
基于随机森林和LSTM-自编码算法的风机高温降容状态智能检测方法
2021-06-04 07:49:22张国珍王其乐叶天泽杨锡运
华北电力大学学报(自然科学版) 2021年3期
张国珍, 王其乐, 叶天泽, 杨锡运
(1.龙源电力集团股份有限公司,北京 100034; 2.中能电力科技开发有限公司,北京 100034; 3.华北电力大学 控制与计算机工程学院,北京 102206)
0 引 言
受气象环境、随机性载荷、脉冲电压等因素影响,发电机、齿轮箱等风电机组部件的工作运行条件往往存在较大的不确定性,从而给风电机组的稳定运行埋下了诸多安全隐患[1]。相关部件若后期维护不及时或缺乏针对性,很容易引发意外故障,严重时甚至会折损风机的寿命。
齿轮箱等部件的高温降容状态是表征风电机组亚健康状态的良好指标。当高温降容状态不超过某一阀值时,通常表明风机各部件、各子系统整体运行良好;而当其超过阀值显示异常时,则可能指示存在装置老化、转子超速、线圈短路等问题[2,3]。因此可以通过开展风机高温降容状评估,提前研判风机潜在的运行故障,以便及时针对性地开展运维工作。
随机森林(Random Forest,RF)具有良好的抗噪性和泛化能力,过拟合问题影响较小[4,5]。除此之外,RF能够评估各个特征在分类问题上的重要性,有助于挑选最优特征子集。虽然RF算法的泛化能力和分类性能较好,但随机设置参数时其分类稳定性仍会受到影响,最优特征子集也会收到影响,最优特征子集的维度也会因此而增加。文献[6]通过vine-copula模型对机组各个特征进行相关性分析,建立合适的贝叶斯概率图形网络,从而实现对高温降容状态的评估。
鉴于传统的基于单一算法或理论的状态评估方法的预测精度尚不够理想[7-10],为了实现考虑时序特性的负荷特征自动提取和非线性降维。本文基于“数据驱动”的思想,提出基于随机森林和长短时记忆(LSTM)自动编码器(Autoencoder,Aec)的风机高温降容状态检测方法。将具备时序记忆功能的LSTM单元作为Aec的神经元。利用随机森林算法对SCADA数据进行特征约简,自动编码器的非线性特征提取能力和LSTM的时序特征提取能力,建立重构曲线,拟定合适的阈值。从而对风机高温降容状态进行评估检测,为风电场运维方案的编制提供提供科学依据,从而更好地应对和处置齿轮箱高温降容状态,减少及避免更大的损失。
1 随机森林算法
随机森林算法是一种基于传统决策树的统计学习理论,其基本思路为:(1)利用重采样抽样法从初始样本集中选取k组数据,每组数据的容量都与初始样本集相同;(2)分别对k组数据建立k个决策树模型,并计算相应的分类结果;(3)根据k个分类结果来投票决定其最终分类。为了处理风机高温降容中的多维特征信号,提高模型的预测能力,本文采用随机森林算法对SCADA数据中的多维特征进行约简,如图1所示。

图1 随机森林算法流程图Fig.1 Flow chart of random forest algorithm
1.1 随机森林特征选择
随机森林[8]特征选择中舍弃掉风机SCADA数据的冗余特征,降低了干扰因素,筛选后的特征指标体系更具代表性,从而有效地提高分类的精度。其算法流程如下所示:
(1)计算Ck(x)在对应OOBk中的准确率acck;

(3)计算特征x(j)(j=1,2,…,n)的重要性度量。
(1)
(4)从现有的特征数据中删去重要性较低的特征,从而得到全新的特征子集,在全新特征子集上构建随机森林C*(·),得到全新特征子集对应随机森林算法中的OOB误差率;
(5)重复步骤(4),当仅剩1个特征时此流程结束,通过最小OOB误差率的方法来决定最终的特征子空间。
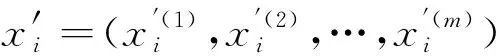
2 LSTM-Aec网络
2.1 LSTM网络
LSTM是一种特别的循环神经网络(Recurrent Neural Network,RNN),善于解决时间序列问题,RNN中的梯度爆炸和梯度消失等问题也得到有效解决[11-15]。LSTM中单元状态ct的内容由两个门来控制:一个是遗忘门,它决定了上一时刻的单元状态ct-1有多少保留到当前时刻ct;另一个是输入门,它决定了当前时刻网络的输入xt有多少保存到单元状态ct。而LSTM的当前输出值ht是由输出门和单元状态ct来决定。LSTM的结构原理[16]如图2所示。

图2 LSTM网络结构Fig.2 Structure of LSTM network
2.2 基于LSTM的自编码网络
LSTM的长期记忆特点可在时间序列数据分析中得到有效应用,结合当前信息和筛选后的过往信息,最终实现预测的作用。为了确保模型的预测精度,需要参考预测值与实际值的重构误差,进行参数调节。

(2)
式中:h(t-1)i∈Rm为t-1时刻第i个编码单元的输出状态向量;输入向量xti∈Rm,W;R为m×d和m×m阶系数权重矩阵;函数k(·)通常为激活函数“tanh”。将Xi中的每个列向量作为编码器的输入,可得
(3)

(4)
hi=ht,ni
(5)
(6)
式中:j为hti的行数,池化步骤结束后,hi输入解码器,输入可重构为
(7)
(8)


图3 LSTM-Aec网络结构Fig.3 Structure of LSTM-Aec
3 结合随机森林和LSTM-自编码算法的风机高温降容状态检测模型
3.1 本文模型选取思路
风电机组在夏季存在齿轮箱油温过高导致机组出力降低频发的情形(简称高温降容状态),机组频繁出现高温降容状态,会引起润滑油化学性能降低,容易造成齿面的磨损和损坏,从而影响风机的正常运行。因此,根据机组的监测数据实时评估机组齿轮箱导致的高温降容运行状态,提前知晓风机亚健康状态,制定合理的运行方案,不仅可以减少风机出力损失,也能避免造成零部件损坏,从而避免发生更严重的故障造成风机长时间停机、维修时间过长以及产生高昂维修成本。
SCADA系统能够提供的机组参数较为庞杂,从数据量庞大的SCADA系统中分析有效数据、提取关键特征时,随机森林算法凭借决策树的特性,利用所有决策树得到的平均不纯度(基尼系数)衰减来量化特征的重要性,根据重要性可以剔除相关度很低的特征,从而有效精简模型特征。这大大减少了模型的训练时间,而且模型的拟合能力也不会降低。
风机齿轮箱油温会随着运行风速、运行功率的随机波动发生不规则变化,会呈现非平稳时间序列特点。传统神经网络每层之间的节点无连接, 而循环神经网络(Recurrent Neural Network,RNN)则不同,RNN通过保存当前隐藏层的信息,并通过隐藏层之间的连接将信息传递到下一时刻的隐藏层,使得网络具有“记忆”功能。记忆功能的存在使得RNN在处理时间序列性问题上表现突出。但网络在进行反向传播时, 对模型的线性关系参数具有长期依赖性,在运算过程中序列过长会引起梯度消失现象,网络参数过大则会产生梯度爆炸现象。本文采用的LSTM方法的网络利用时间反向传播训练,在保存了记忆功能的基础上,克服了梯度消失的问题。
因此,为了提高齿轮箱高温降容状态评估的准确率,本文提出了基于随机森林和LSTM-自编码算法的风机高温降容状态评估方法,该方法兼顾了准确性和快速性,具体流程图如图4所示。

图4 本文模型流程图Fig.4 Flow chart of proposed model
3.2 模型详解
其原理步骤如下:首先,从SCADA系统中获取完整数据、机组异常情况申诉和故障异常情况申诉中的高温降容填报信息。根据风速功率散点图通过最优组内方差算法挑选出异常功率点,同时删除停机点。紧接着,将处理后的数据作为随机森林算法的输入,利用所有决策树得到的平均不纯度(基尼系数)衰减来量化特征的重要性,通过序列后向搜索方法求取各特征组合下的分类精度,删除冗余特征。最后,将特征筛选后的数据输入LSTM-Aec网络,利用LSTM-Aec算法的“记忆”功能以及非线性特征提取能力,得出高温降容状态的评估结果。
4 案例分析
4.1 数据分析
为验证本文所述模型对风机高温降容状态评估的有效性,采用内蒙古东部某风电场中2019年1月~12月从SCADA系统中采集到的完整数据以及机组异常情况申诉和故障异常情况申诉中的高温降容填报信息。该风场装机200台风机齿轮箱油温统计结果表明,机组高温降容散点主要集中在高风速、中高功率、高齿轮箱油温等区域,如图5所示。

图5 风速-齿轮箱油温-功率散点图Fig.5 Wind speed-gearbox oil temperature-power scatter diagram
经过筛选后,提取数据集中的6 000条数据作为仿真数据,其中有5 000条数据是风机正常运行状态时的数据,1 000条是风机高温降容状态下的运行数据。为了得到稳定泛化算法模型,将整体数据集分训练集(80%)、测试集(20%) 输入模型。
4.2 预测评价标准
完成实验模型构建并确定模型结构后,需要通过性能指标对模型进行评价。根据预测类别与真实类别将预测结果分为:真正例(TP)正确地识别风机处于高温降容状态、假正例(FP)将未处于高温降容状态判断为处于高温降容状态、真反例(TN)将处于高温降容状态判断为未处于高温降容状态、假反例(FN)正确识别风机处于正常状态 4 种,得到的混淆矩阵如表1。

表1 分类结果混淆矩阵
根据混淆矩阵,可以得到4个评价指标:
(9)
(10)
(11)
(12)
式中:精准率P表示实际高温降容状态次数占预测为高温降容状态次数的比例;召回率R表示预测为高温降容状态次数占实际高温降容状态次数的比例;准确率A表示测试集中高温降容状态分类正确的次数占测试集数据总量的比例;F1分数是一种调和分数,为对二分类问题分类效果的一种评价指标,兼顾了精准率和准确率。
4.3 利用随机森林进行特征约简
鉴于大量数据的冗余特征会降低分类计算速度与准确度,本此采用随机森林算法对SCADA数据进行特征约简,在此基础上对数据集进行特征权重的求取,将SCADA系统采集的19种特征参数作为输入,得出每一个特征属性在随机森林分类过程中所占的重要性权重大小,如图6所示。
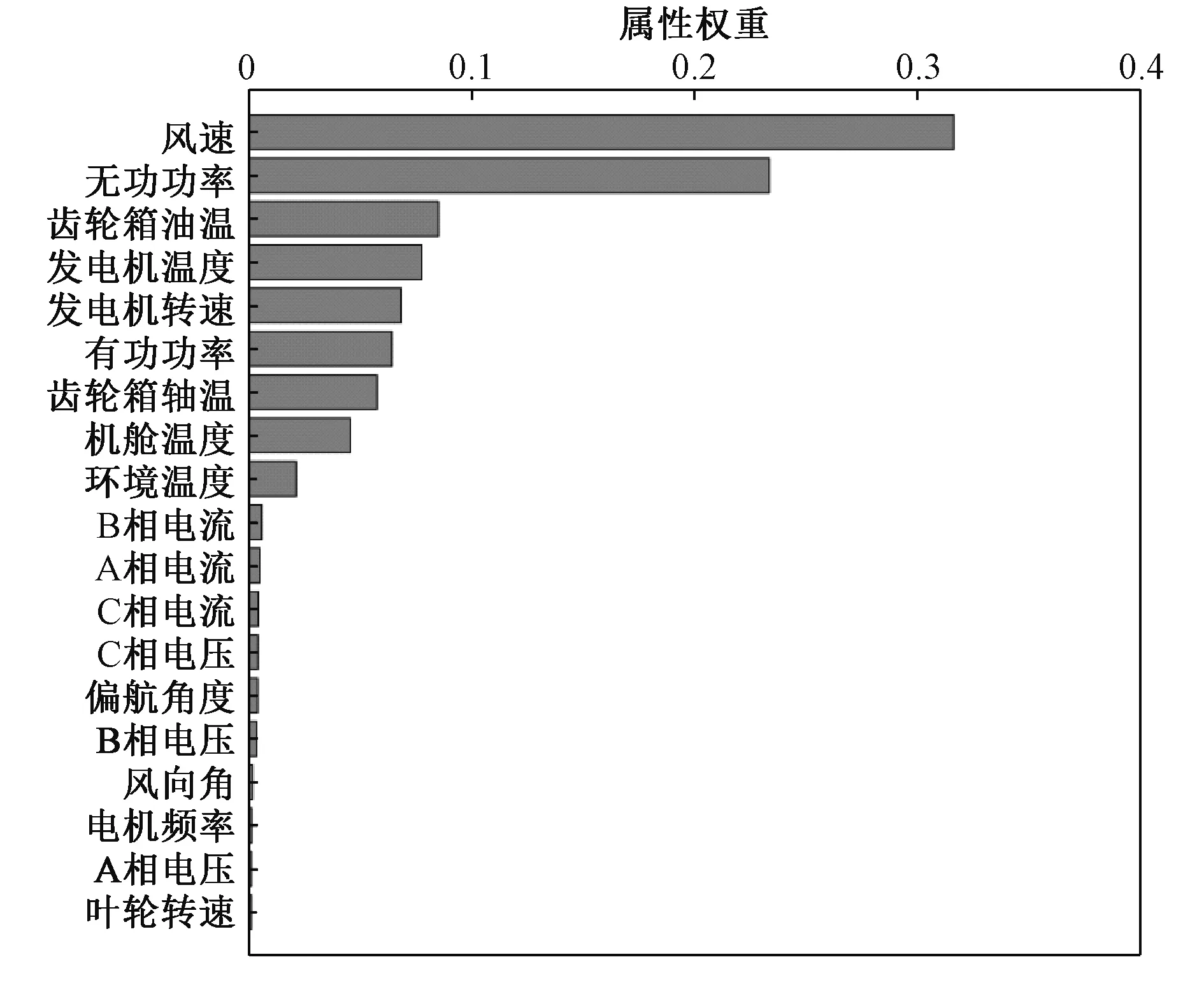
图6 各特征在高温降容状态诊断中所占的权重Fig.6 Weight of each feature in diagnosis of capacity reduction at high temperature
特征权重分类结果表明,机组高温降容状态与风速、有功/无功功率、齿轮箱油温等特征权重较大,而A/B/C相电流和电压的权重则较小,可见风机高温降容状态与风速、功率、齿轮箱油温、发电机转速等特征息息相关。
本文采用的是序列后向搜索方法,以此搜索能够找到实现最大分类准确率的最佳特征子集,最终特征选择的实验结果。统计结果表明,当非重要特征(在重要性排序中次序靠后的特征)依次剔除时,分类结果的准确率在逐渐升高,这是因为相关性较低的特征和冗余特征的减少提升了分类器的性能;如图7所示,当分类结果的准确率达到最高值0.851 3之后又逐渐降低,则是因为相关性较大的特征被剔除,降低了分类器的性能。这说明了随机森林算法能够较为有效地检测并剔除低相关性特征和冗余特征,从而提高分类器的性能。因此,选取前9个特征的组合作为LSTM-Aec算法的特征输入。

图7 特征组合与高温降容状态识别准确率的关系Fig.7 Relationship between feature combination and state recognition accuracy of capacity reduction at high-temperature
4.4 随机森林结合LSTM-Aec网络进行高温降容状态监测
本文的实验仿真环境为:Python 3.7.0,Windows10×64,4 GB RAM,i5-5250 CPU,1.60 GHz。其中LSTM-Aec模型的训练次数被设置为200次。LSTM-Aec结构的隐含层包括一层编码层和一层解码层,输入层节点数和输入特征向量维度相同,解码和编码层节点数只是输入层节点数的一半。正常运行状态下,训练集和验证集的平均绝对误差变化曲线如图8所示,从图中可以看出,LSTM-Aec模型在训练次数达到100前后时,平均绝对误差逐渐收敛,最终达到0.170 7。可见LSTM-Aec的重构数据样本能够有效的反映原始输入数据的相关信息。

图8 LSTM-Aec的重构误差变化曲线Fig.8 Reconstruction errors of LSTM-Autoenconder
阈值的大小会直接影响准确率的变化,本文观测窗口设置为5,阈值选为2.5,训练结果如图9所示。
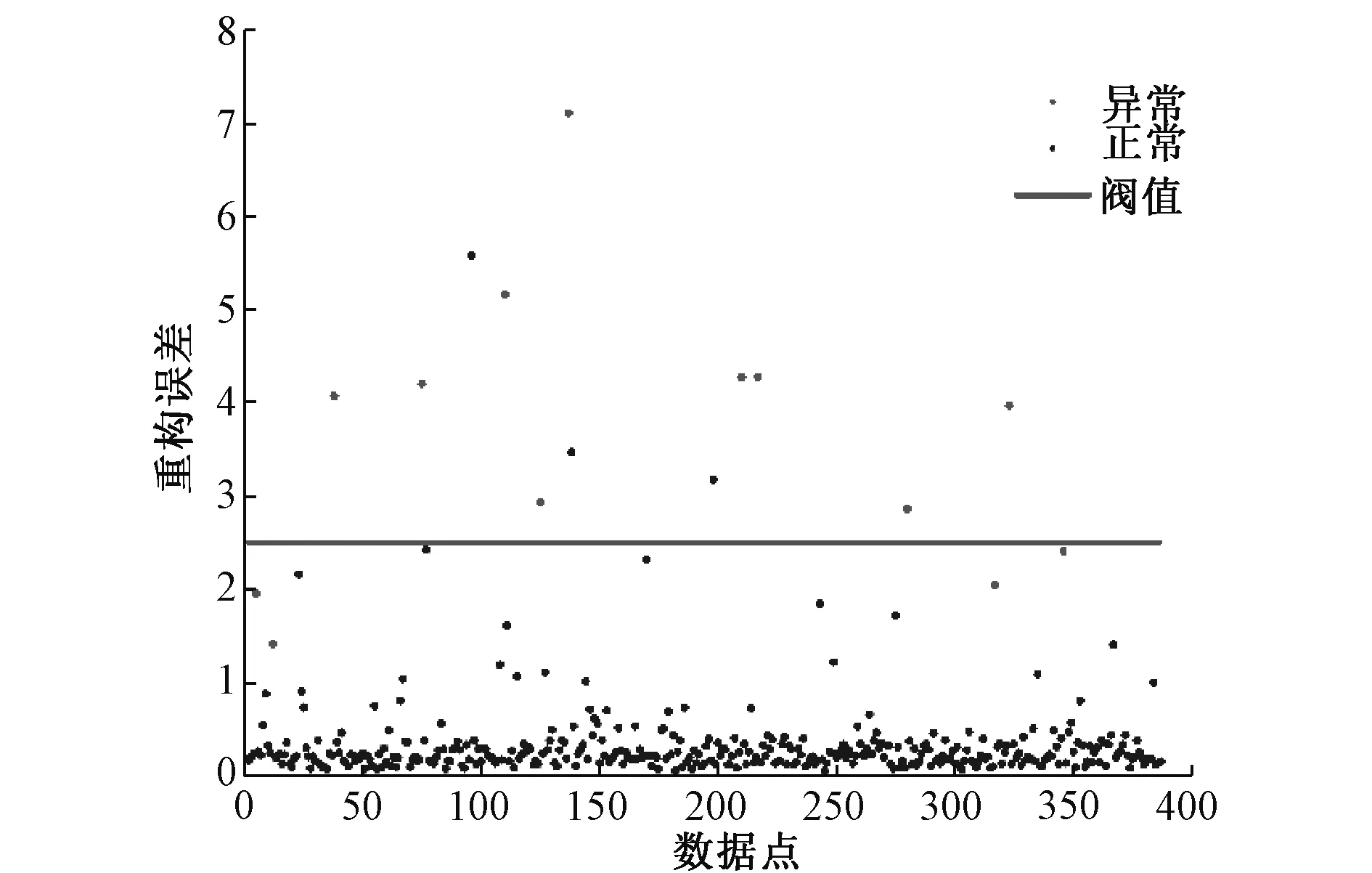
图9 验证集重构误差散点及阈值Fig.9 Validation set reconstruction error scatter and threshold
为了验证本文所提出的随机森林结合LSTM-Aec模型的优越性,将基于RNN的自编码网络和基于LSTM-Aec算法的检测方法得出的结果用来对比,同时对比随机森林(RF)、支持向量机(SVM)、BP神经网络三种传统分类方法的分类结果。其中BP的网络结构为9-50-1;SVM选用多项式基核函数作为核函数;RF采用第1章所述步骤;RNN-Aec结构与LSTM-Aec相同;以上均采用同样的训练数据与测试数据,对得到的测试集拟合结果进行分析。仿真结果如表2所示。
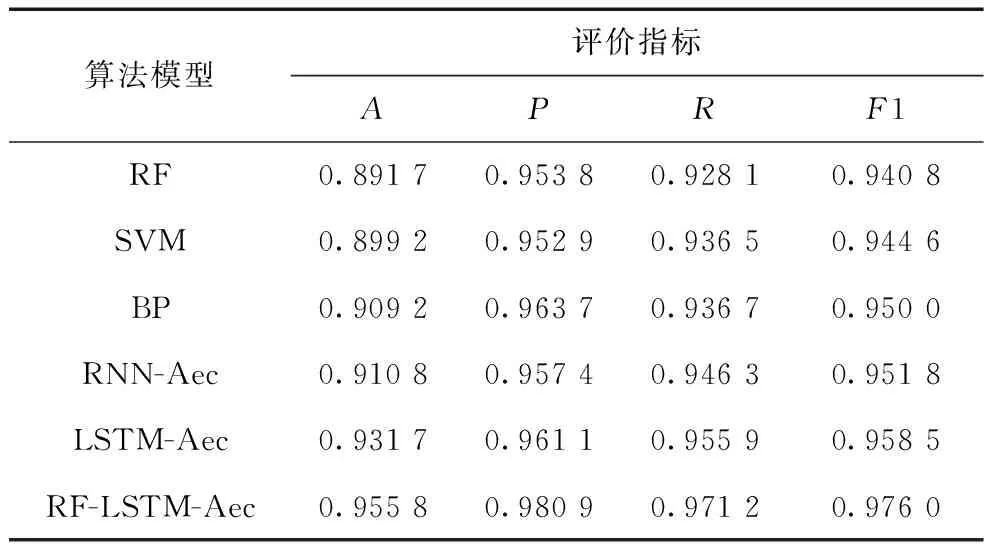
表2 算法性能对比
从表2中可以看出,传统分类方法中RF和SVM的准确率A、精确率P和调和分数F1相差无几,SVM较RF稍有优势,BP模型则比SVM和RF要全面占优,这是因为它作为神经网络算法的优势所在。本文所提方法在三个精准率、召回率和F1值这三个指标上均表现良好,RF-LSTM-Aec模型的精确率P和召回率R都要明显高于未使用随机森林进行处理的LSTM-Aec模型,分别为0.980 9和0.976 0。而RNN-Aec模型的检测结果中,各项指标均有所下滑,其中精确率P、召回率R和调和分数F1分别为0.957 4、0.946 3和0.951 8。综上所述,本文所提出的基于随机森林和LSTM-Aec模型的性能总体上优于RNN-Aec和LSTM-Aec算法以及传统的分类方法。
5 结 论
为了客观、准确表征风电机组高温降容状态本文提出了一种基于随机森林算法和LSTM-Aec算法相结合的风机高温降容状态评估模型。
(1)采用随机森林算法把SCADA数据的特征维度约简至9个,消除冗余特征对试验仿真造成的不良影响;
(2)利用LSTM-Aec算法计算检测值与实际值之间的重构误差进行参数调节,设定合适的阈值,以便对风机高温降容状态进行高精度的评估检测;
(3)实验仿真结果表明,基于该方法的风机高温降容状态评估的精确率和准确率分别达0.998 7和0.992 1,整体优于基于RNN-Aec和基于LSTM-Aec算法的检测方法以及传统分类方法。
猜你喜欢
今日农业(2022年16期)2022-11-09 23:18:44
今日农业(2022年15期)2022-09-20 06:55:48
环球时报(2022-06-20)2022-06-20 17:06:23
基层中医药(2018年8期)2018-11-10 05:32:06
能源(2018年5期)2018-06-15 08:56:02
能源(2017年9期)2017-10-18 00:48:27
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
作文大王·笑话大王(2016年7期)2016-08-08 11:28:43
现代工业经济和信息化(2016年12期)2016-05-17 05:37:47
