
基于改进TextRank的铁路文献关键词抽取算法
2021-06-04 01:13赵占芳刘鹏鹏李雪山
北京交通大学学报 2021年2期
赵占芳,刘鹏鹏,李雪山
(1.河北地质大学 信息工程学院,石家庄 050031;2.河北省光电信息与地球探测技术重点实验室,石家庄 050031; 3.中国铁道科学研究院 科学技术信息研究所,北京 100081)
伴随着中国铁路的高速发展,国内外铁路科技信息资源越来越丰富.但铁路行业涉及较多专业技术领域,且各学科高度交叉融合,面对海量的信息资源,科研人员往往需要投入大量的时间和精力来进行信息的检索、筛选、翻译、分析和内化等工作.作为信息资源的基础性建设工作,如何对铁路科技信息资源进行有效地组织分类并提供智能化、个性化和专业化的检索与服务,已经成为铁路科技工作者亟待解决的重要问题[1-2].关键词自动抽取技术是解决该问题的关键技术之一.关键词自动抽取是指利用计算机技术从文献中抽取反映文献主题的词语[3],该技术可以为信息资源的自动标引、分类和智能检索提供基础元数据.
当前,关键词自动抽取技术主要应用基于统计学的方法、基于语言学的方法、基于机器学习的方法以及其他一些融合方法.基于统计学的方法是利用文本特征的统计信息进行关键词的抽取,例如词频[4]、词长[5-7]、词共现[8-10]、词性及句法特征[11-13]等.基于统计学的方法是目前应用较为广泛的关键词自动抽取方法,TF-IDF(Term Frequency Inverse Document Frequency)算法[4]和TextRank算法[8]是较为经典的算法;基于语言学的方法是从人类语言学的角度出发,对文本的词、句、段落、篇章等进行层级分析进而抽取文本关键字,例如基于词汇链的方法[14-16].基于语言学的方法由于关键词抽取的精确度不高,经常与统计学的方法结合使用;基于机器学习的方法把关键词的识别看作分类问题,这类方法需要对大规模语料进行学习,提取关键词特征,构建关键词识别的分类模型.常见的算法有贝叶斯算法[17-18]、决策树[19-20]、神经网络[21-22]和支持向量机[23-24]等.这类方法因为对语料的数量和质量要求很高,没有被广泛的应用.
基于以上研究,本文作者以铁路行业领域的知网学术期刊资源为基础语料,提出了一种融合Word2Vec模型的改进TextRank的关键词抽取方法,与经典算法相比,该方法在性能上有一定优势,具有实际应用价值,可以为铁路行业基础词库建设提供技术支持,为铁路科技信息资源的智能检索、分类标引和知识导航提供基础元数据.
1 Word2Vec模型
Word2Vec是一种将词转化为词向量的浅层神经网络模型,得到的词向量是包含上下文信息的一种分布式向量表示.这种分布式的向量表示蕴含着潜在的语义信息,具有相近的语义和语法关系的词,训练所得的词向量在向量空间中的距离就越近[25].因此,借助于词向量相似度的计算可以判定词汇之间的语义相似关系.
Word2Vec包含Skip-Gram和CBOW(Continuous Bag-of-Words)两种基本的训练模型.Skip-Gram模型是根据当前词的One-hot向量,得到上下文的词向量概率分布,如图1所示.CBOW模型与之相反,通过上下文的One-hot向量的输入得到中心词的概率分布,如图2所示.Skim-Gram模型所需训练的时间要比CBOW模型要长,对于语料较大的数据计算的复杂度较高,适合数量较少的计算;CBOW模型更适合文本语料较大的运算,并且具有较高的计算精度.

图1 Skip-Gram模型Fig.1 Skip-Gram model

图2 CBOW模型Fig.2 CBOW model
Skip-gram模型是基于某个中心词来生成它在文本序列中周围的词,假设在给定中心词的条件下上下文背景词的生成相互独立,给定任意一中心词生成所有背景词的条件概率为
(1)
式中:m为上下文的窗口大小;T为文本序列的长度;W(t)为时间步t的词.
由图1可以看到, Skip-gram网络模型分别是:输入层(Input Layer)、投影层(Projection Layer)、输出层(Output Layer).其中输入层的输入是中心词的One-hot向量,投影层的训练任务是通过最大化似然函数来学习模型参数,等价于最小化的损失函数,得出
(2)
给定中心词生成背景词的条件概率如下
(3)
式中:vi是中心词向量表示;ui是背景词向量表示.Skip-gram的输出层表示成一棵二叉树,其中叶子节点就是训练样本中出现的词,以各词在训练语料中出现的频次作为权值构造Huffman树.
图2中CBOW模型的假设基于某中心词在文本序列的上下文背景词来生成该中心词.输入层包含样本W的上下文窗口中对应词的One-hot向量,即V(W(t-2)),…,V(W(t+2)):将输入层2m个词向量累加后求平均;输出层同样表示成一棵Huffman 树.
2 经典TextRank算法
TextRank算法[26]根据网络图的定义构建词图G(V,E),词语的集合为V,词语之间的连接集合为E,计算公式如下
T(vi)=(1-d)+d×
(4)
式中:T(vi)表示节点vi的TextRank值;d为阻尼系数;I(vi)代表指向节点vi的节点集合;O(vi)是节点vi所指向的节点集合;wij指的是节点vi到vj之间边的权重即转移概率.
TextRank算法可以仅根据文本语料自身的信息就可以得到文本的关键词.但是,TextRank作为一种完全基于图关系的分析方法,在关键词抽取应用上具有一定的缺点:1)每个词汇初始化权重相同,忽略了词汇位置、词频及专业性等重要特征;2)词语之间的连接权重值相同,未考虑词语之间的语义相关关系.
3 改进TextRank的关键词抽取算法
本文提出一种融合Word2Vec模型的改进TextRank的关键词抽取算法,将词频、词位置及外部铁道叙词库信息综合应用于词汇的初始化权重信息,借助于Word2Vec模型训练的词汇间相似度矩阵作为TextRank算法的概率转移矩阵,应用于铁路文献关键词的抽取.
3.1 融合多因素特征构建词节点初始化权重
经典TextRank算法将每个词汇节点的初始权重默认设置为1或1/N(N为节点个数),再通过邻接关系进行迭代计算,更新节点的权重,在计算词汇节点的权重贡献时以权重均匀分配的方式向相邻节点传递.事实上,每个词汇节点的重要程度不一样,应该综合多源因素,根据每个词汇节点自身的重要程度不同赋予不同的值作为各自的初始权重.
利用词频、词汇位置同时结合铁路叙词表对词汇节点的初始权重进行加权度量,词图节点中的词汇初始权重计算如下
W(vi)=tf(vi)+pos(vi)+val(vi)
(5)
式中:W(vi)代表词节点vi的初始化权重;tf(vi)表示词vi出现的频次;pos(vi)表示节点vi的位置权重;val(vi)表示出现在铁道叙词库中的词的权重.
针对位置加权,采取的方案是如果候选关键词出现在标题中,则给其一个权重ρ,反之为0,位置权重的设置如下
(6)
此外,如果候选关键词在铁道叙词库中出现,则给其赋予一个大于零的权重θ,反之为0,则铁道专有名词的权重设置如下
val(vi)=
(7)
通过以上方式计算出每个节点的初始权重,最后将得到的每一个节点的初始权重值归一化后的结果作为最终的初始权重W′(vi).假设铁路文本语料T经过预处理后包含N个候选关键词,即文本T所对应的候选关键词图可由N个节点组成,每个节点的初始值可以通过式(5)求出,最终所有节点的初始权重值可以用向量T0表示为
T0=(W′(v1),W′(v2),…,W′(vn))
(8)
改进后TextRank候选关键词图见图3,A~F代表词图节点,W′(A)~W′(F)代表不同节点的初始权重,有向边表示节点间的转移概率.

图3 候选关键词图示例Fig.3 Example of candidate keyword graphs
3.2 基于Word2Vec构造概率转移矩阵
经典的TextRank模型是一种无向加权图,图中词汇节点之间的边的权值都是相等的,即词图模型中每条边都是以等概率的方式进行节点间的权重传递,无法体现出词图模型中相连词节点之间关系的差异.Word2Vec模型能将词映射到低维的向量空间中并能体现出词汇之间潜在的语义相似度信息,因此可以将Word2Vec训练得到的词间相似度作为词图节点之间边的权值,即转移概率.
假设预处理后的文档是由N个候选关键词组成的词汇集合T=[v1,v2,…vN],那么词间相似度的计算如下
(9)
(10)
式中:Sij表示节点vi与节点vj之间的相似度;M为词节点间的相似度矩阵.当词图模型中两个词之间的相似度越大,表明词间相关性就越强,权重传递到与之相连的词节点的概率也就越大.最后,TextRank的迭代计算如下
Ti=(1-d)T0+d×M×Ti-1
(11)
式中:d为阻尼系数,通常取值为0.85;Ti为通过 TextRank 算法迭代计算得到的权重值.
3.3 TextRank的关键词抽取算法
1)语料预处理.
利用Jieba分词工具,并引入铁路核心词库作为自定义词典对N篇语料文档进行分词,过滤停用词,获得词汇集(V1,V2,…,VN),每一个词汇集Vi对应一篇文档,词汇集的并集得到语料词典D.
2)构建词图并初始化词汇节点权重.
基于语料的上下文关系建立词图节点间的连接关系,根据词频、词位置以及铁路叙词表计算每个词汇节点权重的加权和,即初始化节点的权重.
3)构建概率转移矩阵.
针对预处理后得到的语料词典D,利用Word2Vec模型进行文本训练得到词汇的向量表征,通过余弦相似度计算得到词汇间的相似度关联关系,将其作为词汇间的转移概率.在语料D中训练所得的相似度矩阵作为TextRank算法概率转移矩阵,即初始化词间关系权重.
4)迭代计算每个词汇节点的TextRank值.
针对词图中每一个词汇节点分别迭代计算TextRank值.
5)抽取关键词.
对词图中每个词汇节点的TextRank值进行排序,输出前N个最大的值所对应的词作为最终抽取的关键词.
3.4 时间复杂度分析
假设共有m篇文档,每篇文档有n个候选关键词.在本次实验中TF-IDF算法的时间复杂度主要体现在对每篇文档每个词的TF-IDF值的计算上,其时间复杂度为O(m×n).TextRank算法抽取关键词的时间复杂度主要体现在转移概率矩阵的构建上,其时间复杂度为O(n2).改进算法在原始的TextRank的基础之上增加了Word2Vec模型训练以及初始权重的设置,训练部分采用CBOW模型结合Hierarchical Softmax的训练方式,该过程的复杂度为O(logV),V代表语料词库词典的规模,此时V=m×n;初始权重设置过程的时间复杂度为O(n),因此,改进的算法相较于TextRank的时间复杂度为O(n2)+O(log(mn))+O(n),其时间复杂度依然为O(n2),所以改进的算法没有明显提高复杂度.
由于TF-IDF算法需构建语料库,该过程因不断用到字符串查找匹配及读取等操作需大量时间消耗,虽然计算速度较快,但复杂度较高,TextRank算法的时间复杂度主要体现在概率转移矩阵的构建和迭代计算的过程中,对于较长文本来说,两者的复杂度可能比较接近.改进的算法利用神经网络模型训练出词向量,从语义的角度上改善TextRank的概率转移矩阵并结合词节点本身的特征改变节点的初始权重设置,明显提高了关键词抽取的准确率、召回率以及F:值,但时间复杂度没有改善.
4 实验与分析
4.1 实验环境及数据
实验使用的语料来源于中国知网学术期刊中铁路行业领域的中文文献,从中选取了31 547篇文献作为本次实验的训练数据,首先对31 547篇语料进行预处理得到词汇集文本D,然后利用Word2Vec模型训练预处理后的文本语料D得到语料中词汇的向量表征,随机抽取1 000篇语料测试关键词抽取的效果.
Word2Vec模型的训练及实验测试的整个流程在腾讯云上部署,GPU为Intel Xeon Skylake 6133(2.5 GHz),内存为40 G.本文算法基于Python 3.7实现,采用Jieba分词模块,训练词向量采用Gensim 库的Word2Vec 模块训练候选关键词语料.本实验Word2Vec模型初始化的主要输入参数:size=100,window=8, min_count=1,sg=0,hs=1,其中size是词向量维度,window是上下文窗口大小,sg=0则采用CBOW算法,hs=1代表采用Hierarchical Softmax技巧加速训练.
将文本语料通过分词以及去停用词等预处理操作后得到训练语料,将训练语料输入到Word2Vec模型中进行训练,Word2Vec模型可以将输入的经过预处理的文本嵌入到向量空间中,从而输出训练后的文本中每个词的词向量,本次实验训练词向量共计耗时4 h17 min,最终得到训练后的词向量文件,然后基于词图模型中相连节点之间的词间相似度构建概率转移矩阵.截取词的部分向量如下
地铁车站 -0.00042947268 0.0017898704 0.0007452105 -0.0016284916…
城市轨道交通 0.003786283 0.0028316667 -0.00455604 -0.0024452142…
地下连续墙 0.0010942959 -0.0018053391 0.0013831913 -0.004778044…
盾构隧道 -0.00082359917 -0.004505363 -0.002531063 -0.00094276527…
围护结构 -0.0041449596 -0.00023882258 -0.004767135 -0.0033635767…
4.2 评判标准
本实验用平均准确率P,平均召回率R及平均F值3个指标来评估关键词抽取的效果,因F值可综合反映准确率和召回率的效果,因此以F值作为最终的评判标准,3种指标的计算公式如下
(12)
(13)
(14)
式中:xi表示第i篇文献通过算法提取出来的关键词集合;yi表示第i篇文献人工标记的关键词集合;N代表算法测试的文本数量,在本实验中N=1 000.
4.3 实验参数确定
由于F值是综合反映准确率与召回率的指标,因此本文通过F值来反映实验效果进而根据实验效果来确定ρ和θ的取值,当设置式(5)中val(vi)=0,关键词抽取数量为5时研究ρ的取值,通过大量实验测试数据得出当ρ取值为11时F值达到最大的0.427,当ρ取值大于11时,不同的取值对F值的影响基本趋于一致.图4(a)展示了抽取关键词个数为5时,F值随参数ρ的变化趋势.在此基础之上,以同样的方式来研究参数θ的取值,当参数θ=16时,F值得到最大0.448,当θ的取值超过16之后,不同的取值对F值的影响也基本趋于一致.图4(b)展示了抽取关键词个数为5时F值随参数θ的变化趋势.抽取关键词个数为3和7时,实验效果基本一致,因此,本次实验的权重参数选取ρ=11,θ=16.
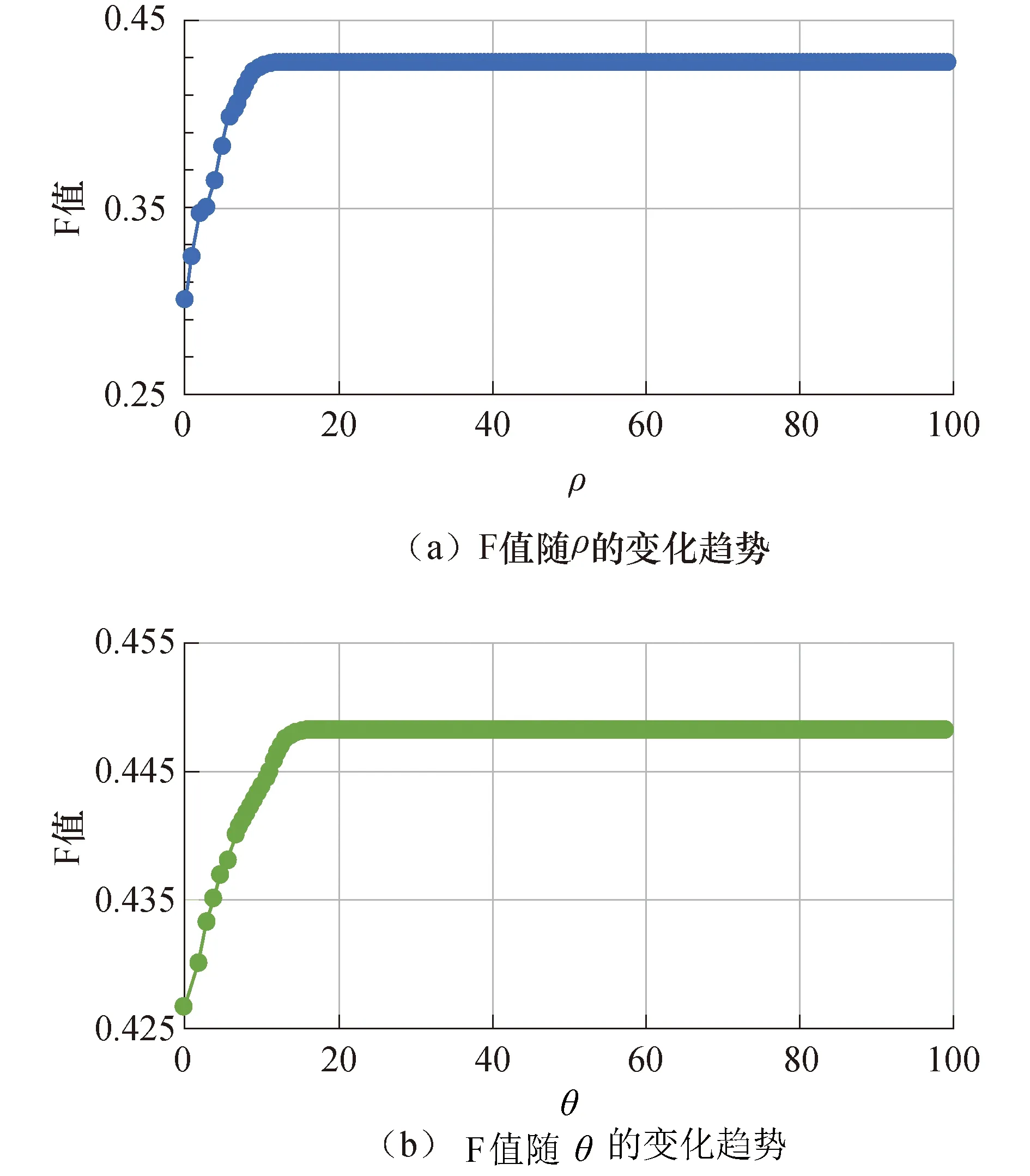
图4 关键词个数为5时F值随不同参数的变化趋势Fig.4 Changes trend of F value with different parameters when the number of keywords is 5
4.4 实验结果与分析
TF-IDF和TextRank算法是关键词抽取的经典算法,本实验将所提出的改进算法与这两种经典算法做了对比实验,在部署的腾讯云上对1 000篇测试语料进行关键词抽取.当设置关键词抽取的数量为3、5、7时,计算各算法的平均准确率、平均召回率和F值,评价指标的对比结果如表1所示.

表1 关键词抽取的3种算法的评价指标对比Tab.1 Evaluation indexes comparisons of three algorithms of keyword extraction
从表1可以看出,针对铁路运输领域的测试语料进行关键词的抽取实验,本文所提出的融合Word2Vec模型的改进TextRank的关键词抽取算法在准确率,召回率和F 值上均明显优于经典的 TextRank 算法和TF-IDF算法.在本实验中关键词抽取个数为5时,改进的算法F值最大,实验效果达到最佳.
本文所提出的改进算法能够得到较好的关键词抽取效果的原因是:1)在语料预处理阶段,使用Jieba工具时,引用铁路核心词库作为自定义词典对文档进行分词,避免了分词结果的粒度过细,保证了分词结果中词汇的专业性特征;2)词频代表词汇在文档中出现的频次,出现次数越多的词汇其重要性也越大,出现在文档标题部分的词汇相对更重要,铁道叙词库中的词汇表明了词汇的专业性.所提出的改进算法综合考量了词频、词位置和铁道叙词库等因素,对词汇节点的权重进行了加权求和并初始化,对提升关键词抽取的准确性有积极意义;3)利用Word2Vec训练词汇向量,既考虑了词汇之间在文本中的相对位置关系,还保留了词汇之间的语义相关关系,利用词汇间的相似度距离作为词汇之间的转移概率,充分考虑了词汇之间的关联关系.
5 结论
1)提出了一种融合Word2Vec模型的改进TextRank的关键词抽取算法,该算法不仅考虑了词汇出现的频次、位置信息,还考虑了词汇在铁路专业领域的专业性、文本的上下文信息及语义相似度.
2)所提出的算法应用于铁路运输类文献语料的关键词抽取上,与经典的TF-IDF和TextRank算法相比,在准确率、召回率和F值的性能评价上均有明显的优势,具有实际的应用价值.
铁路行业基础词库可以为海量的铁路科技信息资源的使用提供有效的知识组织工具.将关键词的自动抽取技术应用于铁路行业基础词库建设,应用于铁路文献的自动标引分类,为铁路科技信息资源的智能化管理和应用提供新手段是本研究下一步的主要工作.
猜你喜欢
北京大学学报(自然科学版)(2022年4期)2022-08-18
心理学报(2022年5期)2022-05-16
社会科学战线(2022年2期)2022-03-16
现代计算机(2021年33期)2022-01-21
当代陕西(2020年17期)2020-10-28
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
人大建设(2018年5期)2018-08-16
