
海平面聚类算法
2021-06-05 06:37:28马杰,杨磊,徐建
智能计算机与应用 2021年4期
马 杰,杨 磊,徐 建
(1江苏师范大学 智慧教育学院(计算机科学与技术学院),江苏 徐州221116;2中国矿业大学徐海学院 计算机系,江苏 徐州221008)
0 引 言
本文算法不是一个独立的聚类算法,是用来辅助其它聚类算法更好、更有效地聚类的辅助算法。与其它聚类算法结合使用,能有效地改善聚类算法的聚类效果。
1 问题的提出
有些算法聚类的结果与自然分类有出入,有些算法对某些情况不能正确的分类。比如:Affinity Propagation(AP)聚类算法,是基于数据点间的“信息传递”的一种聚类算法。算法的基本思想是:将全部样本看作网络节点,通过网络中各条边的消息传递 计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度(responsibility)和归属度(availability)。通过在点之间不断地传递信息,最终选出代表元以完成聚类。AP算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生m个高质量的Exemplar(类似于质心),同时将其余的数据点分配到相应的聚类中。其特点如下:
(1)不需要制定最终聚类个数。
(2)将已有数据点作为最终的聚类中心,而不是新生成聚类中心。
(3)模型对数据的初始值不敏感,多次执行AP聚类算法,得到的结果是完全一样的,即不需要进行随机选取初值步骤。
(4)对初始相似度矩阵数据的对称性没有要求。
(5)与k中心聚类方法相比,其结果的平方差误差较小,相比于K-means算法,鲁棒性强、准确度较高,但算法复杂度高、运算消耗时间多。
在实际的使用中,AP有两个重要参数:preference(定义聚类数量)和damping factor(控制算法的收敛效果)。
聚类就是个不断迭代的过程,迭代的过程主要是更新两个矩阵:
吸引度矩阵R:[r(i,k)]N×N
归属度矩阵A:[a(i,k)]N×N
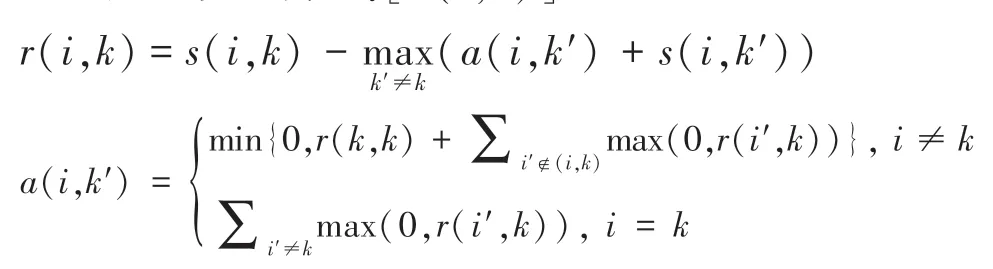
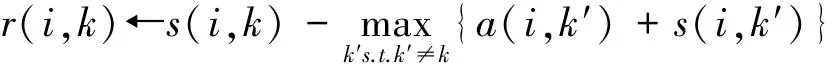
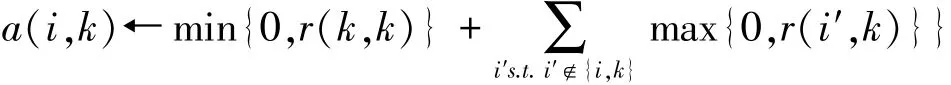
在不断交替更新a和r值,达到一定的次数或收敛后,选取使得r(i,k)+a(i,k)最大的那个k作为i的代表元。其中s(i,k)表示similarity,可以翻译为相似度或度量。是指点k作为点i的聚类中心的相似度,一般使用欧氏距离来计算。相似度值越大说明点与点的距离越近,这在几乎所有的聚类分析中都是最基础的量。
AP算法(参见参考文献[1])是一个很好的聚类算法。但当有大类靠近小类时,往往会把大类的一些边缘点错分给小类。如对图1中的数据,其AP算法的聚类结果如图2所示。显然,没有分成左边两个小类,右边一个大类。而是小类占了大类的几个点。另外,还有一些算法(本文选定一种密度算法,本文称MD算法)对有些数据不能正确的分开。如图3的数据,右边两类中间有两行点连接在一起,很多聚类算法就无法将这两类分开。

图1 AP算法数据准备 Fig.1 AP algorithm data preparation

图2 AP算法分类结果Fig.2 AP algorithm classificationresults
2 问题分析
由上述分析可以看出,问题都出在类的边缘点上。AP算法的问题是大类的几个边缘点离大类的中心点过远,而离靠近其小类中心点更近。另外一些算法无法将图3右边两个类分开,是因为靠近两个类的共同边缘的点连接在了一起。

图3 MD算法数据准备Fig.3 MD algorithm data preparation
3 解决方法
如果能把这些出问题的边缘点先0拿掉(拿掉的点最后还要归类到分好的类中)再进行分类,就不会有上面的问题了。那么,一个问题是解决如何区分边缘点,其二是如何将拿掉的点归类。
首先,对每个点定义一个密度函数,使得类的边缘点的密度小,越靠近中心的点密度越大,这样就解决了第一个问题。再定义每个点的归属点为离此点最近的密度大于自己的点,这样第二个问题就解决了。判断边缘点时,不是直接用密度函数的密度值判断,而是用传导归属点数(既A点到其归属点B点,B点再到其归属点C点,等等,一直传导下去所经历的点叫A点的传导归属点,这个过程叫传导归属。而传导归属数是所有能传导归属到此点的点的个数),传导归属点数越小越边缘,反之越中心。引进一个参数k,传导归属数小于其则为边缘点。先剔除边缘点,然后根据某聚类算法聚类,最后将边缘点传导归属到已分好的类中。
本文定义密度函数:
(1)此点密度为,此点到所有点的距离的倒数之和。
(2)数据的个数为n,每一点为其它各点打分。离此点最远的点得1分,次远点得2分,以此类推。最近的点得n-1分。定义每个点得密度为此点得分的总和。
第一个密度函数要求数据先要剔除相同的数据点。
4 应用效果
本算法与AP算法结合(以下密度函数均选择第一种),采用聚类图1的数据,选择K为2,边缘点如图4所示(方形空心为边缘点),聚类结果如图5所示。本文算法与MD算法结合,采用聚类图3的数据,选择k为3,边缘点如图6所示(圆形空心为边缘点),聚类结果如图7所示。

图4 AP算法结合海平面算法的边缘图Fig.4 Edge map of AP algorithm combined with sea level algorithm
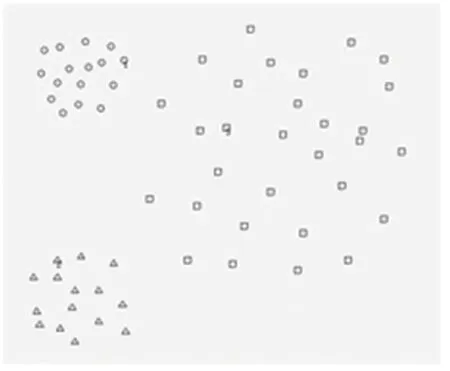
图5 AP算法结合海平面算法结果Fig.5 Results of AP algorithm combined with sea level algorithm

图6 MD算法结合海平面算法的边缘图Fig.6 Edge map of MD algorithm combined with sea level algorithm

图7 MD算法结合海平面算法的结果图Fig.7 Result chart of MD algorithm combined with sea level algorithm
5 结束语
本算法之所以叫海平面聚类算法,是因为k参数相当于设置海平面,边缘点都淹没在海水里,只对陆地进行聚类,因此得名。本算法与其它聚类算法结合可以明显改善聚类结果,经实验证明,本算法是有效的。
猜你喜欢
中学生数理化·八年级物理人教版(2023年5期)2023-05-26 11:21:50
中国医药导报(2022年35期)2022-02-16 05:33:58
江苏安全生产(2020年8期)2020-10-27 01:53:20
北方音乐(2018年8期)2018-05-14 08:59:19
物流技术(2017年4期)2017-06-05 15:13:46
学苑创造·A版(2017年5期)2017-05-09 23:37:47
教育教学论坛(2017年5期)2017-03-06 21:02:38
中国科技博览(2016年26期)2016-10-24 16:40:13
世界科学(2013年11期)2013-03-11 18:09:46
大学(2008年10期)2008-10-31 12:51:10
