计算机算法所理解的特征体系的工程活动,为了提高模型的准确度和泛化能力,就要从原始数据中提取尽可能多的有用信息供算法使用[6]。
1.3.1 特征选取
1) 随机森林特征重要性排序
随机森林/CART树在使用时一般通过gini值作为切分节点的标准,将变量的重要性评分用 VIM来表示,gini 值用 CI 表示,假设有 m 个特征x1,x2,x3,…,xm,现在要计算出每个特征 xj的gini 指数评分VIMj,即第j 个特征在随机森林所有决策树中节点分裂不纯度的平均改变量,gini指数的计算公式如下表示[7]:
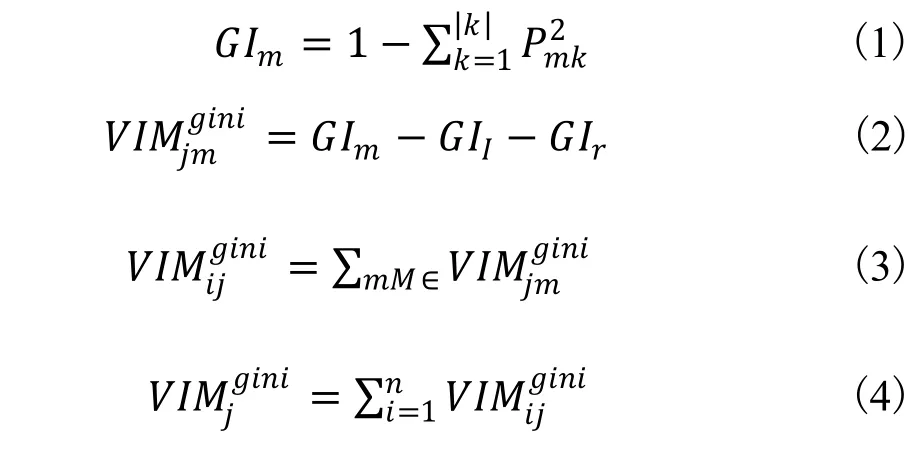
式中,K表示样本数;Pmk表示节点m (将第m 个特征逐行对节点计算gini 值变化量)中类别K所占的比例;表示特征Xj在节点m的重要性,即节点m 分枝前后的gini 指数;表示如果特征Xj在决策树i中出现的节点在集合M中,那么Xj在第i棵树的重要性;最后把所有求得的重要性评分进行归一化处理就得到重要性的评分:

2) 皮尔逊相关系数
本文采用皮尔逊相关系数,分析各个特征之间的相关程度。其公式如下:

其中Cov(X,Y) 为X和Y的协方差,σx,σy分别为X和Y的标准差。
3) 特征提取
首先利用随机森林 指数计算所有特征的重要性分数并降序排序,选取排名前30的特征,并查看这些特征的Person相关系数,对一些相关性极强的特征进行剔除,消除多重共线性。同时为了防止减少特征量会出现过拟合,此处特征剔除的逻辑设置为: (1)两个特征相关系数大于等于0.8;(2)对因变量的解释性更弱。对此提取出特征及各特征的重要性分数值见表2。
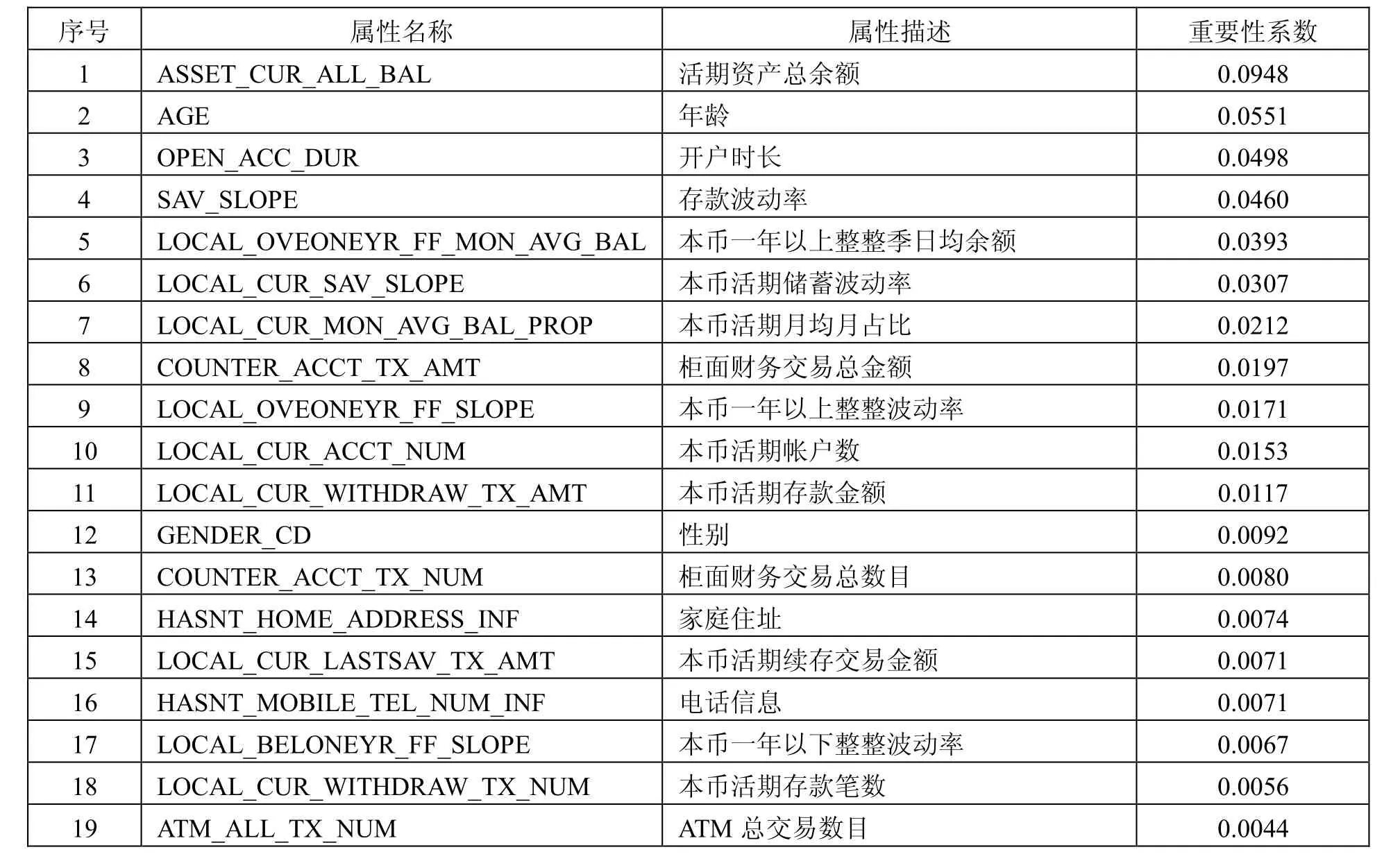
表2 选取特征及其重要性分数
提取特征的相关性热力图如图2所示。
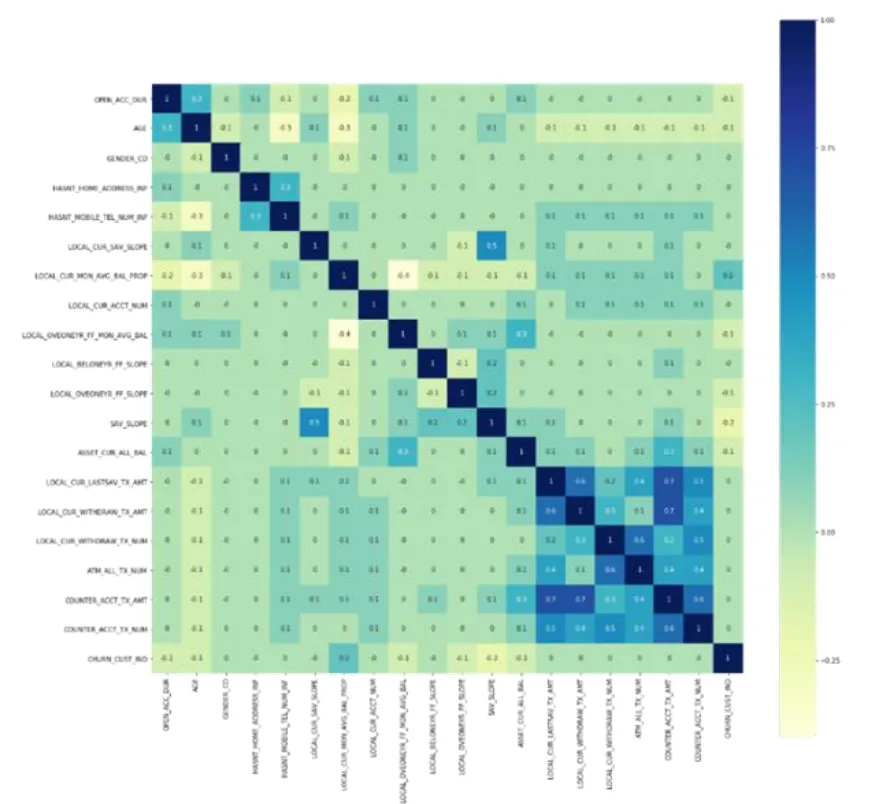
图2 选取特征的相关性热力图
1.3.2 one-hot编码
one-hot编码又称为独热编码,其方法是使用N位状态寄存器来对 N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效[7]。本文共选取特征数量19个,故编码示意图如下图3所示。
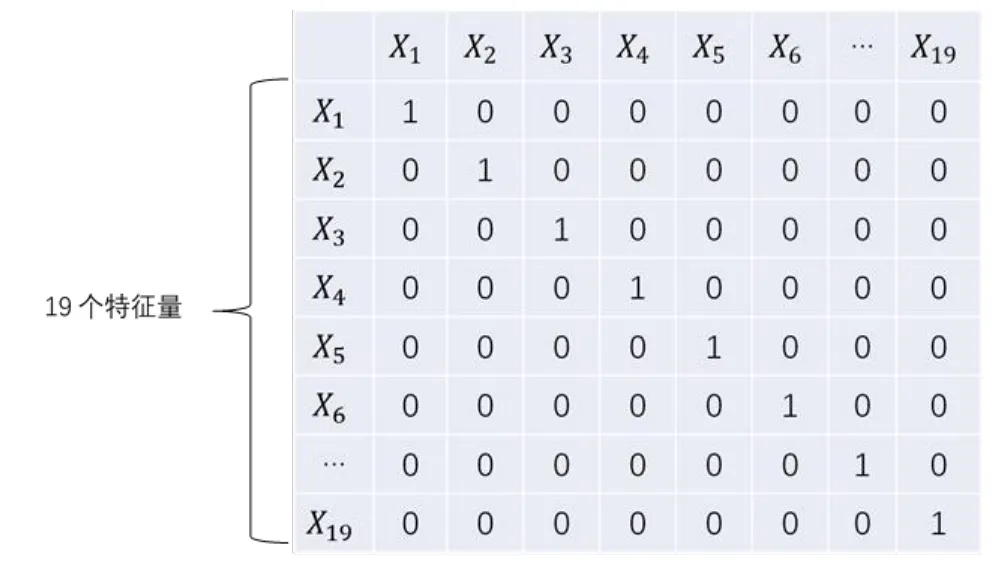
图3 特征独热编码示意图
2 描述性统计分析
2.1 性别与流失率的关系
TGI指数反应目标群体在特定研究范围内的强势或弱势的指数。其中TGI指数大于100,表明某类用户更具有相应的倾向或者偏好,数值越大倾向性和偏好性越强,TGI指数小于100则相反,而等于100表示在平均水平。图3表示不同性别流失情况的TGI指数,其中0表示男性, “1”表示女性,“2”表示未知性别。性别与流失率关系如图4所示。
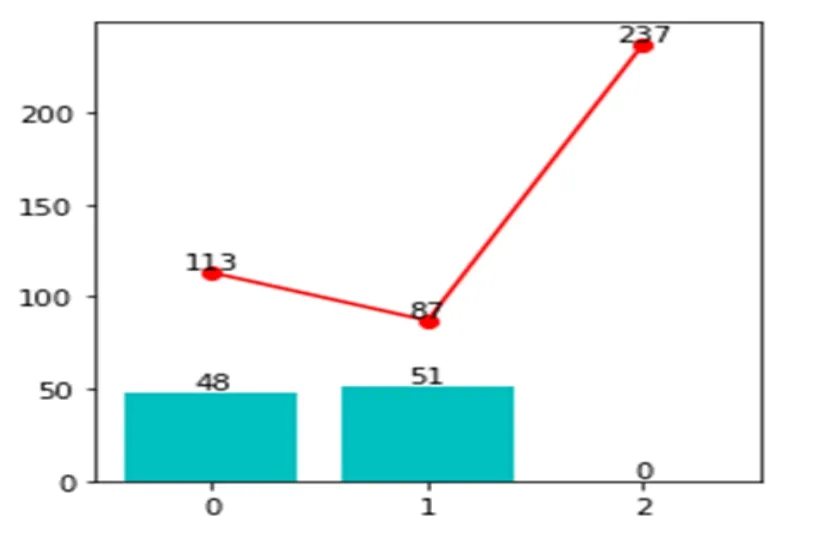
图4 性别与流失率关系图
由上图可知,由于未知性别用户其样本量过小,所以参考价值不大,男性用户流失的 TGI指数为113,女性用户流失的TGI指数为87,表明男性用户较女性用户更易流失。
2.2 年龄与流失率的关系
年龄与流失率关系如图5所示。
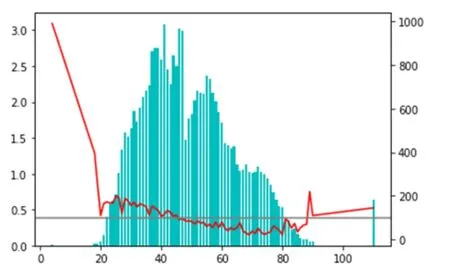
图5 年龄与流失率关系图
由上图可知,年龄在40~80岁之间的中老年用户TGI指数小于100,不容易流失,而小于40岁的用户,尤其是小于20岁的用户流失率更高。
2.3 开户时长与流失率的关系
开户时长与流失率关系的如图6所示。
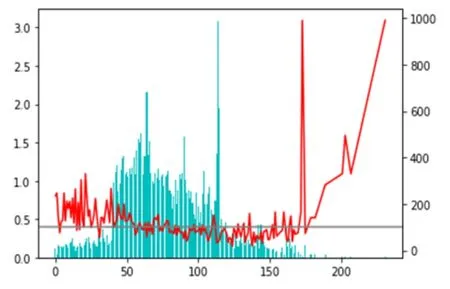
图6 开户时长与流失率关系图
可以看出,开户时长小于 50天或者大于 160天的用户TGI指数小于100,容易流失,而开户时长在50到160天之内的用户更稳定而不易流失。
3 基于随机森林的用户流失预警模型建立
随机森林算法(RandomForest,RF)是一种组成式的有监督学习方法。它通过Bagging集成学习的思想组合多个决策树,最终结果通过投票法或取均值法取得,使模型整体的性能得以提升。随机森林中的决策树在分裂过程中先是从所有的待选特征中随机选取一个包含多个特征的子集,然后根据特征划分准则从随机选取的特征中选择最优的特征划分当前节点,这样能使系统更具多样性,提升模型的分类能力[2]。算法原理流程图如图7所示。
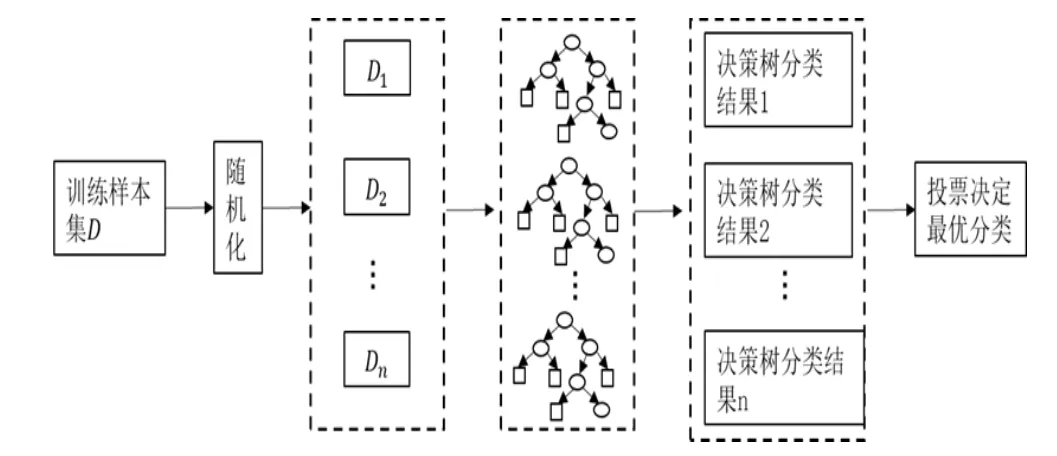
图7 随机森林原理流程图
4 模型求解与参数调优
4.1 实验参数设置
为增强实验的可靠性和实用性,对随机森林参数:决策树个数n_estimators、构建决策树最优模型时考虑的最大特征 max_features、决策树最大深度max_depth、叶子节点含有的最少样本min_samples_leaf、节点可分的最小样本数min_samples_split以及是否使用袋外样本评估模型好坏。参数设置如表3。
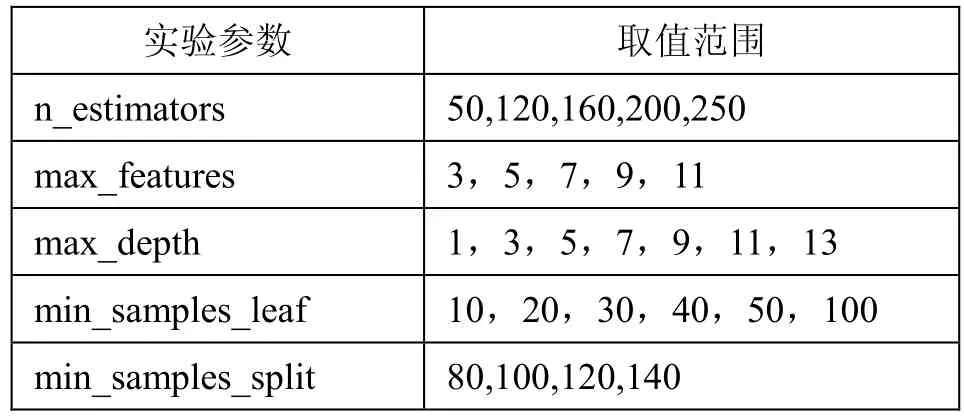
表3 实验参数范围
4.2 网格搜索(Grid Search)寻找最优参数
网格搜索法是指定参数值的一种穷举搜索方法,其核心原理是先设置好要搜索的参数区域,然后将该区域划分成网格,而网格中所有的交叉点就是要搜索的所有参数组合[8-9]。
通过网格搜索法,得到模型训练数据如下表4。
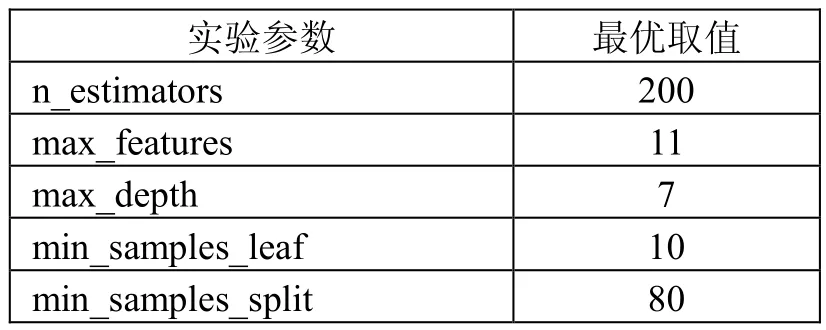
表4 最优实验参数表
4.3 模型求解与评估
对调整参数后的模型进行评估,评估得到准确率、召回率、F1分数如表5所示。
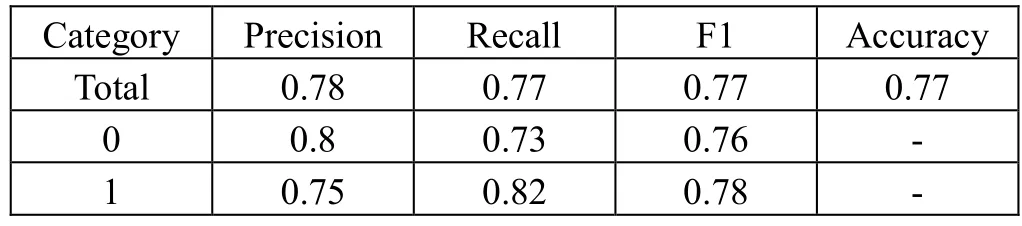
表5 分类结果评估分数表
从表5可看出,模型对留存客户和流失客户的预测准确性相差不大,在所有判定为流失的客户中有75%是真实流失的,在所有实际流失的客户中判定为流失的客户有82%,模型总体的精确度为78%,召回率为77%,F1值为77%,准确度为77%,较未调参的模型提高了0.4个百分点。
实验得到的ROC曲线如图8所示。
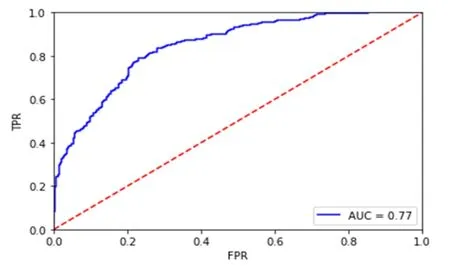
图8 ROC曲线图
ROC是反应敏感性与特异性之间的关系的曲线,横坐标X轴为FPR,即假阳率,纵坐标Y轴为TPR,表示真阳率,曲线下方的面积AUC用来预测准确性,值越大表示预测准确率越高,曲线越接近左上角,预测准确率越高。观察 ROC曲线图可以看出,曲线靠近左上角,即在假阳率很低的情况下真阳率较高,并且AUC面积为0.77,表示模型效果良好,可用于预测。
5 结语
在获客成本越来越高的今天,如何留住客户是一个值得考虑的问题。由随机森林Gini指数得到特征重要性排序可知,ASSET_CUR_ALL_BAL(活期资产总金额)、AGE(年龄)、OPEN_ACC_DUR(开户时长)是影响客户流失的最重要因素,由此建议银行:(1明确目标客户群,锁定目标收入和年龄层的客户,有助于银行实行针对性策略和精细化运营,提高竞争力;(2)采取用户关怀策略,对开户时长不同的用户群采用不同的关怀策略,可以采用会员积分、会员优先等活动,为了吸引新用户,可以通过各种优惠方式如开户免佣金、发送代金券、等优惠方式激励新用户向老用户转化。
本文通过建立基于随机森林的用户流失预警模型,在用户尚未发生流失前采取一定的召回策略,可以有效地防范用户流失。通过分析各个阶段流失率的变化,也可以了解企业运营健康情况。
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
汉字汉语研究(2020年2期)2020-08-13
数码世界(2020年4期)2020-06-18
电子制作(2019年22期)2020-01-14
科学与信息化(2019年28期)2019-10-21
疯狂英语·新读写(2018年3期)2018-11-29
合作经济与科技(2017年17期)2017-09-04
商情(2017年10期)2017-04-30
综艺报(2017年4期)2017-03-29
科学与财富(2016年32期)2017-03-04
