
基于大数据的用户行为分析系统
2021-06-04 02:16丁鹏程
数字通信世界 2021年5期
丁鹏程
(宁波大学信息科学与工程学院,浙江 宁波 315200)
1 大数据相关理论概述
1.1 Spark
Spark 技术可以实现对大数据的快速集群计算,其运行在Hadoop 集群上,能够对Hadoop 中的数据资源进行访问。基于Spark 技术,对数据进行处理和分析,可以支持多种文件格式,包括文本文件、SequenceFile、Avro 等。同时,Spark 的数据结构为RDD(弹性分布式数据集),该数据集在创建后不能修改[1]。应用Spark技术对数据进行处理,是创建RDD、转化RDD、调用RDD,并进行求值的过程。最终,RDD 中的数据会分布到集群中,实现并行化的操作执行。
1.2 Hadoop
Hadoop 技术是基于分布式服务器集群对数据进行运算和分析的框架。包括HDFS、MapReduce、Yarn 组件。基于本文主要研究内容,着重对MapReduce 组件进行介绍。首先,MapReduce 组件是一种数据处理的编程模型,分为:Map、Reduce 两个阶段[1]。
1.3 Clickhouse
Clickhouse 是一个列式数据库,建立该数据库的目的在于对数据进行快速的在线分析与处理[2]。Clickhouse数据库的优点包括:紧凑数据格式、数据压缩、数据存储在磁盘、多核处理、支持分布式、支持部分SQL、数据实时更新等。
2 系统架构设计
Spark(计算引擎)是一种具有通用性特征的,可以对大规模数据进行快速计算和处理的引擎。根据官方的数据信息显示,Spark 计算引擎的运算速度快于HadoopMapReduce 的运算速度100 倍[2]。并且Spark 计算引擎的运行模式具有多样化特征,主要包括:本地运行模式、独立集群运行模式等。本文采用Spark 的分布式集群系统平台架构,对用户的行为数据信息分析系统进行深度设计。该系统架构层次有四层,分别为:数据采集层、数据存储层、数据分析层、数据应用层。其中,数据存储层,可以分布式存储系统所采集到的数据与信息,通过虚拟技术的应用,实现数据信息的统一化管理;数据分析层是该系统的核心层,可以对不同类型的数据进行聚类处理与关联性分析。基于大数据处理需求,数据分析层直接接入Spark 平台;数据应用层可以对数据信息进行提取,并通过文字、图表等形式展示给用户,为用户的应用等带来便利。
3 关键技术
3.1 用户行为的数据采集
数据采集是该系统的基础内容,是数据分析的关键步骤。采集的用户行为数据质量,直接影响着用户行为分析结果的质量。在传统数据采集与应用的系统中,主要对用户的操作行为、浏览习惯行为等数据进行采集,并通过第三方数据收集相关脚本信息。但这种方式存在一定的估算误差,导致用户行为倾向程度判定不精准[2]。因此,本系统设计中,深度应用大数据技术,通过编写代码,实现对用户的全量事件、指标的跟踪与分析。
3.2 用户行为的数据分析
基于数据采集,数据信息将会被发送到消息列队中,通过对海量用户行为数据的存储,赋予用户行为信息日志的高可靠性、高容错性、高获得性。为提高用户的行为数据与信息的分析精准性,基于Spark 的Transformation、Action 算子,对相关数据信息进行实时分析。同时,结合sql 语句形式,对相应算法进行优化,以读取分布式文件系统中的数据,并对数据进行分类和离线分析,最终将分析结果传送到关系型数据库中,从而实现数据分析结果可视化展示。
3.3 用户行为的数据应用
数据应用方面,包括对数据的展示、数据智能推荐、用户行为预测三部分。数据展示方面,是通过Sprintboot提供的数据访问接口,对Mybatis 进行持久化框架连接和应用。同时,Angular 组件在系统中的应用,可以加快信息数据应用的响应速度,有利于系统数据信息处理质量的提升。最后,通过Echarts,将信息动态以直观的形式展示给用户。在数据智能推荐方面,基于内容过滤的推荐算法、双重聚类算法的融合,形成混合推荐技术。通过该技术的应用,可以对用户行为日志进行读取、分析,并在此基础上,对用户行为进行关于服务内容的智能推荐。用户行为预测方面,基于数据包的重组算法,可以根据用户行为的相关数据,实现网络数据信息的重组。
4 基于Spark 的Apriori 算法改进
4.1 Apriori 算法
在用户行为分析方法中,应用最为广泛的方法为关联规则算法。而Apriori 算法是关联规则中常用算法,其核心内容与思想为:通过对候选项的连接与支持,对频繁项集进行剪枝,进而得到最大频繁项集与预先设定的最小置信度阈值,最终生成关联规则[2]。其算法流程,如图1所示。

图1 Apriori算法流程
4.2 Apriori 算法改进
在计算候选频繁项集过程中,需要对每个项集进行数据集合扫描。若数据过于庞大,则耗时较长。因此,在第一次读取数据集过程中,可以通过矩阵的方式,对转换集合的每一项内容进行展示。例如,若第一行的数据项集显示为1,则需要针对该数据项集中每一项数据情况进行挖掘和分析。若分析过程中,出现设置,则表示为1;若未出现设置,则表示为2,并且第二轮及后面轮次的候选集的支持度统计,只需通过候选集、候选集相对应的数据内容,进行下一环节的操作,从而得出候选集的支持度。这种方式,不仅提高数据扫描的效率,减少扫描次数,而且还提高了数据计算的效率与质量。
本质而言,Spark 算法语Hadoop 算法极为相似,但Spark算法能够更好地与数据挖掘、机器学习技术的应用。在运算过程中,用户行为的数据信息统一存储在HDFS中,通过对数据的读取,可以获取频繁项集的全局支持度,最终将计算后的频繁项集保存在HDFS 中。
5 系统实现
以线上教学的移动终端APP 为例,当学生应用APP时,可以保存按钮点击、登录等行为数据信息。通过对保留的数据信息的分析与处理,可以对学生访问APP 时长、次数、感兴趣内容、操作习惯等数据信息进行提取,并将学生使用APP 相关数据显示在屏幕上[1]。基于实践数据分析,教师可以通过APP 显示的相关信息,对学生的学习进行监督与管理。通过Apriori 算法的应用,设定支持度的阈值为22%,置信度的阈值为72%。结合计算分析结果,得出学生的活跃时间情况,如表1所示。
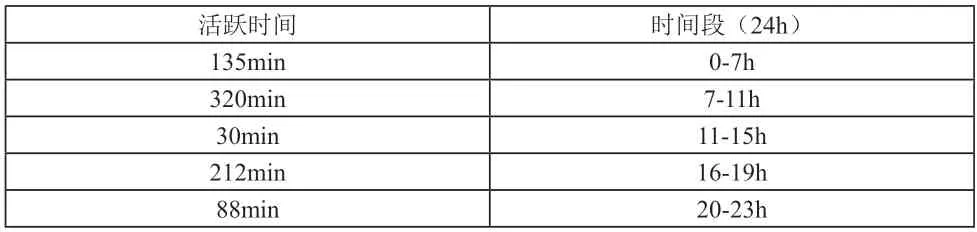
表1 学生活跃时间
表1分析可知,学生在7-11h、16-19h 的学习时间较长,表明学生在课余时间,这两个时间段是学生学习的高峰时间,也是学生学习的习惯时间。
6 结束语
为有效分析用户行为,提出基于Spark 算法的用户行为分析的系统架构。为实现用户行为信息的有效分析和深度应用,对Apriori 算法进行改进,并以线上教学平台的移动终端APP 用户数据进行关联性分析和验证,确保设计的系统可以实现。
猜你喜欢
湖南电力(2022年3期)2022-07-07
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
军事运筹与系统工程(2019年4期)2019-09-11
信息化建设(2019年2期)2019-03-27
计算机与数字工程(2018年10期)2018-10-23
电子制作(2018年11期)2018-08-04
制导与引信(2017年3期)2017-11-02
计算机与数字工程(2017年2期)2017-03-02
知识就是力量(2017年2期)2017-01-21
雷达与对抗(2015年3期)2015-12-09
