
基于深度卷积神经网络的航拍目标检测
2021-06-04 03:09:10赵玉莹
微型电脑应用 2021年5期
赵玉莹
(东北石油大学 计算机与信息技术学院, 大庆 163000)
0 引言
航拍图像是指由无人机搭载高清摄像设备以俯拍的角度获取地面的图像信息。近些年,国家对于无人机的研究,已从简单的飞行操作到实现侦查、勘探等功能。随着人工智能技术的飞速发展,结合无人机等硬件设施已在交通监管、农林管理、智慧城市等领域得到广泛应用。为了实现对地面信息的精准识别,航空影像的目标检测技术已成为人们研究的重点。
在航拍图像中存在背景庞杂,场景多样,目标相对较小等情况[1],传统的目标检测方法无法满足当前航拍图像检测的要求。自Hinton等人在2012年的ImageNet竞赛中提出AlexNet网络以来[2],依靠手工提取特征的传统目标检测方法已被基于卷积神经网络(CNN)的目标检测方法所取缔。目前基于CNN的目标检测方法可归纳为两种类型:一种是分两个阶段来完成目标检测任务,该方法先将图像中可能存在目标的区域都标记出来,即生成目标的候选框;然后采用基于CNN的模型将候选区域进行正确的分类。如R-CNN[3]、Faster R-CNN[4]、R-FCN[5]等都在公共数据集上实现了对目标的精准检测和语义分割。但该类方法中会存在大量的候选框,使得对特征提取的计算量过大,导致检测的速度过慢,无法满足实时检测的需求。针对这类方法存在的问题,研究学者们提出端到端的检测方法。2016年,Redmon等人[6]提出了YOLO,其使用了回归思想,将输入的图像分为大小一致的多个区域,直接在每个区域上预测相应的目标边框与类别[7],相较于Faster R-CNN算法,检测的速度提高许多,但是检测的准确率略有逊色。同年,SSD方法结合了YOLO算法的回归思想与Faster R-CNN中的多尺度特征提取方法[8],实现了检测的精准性与实时性,然而对小目标的检测结果依然不够理想。航拍影像的获取具有特殊性,存在目标尺度小、噪声较多、背景庞杂等特性,因此无法将这些方法直接用于航拍目标检测。
为解决以上问题,本文提出一种基于深度残差网络多特征融合的目标检测模型。本文的主要工作是采用基于端到端的SSD网络框架,引入深度残差网络(ResNet)为基础网络增强网络的学习能力,缓解由网络加深产生的梯度消失现象,并采用特征金字塔(FPN)结构实现底层特征与高层语义信息的融合;提高对航拍影像中小目标检测的精准性与鲁棒性。
1 基于深度卷积神经网络的航拍目标检测算法
1.1 深度残差网络
ResNet是2015年何凯明等人提出的用于图像分类识别的一种深度卷积神经网络[9],其网络的核心是通过对前后卷积层之间添加了“跳跃连接”机制,如图1所示。
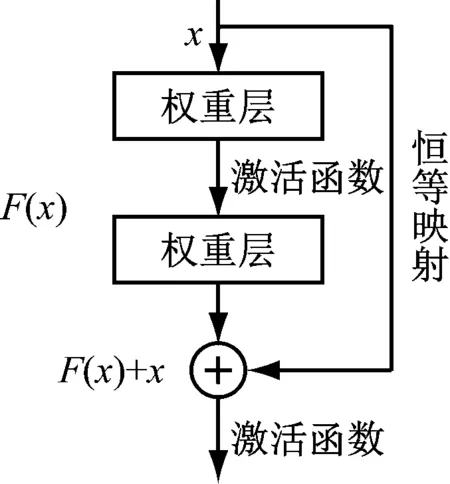
图1 残差块结构图
x为残差块的输入;H(x)为模块的输出。定义另一个残差映射函数F(x)=H(x)-x,那么原始的映射函数为H(x)=F(x)+x,可以看作是主路径上的F(x)与跳跃连接中的x之和,这种结构实现了恒等映射的学习,在网络训练中促进梯度的反向传播,还可以训练更深的CNN。
将残差块的输入设为xl,网络的输出设为xl+1,得到结构的计算过程为式(1)、式(2)。
yl=h(xl)+F(xl,Wl)
(1)
xl+1=f(yl)
(2)
式(2)中,f为激活函数,本文采用ReLU函数。如果h(xl)=xl和f(yl)=yl是恒等映射,那么表达可为式(3)。
xl+1=xl+F(xl,Wl)
(3)
通过网络的层数增加,不断增加残差块,最后得到的递归式为式(4)。
(4)
式中,L表示任意深的残差块。
而对于梯度的反向传播,设损失函数为θ,那么可以得到式(5)。
(5)

1.2 特征融合
虽然深度残差网络加深了网络对目标特征的学习,但是对底层特征图的利用不充分,致使小目标的检测结果不够理想。本文将FPN的思想添加到检测模型的网络结构中,把低层特征的边缘信息和高层特征的丰富语义信息通过横向连接和top-down网络融合起来,实现对各个尺度卷积层的特征信息的充分利用,提升航拍图像中多尺度目标的检测精度。
对ResNet网络的conv2,conv3,conv4和conv5层中最后经过激活函数的输出用{C2,C3,C4,C5}表示,然后在C5上添加1×1的卷积生成特征图P5,再将P5与经过1×1卷积处理后的C4合并生成P4,同理依次生成P3,P2,最后对{P2,P3,P4}的特征图附加3×3卷积生成最终的特征图,如图2所示。
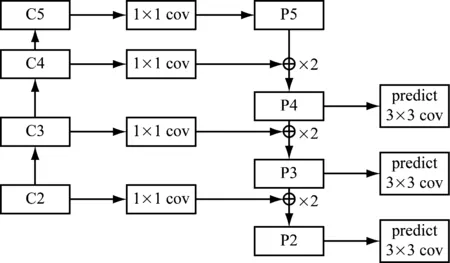
图2 特征融合网络结构
采用特征图金字塔网络结构将浅层特征与深层特征进行融合,有效地解决了网络较深时浅层小目标易丢失、无法获取丰富的语义信息的问题。
1.3 本文目标检测模型
本文提出的检测模型的网络结构,如图3所示。
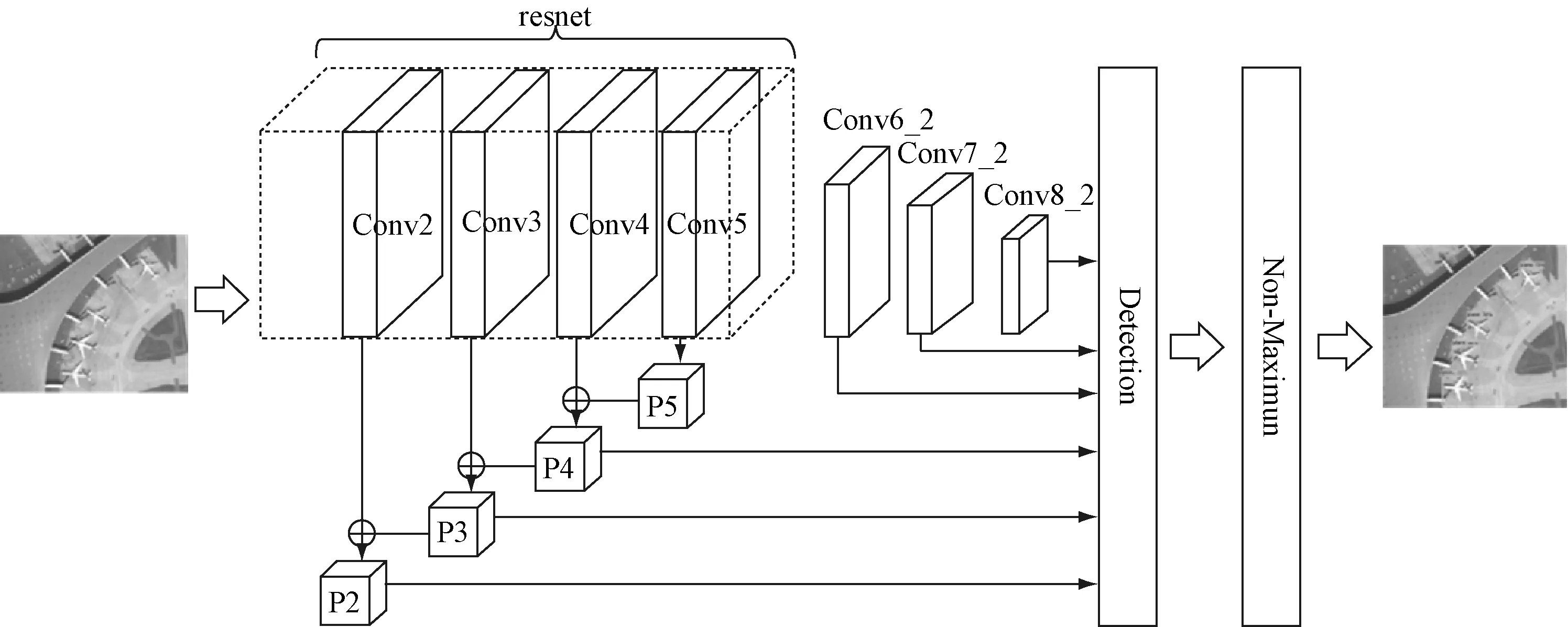
图3 本文检测模型的网络结构图
将原始的ResNet网络去掉最后的全连接层和Softmax层后的网络层作为本文检测模型的基础网络,并将conv2,conv3,conv4特征融合后生成的特征图与新增卷积层中conv6_2,conv7_2,conv8_2的特征图一同进行预测。
对于每个特征层上的默认框本文采取不同的宽高比,由此提取多尺度的目标特征。每个默认框大小计算式为式(6)。
(6)
式中m表示特征图的数量;Sk表示默认框的大小相对于整张图片的比例;Smin和Smax表示比例的最小值和最大值,分别设为0.2和0.9,可计算得出每个默认框的尺寸,其宽高设置为式(7)。
(7)
式中,ar为长宽比,取值为ar∈{1,2,3,1/2,1/3},由此对每个特征图设计5个不同尺寸的默认框用以提取目标。
生成特征图后根据目标函数进行分类与定位,因此目标函数分成类别损失与位置损失两部分,类别损失是计算生成的默认框与目标类别之间的误差,为式(8)。
(8)
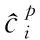
位置损失是计算预测框相对于真实物体边界框的误差,使用Smooth L1 loss进行计算,为式(9)。
(9)
式中,l代表预测框与默认框之间的变换关系;g代表真实物体边界框与默认框之间的变换关系。最后的目标损失函数为置信损失Lconf(x,c)和位置损失Lloc(x,l,g)两部分的加权和,其计算式为式(10)。
(10)
式中,N表示与真实物体边界框对应的预测框的个数;α表示用来决定类别损失和位置损失所占权重的参数,一般取值为1[11]。最后使用非最大值抑制NMS过滤掉重叠度较大的预测框,最终剩余的预测框即为检测结果。
2 实验与结果分析
2.1 数据集制作与分析
本文实验使用的图像数据集是提取了DOTA[12]、UCAS_AOD、RSOD-Dataset等航拍数据集以及自己制作的航拍飞机检测数据集,并通过镜像、旋转、添加噪声、拼接等方式进行数据增广,如图4所示。
最终制作了6 525张航拍飞机图像数据集,并对每张图像中飞机标注的面积占整张图像的比例进行了统计,如图5所示。

图4 数据增广示例

图5 目标面积占图像面积的比例统计
本实验的数据集中共计有29 914个飞机目标,其中占整张图像面积小于5%的就有25 283个,说明该数据集中多数为小目标。
2.2 实验环境与训练
实验环境及具体配置参数,如表1所示。
在模型训练的过程中,学习率初始设为0.03,采用随机下降法进行优化,处理批次为4,共迭代了3万次,前15 000次中学习率为0.03,然后将学习率下调至0.000 1再训练15 000次,最后模型在20 000次左右整体损失函数得到收敛的最佳效果,如图6所示。
图6 总体损失函数
2.3 实验结果与对比
本实验仅对飞机一类目标进行检测,因此对模型检测的结果使用平均准确率(mAP)与每秒处理图像数量(FPS)作为评价标准,对基于VGG16网络、ResNet50网络的SSD算法和本文算法进行实验对比,检测结果如表2所示。

表2 三种检测模型实验结果对比
本文算法较基于VGG16的SSD算法对小目标检测的准确率提升了6.7%。
不同算法对航拍视角下飞机检测的结果如图7所示。
由检测结果图可以看出,无论是在复杂背景还是密集区域中,本文算法都能较原始SSD算法检测的效果更好。

(a) SSD算法
3 总结
本文针对传统算法对航拍图像中小目标检测效果不理想的问题,通过引入深度残差网络加深网络学习提升网络训练能力,并有效降低网络冗余。同时本文针对基础网络中对底层边缘信息利用不充分的问题,结合FPN网络结构实现浅层特征图与深层特征图融合,充分利用多尺度卷积层的特征信息,增强了模型对小目标检测的鲁棒性。实验结果表明,本文的航拍目标检测算法可以愈加精确的检测出图像中的飞机目标,验证了本算法的有效性。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
中外文摘(2021年10期)2021-05-31 12:10:40
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
今日农业(2019年15期)2019-01-03 12:11:33
小学生优秀作文(低年级)(2018年6期)2018-05-19 01:54:27
作文通讯·高中版(2017年6期)2017-07-10 03:21:34
陕西画报(2017年1期)2017-02-11 05:49:48
